
 起点课堂会员权益
起点课堂会员权益以淘宝女装分类为例:AI产品经理要不要懂算法?
有的时候AI产品经理被认为是拿着算法技术在不同的行业里、不同的业务类型中、不同的场景里尝试需求设计成产品并运营之,那么在智能+的红利期,在算法边界的探索期,在传统互联网需要转型+AI的刚需期,AI产品经理要不要懂算法呢?

我们先来分析一个案例:用深度学习算法帮助淘宝女装分类
步骤流程如下:
- 第一步:搜集形成数据集;
- 第二步:沟通团队拟定产品方法策略【比如:选择适合的模型算法】;
- 第三步:所采用的模型算法在第一步的数据集上进行训练;
- 第四步:比对其他模型算法的效率;
- 第五步:上线
一、数据采集及数据处理
产品驱动并有产品经理确定数据采集对象,例如:确定采集女装,跟团队讲出理由。
首先产品提出需求从淘宝网站上爬取大量的女装图像并进行筛选保留了XXX张质量比较高的图像。然后,将这些图像分为多少个子任务(女上衣品类、主颜色模式、次颜色、主模式、次模式、纹理模式、流行元素、领型、袖长、衣长、版型、门襟、面料),其中每一个子任务都是一个独立的细粒度多分类问题,分别展示衣长、女上衣品类、主颜色和主花色模式的一些样本。
最后,在清洗完数据之后,请一些行业专家对数据进行标定和检验,以确保数据的可靠性。另外每个子任务的数据分布都是不均匀的,衣长、主颜色以及主花色模式分布更是极其不平衡,这个现象增加了分类问题的难度。
二、用深度学习技术
1. 框架算法选择
算法工程师选择几个较具有代表性的神经网络(例如:Resnet101、空洞卷积网络和压缩激励网络),并在此基础上进行图像分类。
(1)Resnet101:在深度学习初期,由于梯度消失的问题,网络结构的深度一直是一个难以解决的难题。残差网络 Resnet引入一个所谓的恒等快捷连接,将上一层的输入直接与后面层的输出相加,很好地解决了梯度消失的问题。
(2)空洞卷积网络(Dilated Convolution Network,DRN):在使用深度神经网络解决分类任务的问题上,维护图像的分辨率是一个很重要的任务,即输入的分辨率越大,分类的效果越好。但由于硬件设备的限制,不能无限地增大图像分辨率,而 DRN使用空洞卷积的思想很好地解决了这个问题,即使用较小分辨率的输入一样能得到很好的效果。
(3)压缩激励网络(Squeeze-and-Excitation Networks,SENet):SENet曾经获得了 ImageNet 2017 图像识别大赛的冠军,其做法是通过学习的方式自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
2. 处理不平衡数据
算法工程师共同挖掘数据不平衡问题,比如:基于采样的方法和基于代价(损失函数)的方法。
(1)基于采样的方法:在不平衡分布的数据中使用采样方法,目的是为了将不平衡的数据变为均匀分布。
一般,将分布不平衡的数据变为均匀分布之后能够有效提高分类精度,常见的采样方法一般分为升采样和降采样。 其中,升采样一般又有随机升采样、合成新数据等方法。
降采样一般有随机降采样、指导性降采样等方法:
- 其中,随机升采样的做法是:从样本数量少的类别集合 Smin 中随机复制一部分样本,然后将其添加到总样本集合 E 中,最终使总样本集合中的样本分布达到平衡。
- 而随机降采样的做法则是相反:将样本数量多的类别集合 Smax中随机删掉一部分样本,最终使总样本集合 E 分布达到平衡。
(2)基于代价(损失函数)的方法:主要是从损失函数方面入手解决样本分布不平衡的问题。
对某一类,其类内之间的距离有可能非常大,需要增加一种约束将其类内之间的距离缩小;而对另外一部分类,其类间距离可能太近了,因此需要一种约束来将其类间距离拉大。
技术研究使用,例如:Rangeloss损失函数处理分布不均衡问题。 Rangeloss 损失函数来解决这个问题,其中,Rangeloss 是一种和样本数目无关的损失函数。具体的,Rangeloss 分为类内损失函数和类间损失函数两部分。
具体如公式如下:Lr=| aLr intra+BLr inter|
作为损失函数是解决啥问题呢?
现在数据库中普遍存在的问题,就是数据存在长尾分布的情况。
那么什么是长尾分布呢?
其实有点类似于二八定律,即80%的财富集中在20%的人手里等等。尾巴部分虽然值普遍很小,但是由于数量很多,导致其对一个模型的训练有很大的影响。
对于女装数据库而言,长尾分布主要表现在很多的identity含有较少的赝本数量,如下图:

3. 多任务联合训练策略
在这多个子任务中,有些子任务之间可能是具有相关性的,如女上衣品类和衣长、主颜色和次颜色、纹理模式和版型等。若将每个子任务看作一个独立的子任务,显然会忽略任务之间的一些相关性。为了将任务之间的相关性利用起来,技术一般采用多任务联合训练策略。多
任务学习,是将多个相关的任务放在一起学习的一种机器学习方法,如下图:图中的神经网络处理算法,在笔者的书《AI赋能-AI重新定义产品经理》一书中还有很多撰写。
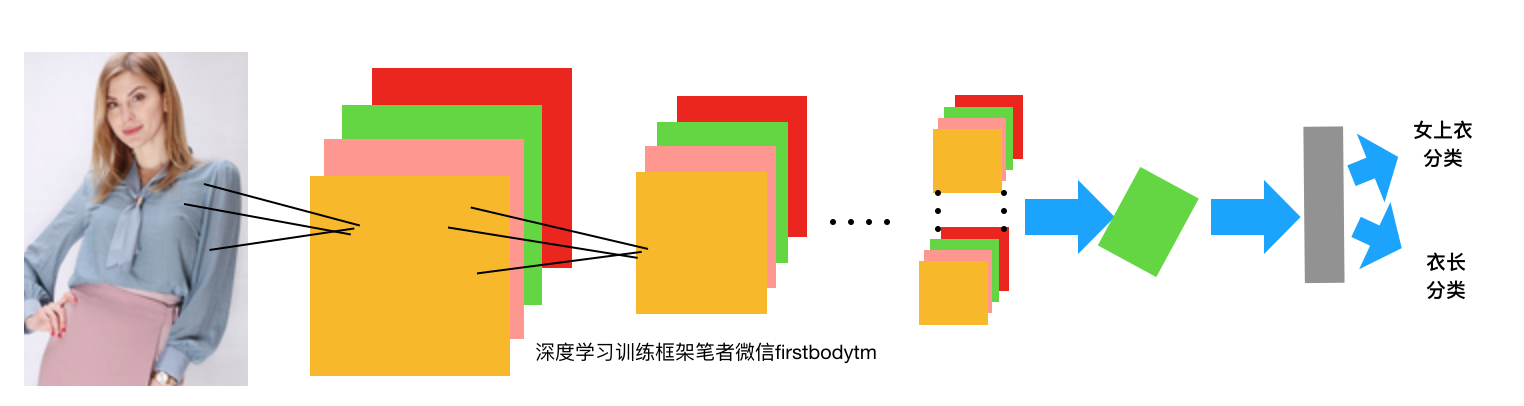
多个任务在浅层共享参数,在最后使用各自任务所对应的分类器进行分类,每个子任务的分类器都是以一层或多层全连接层实现的。在训练时,每个子任务的分类结果使用交叉熵损失函数计算损失,并将每个子任务的损失加权求和得到最后的损失。
4. 技术选择深度学习框架和硬件条件
例如:算法工程师会配合技术人员采用 Ubuntu16.04+python2.7+pytorch 0.4 作为深度学习框架,并在此基础上进行训练。训练中使用显卡为 TITAN XP 2080Ti。
算法工程师在 Resnet101、DRN 和 SENet 这 3 个神经网络上进行对比,看哪种算法分类效果更好。
三、AI产品经理的工作不仅仅是“摆渡人”。
AI产品经理做的还是产品需求挖掘+产品资源规划+行业专家+协同算法工程师探索适合的算法。
1. 产品需求挖掘
如当用户想要在淘宝会等平台购买商品时,往往会根据商品的类别及其属性来筛选需要购买的目标商品,因此商家会为每件商品制定很多属性以便于用户检索。面对海量的商品图像数据,如果使用人工标注的方式对商品图像的属性进行标注,需要花费大量的人力和时间。
2. AI产品资源规划:步骤流程
- 第一步:搜集形成数据集;
- 第二步:沟通拟定产品方法策略【比如:模型算法】;
- 第三步:所采用的模型算法在第一步的数据集上进行训练验证;
- 第四步:比对其他模型算法的效率;
- 第五步:上线。
3. 行业专家
商品图片的特点是:有些商品不同的属性之间数量差异很大,即商品的属性存在数据分布不平衡的特性,如“衣长”属性,日常生活中人们穿得最多的是标准的到达髋部位置的衣服(普通外套、T 恤等),其他的如风衣、长短裙(到达大腿或小腿位置)等的数量明显少于到达髋部位置的衣服。
有些商品不同的属性之间差异很小,可以看作是细粒度分类问题,如“领型”属性,一些领型属性之间的差异非常小,常人难以区分开来。这两个问题加大了商品图像属性分类的难度。
所以首先AI产品经理,是个学习型的衣服行业专家。
4. 协同算法工程师探索技术边界:
选在基于深度学习技术,使用卷积神经网络对商品图像的属性分类进行研究。
(1)首先确定范围:从淘宝网站上爬取XXXXXXXXX个商品图片。
(2)其次并将这些图片分为多少个子任务:女上衣品类、主颜色模式、次颜色、主模式、次模式、纹理模式、流行元素、领型、袖长、衣长、版型、门襟、面料。
每一个子任务都是一个独立的细粒度多分类任务,且几乎每个子任务都具有严重的数据分布不平衡问题,这点重点建议算法工程师采用适合的算法。
5. AI产品经理多少还是要懂一些硬件
笔者在新书《AI赋能-AI重新定义产品经理》一书中和AI产品经理相关内容中多次提到数据由硬件采集,也有的人叫物联网(IoT)。另外笔者也多次强调AI=算法+数据+算力,算力也是有硬件提供。
总结
AI产品经理要懂算法,且是跟算法工程师共同打磨技术的边界。如果团队算法工程师和编码工程师的技术能力非常充足,那么产品经理可以把精力放在非算法协同上,如果团队资源不充足的话,AI产品经理就要付出更多的经历配合算法工程师寻找适合的算法并落地。
部分产品经理阅读了本文会觉得AI产品经理很简单,Just so so 的错觉,作为踩过坑,熬过无数夜的人建议不妨多听听别人踩过的坑。才来判断自己是否适合AI产品经理,才知道自己是否是个能够在互联网冬天愿意突破职业发展瓶颈的人。
如果你想系统化入门AI产品经理,掌握AI产品经理的落地工作方法,戳这里>http://996.pm/7bjab
#专栏作家#
连诗路,公众号:LineLian。人人都是产品经理专栏作家,《产品进化论:AI+时代产品经理的思维方法》一书作者,前阿里产品专家,希望与创业者多多交流。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议









我是Line粉,我觉得,只有勤奋持续学习的人才能抓住AI 的红利。不愿努力的人肯定在互联网裁员风波中深感痛苦。