
 起点课堂会员权益
起点课堂会员权益PM技术课 | 推荐系统,从原理到实现
大数据时代,冗杂的信息让身处其中的用户们感到迷茫,无法抉择。所以,大数据时代推荐系统的重要程度就不言而喻了。如何在有限的时间内给用户推荐合适的信息或商品,是推荐系统最重要的工作。那么,推荐系统是如何运转的,其原理以及运转流程如何?以下,将由笔者为大家详细讲述。

一、你关心的,才是头条
随着互联网行业的发展,网络的数据量也在不断增加。仅微信,平均每个人要关注几十甚至上百个公众号;淘宝的商品数量也有上亿种。
如何在有限的时间找到需要的信息或者商品?如何给用户推荐合适的内容和商品?
除了搜索引擎按照用户的搜索展示外,推荐系统也起了关键作用,通常有两种推荐方式。
第一种推荐方式是:大众推荐。
基于“大家都喜欢潮流(跟风)”这一假设,根据流行程度进行大众推荐,常见的有热搜、排行榜,对于新的作品或者新的商品,也会单独推荐,以提高新鲜感。
这种大众推荐方式主要依靠阅读量或者人工进行推荐,主要有两个问题:一来热门的数量有限,用户可能看一会儿就没什么可看的了;另一方面,用户或许对特定的领域更感兴趣,愿意为此花时间或者花钱,这也就是所说的长尾效应。
这就催生出了第二种推荐方式:个性推荐,也是我们要讲述的。
个性推荐本质上是一种信息过滤系统,用于预测用户对物品的偏好,推荐用户更感兴趣的内容,用户使用时长会快速增加,刷新闻,一刷就是几个小时;推荐用户更感兴趣的商品,“逛”商场的时间和客单价也会相应提高。
最近风头正盛的今日头条正是使用推荐系统,获得快速成长的绝佳范例。

按照今日头条官网的介绍:今日头条“一款基于数据挖掘的推荐引擎产品,它为用户推荐有价值的、个性化的信息,提供连接人与信息的新型服务”。通过个性推荐,今日头条在短短几年时间内,成长为互联网领域炙手可热的明星。
今日头条融合了多种特征进行计算,包括兴趣、年龄、性别、行为等用户特征,地理位置、时间、天气等环境特征,主题词、热度、时效性、质量、作者来源等文章特征。通过数据计算特征,根据特征计进行推荐,最终实现“千人千面”的新闻推荐方式。

在电商领域,最值得称道的是亚马逊,亚马逊宣称,通过个性推荐提高了其30%的销售。

亚马逊记录用户浏览页面的点击、加入购物车、购买、评价等行为,将用户的行为记录与其他用户的进行对比,通过相似用户,向用户推荐更多可能感兴趣的商品。与此同时,根据用户的行为的变化,不定期更新推荐内容,充分考虑到了用户喜好的改变。

除了电商和新闻,在视频、图书、音乐等领域,个性推荐系统也发挥了越来越大的作用。
常见的个性推荐算法主要包括:基于内容个性推荐、利用用户行为的协同过滤、基于数学模型的推荐等。在实际应用中,往往会将这些推荐系统的结果进行融合,生成最终的推荐。

二、基于内容的推荐(Content-Based Recommendation)
1. 猜你喜欢
基于内容的推荐主要利用内容本身的特征进行推荐,把类似的内容推荐给用户。
比如:根据音乐的流派、类型、歌手等推荐类似的音乐,如果用户喜欢听《青花瓷》,音乐APP就会推荐周杰伦的《千里之外》。同样也可以根据商品推荐同类的商品,如果用户搜索过手机,电商APP就会在首页推荐各种牌子的智能手机。
基于内容的推荐是非常基础的推荐策略,最核心环节的是:计算内容本身的相似性。
以音乐为例:向用户推荐同一个歌手的音乐是很简单的,用户喜欢《青花瓷》,就直接把周杰伦的歌单推荐过去就好了。
相比之下,向用户推荐某个流派的音乐稍微有些难度,首先要有每一首歌的流派标签,之后根据标签进行推荐,还好几乎每首歌都有流派标签,比如:流行、轻音乐、摇滚、民谣等。
语言、主题、场景等标签也是类似的。所有这些标签都需要手工标记,虽然麻烦,但是也能实现。
但,如果用户可能就是喜欢某种调调,某些歌词呢?如何向用户推荐某种曲风、曲调或者歌词的音乐?这就需要计算旋律的相似性、歌词的相似性等。
涉及到音频处理,这个问题有些复杂,一时半会儿也说不清楚,我们拿稍微简单些的新闻推荐,剖析下如何实现基于内容的推荐,虽然具体的操作和算法不同,但原理是相通的。
虽说稍微简单些,但新闻相似度的计算也是相当复杂的工作,主要包括获取新闻、清洗数据、数据挖掘、计算相似度等环节。
按照所述《网络爬虫》,我们可以使用爬虫来获取新闻,这里不再赘述。
数据获取之后,就是数据清洗,主要是新闻去重,新闻热点就那么多,大家“借鉴来借鉴去”,不可避免存在重复的内容。
比较简单的去重方式就是直接计算句子是否重复出现,如果连续几句话都一模一样,重复的可能性就比较大。说句题外话,“洗稿”基本就把句子重新写了一遍,直接重复很少,这也是洗稿不容易被发现的一个主要原因。
在去重的同时,也会识别色情内容、广告、政治敏感内容等。
2. 新闻分类
基于内容的推荐,大多数的时间都在进行内容挖掘和分析。
数据清洗之后,基本就是一篇篇新闻文本了。但一篇文章动辄几百上千字,文本自身的数据量太大,直接计算相似度还很困难,需要通过数据挖掘,计算文本的特征,之后再利用特征计算相似度。
最常见的特征是关键词,我们可以用关键词表示一篇文章,就像我们评价一个不是特别熟悉的人一样,使用“标签”来表示我们对他的看法。

常用的关键词获取技术是上一章《搜索引擎》所讲的TF-IDF(Term Frequency–Inverse Document Frequency)模型,通过分词、去除关键词、计算每个词出现的频率获得TF;计算关键词在所有新闻中出现的频率,计算IDF,之后按照TF-IDF模型,计算关键词特征。
这里为了方便展示,没有计算TF-IDF具体数值。
比如:这篇新闻(2019年3月7日《人民日报》),原文有上千字,我们使用TF-IDF模型,去掉停用词和常用词,提取关键词。通过计算, “国产”“科幻电影”“流浪地球”等直接体现本文内容词语就是本文的关键词。

按照同样的方法,另一篇类似的文章(2019年2月14日《中国经济网》),我们可以提取其中的关键词,“好莱坞”“科幻电影”“现实”等。

为了便于对比,我还找了另一篇文章来自微软亚洲研究院的文章(2018年11月6日),关键词是 “推荐系统”“收入”等。

我们用关键词表示这几篇新闻,使用新闻1代指第一篇新闻,其他类似:
新闻1={“中国”,“科幻电影”,“流浪地球”,“人类”}
新闻2={“好莱坞”,“科幻电影”,“人类”}
新闻3={“推荐系统”,“收入”}
这样,一篇几千字的新闻,就被我们压缩成了几个关键词,当然,实际的情况没有这么简单,一篇新闻可能有数十个关键词。
这里还不能明显看出什么区别,当我们把这三篇文章的关键词放在一起,就很容易发现文章之间的相似程度。
因为有相同的关键词,相较新闻3,新闻1和新闻2明显比较类似,可以把新闻1和新闻2归为一类,新闻3单独一类。

3. 余弦相似度
通过数据TF-IDF模型,我们已经获得了关键词,并发现可以根据关键词的不同,判断新闻内容的相似性。
那么,我们如何量化这种类似关系呢?
最简单的方式是余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度。
如图所示,我们使用向量夹角的大小,来判断两个向量的相似程度,夹角越小,两个向量越类似;夹角越大,两个向量越不同。左边的夹角就要小于右边,我们可以认为,左边的两个向量更加类似。

在二维空间中,我们使用a、b表示两个向量,a和b的坐标分别是(x1,y1),(x2,y2),向量a和向量b的余弦计算公式如下:

余弦的这种计算方法对多维向量也成立,这里我们假设总共有n维向量。
利用余弦相似度,我们可以计算关键词之间的相似程度。
我们把每一个新闻当做向量,每一个关键词作为一个维度(可以理解为一个坐标轴,如果有两个关键词,就是二维向量;如果有三个关键词,就是三维向量,依此类推)。
这样,每篇新闻都用关键词表示,每个关键词都有一个TF-IDF值。
下表是一个简单的TF-IDF表格,不同新闻有不同的关键词,以及对应TF-IDF值。


之后,按照多维向量的计算公式,我们可以计算所有新闻两两之间的相似程度。
- 如果向量夹角为0度,余弦相似度为1,此时两个向量应该是最相似的。这表明,两篇新闻内容非常相似,当然,也有可能是重复的文章。
- 如果夹角为90度,此时余弦相似度为0。这表明,两篇新闻的关键词都不一样,内容完全是无关的。
- 余弦相似度在0~1之间,说明两篇新闻具有一定的相关性。
通过计算余弦相似度,我们可以发现:新闻1和新闻2的余弦相似度较大,说明两个新闻很类似;而新闻1、新闻2和新闻3之间的余弦相似度接近0,说明新闻1、新闻2与新闻3基本没有关系。
需要注意的是:在实际计算中,一篇文章的关键词可能有几十甚至上百个,所有文章组成的关键词可能就是几万个了。用关键词代表文章,相当于大小数万的矩阵相乘,计算量会很大,即使是最快的服务器,计算所有的新闻之间的相似程度,也要好几天。
在实践上,会有很多优化的空间,比如:代表文章的向量中有很多0不需要计算,这样可以把计算复杂度降低几十上百倍。也可以利用数学模型,进行矩阵分解,加速计算。
4. 基于内容推荐的特点
首先,基于内容的推荐实现起来比较简单。相较其他推荐系统,不需要复杂的算法和计算,因此在新闻、电影、音乐、视频等推荐中有广泛的应用。
第二,如果只计算标题的相关性,就可以实时计算。这在电商的商品推荐,非常有吸引力。试想一下,根据用户的浏览行为,实时更新“猜你喜欢”,对用户来说,是非常贴心的了,随之而来是较高的转化率。
第三,基于内容的推荐可以解决冷启动的问题。在最开始做推荐的时候,往往没有大量且有效的用户行为数据的,无法实现协同过滤等更加高级的推荐方式,只能利用商品本身的数据做内容推荐。更多关于冷启动的内容,会在后面介绍。
需要注意的是:在特定场景中,基于内容的推荐也存在很多问题。
比如:电商推荐会根据用户购买记录,推荐一些同款或者类似的产品。对于那些手机、单反相机等低频购买行为,重复购买率很低,最好的展位就这样被浪费掉了,机会成本非常大,这就需要更多的算法优化来改进基于内容的推荐,比如用户可以手动过滤一些不想看到的内容等。
三、协同过滤(Collaborative Filtering,CF)
1. 什么是协同过滤
如果你想看个电影,但不知道看哪部,你会怎么做?
可能直接找个热门的电影,这是基于热度的大众推荐;可能会找科幻、爱情类型的电影观看,这是基于内容的推荐;还可能问问周围的人,看有没有什么好看的电影推荐,周围有朋友、同事甚至父母,但我们一般不会找父母推荐,而是找朋友推荐,因为我们喜欢的电影很可能是类似的,这也是协同过滤的核心思想。
前面讲的基于内容的推荐,只利用了内容之间的相似性,在冷启动或者用户数据较少的情况下,可以使用。有了用户(User)数据,比如点击、购买、播放、浏览等操作,就可以投其所好,推荐用户感兴趣的文章、音乐、电影或商品,统称为物品(Item)。这就是协同过滤。
按照计算相似度采用的标准不同,协同过滤主要分为:基于用户的协同过滤(User-based Collaborative Filtering,User-based CF)和基于物品的协同过滤(Item-based Collaborative Filtering,Item-based CF)。
基于用户的协同过滤通过计算用户之间相似度进行推荐,基于物品的协同过滤通过计算基于物品之间相关度进行推荐,这有些拗口,具体的内容会在后文介绍。
2. 数据获取
由上面的分析,我们可以发现:无论是用户的相似度计算,还是物品之间的相关性的计算,前提都是要有大量的数据。
那么,如何收集数据呢?
“当你在看风景时,你已成为别人眼中的人风景”,当你刷新闻APP的时候,后台也在默默记录你的点击的新闻、观看时长、点赞、评论等信息。
比如:新闻APP可能会记录,用户小明,早上8点半打开了APP,此时使用4G网络,同时GPS定位在持续快速移动,他先浏览了首页的推荐新闻,点击了20条,点赞了5条,单个新闻停留最长时间为3分钟,之后打开了“财经”板块,发表了3条评论,快到9点的时候,小明关闭了APP。
同样的,当你逛电商APP的时候,后台也会默默记录你点击、浏览、看评论、加入购物车、购买等行为。
比如,电商可能会记录,用户小红,晚上10点用iPhone打开了APP,此时使用WIFI,GPS定位稳定,她先浏览了首页的个性推荐,点击了几个热销的女装,之后在搜索框输入了口红,在浏览了18支口红之后,她点击进入了购物车,把2天前加入购物车的高跟鞋结算了,使用花呗支付,晚上11点,小红关闭了APP。
数据获取有几个需要注意的问题。
首先,是数据量的问题。针对每一个用户,需要记录几乎所有的操作,无论是隐性还是显性操作,偏好还是厌恶行为,都要把这些行为数据上传到服务器。如果一个APP有几亿的用户,同一时刻可能有上百万的在线浏览量,数据量之大可想而知,遇到双十一、春晚等高流量场景,服务器可能一下子就宕机了。
其次,如何确定用户身份的问题。一个用户可能有多个手机;可能使用微信、QQ、手机号、邮箱、微博、淘宝等不用方式登录;可能使用手机APP,也可能使用电脑浏览器。同一个用户不同终端、账号的信息要同步,这样才能准确地计算用户特征。APP通常会鼓励用户同时绑定微博、微信、手机等账户,很大程度上也是为了确定用户的身份。
第三,数据的进一步清洗。比如因为网络中断,用户在短时间内产生了大量点击的操作,或者手机闪退,造成的信息丢失。这都需要针对每一个情况,具体分析,甚至需要针对每一种情况单独写代码应对,工作量之大,可想而知。
第四,还有难以避免的隐私问题。记录GPS、上传通讯录、访问内容等算是APP的常规操作,不断有APP被曝出偷偷录音、拍照等行为,某互联网大佬,在论坛上演讲直接说出,“多数情况下,中国人愿意用隐私交换便捷性”, 引起舆论哗然。隐私问题,无法仅仅依靠技术来解决。
3. 基于用户的协同过滤(User-Based CF)
基于用户的协同过滤,通过用户对不同物品的偏好,计算用户之间的相似度,之后基于用户的相似度进行推荐,本质上就是将类似的用户偏好的物品推荐给当前用户。
亚马逊的 “浏览词商品的顾客也同时浏览”就是User-based协同过滤的典范。比如:在亚马逊上搜索《统计学习方法》这本书,系统会推荐浏览《统计学习方法》这本书的人,也同时浏览《机器学习》《深度学习》等书。

基于用户的协同过滤计算分两步:第一步,根据用户行为,计算用户的相似程度;第二步,把与当前用户类似的用户喜欢的物品推荐给当前用户,这句话同样拗口,可以参考下图。
计算用户的相似度,与前文计算内容之间相似度的方法基本一样,最常使用的是余弦相似度,通过计算用户之间的余弦距离,判断用户相似程度。
比如下表,代表不同用户对不同物品的喜好程度。

首先,计算用户的相似度。用户A、用户C都喜欢商品1、商品3,但与用户B基本没有什么交集,所以,用户A和用户C比较相似。
之后,我们可以把相似用户喜欢的物品互相推荐给对方。比如:用户C喜欢物品4,而用户A没有买过,我们就把物品4推荐给用户A,实现了推荐的过程。

这里需要注意的是:我们没有必要根据用户C喜欢物品3,就把物品3也推荐给用户A ,因为物品3已经是用户A喜欢的,这里没有必要重复推荐。
4. 基于物品的协同过滤(Item-Based CF)
基于物品的协同过滤,通过分析用户的记录,计算物品之间的相关性,推荐与当前物品类似的物品。
基于物品的协同过滤有个经典的案例:超市巨头沃尔玛发现购买啤酒的人同时也会购买纸尿布,于是,就把啤酒和纸尿布放在一个货架上,在这里,啤酒和纸尿布具有很大的相关性。
基于内容的推荐(Content-Based Recommendation)、基于物品的协同过滤(Item-Based Collaborative Filtering),两者有些类似,都需要计算物品之间的关系,但两者也有很大的不同。
基于内容的推荐,本质是计算内容本身的相似度。其中最大的问题是:我们无法通过用户喜欢的音乐,给他推荐类似的电影;用户购买了电视,我们无法给用户推荐空调。
基于物品的协同过滤,本质上是通过用户行为,计算相关性。不需要计算音乐和电影的相似程度,喜欢某首歌的人,也喜欢看某部电影,我们就说这首歌和这部电影有相关性;用户购买电视的时候,很多时候也会顺便购买空调,我们就判断电视和空调具有相关性。
基于物品的协同过滤,同样有两个步骤:第一步,根据用户行为,计算物品的相关度;第二步,根据用户的偏好,推荐相关的物品给他。
相似度的计算是都是类似的,通常情况下直接计算余弦距离就可以了。这里着重讲一下推荐的过程。
如下表所示:物品1同时受到用户A、用户B、用户C喜欢,物品3同时受到用户A、用户B喜欢,而物品2只有用户B喜欢,我们可以发现物品1和物品3有某种相似性或者相关性。我们就可以把物品3推荐给用户C,这里同样要避免重复推荐。


User-Based CF 和Item-Based CF是协同过滤的两个最基本的算法,有各自的适用场景。User-Based CF计算用户之间的相似度,适用于用户较少的场景,Item-Based CF计算物品之间的相似度,适用于产品较少的场景。
User-Based CF很早以前就提出来了,Item-Based CF是从 Amazon 的论文和专利发表之后(2001 年左右)开始流行,其中的一个主要原因是亚马逊提供很多都是自营服务,商品数量有限,商品的数据也比较稳定,计算起来比较方便。相比之下,用户的数据就很多,而且分散,计算速度比较慢。
但对于新闻、影视等内容推荐系统,或者淘宝等电商平台,情况正好是相反的,物品的数量很多,更新频繁。相比之下,用户数量就相对较少并且比较稳定了。在这种情况下,就比较适合User CF推荐系统。
5. 协同过滤的特点
协同过滤的优势显而易见。
首先,在于充分利用了现有的数据,从而可以挖掘出更多的信息。比如:前面所说的纸尿布和啤酒的相关性,使用基于内容的推荐无论如何也是计算不出来的。
其次,协同过滤可以更加直观地展示推荐理由。让人信服的理由,总能激发人们的点击和购买的欲望。比如:亚马逊在推荐页面显示“浏览此商品的顾客也同时浏览”就比较有说服力,用户购买的可能性就比较大。使用基于内容的推荐或者更高级的基于数学模型的推荐算法,往往不能简洁清楚地说明推荐理由,总不能显示“根据计算新闻之间的相似度,这篇新闻和某篇新闻比较相似,推荐给你”。
但,协同过滤也存在一些问题。
首先,是数据的问题。在用户冷启动或者产品上新时,因为没有数据,协同过滤就无法实现推荐。与此同时,大量的数据随着而来的是较大的计算量,在一些实时推荐系统中,应用受到一定限制。
第二,是用户喜好的变化。不少追星族可能会三天两头换一个明星追,在推荐领域,也存在类似的问题。协同过滤通过历史数据计算用户的爱好、用户之间的类似程度,这就存在一个基本假设:用户会喜欢和他以前喜欢的相似的东西,但用户的爱好会随着时间、新产品的出现、营销等发生改变。
甚至在某种程度上,推荐系统本身就在有意无意地影响用户的喜好,典型的社交电商会通过各种方式“种草”新的流行产品。
6. 50行代码实现Item-Based协同过滤
import pandas as pd
import numpy as np
# 原始数据
data = {‘张三’: {‘小时代’: 2.5, ‘大圣归来’: 3.5, ‘无双’: 2.5},
‘李四’: {‘小时代’: 3.0, ‘我不是药神’: 3.5,’致青春’: 1.5, ‘霸王别姬’: 3.0},
‘王五’: {‘小时代’: 2.5, ‘大圣归来’: 3.5, ‘霸王别姬’: 4.0},
‘赵六’: {‘我不是药神’: 3.5, ‘致青春’: 3.0, ‘霸王别姬’: 4.5, ‘无双’: 2.5},
‘小甲’: {‘致青春’: 2.0, ‘大圣归来’: 3.0, ‘无双’: 2.0},
‘小乙’: {‘我不是药神’: 4.0, ‘霸王别姬’: 3.0, ‘无双’: 3.5},
‘小丙’: {‘我不是药神’: 4.5, ‘无双’: 1.0, ‘大圣归来’: 4.0}}
#读取数据,清晰数据,数据归一化[0,1]
data = pd.DataFrame(data)
data = data.fillna(0)
mdata = data.T
np.set_printoptions(3)
mcors = np.corrcoef(mdata, rowvar=0)
mcors = 0.5 + mcors * 0.5
mcors = pd.DataFrame(mcors, columns=mdata.columns, index=mdata.columns)
#计算user-item评分
def cal_score(matrix, mcors, item, user):
totscore = 0;totsims = 0;score = 0
if matrix[item][user] == 0:
for mitem in matrix.columns:
if matrix[mitem][user] == 0:
continue
else:
totscore += matrix[mitem][user] * mcors[item][mitem]
totsims += mcors[item][mitem]
score = totscore / totsims
else:
score = matrix[item][user]
return score
#计算物品之间的相关性
def cal_matscore(matrix, mcors):
score_matrix = np.zeros(matrix.shape)
score_matrix = pd.DataFrame(score_matrix, columns=matrix.columns, index=matrix.index)
for mitem in score_matrix.columns:
for muser in score_matrix.index:
score_matrix[mitem][muser] = cal_score(matrix, mcors, mitem, muser)
return score_matrix
#根据物品相关性,进行推荐
def recommend(matrix, score_matrix, user):
user_ratings = matrix.ix[user]
not_rated_item = user_ratings[user_ratings == 0]
recom_items = {}
#排除用户已经看过的电影
for item in not_rated_item.index:
recom_items[item] = score_matrix[item][user]
recom_items = pd.Series(recom_items)
#推荐结果排序
recom_items = recom_items.sort_values(ascending=False)
return recom_items[:1]
score_matrix = cal_matscore(mdata, mcors)
user = input(‘请输入用户名:’)
recom_items=recommend(mdata, score_matrix, user)
print(recom_items)
如果你的电脑有Python环境,运行这个程序,按照提示输入,就可以看到输出结果:
你可以对这些Python语言不太了解、对编程也不太感兴趣,但你不用知道每行代码用什么用,如何运行这些代码,只需要有个直观的印象,直观了解程序员每天的工作——协同过滤原来是这么做的呀。
首先获取User-Item信息,进行数据处理,计算用户或者物品之间的相关性,最后进行推荐就好了。每一个步骤都可以用一个代码模块写出来,之后汇总到一起就可以了。
在实际写代码的过程中,也有开源的解决方案可以使用,在开源解决方案的基础上,可以在较短的时间内、花费较短的成本,获得可靠的解决方案。
当然,现实中的推荐系统没有这么简单,应用场景不同,使用的算法、系统的配置也不尽相同,程序员要花很多时间在系统的配置上,这个我们在最后会讲到。
四、现实中的推荐系统
1. 如何实现冷启动
在推荐系统中,数据积累量较少,无法给新用户或者新产品做个性推荐,这就是冷启动问题。没有用户数据,就没办法推荐;没有更好的推荐,用户留下的数据就很少,这也是一个先有鸡还是先有蛋的问题。
冷启动问题基本可以分为两类:用户冷启动和物品冷启动。顾名思义,用户冷启动指如何给新用户进行个性化推荐。
物品冷启动指:如何将新的物品推荐给可能对它感兴趣的用户?
产品经理、程序员、创业者想了很多办法来解决冷启动问题,最常见的两种解决办法。
第一种解决方式是:大众推荐。
通常20%的产品获得了80%的关注和流量,给用户推荐一些热门产品,比如:热搜榜、热销榜等,点击率也不错,通过这种方式,可以满足用户的基本需求。对于一些新上架的商品或者新的音乐,也会有新品榜单独推荐,以此解决物品冷启动的问题。
第二种方式是:尽可能获得更多的信息。
比如:在用户注册时候,激励用户绑定微博账号,从微博的数据接口,可以发掘用户的一些偏好;激励用户选择一些感兴趣的博主或者板块,可以直接获得用户的喜好;利用用户注册时填写的年龄、性别、手机号码(归属地)甚至教育程度等信息,也可以获得很多有用的数据。
一些APP或者网页也会开发出有趣的测试,获得用户的偏好。

2. 位置和时间约束
地理位置约束:
在很多情况下,地理位置是推荐系统最常见的一个约束,不少外卖、本地电商等平台,在排序中也有距离优先的选项。比如:我们使用本地电商平台找餐厅,通常情况下,我们不会跑大半个城市吃饭,所以APP会推荐较近的餐厅。
那么,如何实现基于地理位置进行个性推荐呢?
常见的方式是在排序的时候,对距离添加一个权重,如果距离越近,相应的权重越高,排名越靠前。比如:我们在杭州火车站搜索餐馆,会优先推荐附近的,这也是搜索引擎和个性推荐的一个交集。
为了加快计算速度,通常会采用树状存储,比如:下面这张图,可以通过杭州、上城区、火车站,快速找到火车站范围内的餐馆。

时间约束:
在协同过滤中,我们讲到,用户的喜好可能会随着时间发生改变,比如:电商产品在卖衣服时,冬天推荐的衣物和夏天推荐的衣物是不同的;上班时候上看的新闻跟下班看的也可能不一样。这就要求我们在进行推荐的时候,把时间这个因素考虑进去。
最常用的处理方式,是在推荐中添加跟时间相关的权重。比如:用户一个月前加入购物车跟今天加入购物车的行为应该有不同的权重,今天的行为权重更高,在个性推荐时,应更多地根据今天的行为进行推荐,这也是电商APP实时更新推荐商品的重要方式。
实时热榜,也是利用时间约束的一个范例,用户可以关注时下最流行的新闻、衣服、电影等,阅读时长、购买转化率等都会有很大的提高。比如:微博的Slogan就是“随时随地,发现新鲜事”,把热点利用到了极致。

3. 推荐系统架构

融合:
在实际使用中,单独使用一种推荐系统无法解决所有的问题,推荐系统需要将用户的行为、物品的特征、时间和地理条件等考虑进去。通常情况下,推荐系统会同时使用基于内容的推荐、协同过滤、基于时间的推荐等作为推荐引擎,之后,对这些推荐结果进行按照一定权值进行合并。
这样的好处非常明显,每一个推荐引擎都实现了特定的目的,相当于解耦合,降低了系统的复杂度,我们可以单独调整某个模块进行优化。
需要注意的是:推荐引擎也会添加一些大众推荐或者随机推荐,以增加系统的多样性,给用户带来新鲜感。同时,在某种程度上也可以避免“信息茧房”的道德指责。比如推荐音乐,如果完全按照用户的习惯进行推荐,结果往往就局限在一个很小的范围——听民谣的人,可能永远不会被推荐摇滚,这就需要加入大众推荐或者随机推荐,适当拓展推荐的内容。
过滤:
过滤是对初始的推荐结果进行处理,这里主要有两个方面的过滤。
一方面,为了针对实际需求,对推荐结果进行筛选。
最常见的是过滤热门的物品,比如:TFBOYS新出了一首歌,成为爆款,很多年轻人都听过,再把这首歌推荐给用户可能就没有什么意义。
除此之外,还需要过滤用户已经看过的新闻、电影、购买过的商品,比如:我们已经买了一款手机,电商APP还在一直推荐,我们就会觉得这个APP很傻。针对一些质量差、评价低的商品,也可以有选择的过滤,比如电商APP会折叠一些低质低价的商品。
另一方面,是合规的需求。
无论是什么产品,都要合法合规,今日头条等不少内容平台,也加大力度,对热搜、推荐进行审查。
比如:今日头条成立早期,官媒就连发评论,批评其让用户困在信息茧房,低俗内容污染网络生态,字节跳动旗下内涵段子就被广电总局永久关停。为此,今日头条张一鸣公开道歉,声称要传播正能量,符合时代要求,尊重公序良俗。
4. 现实中的推荐系统
个性推荐系统可以提高用户体验,增加用户使用时长,提高销量,但在实践上,根据应用场景和数据规模的不同,系统的差异也非常大。
对小型的网页或者APP而言,由于成本、内容数量、技术的限制,很可能是不进行个性推荐的,运营人员直接编辑推荐或者通过热度进行大众推荐,可以满足一般的使用。
对于稍大些的网页或者APP,可能在单个或较少的服务器上就可以搭建出推荐系统,每天进行离线特征提取、模型训练,训练完成之后,再上线运行。对于这类需求而言,有成熟的开源推荐系统可以使用,比如Spark的机器学习(Machine Learning,ML)模块可以直接使用。

离线数据处理,对一段时间(比如一天)的数据进行集中计算,对于用户今天的操作,可能第二天才会更新模型,并进行个性推荐。离线数据处理实现起来比较简单,但速度慢是硬伤。与离线数据处理对应的是在线处理,两者最大的差别是数据处理是不是实时的。
比如:我们点击商品之后,个性推荐就会实时更新,这个是根据用户的数据,实时进行处理。在线数据处理要求实时记录用户行为、上传到服务器、进行推荐、之后再反馈给用户,完成整个过程可能只有50ms的时间,眨眼的时间200ms,真真一眨眼的功夫就计算好了。
对于大型的信息或者电商平台,可能有百万的用户同时在线,数据量也急剧上升,通常采用实时数据处理和离线数据处理相结合的方式。
由前面章节的介绍,我们知道:当用户数据量增加十倍,系统的复杂度可能不是十倍增加,而是上百倍的增加,甚至直接演变成了另外一个系统。
复杂系统的每一个环节都有可能成为系统的短板,进而拉低整个系统的运行效率,所以就需要对整个系统进行重新开发。大多数时候也不是简单的推倒再来,而是在现有基础上进行的修改,这就像在老城区开发一样,既要维持现有的秩序,又要满足不断增长的流量需求。
对于大数据离线处理而言,单个服务器的数据存储容量、处理速度有限,通常使用几十甚至上百个服务器同时进行数据存储和计算,如同上百人的大公司一样,人与人之间的交流和分工,要耗费大量的时间和精力。
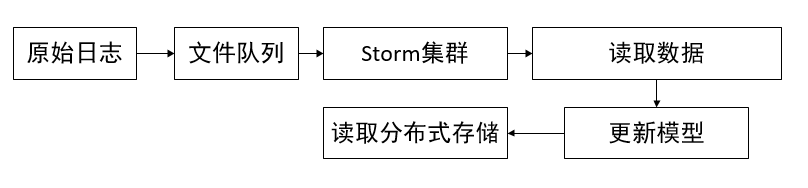
上百服务器通常作为一个集群,使用分布式管理,比如:使用开源的工具Hadoop作为整个分布式系统的基础架构,使用Hive进行分布式存储,使用Spark进行分布式计算和数据挖掘。
幸运的是,这些优秀的工具都是开源的,这也是互联网发展速度非常快的重要原因。相比之下,不少行业更加封闭,一个公司老员工、新员工之间的技术交流尚且不畅,更别说不同公司之间的技术共享了。
对实时数据处理而言,处理速度是最大的追求,通常使用“流”式处理,就像生产工厂的流水线一样,数据实时从用户传到服务器集群,服务器对接收的数据处理、更新模型、保存结果,客户端实时获取这些更新。
大规模的数据处理,特别是实时处理,要花不少时间在系统的架构、调试上,还要时不时面对流量过高的宕机风险,这种情况下进行个性推荐,有时候,难度可能不在推荐算法本身。
本文由@linghu 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash, 基于CC0协议










请问 {‘小时代‘: 2.5, ‘大圣归来‘: 3.5, ‘无双‘: 2.5},这里面的2.5,3.5是怎么计算出来的呢?
“常用的关键词获取技术是上一章《搜索引擎》所讲的TF-IDF(Term Frequency–Inverse Document Frequency)模型,通过分词、去除关键词、计算每个词出现的频率获得TF” —–>应该是通过分词、去除停用词/功能词、计算每个关键词吧
干货,正在学习中!
满屏都是干货
受益匪浅,请问在推荐系统这方面,有什么书或者课程可以学习吗,先谢谢啦?
2012年有本《推荐系统实践》,不过都是比较传统的推荐方式了,现在很多都转深度学习了,相关的书籍和课程还比较少。
好的,谢谢~
难的干货
真是一篇好文章