
 起点课堂会员权益
起点课堂会员权益常见的A/B测试误区分析:重复检验显著性
避免重复检验显著性错误的最好方式就是不去重复地检验显著性。
一、一种常见的A/B测试误区
如果网页正在运行A/B测试的时候,你时不时地去查看试验结果的显著性,你就会陷入误区。
统计学上,重复检验显著性是错误的行为。这样做的后果是,即使数据报告显示统计显著,实际上仍有较大可能性非统计显著。下面解释原因。
二、背景
当A/B测试的数据面板显示“95%可能性比原版本有提升”,或者“90%可能统计显著”,需要考虑如下的问题:假如A版本和B版本没有潜在的差别,我们能看到数据中显示出区别的可能性有多大?
这个问题的答案就是显著性水平,“统计显著的结果”意味着显著性水平数值比较小,5%或1%。数据面板一般会取补集(95%或99%),作为“优于原版本的概率”或类似的东西来报告。
然而,显著性水平的计算有严格的假设:样本数量的多少是事先指定的。你很可能违反了该假设而不自知。如果开始试验之前你没有“本次试验将采集1000个样本”这样的预期,而是打算“一看到统计显著的结果就结束”,那么上报的显著性水平将毫无意义。这一结论完全反直觉,大量A/B测试工具忽略了这一点。下面会用一个例子解释问题出在哪里。
三、例子
假设你在样本量达到200和500时对试验进行分析,4个可能发生情景如下:

假设AB版本效果相同,显著性水平为5%,那试验结束时,我们有5%的可能性得到统计显著的结果。
而如果我们一观察到显著结果就停止试验,事情会像下面这样发展:

第一行和之前一样,收集200个样本之后报告的显著性水平没啥问题。然而问题出在第三行,试验结束时,假设AB两个版本实际效果相同,我们得到统计显著结论的比例上升了。因此,显著性水平——用来衡量因为运气因素观察到区别的概率,将是错误的。
四、问题有多严重?
如果你的转化率是50%,想测试一下新的logo是否能把转化率提升到50%以上。你打算观察到5%级别的统计显著性就停止试验,否则在收集150个样本后停止试验。
假设新logo没有任何影响,得到错误的统计显著结果的概率有多大?不过5%?根据前面的分析,也许是6%?
结果是26.1%——比你预计的显著性水平的5倍还多。这是最差的情况,因为我们每收集一个新样本都检查统计显著性(也不是没有这样先例)。至少有一家A/B测试平台确实提供在出现统计显著就停止试验的功能。听起来这是个巧妙的花招,直到你意识到在统计学上这是恶习。
重复进行显著性检查总会增加虚报概率,也就是说会把许多本来非显著的结果变成显著(而不是反之)。只要你有“偷窥”数据,发现统计显著就结束试验的行为,该问题就会存在。偷窥地越频繁,显著性水平偏差越大。
例如,在试验过程中偷窥10次,表面上是1%的显著性实际上仅是5%的显著性。下面的表格展示了在有偷窥的情况下,数据报表中的显著性需要达到多少才能有实际上的5%显著性。
偷窥次数达到实际显著性水平5%时,所需要的报告显著性水平:
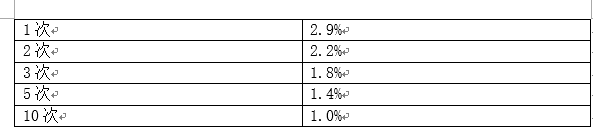
看一下自己犯了多大的错误,如果你在A/B测试过程中不时地查看统计结果并快速的做决定,上面的表格会让你起鸡皮疙瘩。
五、应该如何做
避免重复检验显著性错误的最好方式就是不去重复地检验显著性。
事先决定样本数量,等试验结束后再去A/B测试软件中查看“优于原版本的概率”。如果你能抑制提前结束试验的想法,那中途偷窥数据也无妨。这有些反人性,所以最佳建议还是不要偷窥。
既然要事先决定样本数量,应该取多少呢?下面是经验公式:
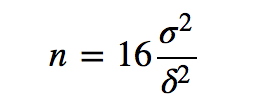
δ是能检测到的最小变化,σ是样本的标准差。样本的标准差可能不好预知,但是如果参与计算的样本取值是2值的(比如统计转化率),则有:
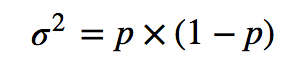
保证样本的规模就能避免问题。
对A/B测试软件的建议:在试验结束之前不要报告显著性水平,不要用显著性水平来决定是继续试验还是停止试验。试验进行中不报告显著性水平而是报告目前样本数量能检测出多大的差别,计算公式为:
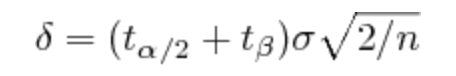
两个t是给定显著性水平α/2和统计功效1-β的t统计量。
听起来痛苦,你甚至可以考虑把试验效果的“当前估计值”去除掉,直到试验结束再显示。如果该信息用于提前结束试验,则报告的显著性水平毫无意义。
如果你真想把这事做对:事先固定样本大小可能令人沮丧,如果改动后效果确实不错,难道不应该立刻部署吗?
这个问题长期困扰着医学界,因为医学研究人员通常希望在新的疗法看起来有效时停止临床试验,但是他们还需要对其数据进行有效的统计推断。下面是两种用于医学试验设计的方法,有些部分应该也适用于网页试验:
- 序贯分析试验设计:序贯分析试验设计让你可以预先设定检查点,决定是否继续试验,给出正确的显著性水平。
- 贝叶斯试验设计:贝叶斯试验设计让你可以随时停止试验并给出正确推断。实时反映网页试验的状态,贝叶斯方案看起来是未来发展方向。
六、结论
虽然数据面板看起来很强大和方便,但在进行中的A/B测试中被滥用。任何时候,当它们与手动或自动的“停止规则”结合使用时,显著性检验结果会无效。除非在软件中实现序贯分析或贝叶斯实验设计,否则任何运行网页试验的试验者都应该只在样本量已经提前固定的情况下进行试验,并且像虔诚的教徒一样坚持该样本量。
作者:祁永辉,微信:yonghuishuo,吆喝科技增长顾问,专注于A/B test相关知识分享
本文由 @祁永辉 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









额,翻译的还行
emmm 这篇文章是翻译的Evan Miller的文章吧,怎么就成原创的了呢。。
QQ群