
 起点课堂会员权益
起点课堂会员权益如果你应聘微信产品经理,怎么回答这道面试题?

问题源自知乎问题,感兴趣可以知乎搜索「关于微信的产品面试题,产品经理来答答?」,我从中选取了一个问题,加了一点自己的思考,发出来探讨一下。
朋友圈的基本数据结构设计是怎么样的?既能做到完美的阅读权限设置,又能兼顾性能?
题目本身给出了两个重点,「阅读权限」和「性能」,考察产品经理思考问题的全面性和对技术的了解程度。
首先梳理一下朋友圈的几个功能特点:
- (0)基础存储功能,可发布视频、链接、纯文本、图文消息。
- (1)异步发布,即时用户交互行为反馈。在网络情况较差时可以先提交任务(如发布朋友圈、点赞、评论),无需等待任务完成。
- (2)可选择部分用户可见,也就是题目中说到的权限。
- (3)对某些用户可见的权限,除了用户主动选择的,还有系统层面的过滤器,比如某些违反微信运营规定的活动链接可被系统限制在朋友圈中传播(也就是你发了之后只有你自己能看到,别人看不到)
- (4)新消息通知主动push,无需刷新界面,新消息可自动push;新朋友圈需要刷新才能看到。
问题(0)和(1)与阅读权限设置没有多大关系,与性能有一点点关系,但并不是本文讨论的重点。这个面试题我们可以围绕「阅读权限」和「性能」这两个基本点,对(2)、(3)、(4)三个点进行探讨。
回答问题(2)时,我们可以从微信提供的功能上找到一些设置阅读权限的蛛丝马迹。
1)互为好友关系,是好友关系才能看到对方朋友圈,这是第一前提。
微信的朋友与朋友之间的关系虽然是双向的,如A和B要成为朋友,A需要给B发送好友申请,当B通过A的申请时A才能看到B的朋友圈。
此时,A与B虽然存在好友关系,但彼此有一份独立的通讯录,互不干扰。比如A把B从朋友圈删除时,B会在A的通讯录列表里消失,但A不会在B的通讯录列表里消失,当B给A发信息时才能发现双方已非友好关系。
2)不在黑名单内,才能给对方发送消息并且能看到对方的朋友圈。
黑名单是介于「关系正常」和「删除」之间的一种关系,双方的好友关系还被保留,比如A把B拉黑了,有如下表现:
B无法给A发送消息,也看不到对方朋友圈的任何内容。
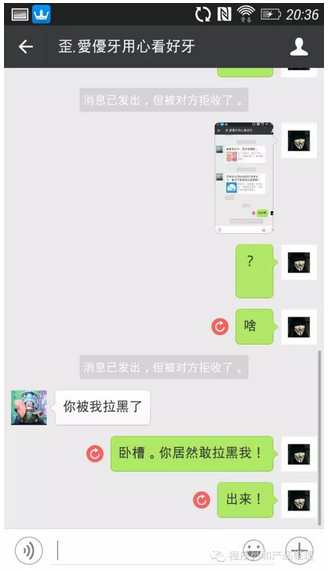
因为A主动拉黑B,A可以看到B的历史朋友圈,但看不到拉黑后更新的内容。

3)申请加为好友时,选择「不让他看我的朋友圈」开启或关闭。
不让看朋友圈是介于黑名单和正常关系之间的一个状态,如果互相加为好友时,被选择了「不让看朋友圈」,你是不能看到对方朋友圈的更新的。
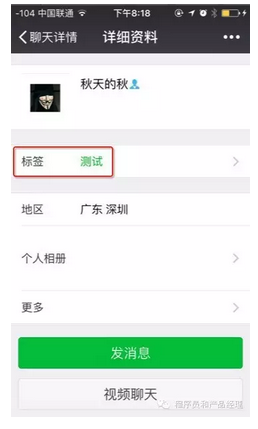
4)通讯录朋友标签化。
我们可以在微信提供的功能上找到「标签」,这个标签除了对朋友属性进行标记(如你可以把某个微信联系人标记为老板、同事)外,还可以在发布朋友圈时选择带某标签的朋友可见或不可见。
微信基于此构建了朋友圈和通讯录的权限体系,那在具体技术实现上是什么场景呢?
我认为,微信朋友圈的权限是在朋友关系和朋友圈内容有写操作的时候进行下发的,也就是当用户发布内容或对关系进行修改时,就会下发朋友圈的内容可见状态,按照权限优先级分为三种下发情况:
- 非好友、黑名单关系是实时触发的。一经修改,所有内容实时生效。
- 标签关系也是实时触发的,但不会因为修改标签的动作而对已发布内容是否可见产生变化。比如你发了一条朋友圈,对打了标签的A和B两个好友可见,C当时还不在可见标签内。发布完成之后修改C的标签为可见,C仍然看不到这条朋友圈。除删除状态和取消点赞,朋友圈是不具备修改、编辑功能的。
- 对于违规的朋友圈内容,微信会限制内容在朋友圈传播,这个限制是系统限制,是异步进行的。比如你发布了一个受限的链接,发布之后在很短的时间内(1-2分钟内)朋友是可以看到这条链接的,但随后这条链接马上会被屏蔽,这样异步处理的初衷大概是 “把部分复杂的但不是最高优先级的权限计算发送到闲散的客户端或机器资源上去做”,保证核心的阅读体验不会受到影响。
以上便是一些权限处理上的策略,接下来我们来讨论一下,用什么样的技术手段或者存储方式,来支持这些复杂的权限下发和阅读权限控制。
在timeline(时间流)或feeds流的产品技术实现上常用到一个算法叫「混排算法」,顾名思义就是结合了一系列的影响因子,把用户发布的状态/信息 实时分发到好友关系链里,感兴趣的朋友们可以使用谷歌学术搜索timelime cache等关键字自行检索。
这些存储计算使用的技术肯定不是我们平时说的数据库,而多用一些分布式存储、持久缓存技术作为工具,比如Memcached、Redis等。
我们大胆猜想微信朋友圈的实现也使用了Redis,或者类似Redis系统的Key-Value键值对存储系统。

一条条的朋友圈状态在用户的权限列表里是以key-value的形式存在的,每个用户的 timeline 是由一个 Redis list 来维护, Redis list 存放着经过上面权限策略过滤之后可见好友发布的朋友圈的 ID。每当一个用户发布朋友圈时, 会把这条朋友圈的 ID 推到有权限阅读的好友的timeline 中(也就是存储到Redis list 里)。当用户刷新自己的朋友圈时,只需要到自己的Redis list 里拉取到对应的朋友圈列表,然后再比对本地缓存,决定该朋友圈是否要显示或重新请求。数据格式大概如下:#{user_id}/#{post_id}(发布朋友圈的用户ID/该朋友圈的ID)”
Redis_List = [“10010/100111”, “10020/103111”, “10030/140111”, “100210/100786”, “100233/100444”]
同样的,点赞数、评论数、自己是否点赞等与某条朋友圈的关系,也是存储在Redis List里。
虽然朋友圈内容是不会变的,但是点赞数和评论数目可是实时变化的哟。每一条朋友圈都会要获取这条动态获得了多少赞、有多少条评论、自己是否点赞。而这三个属性都是从 Redis 中读取出来的。也就是说如果这个接口返回了 20 条动态的话, 我们需要调用20*3次= 60 次 Redis。这似乎也是不可以接受的,特别是有一些人好友比较多、互动比较频繁的,有时候还需要主动给用户推小红点提醒有新消息更新,这些人所在的机器性能就会告急。
所以,微信的这道面试题提到了「性能」这个点。
这里,可以可以考虑使用时间戳来标记上一次动态更新的时间。比如,当用户在发布新的朋友圈信息时,如果跟当前用户有新的互动(比如回复了你的评论、给你点赞了),上一次更新的时间戳就会发生变化,并主动更新到用户相关的各个Redis List里。当发现客户端发现上次更新的时间戳和本地时间戳不一样时,可以主动更新获取信息,否则保持不动。
调整对象结构为 用户ID=>[状态,上次更新时间戳]
{ ‘10010’ => [‘200101′,’123453454’], ‘10011’ => [‘200102’, ‘12345345435’], ‘10021’ => [‘200103′,’12345345435’], ‘10031’ => [‘200104′,’12345345435’]}
额,讲到这里,很多同学没看懂?
看吧,产品经理懂一些技术还是好一点的吧。^_^
好了,以上是一位产品经理作为旁观者对微信朋友圈数据结构设计的一些思考,希望对大家思考有所帮助。许久不写技术文章,如有错误,欢迎留言指正。
本文系作者@歪 (微信公众号:程序员和产品经理)授权发布,未经许可,不得转载。









如果对方开了陌生人可以浏览10条朋友圈,有些内容还是可以看到的
后面基本上看不懂,尴尬
路过纠正一下:在微信平台,非好友关系也能看到对方的朋友圈。这也是权限范围的功能
发现看不懂,但学到了微信这种机制思想 😉
这是产品分享还是技术分享
没看懂数据结构 讲技术没有多全面
你是开发转产品吧,有点深奥。
果然任何一个牛逼的产品都不是简单实现的👍👍👍
分析很深入很全面,微信的产品逻辑好深奥呀
1.
表示看不懂代码,不明觉厉,厉害了,我的大神
赞一个,微信的产品逻辑恰到好处。不过后面的一部分有点炫技了
😆 😆 😆 😆
留个脚印来看看
赞同,微信的缓存设计结构理念,有点类似新浪微博。尝试一下看看,做个REDIS数据结构,来设计微信朋友圈。转产品中,不过码农的老本忘得快差不多了,哈哈
有点扯
1、这个点上怎么可能成为性能瓶颈?性能问题取决于实现模型,腾讯用的肯定是分布式计算,在服务端的鉴权如何会引起性能问题
2、这个点上关注的应该是权限的业务模型,不要零碎的场景化,而应该有一个贯穿始终的“权限主线”
我也觉得
厉害,数据结构都忘的差不多了
😈 😈 😈