
 起点课堂会员权益
起点课堂会员权益AI产品经理必修课:知识图谱的入门与应用
知识图谱是AI的基础功能,本篇文章笔者就知识图谱是什么?如何构建知识图谱?怎么应用?进行了讨论分析,与大家分享。

一、人工智能时代已经来临
伴随着全球智能手机销量的首次下滑,移动互联网已经不可避免地步入了下半场。
与此同时,智能音箱销量爆发式增长,ZAO换脸APP刷屏朋友圈……人工智能技术正在越来越深刻地影响人们的日常生活。
作为人工智能领域的核心技术之一,知识图谱已经成为了AI产品经理必须掌握的基础技能。
二、什么是知识图谱?
1. 什么是知识?
在聊知识图谱之前,我们先简单了解下什么是知识。
下图是在Quora(国外版知乎)上关于信息与知识的对比图。
信息是杂乱无章的点,而知识相对来说更有逻辑性。在当今这个信息爆炸的时代,知识对人们来说显然更便于理解和记忆。
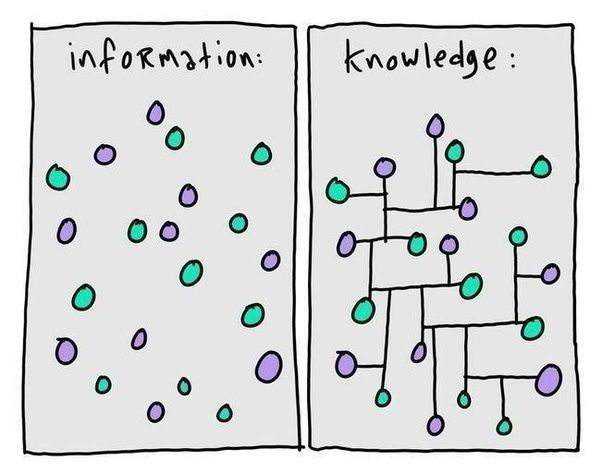
图一,图片出处:https://www.siilo.com/blog/information-vs-knowledge
2. 什么是知识图谱?
知识图谱(Knowledge Graph,简称KG)的概念由Google在2012年5月提出,初衷是希望借助网络多源数据构建的知识库来增强语义搜索的效率和质量。
Google知识图谱团队负责人Amit Singhal认为,“The world is not made of strings,but is made of things”。
知识图谱的主要作用在于以结构化的方式来描述客观世界实体间的复杂关系。通过在信息与信息之间建立联系,人类更加容易获取自己所需要的知识。
3. 维基百科关于知识图谱的介绍
知识图谱是Google用于增强其搜索引擎功能的知识库。
本质上, 知识图谱旨在描述真实世界中存在的各种实体或概念及其关系,其构成了一张巨大的语义网络图,节点表示实体或概念,边则由属性或关系构成。
三、如何构建知识图谱?
知识图谱的构建主要分为知识体系构建、知识获取、知识融合、知识存储和检索、知识推理、知识应用六个步骤。
下面是产品视角的知识图谱构建流程图:

1. 知识体系构建(建模)
1.1 定义
知识体系构建,也称为知识建模,是指采取什么样的方式来表达知识,其核心是构建一个本体对目标知识进行描述。
在这个本体中需要定义出知识的类别体系、每个类别下所属的概念和实体、某类概念和实体所具有的属性以及概念之间、实体之间的语义关系,同时也包括定义在这个本体上的一些推理规则。
知识图谱是随着语义网的发展而出现的概念。语义网的核心目标是让计算机能够理解文档中的数据,以及数据和数据之间的语义关联关系,从而使得计算机可以自动化、智能化地处理这些信息。
1.2 RDF三元组
语义网技术涉及面较广,这里只介绍与知识图谱数据建模紧密相关的核心概念——资源描述框架(RDF)。RDF基本数据模型包括了三个对象类型:资源(resource)、谓词(predicate)以及陈述(statements)。
- 资源:能够使用RDF表示的对象称之为资源,包括互联网上的实体、事件和概念等;
- 谓词:谓词主要描述资源本身的特征和资源之间的关系;
- 陈述:一条陈述包含三个部分,通常称之为RDF三元组(主题:被描述的资源,谓词:可以表示主体的属性,也可以表示主语和宾语之间的关系,宾语:属性值)。
知识图谱将三元组(triple)作为知识存储和表示的基本单元。三元组的表现形式有两种:“实体—关系—实体”、“实体—属性—属性值”。
其中每个实体代表现实世界中一个独一无二的对象,并对应全局唯一的ID。
1.3 实例
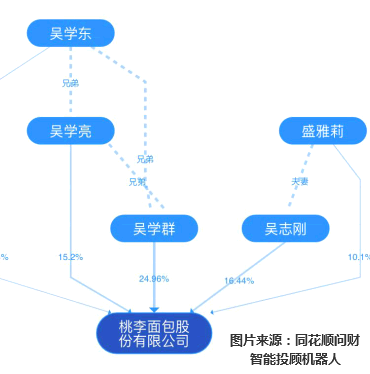
下图中包含了多组三元组信息:
- 桃李面包作为一个实体,其属性是公司名称,属性值是桃李面包股份有限公司;
- 吴志刚作为实体,与桃李面包之间是持股关系,属性值为具体持股比例;
- 吴志刚作为实体,与盛雅莉之间是亲属关系,属性值为夫妻。
2. 知识获取
2.1 目标
知识获取的目标是从海量的文本数据中通过信息抽取的方式获取知识,其方法根据所处理数据源的不同而不同。
2.2 数据类型
知识图谱中数据的主要来源包括结构化数据、半结构化数据和非结构化数据(纯文本)。
其中,非结构化文本的信息抽取是构建知识图谱的核心技术。
2.3 知识获取的基本任务
- 实体识别:指从文本中识别实体信息;
- 实体消歧:指消除指定实体的歧义;
- 关系抽取:指获取两个实体之间的语义关系;
- 事件抽取:指从描述事件信息的文本中抽取出用户感兴趣的事件信息并以结构化的形式呈现出来。
3. 知识融合
知识融合是对不同来源、不同语言或不同结构的知识进行融合,从而对已有知识图谱进行补充、更新和去重。
- 从融合的对象来看,包括知识体系的融合和实例的融合;
- 从融合的图谱类型来看,可以分为竖直方向的融合和水平方向的融合。
4. 知识存储
知识存储就是研究采取何种方式将已有知识图谱进行存储。
4.1 存储方式
目前知识图谱大多是基于图的数据结构,存储方式通常采用RDF格式存储和图数据库(Graph Database),前者例如Google开放的Freebase知识图谱,后者例如开源图数据库Neo4j。
4.2 质量评估
有效的质量评估可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识图谱的质量。
4.3 知识更新
(1)更新类型
从逻辑上看,知识图谱的更新包括概念层的更新和数据层的更新。
- 概念层的更新是指新增数据后获得了新的概念,需要自动将新的概念添加到知识图谱的概念层中。
- 数据层的更新主要是新增或更新实体、关系、属性值,对数据层进行更新需要考虑数据源的可靠性、数据的一致性等,并选择在各数据源中出现频率高的事实和属性加入知识库。
(2)更新方式
- 全面更新:指以更新后的全部数据为输入,从零开始构建知识图谱。
- 增量更新:以当前新增数据为输入,向现有知识图谱中添加新增知识。
相对而言,前者比较简单,但资源消耗大,而后者资源消耗小。
5. 知识推理
为了解决数据的不完备性和稀疏性,需要采取推理的手段发现已有知识中隐含的知识。
目前研究重点在于挖掘两个实体之间隐含的语义关系。
两种推理方法:
- 基于传统逻辑规则的方法进行推理,其研究热点在于如何自动学习推理规则,以及如何解决推理过程中的规则冲突问题;
- 基于表示学习的推理,即采用学习的方式,将传统推理过程转化为基于分布式表示的语义向量相似度计算任务。
四、如何应用知识图谱?
伴随着人工智能浪潮,知识图谱已经在搜索引擎、智能问答、推荐等领域得到了广泛的应用。
1. 智能搜索(实体关系)
在智能搜索方面,基于知识图谱的搜索引擎,内容存储了大量的实体以及实体时间的关系,可以根据用户问句准确地返回答案。
下图中,用户询问马云,机器人便可以准确地给出马云的个人介绍。
当存在多个同名的人时,知识图谱可以基于实体唯一ID进行消歧,帮助用户更加准确地定位答案。
2. 自动问答(实体关系推理)
在自动问答方面,可以利用知识图谱中实体及其关系进行推理得到答案。
下图中,百度“马化腾是哪里人?”百度会基于知识图谱直接给出马化腾的出生地。
3. 推荐(实体关系)
在推荐方面,可以利用知识图谱中实体的关系向用户推荐相关的产品。
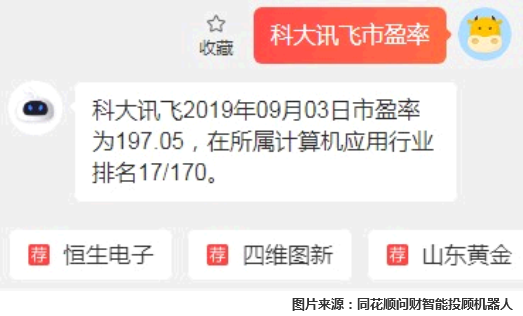
下图中,用户询问“科大讯飞市盈率”,机器人通过判断科大讯飞是一只A股的股票,然后给出了相同属性其它实体的推荐。
4. 决策支持
知识图谱能够把领域内复杂知识通过信息抽取、数据挖掘、语音匹配、语义计算、知识推理等过程精确地描述出来,并且可以描述知识的演化过程和发展规律,从而为研究和决策提供准确、可追踪、可解释、可推理的知识数据。
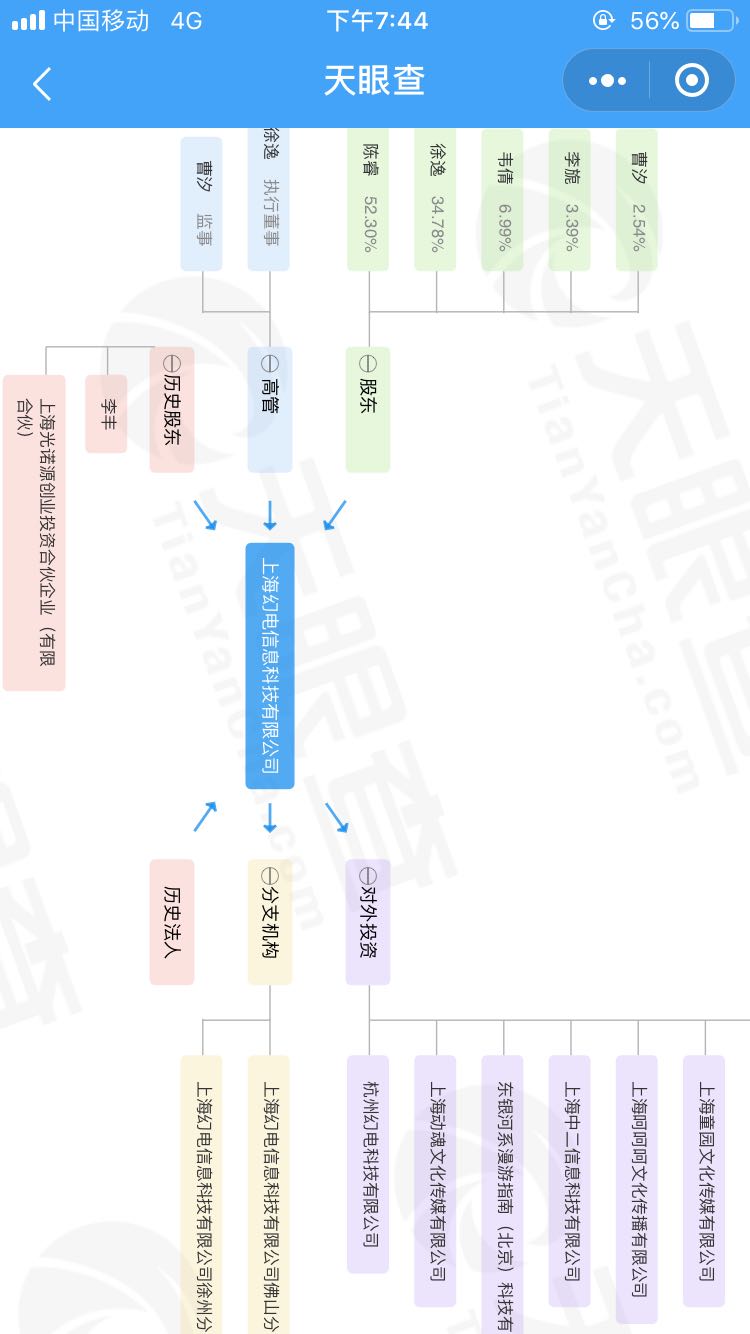
下图中,用户输入Bilibili,天眼查企业图谱便可以准确地返回上市公司股东、董监高、对外投资等完整信息,辅助用户进行决策。
#参考文献#
《智能问答》,段楠,周明
《知识图谱》,赵军,刘康,何世柱,陈玉博
《人工智能产品经理:人机对话系统设计逻辑探究》,朱鹏臻
《自然语言处理实践:聊天机器人技术原理与应用》,王昊奋,邵浩等
本文由 @Alan 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。










牛
😐