
 起点课堂会员权益
起点课堂会员权益AI产品经理必修课:如何构建推荐系统
本文简单介绍了什么是推荐系统、如何构建推荐系统,适合希望成为人工智能产品经理的产品新人阅读。

内容框架
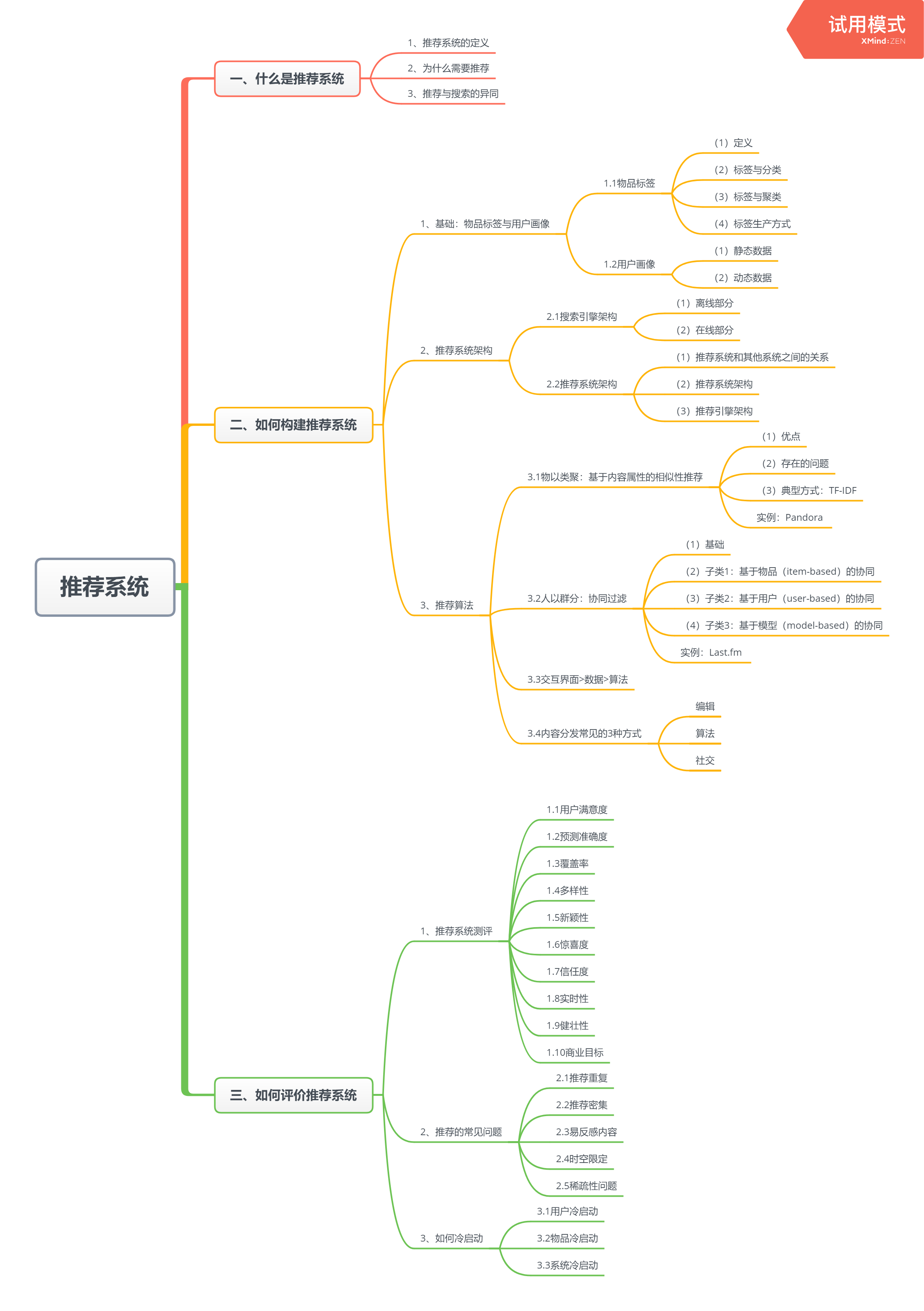
一、什么是推荐系统
推荐系统在我们的生活中无处不在:淘宝shopping时的相关物品、一刷就让人停不下来的抖音短视频、百度地图的导航路线……
既然推荐系统与我们的生活密不可分,那么什么是推荐系统呢?
1.1 推荐系统的定义
根据维基百科的定义,推荐系统是一种信息过滤系统,用于预测用户对物品的“评分”或“偏好”,广泛应用于电影、音乐、新闻、书籍、学术论文、搜索查询等行业。
从本质上来说,推荐是特定场景下人与信息更有效率的连接。
1.2 为什么要有推荐系统
据IDC《数字宇宙》的研究报告表明,2020 年全球新建和复制的信息量将超过40ZB,是2012年的12倍;中国的数据量在2020年超过8ZB,比2012年增长22倍。
单位换算是这样的:
- 1ZB = 1024 EB;
- 1EB = 1024 PB;
- 1PB = 1024 TB;
- 1TB = 1024 GB;
- 1GB = 1024 MB;
信息量的指数化增长反映了用户需求的变化,为了更好地满足用户的需求,互联网从门户网站时代发展到了搜索引擎时代。
作为门户网站的代表,雅虎以分类目录满足了早期互联网用户的需求。
作为搜索引擎的代表,谷歌以智能化的搜索解决了信息不断增长与门户网站内容有限之间的矛盾。
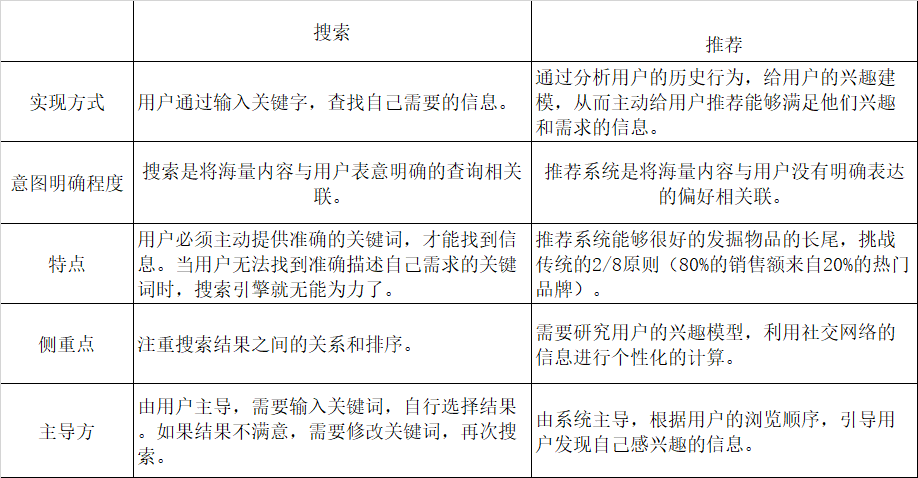
1.3 推荐与搜索的异同
1.3.1 相同点
- 和搜索引擎一样,推荐系统是一种帮助用户快速发展有用信息的工具;
- 二者目的都是实现信息与用户意图之间的匹配;
- 推荐系统的架构与搜索系统的架构具有一定的相似度。
1.3.2 不同点
二、如何构建推荐系统
2.1 基础:物品标签与用户画像
只有更好地了解待推荐的内容和要推荐的人,推荐系统才能更加高效地完成内容与人之间的对接。
2.1.1 物品标签
(1)定义
标签是我们对多维事物的降维理解,以抽象出事物更具有表意性、更为显著的特点。
(2)标签与分类
通常来说,分类是树状的,是自上而下依次划分的。在分类体系中,每个节点都有严格的父子继承关系,在兄弟节点层都具有可以被完全枚举的属性值。
考虑到分类权威性和信息完备性问题,建议由专家系统进行编辑分类。
标签是网状的,更强调表达属性关系而非继承关系,只有权重大小之分,不强调包含和被包含的关系。这就使得相对于分类而言,标签的灵活性更强,权威性更弱,每个用户都可以参与。
(3)标签与聚类
标签适用文字表意歧义较小、可以枚举的类型。其它很难准确地表意或概括地不适用。这时候就需要有聚类的协助。
聚类是指基于某一维度地特征将相关物品组成一个集合,并告诉你这个新的物品同哪个集合相似。
(4)标签生产方式
常见的标签生产方式有两种:PGC(专家系统产出),例如潘多拉音乐基因工程;UGC(普通用户产出),例如豆瓣音乐标签系统。
2.1.2 用户画像
用户画像数据,也称为KYC(Know Your Customer),主要分为静态数据和动态数据。
- 静态数据指用户基本信息,例如性别、学历、年龄、婚育情况、常住位置、教育程度。
- 动态数据指用户显性或隐性行为,包括用户物品偏好、行为路径、点赞、评论、分享、关注等。
2.2 推荐系统架构
作为参照,我们先了解一下搜索引擎的架构。
2.2.1 搜索引擎架构
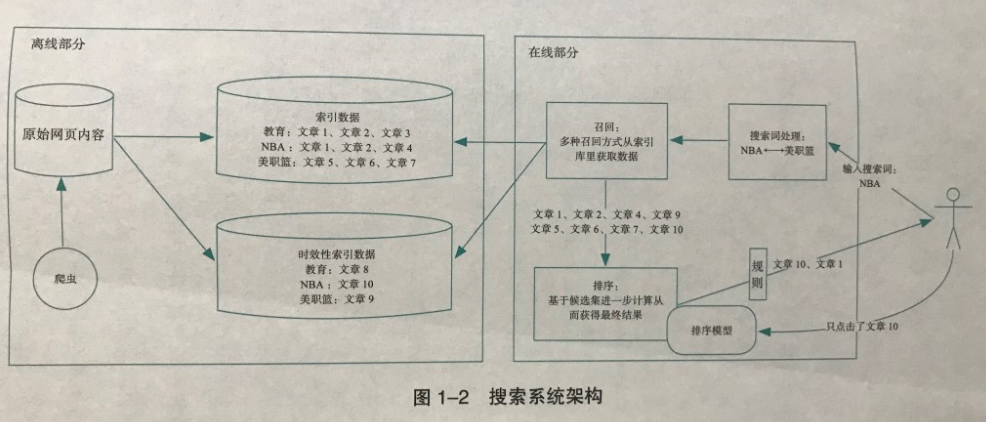
搜索系统架构,图片来源:《内容算法》
我们通常将搜索系统划分为离线和在线两部分。
(1)离线部分专注于内容的搜集和处理。
- 搜索引擎的爬虫系统会从海量网站上抓取原始内容,并针对搜索系统的不同要求建立不同的索引体系。
(2)在线部分负责响应用户的搜索请求,完成内容的筛选和排序,并最终把结果返回给用户。
- 当用户输入搜索词后,系统会首先对搜索词进行分词、变换、扩充、纠错等处理过程,以便更好地理解用户地搜索意图。
- 经历完搜索词处理后,将进入召回环节。系统通过多种方式从不同地索引数据里获得候选集合。
- 召回得到地候选集合会继续进入排序环节,通过更精细地计算模型对每一篇候选内容进行分值计算,从而获得最终结果。
- 在展示给用户之前,搜索结果还需要经过规则干预这一环节。规则通常服务于特定地产品目的,对计算产出地内容进行最终地调整。
- 在结果展示给用户之后,用户的点击反馈会影响到排序环节地模型。
2.2.2 推荐系统架构
(1)推荐系统和其他系统之间的关系
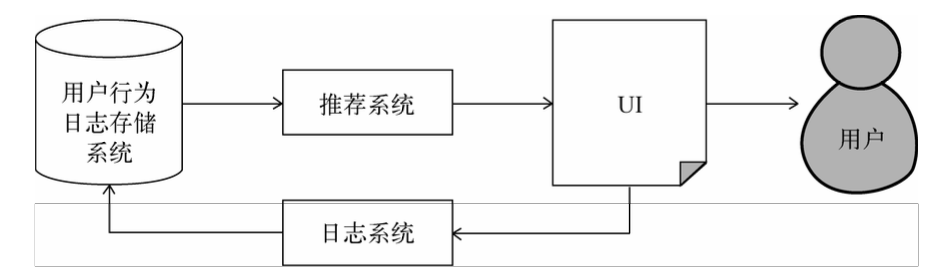
推荐系统和其他系统之间的关系,图片来源:《推荐系统实践》
推荐服务通常由三部分组成:前台展示子系统、日志子系统和算法子系统。
- 推荐服务首先需要采集产品中记录的用户行为日志到离线存储;
- 然后在离线环境下利用推荐算法进行用户和物品的匹配计算,找出每个用户可能感兴趣的物品集合后,将这些预先计算好的结果推送到在线存储上;
- 最终产品在有用户访问时通过在线API向推荐服务发起请求,获得该用户可能感兴趣的物品,完成推荐业务。
(2)推荐系统架构
推荐系统需要由多个推荐引擎组成,每个推荐引擎负责一类特性和一种任务,推荐系统的任务是将推荐引擎的结果按照一定权重或者优先级合并,排序然后返回。如下图:
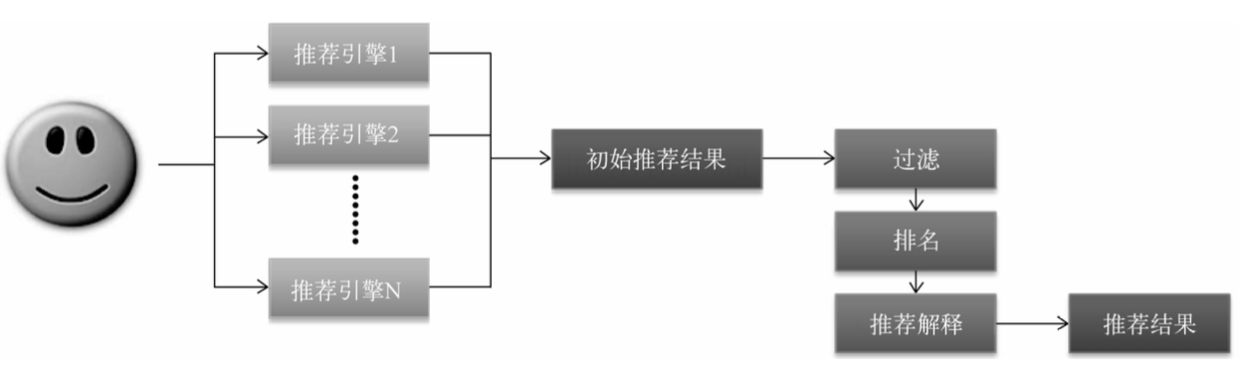
推荐系统架构图,图片来源:《推荐系统实践》
这样做的优点是方便增加或删除引擎,控制不同引擎对推荐结果的影响,可以实现推荐引擎级别的用户反馈,对不同用户给出不同引擎组合权重。
(3)推荐引擎架构
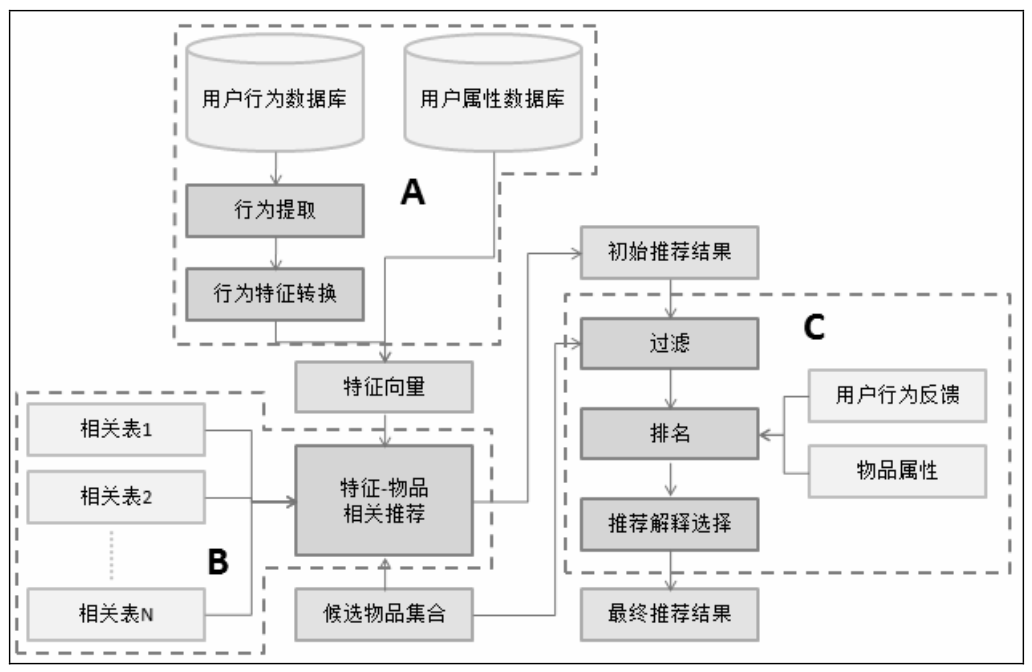
推荐引擎架构图,图片来源:《推荐系统实践》
推荐引擎架构主要包括三部分:
- 图中A部分负责从数据库或缓存中拿到用户行为数据,通过分析不同行为,生成当前用户的特征向量,如果使用非行为特征,就不需要行为提取和分析模块了,该模块的输出就是用户特征向量。用户特性向量包括用户行为的种类、用户行为产生的时间、用户行为的次数、物品的热门程度。
- 图中B部分负责将用户的特征向量通过特征-物品相关矩阵转化为初始推荐物品列表。
- 图中C部分负责对初始的推荐列表进行过滤、排名等处理,从而生成该引擎的最终推荐结果。过滤模块会过滤掉以下物品:用户已经产生过行为的物品、候选物品以外的物品(不符合用户筛选条件的物品)、某些质量很差的物品。
2.3 推荐算法
推荐系统产生推荐列表的方式通常有两种:基于内容属性的相似性推荐、协同过滤。
2.3.1 物以类聚:基于内容属性的相似性推荐
基于内容推荐利用一些列有关物品的离散特征,推荐出具有类似性质的相似物品。
(1)优点:只依赖于物品本身地特征而不依赖用户的行为,让新的物品、冷僻的物品都能得到展示的机会。
(2)存在的问题:推荐质量优劣完全依赖于特征构建的完备性,但特征构建本身就是一项系统的工程,存在一定成本。没有考虑用户对物品的态度,用户的品味和调性很难得到诠释和表达。
(3)典型方式:TF-IDF,其基本思想:出现频率越高的标签区分度越低,反之亦然。
实例:Pandora 使用歌曲或者艺人的属性(由音乐流派项目提供的400个属性的子集)从而生成一个电台,其中的乐曲都有相似的属性。
用户的反馈用于精化电台中的内容。在用户“不喜欢”某一歌曲时,弱化某一些属性;在用户喜欢某一歌曲时,强化另一些属性。
Pandora 启动时则仅需要很少信息,然而这种方法的局限性很大,只能得出与原始种子相似的推荐。
2.3.2 人以群分:协同过滤(collaborative filtering)
协同过滤方法根据用户历史行为(例如其购买的、选择的、评价过的物品等)结合其他用户的相似决策建立模型。作为目前应用最为广泛的推荐机制,其基于用户行为的特点使我们不需要对物品或信息进行完整的标签化分析和建模,可用于预测用户对哪些物品可能感兴趣(或用户对物品的感兴趣程度)。
(1)基础:把用户的消费行为作为特征,以此进行用户相似性或物品相似性的计算,进行信息匹配。
(2)子类1:基于物品(item-based)的协同
基础思路:先确定你喜欢什么物品,再找到与之相似的物品推荐给你。
(3)子类2:基于用户(user-based)的协同
基础思路分为两步:第一步,找到那些与你在某一方面口味相似的人群;第二步,将这一人群喜欢的新东西推荐给你。
(4)子类3:基于模型(model-based)的协同
基础思路:用用户的喜好信息来训练算法模型,实时预测用户可能的点击率。
实例:Last.fm 建立通过观察用户日常收听的乐队或歌手,并与其它用户的行为进行比对,建立一个“电台”,以此推荐歌曲。
Last.fm 会播放不在用户曲库中,但其他相似用户经常会播放的其它音乐。为了提供精准推荐,Last.fm 需要大量用户信息。这是一个冷启动问题,在协同过滤系统中非常常见。
2.3.3 交互界面>数据>算法
虽然推荐算法是推荐系统的核心要素,但是交互界面对于推荐系统来说也至关重要。
例如“推荐理由”,从工程角度出发,推荐理由提升了推荐系统的透明性,让用户明白为什么会推荐该种类型的内容。站在业务的角度,会更多地从促成转化入手,即什么样的推荐理由可以增加说服力,引发用户认同。
因此,对于推荐系统而言,有着“交互界面>数据>算法”的说法。
2.3.4 内容分发常见的3种方式
作为内容分发常见的3种方式,编辑、算法与社交分发各有千秋,互相补充。
(1)编辑分发指中心个人主导的分发机制,常见于纸媒、门户网站等。
(2)算法分发指机器主导的分发机制,常见于今日头条等内容APP,形成了真正的千人千面。
ACM世界冠军,第四范式创始人戴文渊在2009年加入百度时,百度基于1w条专家规则进行内容分发,而机器分析数据之后得到了更加精细化的1000亿条规则。相对应的,百度的收入提升了8倍。
(3)社交分发指离散人工主导的分发机制,常见于Facebook等社交网站,用户给出负面评价过多的内容,Facebook审核人员会优先处理。
三、如何评价推荐系统
正如管理学大师彼得德鲁克所言:”if you can’t measure it, you can‘t improve it.”
3.1 推荐系统测评
常见的推荐系统评估指标有用户满意度、预测准确度、覆盖率、多样性、新颖性、惊喜度、信任度、实时性、健壮性、商业目标。
3.1.1 用户满意度
用户满意度是评测推荐系统的重要指标,无法离线计算,只能通过用户调查或者在线实验获得。在线系统中,我们可以用用户付费率、点击率、停留时间、转化率等指标度量用户的满意度。
3.1.2 预测准确度
预测准确度,度量的是推荐系统预测用户行为的能力。是推荐系统最重要的离线评测指标。包括了评分预测、TopN推荐两种。
对应到内容推荐系统中,表现为对用户点击地预判和对消费情况地预判。由于准确度评估是可以复用既有数据进行离线计算的,故通常用于各种算法的迭代。
网站提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫做TopN推荐。
TopN推荐的预测准确率,一般通过2个指标度量:精度(precision)和召回(recall)
推荐系统中的精度(precision)和召回(recall)本质上和二元分类中的概念是一样的。
推荐系统往往只推荐有限个(如k个)物品给某个用户。真正相匹配的物品我们称之为相关物品(也就是二元分类中的阳性)。
k召回(recall at k)=所推荐的k个物品中相关物品的个数/所有相关物品的个数
k精度(precision at k)=所推荐的k个物品中相关物品的个数/k
比如说,根据你的喜好,我们推荐了10个商品,其中真正相关的是5个商品。在所有商品当中,相关的商品一共有20个,那么
k召回 = 5 / 20
k精度 = 5 / 10
3.1.3 覆盖率
也称为多样性,能够给用户提供视野范围之外的内容,丰富度越高代表个体体验的多样性越好;
从内容角度可以评估有推荐展示的内容占整体内容量的比例,或整个内容分发体系的基尼系数。
3.1.4 多样性
为了满足用户广泛的兴趣,推荐列表需要能够覆盖用户不同兴趣的领域,即需要具有多样性。
3.1.5 新颖性
新颖性也是影响用户体验的重要指标之一。它指的是向用户推荐非热门非流行物品的能力。
3.1.6 惊喜度
推荐结果和用户的历史兴趣不相似,但却让用户满意,这样就是惊喜度很高。
3.1.7 信任度
如果用户信任推荐系统,就会增加用户和推荐系统的交互。
提高信任度的方式有两种:增加系统透明度:提供推荐解释,让用户了解推荐系统的运行机制;利用社交网络,通过好友信息给用户做推荐。度量信任度的方式,只能通过问卷调查。
3.1.8 实时性
实时性包括两方面:实时更新推荐列表满足用户新的行为变化;将新加入系统的物品推荐给用户;
3.1.9 健壮性
任何能带来利益的算法系统都会被攻击,最典型的案例就是搜索引擎的作弊与反作弊斗争。
健壮性(robust,鲁棒性)衡量了推荐系统抗击作弊的能力。
3.1.10 商业目标
设计推荐系统时,需要考虑最终的商业目标。不同网站具有不同的商业目标,它与网站的盈利模式息息相关。
3.2 推荐的常见问题
前美国总统奥巴马的法律顾问凯斯·桑斯在2006年出版了《信息乌托邦——众人如何生产知识》,书中提出了“信息茧房”的概念。信息茧房指在信息传播中,由于公众自身的信息需求并非全方位的,公众只注意自己选择的东西和使自己愉悦的领域,久而久之,会将自己桎梏在像蚕茧一般的“茧房”中。
推荐系统存在着“信息茧房”等诸多问题:
- 推荐重复,指大量内容高度重复,缺乏新意。
- 推荐密集,指同一类内容的占比过高,导致局部多样性丧失。
- 易反感内容,包括详情页和列表页的不好体验。
- 时空限定内容,指不同类内容有不同的时效性。
- 稀疏性问题,实际场景中,用户和物品的交互信息往往是非常稀疏的。
如电影推荐中,电影往往成千上万部,但是用户打过分的电影往往只有几十部。使用如此少的观测数据来预测大量的未知信息,会极大增加过拟合的风险。
3.3 如何冷启动
3.3.1 用户冷启动
指一个新用户,没有任何历史行为数据,怎么做推荐?
解决办法:一种选择是利用用户注册信息等基础用户数据,另一种选择是新用户第一次访问推荐系统时,不立即给用户展示推荐结果,而是给用户提供一些物品让用户反馈他们对物品的兴趣,然后根据反馈提供个性化推荐。
3.3.2 物品冷启动
指一个新上线的物品,没有用户对它产生过行为,怎么推荐给感兴趣的用户?
解决办法:利用物品本身的属性,UserCF算法对于物品冷启动不是非常敏感。
3.3.3 系统冷启动
指一个新开发的网站,没有用户数据,怎么做个性化推荐?
解决办法:充分发挥专家系统的作用,并与机器学习适当结合。
#参考文献#
《内容算法:把内容变成价值的效率系统》,闫泽华
《推荐系统实践》,项亮
《推荐系统》,Francesco Ricci,Lior Rokach,Bracha Shapira,Paul B.Kantor
http://sofasofa.io/forum_main_post.php?postid=1001389
本文由 @Alan 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。










老师 请问相关列表是什么数据的列表
想问下,推荐算法中的物以类聚和基于物品协同过滤两个内容有区别吗?都是推荐相似的物品啊。。。
很有帮助
好文,订阅了