
 起点课堂会员权益
起点课堂会员权益产品经理懂点技术:前后端是如何“分家”的?
你知道早期的开发中,前后端是不分离的吗?那么后来它们又为什么要“分家”呢?分离后又有什么好处呢?

在前面一篇文章中,产品汪搞懂了前后端的工作分工。但是了解过程中,一个程序猿哥哥不经意间的一句话:“现在都是前后端分离的”,让小汪感到纳闷了,以前难道前后端不分离的么?于是小汪就继续深究起来。
不温馨的一家人
在十几年前,前端的地位其实相对于后端并不那么强势,以下是一种经典的编程框架。
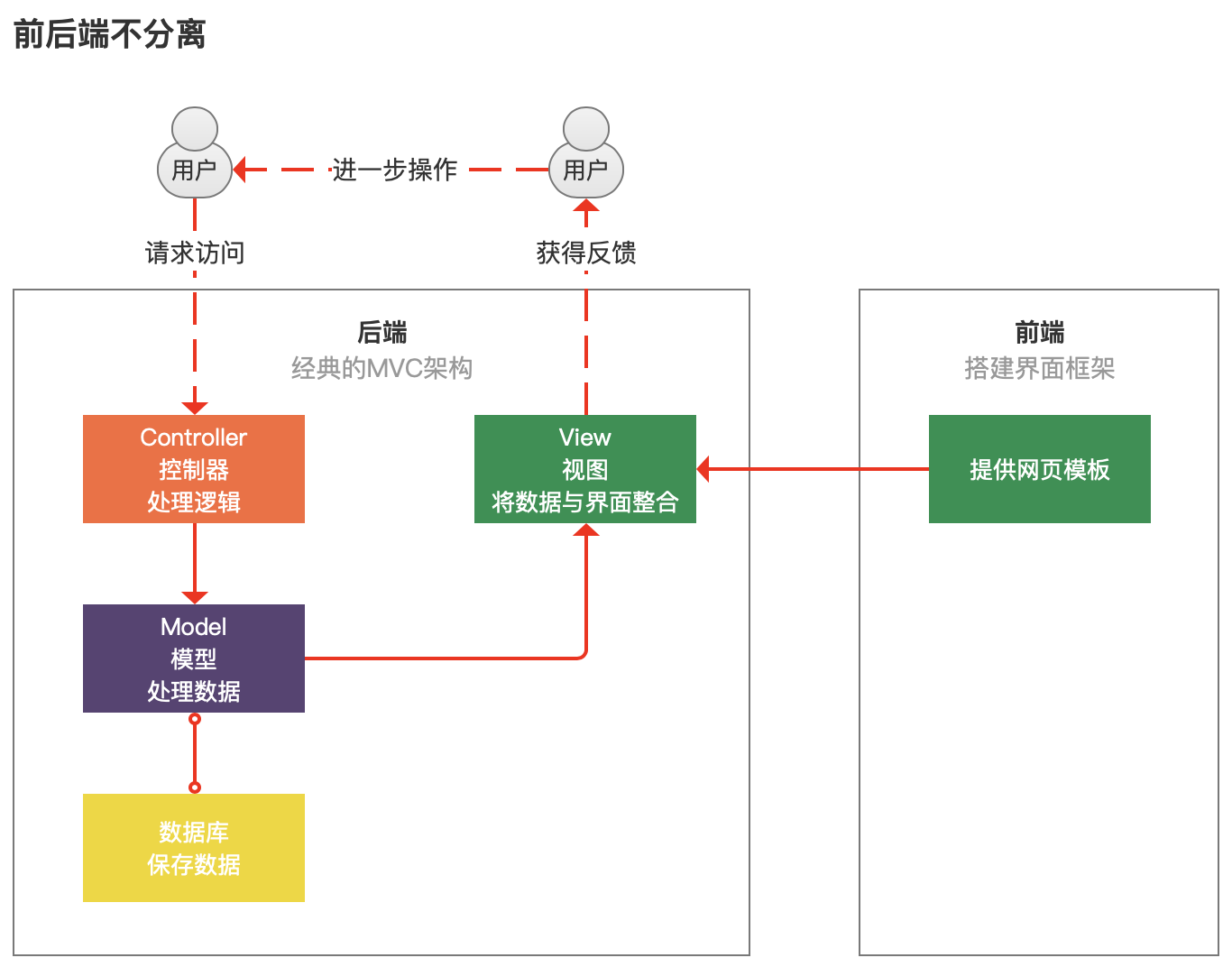
MVC:Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码。
有意思的事情出现了,内容是传给用户的,前端并不是直接接触用户的!前端只是提供了个样式模板,由后端把内容嵌入进入,再由后端直接传给用户。
这个时候,前端的编程要各种顺着后端哥哥的心意,而且前端要是出bug了,还得拉上后端一起研究,谁让你往我的模板里插了内容,出了幺蛾子你就得负责到底。
这个时期前后端高度耦合,从编程环境、到开发调试,都必须“在一起”,对于前端来说,其实自主权就不高,对后端来说,也要懂一些前端的知识。
于是前端程序猿对后端程序猿说,要不……你只管你的业务和数据,把结果给我,我来负责组装与呈现,这样大家都轻松些。于是前后端就分离了。
当初是你要分开,分开就分开
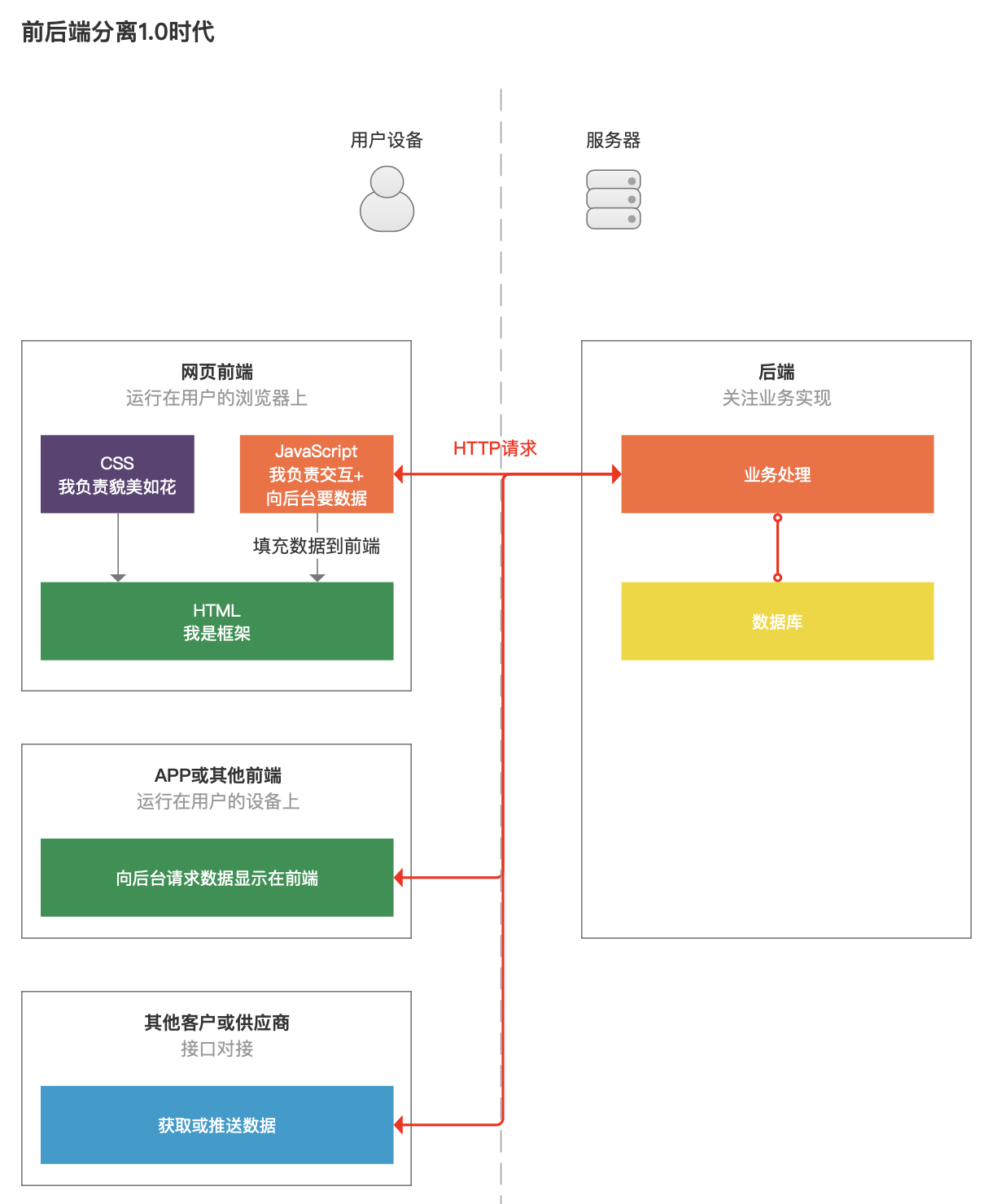
前后端分离带来的好处:
(1)编程更轻松
前后端分离之后,后端更专注于实现业务逻辑,形成一套标准化的“API接口”,例如需要创建商品,前端将商品信息传给后端创建商品的接口,后端就会完成商品的创建,并返回创建结果。如果前端给的创建商品信息缺了标题或者价格,后端还能返回创建失败的结果,并且提示缺失了哪些信息等。
前端除了负责界面样式和交互,还接管了获取和展示数据的权利,从此前端开发就自由多了,如果遇上bug,也能很轻松定位到是前端还是后台的事情。
(2)更高的可复用性
前后端分离,更是顺应了互联网发展多样化的潮流。后端通过提供一系列可以实现不同业务功能的接口,就可以让不同的前端、甚至外部系统过来对接。
这样方便了公司不断推广自己的产品,今天推出手机网页版、明天推出APP版、后天推出小程序版本等。而后端只需要提供一次接口,无需每增加一类客户端,后端就要新写过。
用户访问网站的过程小知识:
- 浏览器先下载HTML的内容
- 根据HTML里的内容,下载并加载对应的CSS,让网页漂亮起来
- 根据HTML里的内容,下载并加载对应的JavaScript,让网站具备交互动效,其中部分JavaScript代码负责向服务器上的后端请求数据,并展示在页面上。
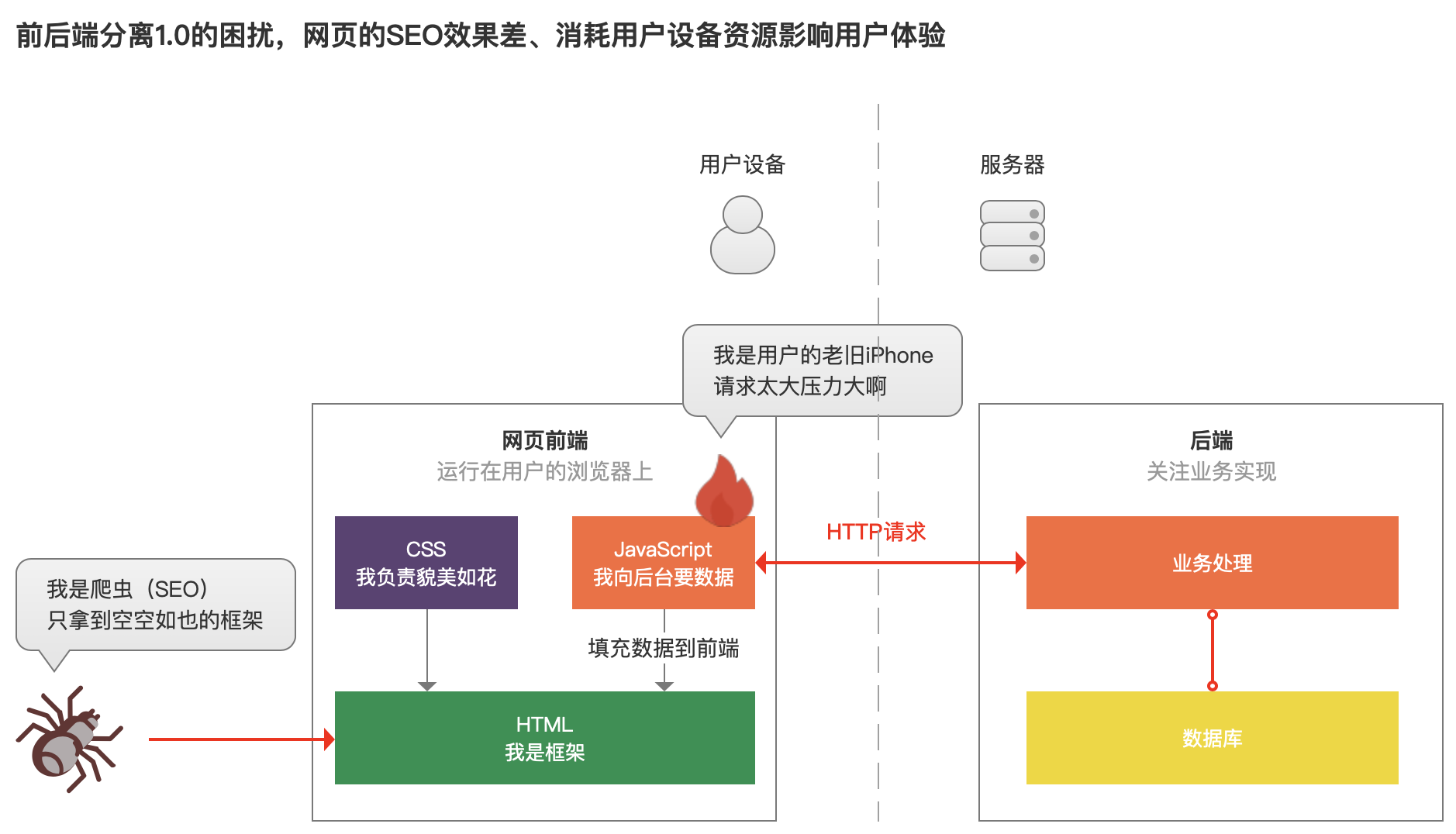
但是久而久之,前后端分离在web网页上也遇到了一些问题,最明显的是以下两点:
- JavaScript的请求在用户浏览器中进行,当一个网站需要展示非常多的内容时,JavaScript就要向后台多个接口请求数据,然后再在用户浏览器上完成页面组装,这过程中就会给用户设备的网速、设备的运行速度(CPU、内存等)带来一定的压力。
- 搜索引擎,如百度、搜狗、谷歌等,想爬取网页的内容时,就会用到爬虫。爬虫会抓取网页HTML里面的内容,然后让其他网友可以搜索到你的网页。但是此时,HTML文件就是个框架,要依靠JavaScript才能获取到数据。这就会导致你的网页难以被搜索引擎收录,用户很可能搜不到你的网页。
前后端分离为用户设备带来的影响,可以通过“换台新手机”、“换台新电脑”解决,但是搜索引擎爬不到网页的数据,对很多重度依赖搜索引擎流量的产品来讲,打击可就大了。
例如你需要找一个菜谱的时候,可能会在百度搜索“芥蓝怎么炒好吃?”,然后再从搜索结果里面访问各种美食网站。又或者你想去哪里玩,就会在百度搜索“土耳其旅游攻略”等等。对于这类重搜索引擎流量的网站而言,如果爬虫爬不到自己的数据,客流损失就比较严重。
运行在后面的前端
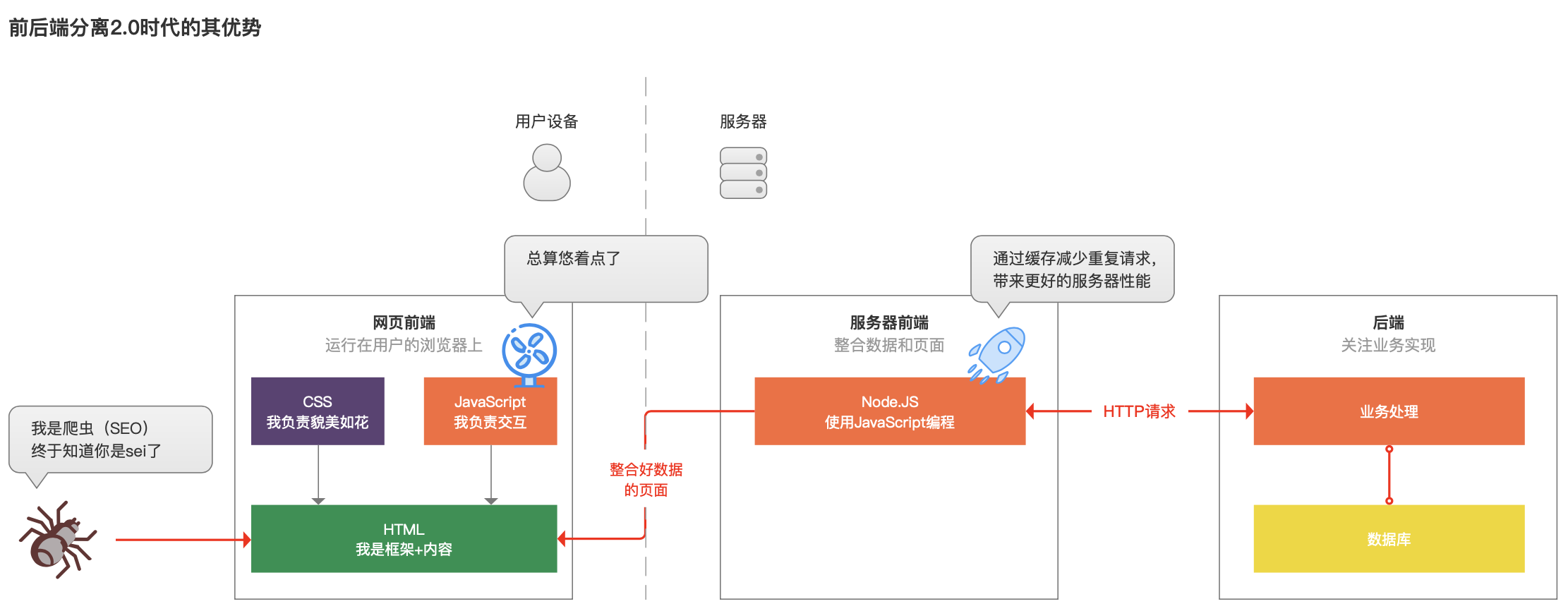
考虑到上诉问题,聪明的网页前端程序猿就想到了一个新的办法,那我们先把后台的数据跟HTML内容整合好,再呈现给用户吧,得力于一种叫做Node.JS的、可以使用网页前端熟悉的JavaScript编程的工具,于是有了2.0版本的前后端分离。
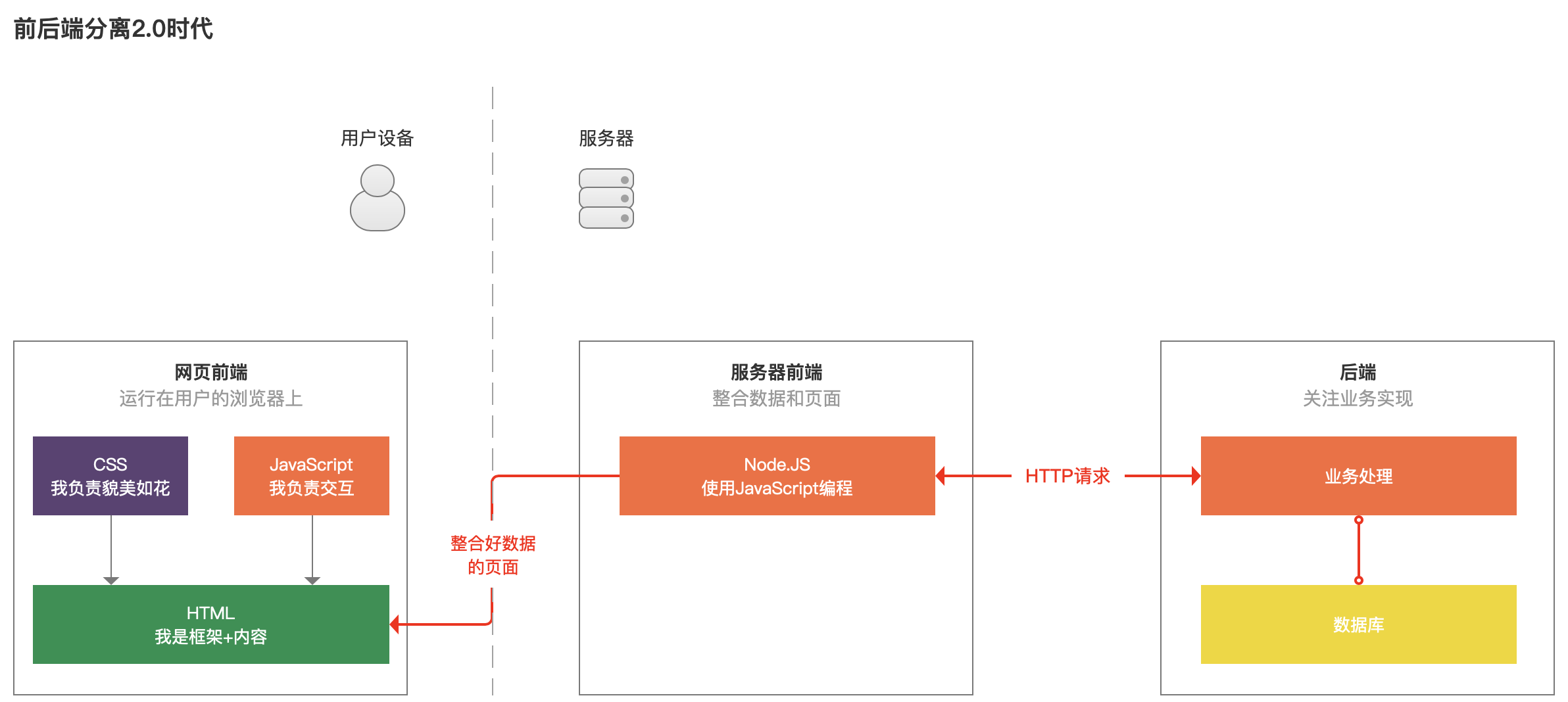
前端程序猿跟服务器上的后端说,让一让,给我腾个地儿,然后把Node.JS放在了服务器上。等用户或者爬虫需要访问网页时,这个运行在服务器上的程序,先请求后端获得数据,并整合到HTML中,然后再返回给用户。
这样一来,用户的设备就少了JavaScript多次请求后端的烦恼,加快了运行速度,而爬虫也可以爬取到填充好内容的HTML网页了。
看到这里,小汪就想,这么一来,用户体验、爬虫的问题确实解决了,但是让本来本该发生在用户浏览器上的事情,都在服务器上做了嘛,如果访问量大的话,咱服务器的压力不就很大了?
前端程序猿哥哥呵呵一笑,其实不然,你想想,很多用户都是在访问同一个网页,看同一个商品、读同一篇文章,这些请求,要是服务器的前端就请求后台一次,然后把整合好的HTML保存起来,下次再有人再来访问,就把这个生成好的HTML展示给用户,这样不就服务器轻松了、用户访问也快了么!
小汪又问了,那咋们页面多了,不就要每个页面都保存一份HTML文件么,服务器储存的空间不就越来越少了么?
前端程序猿哥哥继续答道:久而久之,HTML文件在服务器积累多了,就把好久都没人访问的HTML删了,给其他新保存的HTML文件让位置,通过“缓存”技术,让服务器永葆活力。
小汪恍然大悟,原来这就是缓存啊!这下子,小汪终于明白了前后端分离是什么回事,以及为什么要前后端分离。
现在随着很多大型产品的形成、独立运行,新的“信息孤岛”正在形成。例如微信的公众号-小程序-朋友圈-圈子,然后通过搜一搜进行统一搜索,内部造血,而不再依赖传统的搜索引擎为他引流。
又例如淘宝,很多年前就拒绝了让百度爬虫爬取他的商品信息,只允许在淘宝内进行搜索。你在百度上搜不到淘宝的商品,在微信上也找不淘宝的任何信息、无法访问淘宝任何的链接,如果你要淘宝购物,就只能去淘宝网站或者下载淘宝APP。新的互联网格局的形成,肯定会进一步影响着前后端的关系。
本文由 @iCheer 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。









操你妈逼的,吃软饭的
文章写的非常精彩,比大学老师讲得好,非常感谢作者,在评论区做个笔记。
1.前后端不分离:前端只提供一个模板,后端直接和用户交接数据。
2.前后端分离时代1.0:前端获取业务信息(JavaScript)通过实现相应业务功能的【接口】将数据传给后端,后端将完成的结果通过接口返回结果给前端,前端将数据展示给用户。缺陷:当前端页面请求的接口过多,会受限于用户使用的设备性能,前端无法获取数据,搜索引擎的爬虫无法识别内容,会流失用户浏览量。
3.前后端用户分离时代2.0:出现了一项技术Nodejs,是Javascirpt的升级版,它部署在服务器上,由Nodejs负责与接口对接交换请求和结果的数据,提前填充好了Html网页,可以快速的加载到浏览器上,不仅减轻了1.0版本对用户设备的压力,爬虫也能更快的识别信息内容。同时增加了缓存技术,对于使用低频的页面(Html 文件)进行删除,减轻了服务器的压力。
4.信息孤岛,部分软件不与传统的搜索引擎共享数据,仅内部造血,内部使用。
👍写的非常通俗易懂,希望作者经常分享这种技术知识
写得通俗易懂~~
前后端分离好处中的二,应该是前端重新写过,不是后端重新写过叭。
学习了
谢谢楼主,学习了!
感谢,困惑我多年的问题得到了解答,祝工作顺利!
示意图很生动,必须一个赞
赞赞赞
通俗易懂
厉害厉害 😉
写的通俗易懂,关注
老哥 您这个写的真的生动 , 我一个不太懂的 都看明白了 感谢
写得很好,让我这个小白都看明白啦,感谢感谢~~~多多出新文章呀~~ ❓