
 起点课堂会员权益
起点课堂会员权益一个输入框你要做一周?
对于产品和开发来说,这两者可能会因为需求开发的难度与耗费工时发生一些争议与不同看法。那这背后隐藏的是什么原因呢?我们又该如何解决这类问题呢?

如果PO说这是个很小的改动,你不要信他。
01 一次有争议的估点
在某次迭代会议上,PO希望交付这样一个“简单”功能:在应用中,用户可以输入自己的地址,这样我们可以定期邮寄一些宣传册给用户。
按照PO的描述,这只是一个很简单的文本输入框,用户填写地址之后,地址信息随着其他个人信息一起存到数据库即可。
PO甚至在白板上画了一个不太规则的长方形作为示意,然后满怀期望的将目光投向了你—— 一个做事情还算靠谱的开发,友善的问道:
“你觉得实现这样一个输入框,需要多长时间?如果你觉得太小的话,我们是不是可以在做其他卡的时候顺手做了?”。
你定了定神,在脑海里大致验算了一遍,说:“嗯,我觉得在理想情况下,大概需要五、六天。如果算上开会……”。
“什么?这样一个输入框你要用一周?!”,PO敲着白板上那个不规则的长方形问道。
“呃……,我说的是理想情况,实际上应该会比这个时间更长……”
“……”
如果你有过和非技术出身的PO(或者站得太高而忘记地面是什么样子的架构师)一起工作过,大约很大程度上有过类似的经历。
通常来说,预期有这么大的偏差,很可能是大家说的并不是同一件事儿:要么是PO想的过于简单,要么是开发想的过于复杂。
02 遗漏掉的细节
由于专业知识的屏障,以及对细节的过度简化,使得非专业人士往往会低估完成某项工作所需要的工作量。另一方面,对于专业人士自身,如果忽略了外部环境中客观存在的阻力,同样会对实际工作量产生错误的判断。
1. “简单”的输入框
在PO眼中,一个普通的文本输入框大约长这个样子:

输入之后,传到后端保存一下就完事儿了。当然,可能还需要一些必要的校验,比如长度不能太短或者太长,地址遵循一定的格式之类。
2. 不那么简单的输入框
不过在一个有经验的开发眼里,一个“普通”的文本输入框是这样的:
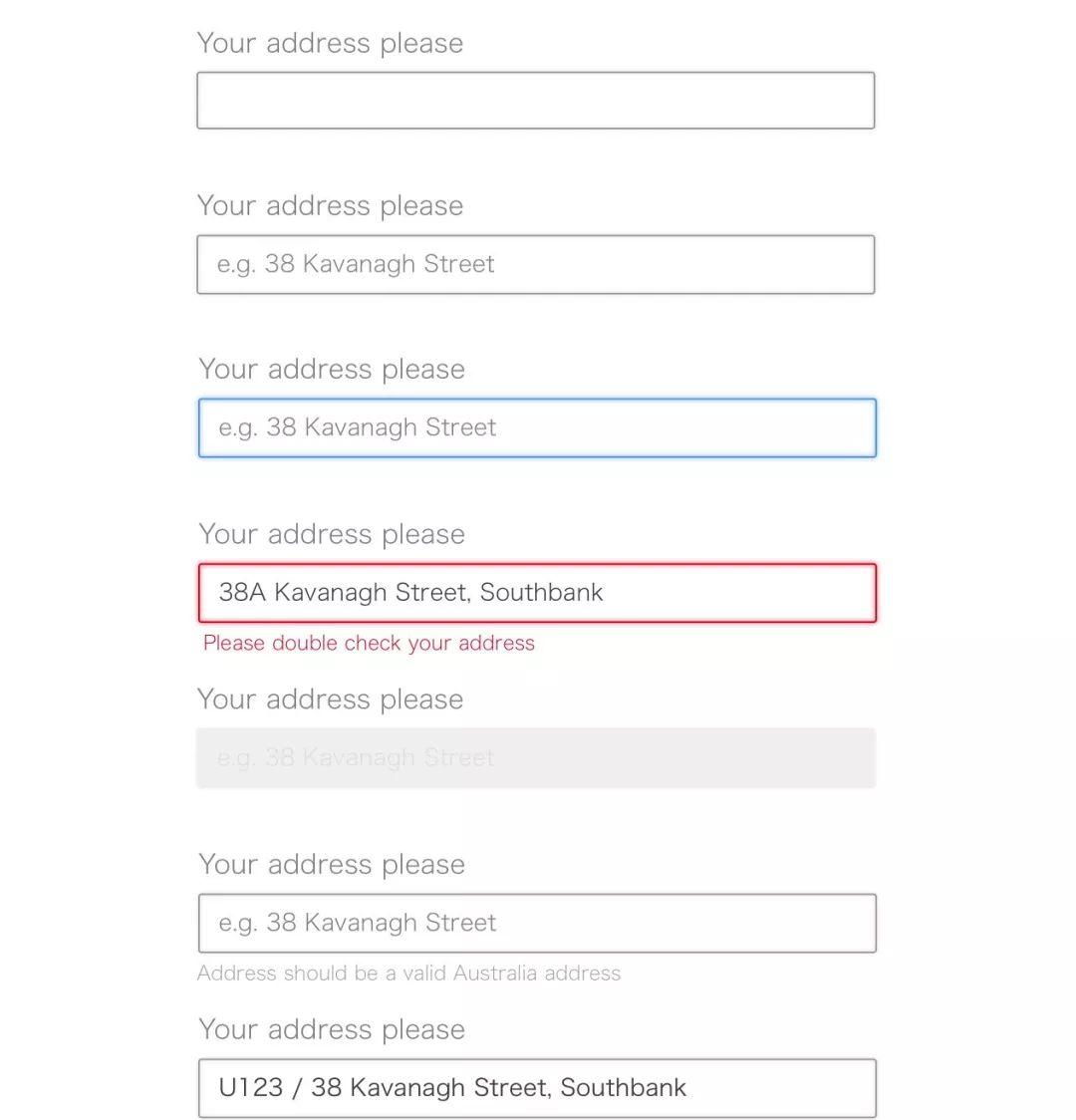
显然它拥有更多的状态,也更加复杂:
- 禁用状态
- 内容为空的时候
- 设置焦点之后的状态
- 非法输入状态
- 提示信息(helperText)
- 可用性(Accessibility)
- 其他状态
通常来说,在初始状态下,输入框会显示一个占位符。当用户开始输入时,需要有各种各样的反馈:拼写错误、太短或者超长等。此外,系统的其他部分的状态还可能影响输入框的状态,比如一个未授权的用户不能输入,这时我们需要将输入框禁用。
通常这些状态对应的样式会有差异,比如字体、字号、颜色和间距等等。这些细小的,但是需要和UX频繁沟通和改进的细节无疑会耗掉很多时间。
除了众多的状态之外,另一个会花费很多时间的地方是校验(以及限制)。
3. 校验
事实上,校验作为一个Cross Functional的点在实际中占用的开发时间(包括测试时间)往往被严重低估。除了基本的校验规则如:长度限制(最长10位,最短3位),格式限制(邮件)等之外,往往会有更为复杂的校验规则,这些规则有时候对校验逻辑实现的结构有一定的“破坏性”。
比如,开发可能定义了一系列的validations
const validations = {
minLength: 1,
maxLength: 16,
}
<AddressSearch validations={validations} value={value} />
经过一些时间的调试和代码的重构之后,假设这个校验机制可以良好的运行了。
const builtIns = {
minLength: (value, criteria) => value && value.length > criteria,
maxLength: (value, criteria) => value && value.length < criteria
}
const isValid = (validations) => (value) => {
return _.every(validations, (k, v) => builtIns[k](value, v))
}
const AddressSearch = ({validations, value}) => (<Input error={isValid(validations)(value)} ... />);
很快,下一个需求是将这个AddressSearch的合法性和页面上的另外一个输入框关联起来:当另一个选择国家的Dropdown的值发生变化之后,AddressSearch组件的校验规则会随之变化。
这种情况下,之前的很多逻辑被打破,开发需要更多的时间来修改代码,以及代码对应的测试,比如上面代码片段中的builtIns中的规则都需要重写。
4. 输入值的限制
另一个与校验相关的功能是限制某些值的输入,对于某些字段,需要禁止用户输入特定的字符。它可以认为是对校验的进一步扩展,不过有时候在实现上会将其独立起来。一些常见的例子如下:
- 不允许输入特殊字符
- 只允许输入数字
- 只允许输入alphabet
- 只允许输入1-12的月份或者1-31的年份
- 允许输入数字的小数点,其余则为非法
等等,有时候这些限制是正交的,互不干涉。有时候则不然。比如在允许输入数字(初衷是允许输入手机号码)的场景下,如果使用
<input type="number" />
作为实现,则当输入值实际需要0作为前缀的场景就会出现问题:浏览器往往会很智能的将前缀0删掉。
你可以通过:
<input type="tel" pattern="[0-9]*">
修复这个问题,不过很有可能你又会遇到跨浏览器等其他问题。总之,每一个潜在的问题,以及对应的解决方案都隐藏在表面之下,我们通常很难在开始前就能预料到这些细节。即使对有经验的开发者也是如此,更不用说远离这些细节的业务人员了。
5. 通过网络获取数据
现在,我相信PO已经能对“一个简单的输入框”所需要的工作量有一个初步的了解了。这些还只是对于纯前端的工作量。
现在假设有这样的一个增强:当用户输入地址时,我们需要搜索地址并智能地自动补全(auto-suggestion):
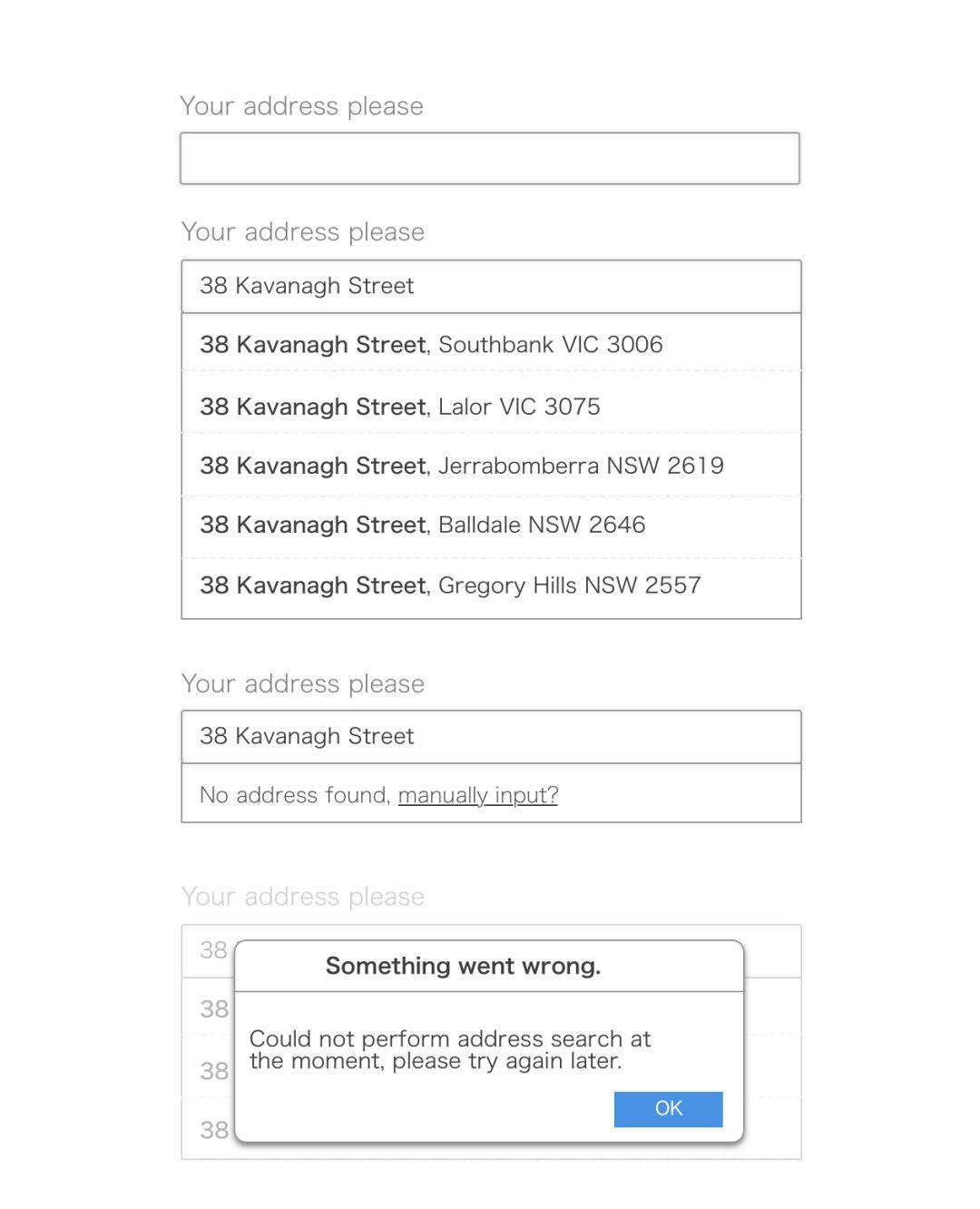
当引入网络数据获取之后,情况会变得更加复杂。
一方面,异步数据本身就比本地数据复杂,它需要额外的库(如果你想要屏蔽各个浏览器对异步请求的差异的话)。
另一方面,网络中很多变量会超出开发者的控制:比如网速,网络异常(路由配置,防火墙等)。
另外,当有了前端和后端的分别之后,协议/契约就会变成另一个障碍 — 如何保证协议双方对契约的消费的同步。比如,当前端发现需要展现一个额外字段在界面上,而发现后端并没有提供的时候;或者后端将日期存成了更加方便存储的long,而前端消费时发现没有timezone信息等等。
有了前后端双方的交互之后,校验规则同样需要在后端的模型对象和持久化层中都有所体现。
一种做法是前后端使用同构的架构(JavaScript全栈),这样有一部分代码可以在全后端复用(我们在上一个项目就中采用了React+AWS Lambda+Node.js的模式,整体体验还算不错)。
如果是异构架构,则需要将类似的代码用不同的语言写两遍,而且另外一个潜在的问题是:如何使得两者保持同步?
当然,我相信在工程上,这些问题最终都可以被解决,但是每个问题及其解决方案都不是免费的。即使团队中的开发有足够的经验和快速的学习能力,很多问题依然是无法预见的,而你永远无法解决一个你不知道的问题。
6. 异常情况
大部分情况下,人们倾向于从正常流程去考虑工作量。
而事实上在开发过程中,所谓的“正常流程”才是不正常的。现实世界中有太多的不确定的因素可以让我们的应用崩溃或者停止工作——网络请求超时,地址服务器宕机,后端版本升级,浏览器的不兼容,操作系统的不兼容,不同的硬件环境,特定的浏览器版本(我最近工作的项目上,由于客户使用的kerberos鉴权机制导致只有Firefox的特定版本才可以正常访问应用)等等。
与之对应的正常流程反而如同在走钢丝。
既然异常无可避免,我们需要为其设计很精巧的保护机制,一方面需要让系统可以在错误中恢复(不至于白屏,或者禁用所有功能),另一方面还需要展示以及记录可靠且准确的信息以供修复(日志,前端的Modal,截图等等)。
7. 用户体验
功能之外,还有很多其他因素需要考虑。比如可用性(Accessibility)以及易用性(包括页面上字词的选择和用户体验),以及兼容性的考虑。一些常见的会影响开发工作量的因素包括:
- 跨浏览器支持
- 老旧的浏览器兼容
- 多设备支持
如果涉及响应式设计,则需要和UX进一步合作来确定实际方案。很多时候,多个设备上的交互模式都不尽相同,比如iPad上的hover效果,小尺寸屏幕上的字体等等。
03 技术之外的因素
除了技术上很难预见的延迟和障碍之外,实际项目中还有很多会消耗掉大量时间的事件,它们无处不在,细微而琐碎,但是累积起来产生的影响则相当可观。
1. 混乱才是常态
比如项目上有若干名同事:
const roster = [ '吴荣华', '侯晓成', '贾彦军', '邱俊涛' ]
从概率上来说,每个人都或多或少有些工作之外的事情要处理,比如偶尔休假,不太舒服在家休息,通勤路上堵车,或者在买咖啡排时迷路等等。
const excuses = [ '堵车了', '迟到了', '要接小孩', '不舒服,请半天假', '休假了' ]
而生活就像是这样一行代码:
${_.shuffle(roster)[0]} ${_.shuffle(excuses)[0]}
所以,我们眼中的世界就是这个样子的:
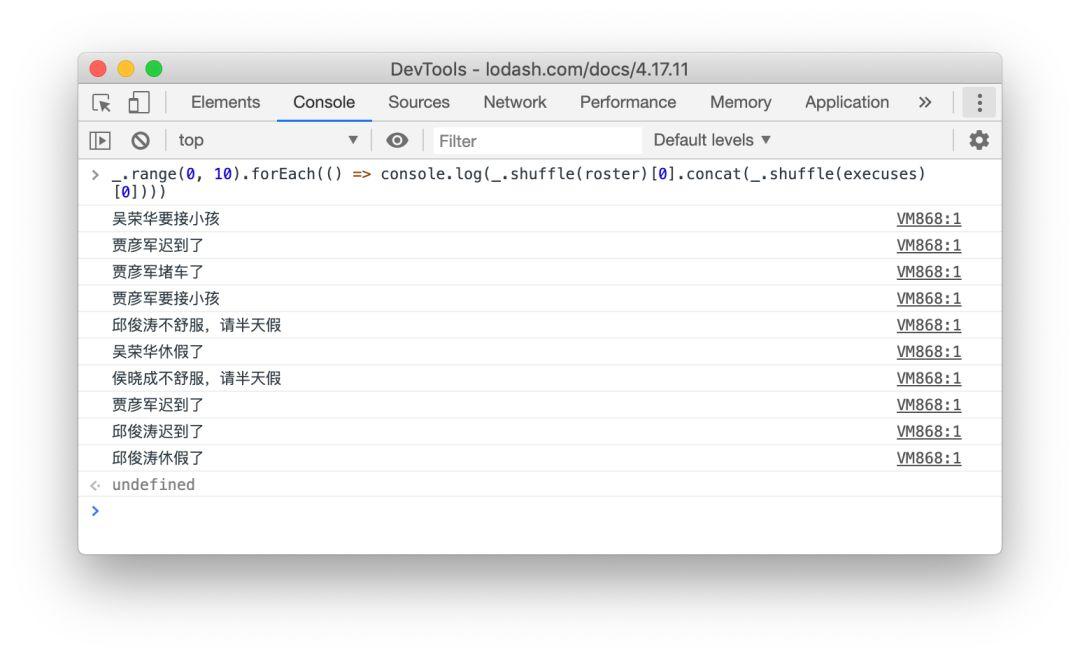
当然这些异常不会每天都发生,但是如果项目足够长,这些事情则几乎必然会发生。随着人员的增加,参与方的增加,不确定性随之提高,不是一切都正常的概率则会变得非常大。毕竟,混乱才是这个世界的常态。
而这些混乱可以让我们之前的估算失效,耗时增长。而这些混乱在估算之初则很难被我们看到,从而导致估算往往偏小。
2. 一个小故事
在几年前的一个项目上,我估计理想情况下大概需要三天来实现一个对某个资源的RESTful API,客户的技术负责人当时就怒了,说他自己写半天就可以写完,不就几个CURD嘛。
我帮他略为列了一些子任务之后,他陷入了沉思:
- Database migration脚本
- 实体类
- 实体类之间的关联
- Service/Controller类
- 异常处理
- 单元测试
- 与下游系统的契约
- 集成测试
我印象中这个任务花费的时间应该是多于三天的,因为光找其他团队的接口人要契约就花了一天半。
04 应对策略
通过上述的例子,相信大家已经看出评估失误的一些原因了,而要应对这些错误,大的原则当然是反其道而行之。
在具体的实践上,除了经验之外,一个可行的应对策略是足够程度的细化。通过细化事实上可以在一定程度上降低不确定性,使得很多原先没有看清楚的点被重新发现。
比如输入框的各种状态,状态之间的迁移,每个不同状态所涉及的样式等,通过细化(比如通过可视化的方式画出状态机),则很多细节自然浮现。
更进一步,如果涉及到数据的获取,那么对应的加载中,加载失败,无数据等等状态又会进一步驱动出更多的细节,从而潜在的可以产生更加客观的评估。
实践中,通过有限状态机的方式来描述穷举一个组件(或者一组互相关联组件)的状态是一个比较有效的方式,它可以更好的揭示组件的各种变体的形态和所需逻辑。

(图片来自:http://dwz.date/gcS)
另一方面,在心理上需要充分认识到现实世界的复杂程度,特别是涉及组织,相关方很多的时候,不确定性会非线性的增加,从而导致评估的失误。
这要求我们一方面要拥抱变化而不是对抗变化,另一方面驱使我们采用更简单的设计,更坚固的基础设施,质量更高的构建方法等等,从而更快速的响应变化。
05 小结
至此,相比你已经猜到,虽然开发在估算中以为自己已经留有足够buffer,事实上这个功能的实现必然超过一周。
在实际项目中,一方面由于知识壁垒和一些偏见,人们倾向于忽略必要的细节,从而造成对实际所需工作量错误的评估。
另一方面,由于我们所处于的现实世界是一个高度复杂,不确定性很高的环境,很多因素往往会互相叠加,互相影响,从而导致即使我们从比较客观的视角去评估,如果忽略了不确定性,同样可能低估实际所需的工作量。
我们可以通过足够细化的方式降低不确定性,从而提高估算的可靠性。
另一方面,还需要积极的拥抱混乱,通过更简单可靠的方式来构建软件,从而提高响应变化的能力。
P.S. 我本来计划着写这篇文章大概需要3天,结果画图就花了两个晚上。然后又去检查了之前的博客,确定相对于之前的类似观点有了一些提升,才开始写草稿(耗时两个晚上),然后又花了两个晚上来润色。
来源:https://mp.weixin.qq.com/s/cjONOqFZoVbmLSROWde7RQ
作者:邱俊涛;公众号: ThoughtWorks洞见
本文由@ThoughtWorks洞见 授权发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议









这篇文章想表达的应该是产品经理与开发之间的理解差异,并不是想说搜索框要这么久,这仅是一个例子而已
百度的搜索框吗?
输入限制和流程不是PO给的吗
说的这些我都明白,但一个输入框我也只会给一天时间去做
校验这些都能有公共方法实现,如果一个简单的输入框也要做一个礼拜,这个产品的执行力太差
一个细小的功能要做到完美,需要投入超常识的时间,怎么办?
1、完成比完美重要
2、理解核心需求与应用场景,团队协商,主动做减法
3、长期的积累提升复用率,这也是珍视自己时间的意义。
说的很有道理
说的很有道理,但是一周的时间做一个输入框大概会被炒吧
看题目,还以为说的是搜索
我开始还以为是搜索