
 起点课堂会员权益
起点课堂会员权益互联网征信的核心在于应用场景

初涉征信行业,对征信最初的印象还停留在几个关键词:靠谱、相信你、芝麻信用,很直白、很简单、甚至还有些”肤浅”。《左传·昭公八年》提到“君子之言,信而有征,故怨远于其身”。“信而有征”即可验证其言为信实,或征求、验证信用。描述地很久远、很专业,也很装B,但充分表达了信用的基本面:可验证。既然可“可验证”,那么信用必然不是无源之水。
由于刚接触征信行业不久,个人理解的征信也只能浅显地考虑到以下三个方面(3W):
一、征信验证什么?(WHAT)
征信的基本面——可验证,究竟验证什么呢?征信的核心是数据,而真实、可靠的描述性数据和结构化数据显得更加弥足珍贵。以单一维度评价一个人/组织显得很单薄、很平淡,不那么有说服力,拓宽数据来源场景,累积多维度的数据资源。
撇开企业征信不谈,个人征信领域的翘楚:芝麻信用、腾讯信用、51信用卡、 聚信立都携带特定消费场景的基因,并非完全意义上的综合征信评价模型。有一点必须承认:在其优势领域内有着得天独厚的先机优势,但数据单一性也不容忽视。以上四类征信场景分析如下:
1、 侧重电商
芝麻信用。以芝麻信用所构建的信用体系来看,芝麻信用分根据当前采集的个人用户信息进行加工、整理、计算后得出的信用评分。 综合考虑个人用户的信用历史、行为偏好、履约能力、身份特质、人脉关系五个维度的信息,其中淘宝、支付宝等“阿里系”的数据占 30-40%。数据的电商属性成就了电商领域的王者,也是其征信数据的短板之痛。
2、侧重社交
腾讯信用。主要是基于社交网络。通过QQ、微信、财付通、 QQ 空间、腾讯网、QQ 邮箱等社交网络上的大量信息, 比如在线时长、登录行为、虚拟财产、支付频率、购物习惯、社交行为等,利用其大数据平台 TD Bank,在不同数据源中, 采集并处理包括即时通信、 SNS、电商交易、虚拟消费、关系链、游戏行为、媒体行为和基础画像等数据,并利用统计学、传统机器学习的方法,得出用户信用得分,为用户建立基于互联网信息的个人征信报告。
3、侧重信用卡
51信用卡。主要是基于用户信用卡电子账单历史分析、电商及社交关系强交叉验证。 根据用户的信用卡数据、开放给平台的电商数据所对应的购买行为、手机运营商的通话情况、登记信息等取得多维信息的交叉验证,确定用户的风险等级以及是否贷款给该用户。
4、侧重运营商
聚信立。主要是基于互联网大数据,综合个人用户运营商数据、电商数据、公积金社保数据、学信网数据等,形成个人信用报告。 聚信立通过借款人授权,利用网页极速抓取技术获取各类用户个人数据,通过海量数据比对和分析,交叉验证,最终为金融机构提供用户的风险分析判断。
征信数据场景化,场景恰恰又是数据的最广泛来源。数据衍生于一定的生活和工作应用场景之上。尝试将征信扩展到更为广泛的场景之上,金融是征信被应用的最广泛的领域,衍生出这样一种说法:市场经济本质是信用经济,而征信的最核心本质:风险控制。
二、信用怎么验证?(HOW)
如何验证一个人/组织的信用好坏?不可能仅凭一句话:你的信用不错,你的信用挺好,就能评判一个用户的信用好坏,这显然是不合理的。虽说一家之言略显有理,也并非完全可信。在没有健全的法律法规、没有优秀的实践先例的情况下,国内征信均是根据市场需求和国外征信产品经验,以传统的“信用报告+增值服务”的商业模式来运营的。以央行征信中心为例:个人和企业征信报告+动产融资质押登记和应收账款融资服务等增值服务。
如何设计征信评价标准/尺度?传统的征信商业模式均采用——信用报告的模式,说白了就是将个人/企业信息进行整理输出,论技术含量和信息价值量都不是那么可观的。普通用户或许更加愿意接受简单、直观的征信产品形态,不需要洋洋洒洒的一纸文书,更不需要那些看不懂的专业评价内容。一个分数等级、一个评价体系简化面向用户的信用评分模型,其实并未减少评价模型背后的任何可能。蚂蚁金服的芝麻信用就是典型的信用分模型,而腾讯征信采用了信用评级的形式。信用分、信用评级概念上都简化了用户的理解和获取成本,这一点上可谓异曲同工;同时,直观的征信模型对信用场景也更加友好,应用场景更加宽泛。那么如何将背后无数信用数据变量整合成一个显性衍生变量呢?
互联网+金融(征信)更多融入到生活消费的各个领域,使得消费金融更具普惠性,拉近用户的距离,覆盖更多的中低端用户群体。
以消费金融_汽车贷款为例进行分析和思考:
- 用户故事:用户A想要购买一辆价值10万元的汽车,由于单次支出10万额度的压力太大,想要分期购车。
- 汽车企业:想要发展汽车贷款业务,为用户提供汽车贷款,最大化提高汽车销售的规模效益。
- 面临挑战:如何客观地评价贷款申请者的风险,尽可能避免、减少、控制贷款的坏账损失?
- 解决方案:信用评分模型——信用分,简洁、直白的风险控制因素。
5、信用分设计
5.1数据来源
a.基础数据:贷款人的个人信息;
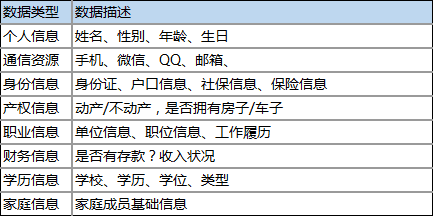
b.贷款信息:历史信用数据与场景中衍生的数据;

c.信用机构的信用历史纪录信息,即征信机构出具的个人信用报告;
5.2模型构想
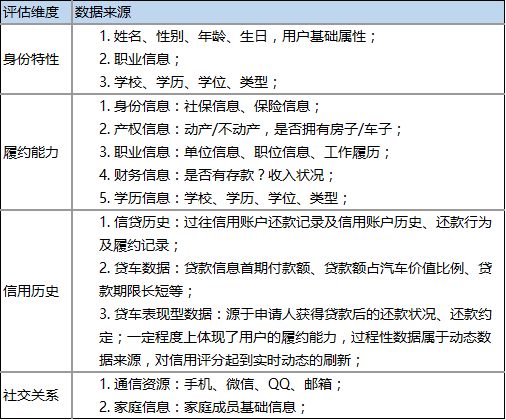
以上三大类数据来源可以实验性地综合出三个信用分评估维度:身份特性、履约能力、信用历史、社交关系;
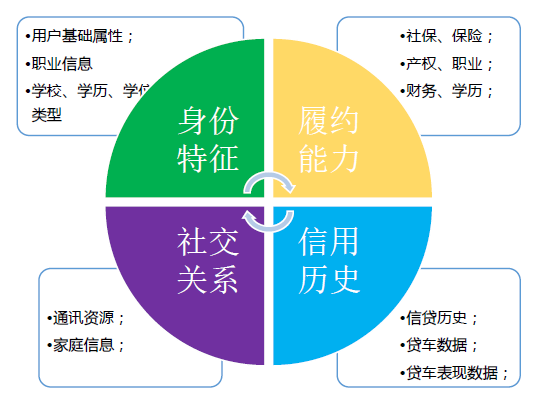
通过以上数据类型可以提炼出更多的数据分析维度,下面仅以上述四个征信评价维度为例。
5.3数据经营
以[职业信息]为分析对象,将[]职业信息]作为衡量用户[偿还能力]的维度,应该做哪些方面的思考。
从事什么职业?什么级别?在哪个行业?
1、什么职业类型,初步判断该用户的偿还潜力;具体的职位类别最终关联到用户实现价值,用户做什么,明确不同工作之间的差异,一定程度上可以区分不同人之间的经济能力。
2、什么职位级别,决定用户短期内的偿还实力;用户所在职位级别直接决定该用户的价值实现程度及获取价值的能力,以及该职位在公司实际所处的战略位置和重视程度。
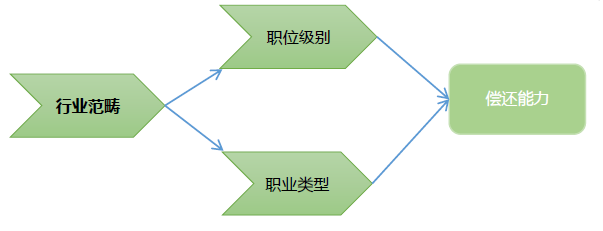
3、什么行业范畴,预判用户持续偿还能力愿望;尝试对该用户所处行业的发展现状及前景进行调研,给出该用户公司在该行业的综合水平。实际上,行业范畴给职业类型和职位级别都加上了相应的权重。
综上所述,职位、级别、行业基本决定用户现在及未来的“薪资水平”,而赚钱能力也直接关联用户的偿还能力。
5.4应用场景
以上构想的信用分征信评价模型,在消费金融_汽车贷款的应用场景大致包括以下几个方面:
- 批准/拒绝贷款申请
- 决定贷款额、首付额和贷款额占汽车价值的比例
- 决定贷款期限
- 决定贷款利率
根据用户所获得的信用分的高低,对以上不同场景进行相应的决策,降低汽车分期贷款的风险,最小化坏账率。
三、为什么验证?(WHY)
为什么要验证一个人/企业的信用?肯定是为了获得些什么,追求的是价值,具体的缘由我就不深究了。信而有征即可验证其言为信实,或征求、验证信用。首先,我们需要明确一个前提:征信,征什么?有很多声音说是数据,数据是征信机构的核心,数据质量是征信机构的生命线。正如前文所说——征信的最核心本质:风险控制,而所谓的“风控”也必然是基于一定的用户场景之上。
1. 征信最初的目的是为了防范风险、约束征信主体,而现实的风险往往来源于实际的场景之中,比如P2P网贷、京东白条、信用卡等等。征信本身并不具备价值,只有将征信嫁接在更为广泛的场景之上才能真正发挥信用价值。
2. 征信的另一个本质是数据分析,数据为主体。基础数据决定模型的最初的雏形,而模型的动态因子又使得模型呈现出一个动态变化的过程。将征信推向更加广泛的应用场景,累积征信模型成长性数据,实现模型的自迭代。
数据维度越多元,征信可靠性越高;征信可靠性越高,应用场景越广泛;应用场景越广泛,数据维度越多元。构建一个“以传统征信体系+大数据技术”的征信服务平台,向信用风险管理的其他领域纵深扩展,创造一个又一个的应用场景。
作者简介:王伟(微信号:Daviiwong)。专注工具和内容型产品,关注互联网金融、农村电商和财经领域。曾从事互联网金融社区的产品设计,目前涉足互联网征信产品。
本文由 @王伟 原创发布于人人都是产品经理。未经许可,禁止转载。









sorry,发错地方了。。。
空欢喜一场 😳
写的很棒, 看完了说下我的感想。论起社群,其实空格里社群的体现是蛮丰富的,但是却因为类目太杂,反而失了精准和高质量
写的不错啊,我也收藏了
非常感谢您的认同,大家多交流切磋!
收藏一下
非常感谢!