
 起点课堂会员权益
起点课堂会员权益
用户增长实验三部曲(3):策略效果分析中的两个代表性问题
 产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..
产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..本篇为实验三部曲的完结,主要供有一些实验经验、或者对实验感兴趣的同学了解。增长实验中,除了之前提到的“可比性”以外,还存在这样或那样的分析陷阱,文中主要讲两个代表性问题:正交分层及其局限性,SRM问题及其应对方法。

01 正交分层如何实现“平行宇宙”
在之前有关实验设计的文章中,我们简单提到过正交分层,它的作用在于将有限的用户数或流量,同时用于多个实验中而互不干扰。
理想情况下,正交分层体系中的每一层,就像是一个“平行宇宙”,可以各自进行独立的实验。在正交分层的体系里,一个用户很可能是同时被多个实验命中的。既然这样,如何能做到实验间没有互相干扰呢?
AB实验中的随机分组通过性能较好的哈希算法,将用户ID进行特殊转换处理,确保分组时尽可能做到随机。可以理解成对我们每个人的手机号做一些复杂处理,避免直接按照尾号分组时,出现尾号8用户群和尾号4用户群之间的样本有偏差。
随机分组是发生在每一个分层中的,而正交分层是指层与层之间需要保证正交性,有现成的检验方法,感兴趣的同学可以自行查找,此处先不做赘述。借助一系列正交哈希算法(目前较多采用正交表算法),我们可以保证任意两层之间的实验独立性。

如上图,假设我们选择同一个用户群体,任意取到若干正交分层中的两层:分别记为第N层和第N+1层。
我们决定对第N层进行AB实验,即将该层的用户随机分为A、B两组;同时我们再对第N+1层进行AB实验,记为A1、B1两组。
两组实验覆盖到的人群是一样的,我们下发不同的策略。正交分层能够做到第N层中的A组用户,在第N+1层随机分散到A1和B1两个组。当我们在分析第N+1层实验效果时,可以认为A1组和B1组所受到来自第N层策略的影响是相同的。因此,在分析A1、B1两组间的效果差异时,可以将来自其他层的影响忽略不计。
通过正交分层,我们可以做到样本量有限时,依然可以同时进行多组实验,这有助于我们更快速找到有效的策略。因此,正交分层也成为了成熟实验平台的标配。然而,并不是满足了正交分层,我们就可以认为可以无视不同层间的策略干扰,下面我们详细介绍。
02 正交分层存在局限性
正交分层若想保证策略间“无干扰”,还需要一个前提:不同层间策略的相关性需要尽可能低。先举个例子说明策略相关性。
比如,常见的给用户发红包的策略,假定策略1是每人发0.5元,策略2是每人发1.0元。这两个策略都是发红包,是高度相关的(本质上是同一类),其效果会产生干扰。
试想,如果我们实验时分别取一层来下发策略1,另一层与之正交,下发策略2。由第一部分的解释,策略2将会均匀的影响到策略1的实验组和对照组。就这个例子看,因为策略2下发的金额较高,效果大概率会好于策略1,所以当分析策略1效果时,很可能发现其实验组相比对照组没有提升,得到“发钱无效“的实验结论。其原因是策略1(弱策略)的实验组和对照组均匀的受到了策略2(强策略)的影响,而策略2覆盖掉了策略1的效果。
策略相关性难以准确量化,可以通过策略种类、参数是否会出现增强、削弱、替代等,来判断策略是否会存在相互影响。上面是一个典型的强策略覆盖弱策略的例子,它会让弱策略看起来是无效的。可见正交分层有其明显的局限性,即便是使用了正交分层,依然无法避免相关策略间的干扰。
下面再举一些常见的、需要注意的场景:
- 头条、抖音信息流,针对某特征设置不同权重的推荐算法实验。如果使用正交分层,权重较高的策略效果很可能覆盖权重较低的策略,得到低权重策略无效的结论
- 在百度搜索结果页中,用户点击会调起百度,这是一种常见的拉活方式(如下图)。对不同调起方式(例如点击百度知道、点击贴吧调起)做效果分析时,二者可能存在干扰。比如说,百度知道能够覆盖的关键词和问题更多,极有可能每一位搜索用户每天都会被它调起1次,而贴吧覆盖的搜索query相对少,使用正交分层去做这个实验(一层是点击知道调起,另一层是点击贴吧调起),很有可能会得到“通过贴吧调起百度App是无效的”这种结论
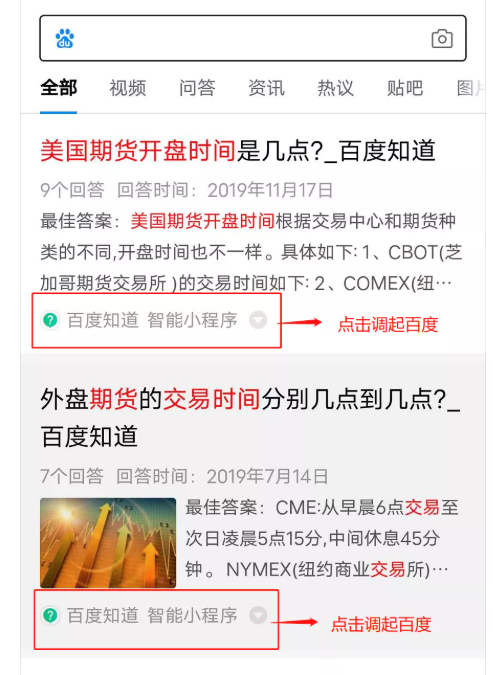
类似的情形,你还碰到哪些?
实验分析需要基于实验场景制定针对性的分析方法,更需要选择对正确的实验方式。当需要验证这种相关策略的差异时,建议使用同一层来进行分组,对每个组进行策略互斥的实验。
03 样本比率偏差问题
实验的样本比例偏差问题(Sample Ratio Mismatch,SRM)指实验组和对照组样本比例偏离预期,所带来的对实验分析结论的影响。平时大家可能没有特别关注SRM问题,但是它在很多环节都存在。有时它的差别可以忽略不计,有时却能够颠覆实验结论。我们先介绍SRM问题可能带来的影响,接着列举可能产生SRM问题的原因,以及应对方法。
SRM问题的核心,是实验组和对照组的实际比例和理论比例有所偏差,而分析时使用的是理论比例,这个偏差就使分析结果失真,严重时会得到错误结论。
比如,我们选取一个人群按照50%/50%的比例设计了实验组和对照组,这时的理论样本比例为1.0/1.0;假设实验下发过程中因为某种原因,部分的对照组也被策略影响(或污染)到了,使得实际的样本比例是1.05/0.95。这会造成什么后果?
如前面实验分析的文章所说,在分析效果时,需要以理论的样本比例为基础,来对比实验组与对照组的指标之差。也就是说,没做实验时,这个指标差应该是0,做了实验它会偏离0,这个偏离值大小就是实验带来的影响。这个例子中,便于理解不妨把实验前各组的指标都设为100(可以不用在意是什么),SRM问题的影响可概括如下表:
表1 SRM对实验结果分析的影响示例:
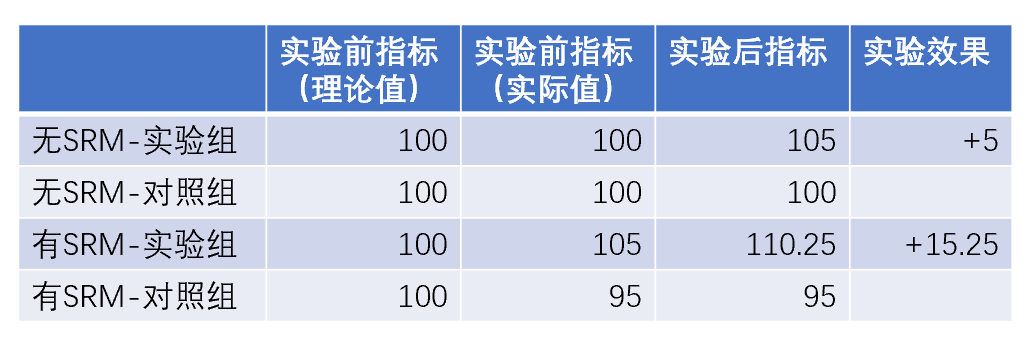
注:有SRM-实验组的实验后指标为105*1.05=110.25;其中1.05是策略的提升效果
如表1所示,这个例子中SRM问题将实验效果夸大了两倍以上,虽然实际工作中,SRM一般不会如例子中这么明显,但依然需要注意。
比如,实际样本比例是1.01/0.99,上述例子中实验效果偏差依然可以达到41%;而实际样本比例低至1.001/0.999,实验效果偏差也还有0.2%左右(感兴趣的同学可以自行计算)。判断样本偏差是否显著,可以使用卡方检验;而造成SRM问题的原因很多,也可能遍及实验各主要环节,下一小节将详细介绍。
04 SRM问题成因和应对
SRM问题存在于实验部署、执行、数据采集、实验分析等主要环节,以及实验时的外部干扰。这五个原因,来自一篇SRM论文的概括,我结合实践经验给出如下一些理解,如果大家对全文感兴趣可以进一步细读(文末参考文献)。
1. 实验部署
实验部署阶段,涉及到分层、分组的随机算法的性能和稳定性。包含但不限于能否完成理想的正交分层,能否完成大量、实时的随机分组,能否在一段时间后依然保持这种效率。这算是SRM问题产生的主要根源。此外,一些实时服务的Bug,也会导致分组不符合预期,实验平台在有重要迭代或修改后,尤其需要测试是否对分层分组产生影响。
2. 实验执行
实验部署完毕,下一步就需要下发策略,而下发策略需要对齐时机。假设客户端需要给用户展示两套UI,这个策略需要同时对实验组和对照组来下发,以避免下发时机不同带来的偏差。如果实验组下发完,再下发对照组,很可能两个时间段网络情况不一致、用户活跃度有差异,引发很多不必要的变量,最终会体现到实际样本比例的偏差上。
即使是同时下发,也需要注意避免引入“不必要的过滤条件”,比如我们经常会遇到的实验场景,A组下发某策略、B组不下发,如果实验具体执行时是A组下发而B组不下发,最后拿A组下发策略的用户来和B组对比,可能引入了一个“过滤条件”。因为A组并非100%能下发成功,如果拿A中下发成功的用户对比整个B组,可能会出错。如果A组下发策略,B组不是不发而是下发“空策略”,那么“下发成功”这一层过滤可以避免掉。
3. 数据采集
这里主要关注实验组和对照组的数据上报是否一致、是否准确,数据存取过程是否可靠。这些需要实验平台、策略下发平台、用户端产品联动来检查确认,并且每增加一个需要实验的功能点、资源位,都需要确保数据上报的方式、数据质量是否能满足未来实验分析的要求,即数据可比性。
4. 实验分析
分析过程中的SRM问题,类似于前面提到的不满足“可比性”,即分析时因为一些样本偏差被忽视,以理论的样本比例进行分析造成的错误。这里具体会涉及到分析起点问题——即选取那两个人群进行对比,一般需要从样本源头来分析,保证可比性。这个问题比较宽泛,我们后面结合一些具体案例继续讨论。
5. 外部干扰
外部干扰通常来自用于实验设计之外的不可控因素。比如AB两套落地页实验,其中一套不小心被用到了其他活动,分析时,实际样本比例就会和理论值有较大的偏差。
上面提到的造成SRM的可能原因,可以简单的分为两类来处理:哪些是实验平台需要克服,哪些是实验分析需要注意。表2做了简要的梳理。
表2 主要的SRM问题原因及应对方法:
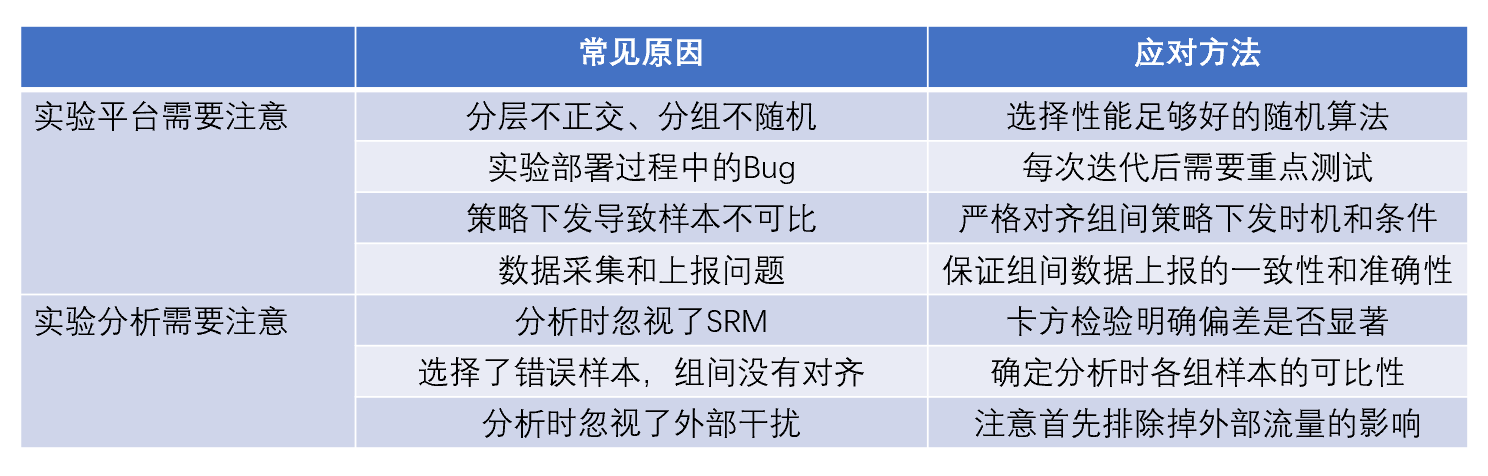
SRM问题的产生原因很多,但其最终影响到实验分析结果时,都是通过破坏了实验组和对照组间的“可比性”来实现,和我们之前提到的很多分析错误可谓殊途同归。实验平台设计和实验分析时,需要针对具体问题来找合适的应对方法。
以上是我个人理解,经验和能力所限,难免会一些偏差或错误,还请指出。
参考文献
Diagnosing Sample Ratio Mismatch in Online Controlled Experiments: A Taxonomy and Rules of Thumb for Practitioners
相关阅读
《用户增长实验三部曲(2):如何准确评估「产品和运营策略」的效果? 》
作者:jinlei886;5年+用户增长的一手经验,前腾讯、滴滴出行用户增长产品经理,专注增长策略挖掘、增长工具搭建、实验设计分析。本硕博均就读于浙江大学高分子系。微信公众号:用户增长实战笔记
本文由 @jinlei886 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议







- 目前还没评论,等你发挥!









