
 起点课堂会员权益
起点课堂会员权益A/B测试算法大揭秘第四篇:置信区间究竟是怎么来的?

当你的试验已经跑了一段时间之后,需要通过分析数据来看不同版本的行为数据表现,从而决策出最优版本。那么如何才能在已有数据基础上,进行科学可信的统计推断呢?我们将采用置信区间这个工具。它是与P-value相关的一个概念,但比P-value给出的信息更多。所以这一章,我们就将详细介绍置信区间的概念、计算方法以及它在A/B测试中的意义。
置信区间的概念
置信区间(Confidence Interval)是用来对一个概率样本的总体参数进行区间估计的样本均值范围,它展现了这个均值范围包含总体参数的概率,这个概率称为置信水平。
置信水平代表了估计的可靠度,一般而言,我们采用 95% 的置信水平进行区间估计。
置信区间的计算方法
根据统计学的中心极限定理,样本均值的抽样分布呈正态分布。
由之前介绍的t检验大样本检验公式计算得出Z值,再根据两个总体的均值、标准差和样本大小,利用以下公式即可求出两个总体均值差的95%置信区间。
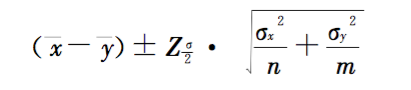
置信区间在A/B测试中的意义
置信区间的不同表现,可用作判断试验结果显著与否的标准:在试验运行一段时间之后(一般来说是1-2周),如果置信区间的上下限同为正,说明试验结果是统计显著的,并且试验版本优于对照版本;如果同为负,试验结果也是统计显著的,且对照版本优于试验版本;如果置信区间为一正一负,则说明版本间差异不大。
举个例子,当两个不同版本都以7%的小流量运行时,A版本的用户总数(样本大小)为33771,均值为23.01,标准差为53.21;B版本的用户总数(样本大小)为34190,均值为22.11,标准差为50.21。
我们可以计算出这两个均值比较得到的变化百分值为-3.9%,但这只是根据两个点估计计算出的新的点估计,是有误差的,所以我们就必须找到一个概率范围,来准确描述结果。
计算出Z值为2.28,再根据置信区间的计算公式,我们可以得出结果为-1.678,-0.112,即这个区间有95%的可能性包含两个总体均值之差。为了更直观,我们把这个总体均值差的置信区间转换为相比A版本均值变化的百分比置信区间,即-7.3%,-0.5%。这时候我们就可以评价试验的结果为:B版本不如A版本,并且有95%的可能性是差了0.5%到7.3%之间。
值得注意的是,置信区间同为正或负,只能说明试验是统计显著的(也就是试验版本和对照版本有差异),但是这个差异有可能是非常小的,在实际应用中微不足道的。因此,只有兼备统计显著和效果显著两个特征的结果,才能说明该版本是可用,值得发布的。
至于如何判定结果是否是效果显著,则需要结合我们在下一章中介绍的统计功效来综合考量了。
作者:吆喝科技,微信公众号(appadhoc)。
本文由 @吆喝科技 原创发布于人人都是产品经理。未经许可,禁止转载。









如果置信区间的上下限同为正,说明试验结果是统计显著的,并且试验版本优于对照版本;如果同为负,试验结果也是统计显著的,且对照版本优于试验版本;如果置信区间为一正一负,则说明版本间差异不大
为啥?
测试用例