
 起点课堂会员权益
起点课堂会员权益AI产品经理 VS 数据产品经理,看这5点区别与联系
本篇从4点区别,产品目标的区别、产品实战过程的区别、算法模型实战区别、产品经理驾驭难易程度区别,和1点联系的实战多案例鉴别AI产品经理与数据产品经理的区别与联系,并通过多个实战案例掌握数据产品经理和AI产品经理各自的技能。

人工智能快速渗入到各个行业,AI 产品经理缺口高达 6.8 万,成为稀缺人才。「AI 产品经理」项目面向想要通过AI 技术推动业务发展的产品经理以及商业领导者。
将介绍如何创建能带来商业价值的 AI 产品,学习 AI 产品开发流程。你将跟LineLian学习案例研究、创建数据集,并构建AI模型,熟练掌握各种 AI 概念和实用技能并能够构思、开发、评估和实施基于人工智能技术的新产品。
而数据产品经理也是时下的热门岗位。
两者关系是,AI产品经理以数据为基础,数据产品经理发展的晋级阶段是AI产品经理。
第一点区别:产品目标不同
有时候产品经理不得不拍着胸脯提需求,常常会遭遇多方的质疑,这个需求靠谱吗?有时候产品上线后大家感觉应该一片欢喜,但是公司却没有带来很好的商业增长;
当增长遇瓶颈;当产品不能精准的推荐给用户;当生产效率变低;当产品经理不能预测新的产品需求和新的服务需求;当人力成本变高,当有些固定流程的工作可以被机器人代替;
前类主要是数据产品经理要解决的问题,通过数据来验证产品提出的产品需求的正确性,通过上线后的数据来发现产品需要迭代改进甚至创新的点,通过数据分析,数据挖掘发现原本发现不了的产品问题,改进问题。
后类主要是AI产品经理的产品目标,AI一方面能帮人节省时间,另外能预测原本发现不了的产品和服务需求,还有AI能够解决不确定性的产品服务需求。
数据产品经理的产品目标是用数据确认确定性的需求;AI产品经理的产品目标是创造性的解决不确定性的产品需求。
第二点区别:产品实战过程不同
先讲数据产品经理的产品过程,再看AI产品经理的产品过程。
数据产品经理的数据分析的步骤一般可以分为如下6个步骤:
- 明确分析的目的
- 数据准备
- 数据清洗
- 数据分析
- 数据可视化
- 分析报告
数据产品经理案例:朝阳医院医药销售情况数据分析经典案例拆解
1. 分析目的
通过对朝阳区医院的药品销售数据的分析,了解朝阳医院的患者的月均消费次数,月均消费金额、客单价以及消费趋势、需求量前几位的药品等。
2. 数据导入
从笔者LineLian本地读取数据,如果需要数据分析进一步的可以点击文章最后的链接。
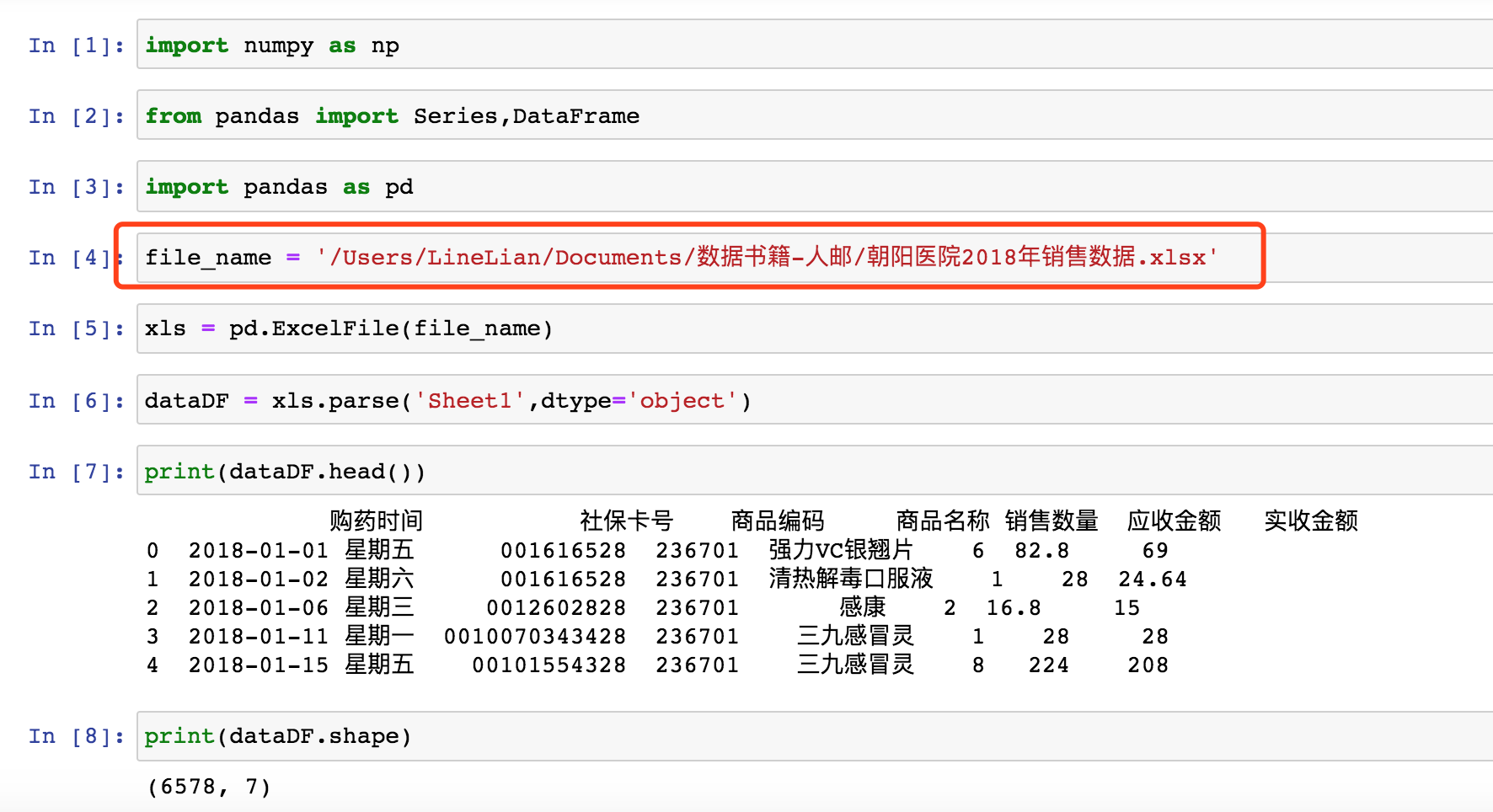
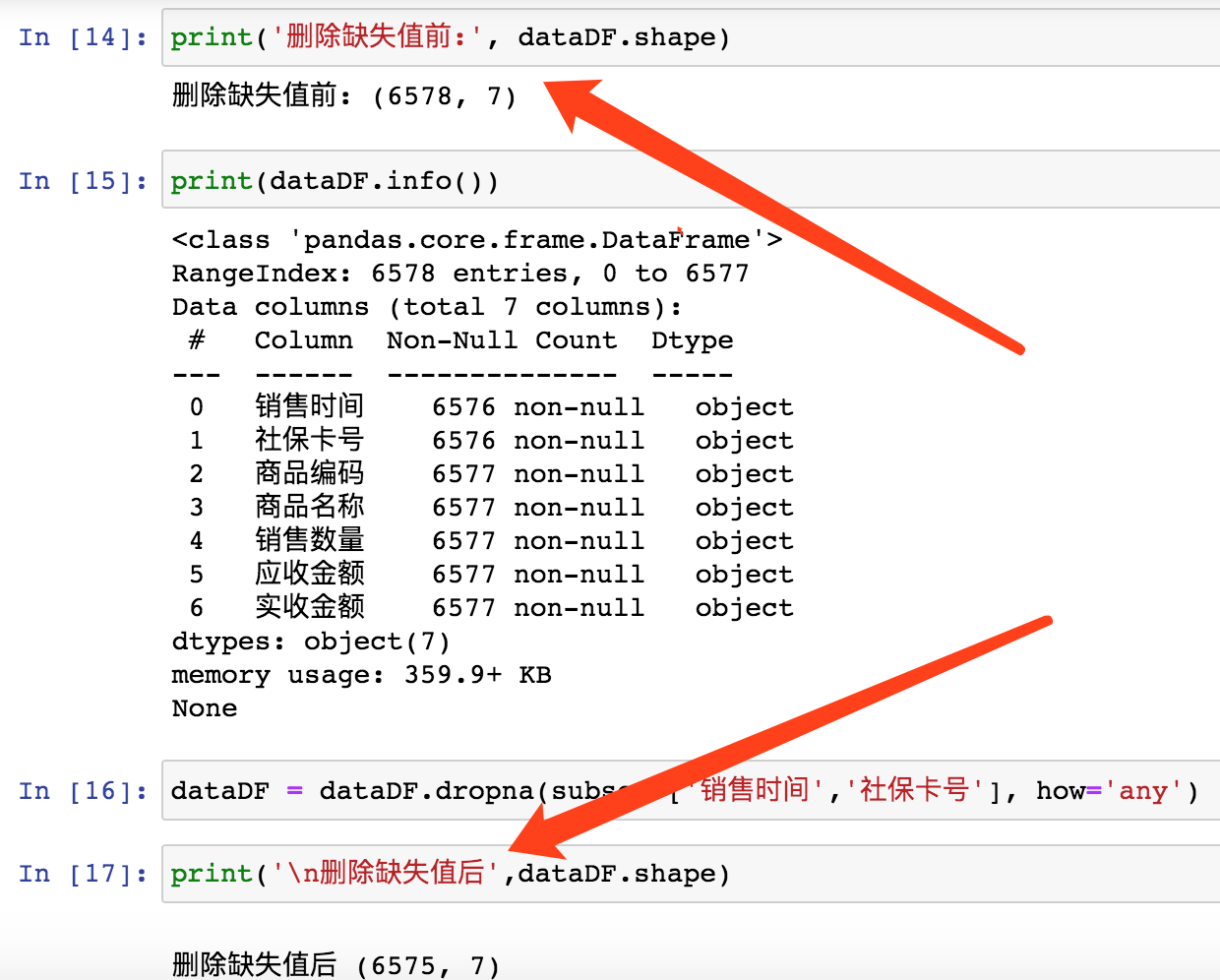
3. 数据清洗
数据清洗包含,行缺失值、列缺失值、异常值如不该出现负值出现了负值,不该过大不该过小等异常值的清洗、数据列名的修改变更、数据类型的转换、数据重新抽取排序等等清洗。
4. 数据分析
数据产品经理的数据分析主要是数据对应的业务分析,数据场景分析,常由数据产经理提出产品分析方案,例如本案例中,月均消费次数的业务定义计算方式是:月均消费次数 = 总消费次数 / 月份数;
月均消费金额的业务定义计算方式是:月均消费金额 = 总消费金额 / 月份数;客单价业务定义计算方式是:客单价 = 总消费金额 / 总消费次数。等等

5. 数据可视化
对于擅长形象思维的同学来说,文不如图,图不如视频,数据可视化就是讲数据分析的文变成形象的图或者变成可视化直观化的结构呈现的更直接明了。
例如本案例中药品销售前十的情况如下图:
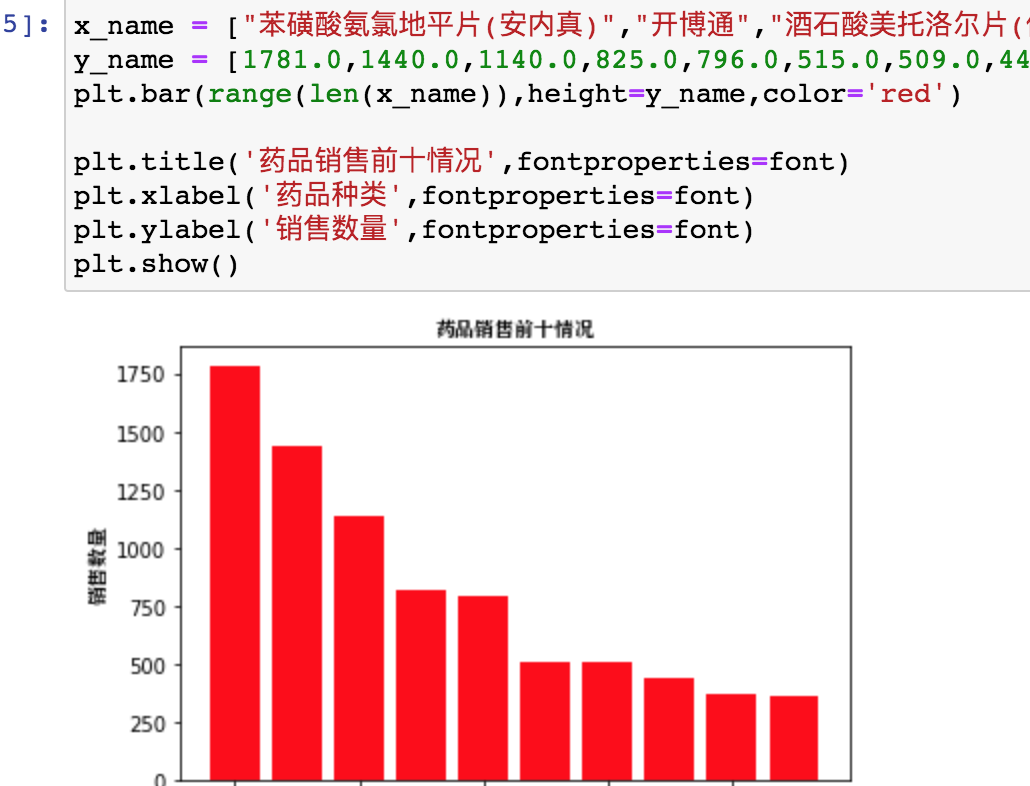
6. 产品数据分析报告
产品数据分析报告无固定的形式,根据笔者的经验有的专家直接带着一张嘴也行,有的写成PPT,有的用Word文档,有的则是PDF,有的是个其他的文档或者图片。
AI产品经理案例:
AI产品内容领域增长方向更加明显,根据笔者LineLian实际工作发现有以下几个产品实战过程方案。
- 神经网络、机器学习、深度学习以软件为主的产品;
- 机器人、芯片、智能硬件、软硬件协同类的产品;
- 具有行业经验以场景驱动寻找AI赋能;
- 以AI算法创新为主。
本篇先讲以神经网络、机器学习、深度学习软件为主的产品方案解决过程。
AI产品经理案例:训练神经网络经典案例拆解
- 选定一个基础模型
- 设定初始化参数代入模型
- 用训练集对模型进行训练
- 通过一些数量指标,评估训练误差
- 如果训练误差不满足要求,继续调整参数
- 重复7–8次
- 采集新的数据,生成新的数据集。
(1)选定一个基础模型
本篇选择sklearn.neural作为基础训练模型框架。如下图

(2)设定初始化参数代入模型
设置神经网络模型参数,隐藏层坐标大小(50,50)。

(3)训练出模型,用训练集对模型进行训练
导入数据,需要如下图中数据集的同学请观看笔者的微信公众号LineLian数智产品窗口。

一次训练模型,采用训练集数据训练MLP分类器模型
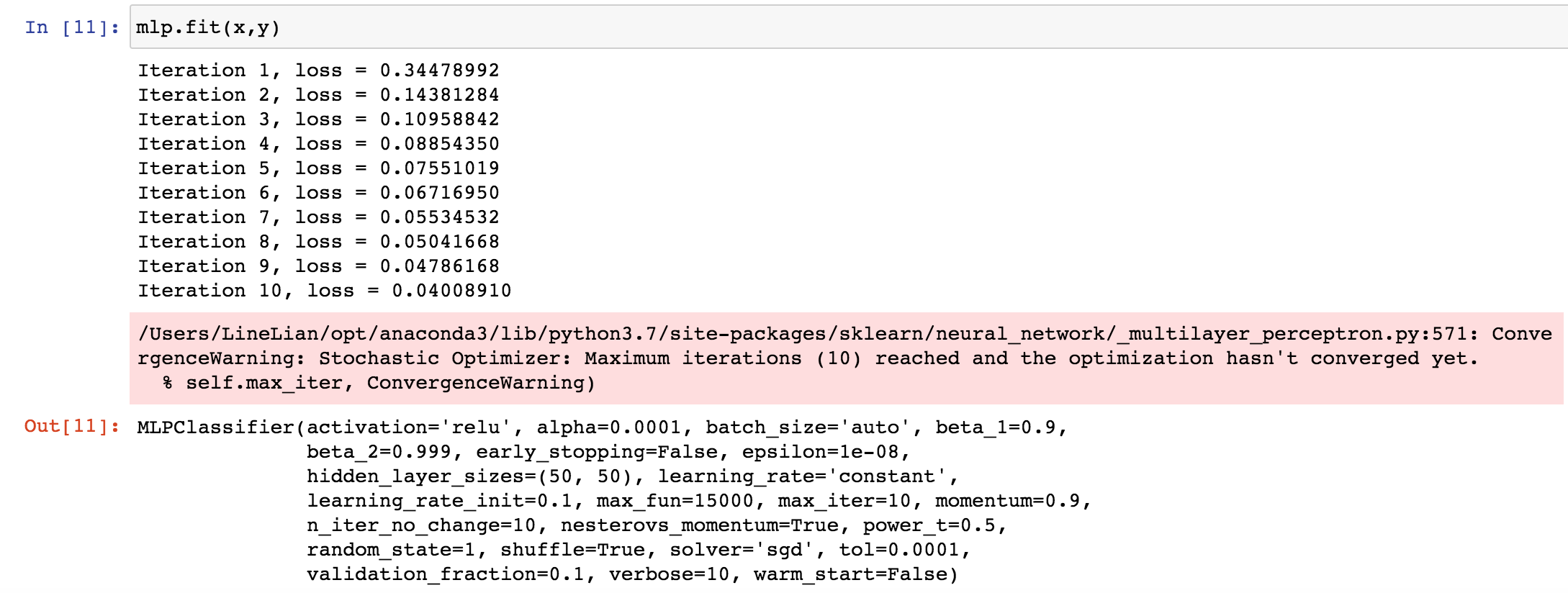
一次查看模型训练结果

将一次训练的模型保存
(4)通过一些数量指标,评估训练误差
通过准确率数据、通过绘制误差曲线等等评估模型训练效率。

(5)如果训练误差不满足要求,继续调整参数
重新优化节点数等参数,再次训练模型

(6)重复7–8
重新调整,坐标、节点、训练次数等参数、超参数,重复训练模型,最终选择优秀的模型备用。
(7)选择新的数据,生成新的数据集
本篇使用的是著名的MINST数据集,如果需要请关注笔者的微信公众号LineLian数智产品窗口。
针对这个图像数据集存在的问题比较明显,1.训练的数据数量;2.数据标注的质量;鉴于此,可以使用自己的自有Label数据集重新训练新的模型。
第三点区别:算法模型不同
数据产品经理常用的算法如下:
对于数据分析所采用的的算法非常多,主要是解决验证性和确定性问题的算法,例如:回归、三次多项式等等算法均可以属于数据产品经理采用的数据分析算法。
1. RFM算法模型
RFM模型想必很多搞数据做产品运营的同学都听说过,最常用在用户分层管理中。而且很多提到RFM模型都会动不动就祭出。
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。
2. CART: 分类与回归树
CART, Classification and Regression Trees。
在分类树下面有两个关键的思想:第一个 是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
3. K-Means算法
k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割(k < n)。
它与处理混合正态分布的最大期望算法(本十大算法第五条)很相似,因为他们都试图找到数据中自然聚类的中心。
它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。
4. 关联规则Apriori算法
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
5. SVM支持向量机
支持向量机,英文为Support Vector Machine,简称SV机(论文中一般简称SVM)。
它是一种监督式学习的方法,它广泛的应用于统计分类以及回归分析中。支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。一个极好的指南是C.J.C Burges的《模式识别支持向量机指南》。van der Walt 和 Barnard 将支持向量机和其他分类器进行了比较。
6. 最大期望(EM)算法
在统计计算中,最大期望 (EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variabl)。最大期望经常用在机器学习和计算机视觉数据集聚(Data Clustering)领域。
7. PageRank算法
PageRank是Google算法的重要内容。2001年9月被授予美国专利,专利人是Google创始人之一拉里•佩奇(Larry Page)。因此,PageRank里的page不是指网页,而是指佩奇,即这个等级方法是以佩奇来命名的。PageRank根据网站的外部链接和内部链接的数量和质量,衡量网站的价值。
PageRank背后的概念是,每个到页面的链接都是对该页面的一次投票,被链接的越多,就意味着被其他网站投票越多。这个就是所谓的“链接流行度”——衡量多少人愿意将他们的网站和你的网站挂钩。PageRank这个概念引自学术中一篇论文的被引述的频度——即被别人引述的次数越多,一般判断这篇论文的权威性就越高。
8. AdaBoost 迭代算法
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。
9. 其他数据分析算法模型
AI产品经理常用的算法如下:
(1)神经网络算法模型
起步神经网络算法( Neural Network )是机器学习中非常非常重要的算法。这是整个深度学习的核心算法,深度学习就是根据神经网络算法进行的一个应用特例。某种程度上来说AI产品的入门在于对神经网络算法的理解和应用。
(2)机器学习算法模型 Maching learning
机器学习的对象是:具有一定的统计规律的数据。
机器学习根据任务类型,可以划分为:
- 监督学习任务:从已标记的训练数据来训练模型。主要分为:分类任务、回归任务、序列标注任务。
- 无监督学习任务:从未标记的训练数据来训练模型。主要分为:聚类任务、降维任务。
- 半监督学习任务:用大量的未标记训练数据和少量的已标记数据来训练模型。
- 强化学习任务:从系统与环境的大量交互知识中训练模型。
机器学习根据算法类型,可以划分为:
- 传统统计数据学习:基于数学模型的机器学习方法。包括SVM、逻辑回归、决策树等。
这一类算法基于严格的数学推理,具有可解释性强、运行速度快、可应用于小规模数据集的特点。
(3)深度学习DeepLearning
深度学习:基于神经网络的机器学习方法。包括前馈神经网络、卷积神经网络、递归神经网络等。
这一类算法基于神经网络,可解释性较差,强烈依赖于数据集规模。但是这类算法在语音、视觉、自然语言等领域非常成功。
没有免费的午餐定理(No Free Lunch Theorem:NFL):对于一个学习算法A,如果在某些问题上它比算法B好,那么必然存在另一些问题,在那些问题中B比A更好。
(4)CNN
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
(5)RNN
循环神经网络(Recurrent neural network:RNN)是神经网络的一种。单纯的RNN因为无法处理随着递归,权重指数级爆炸或梯度消失问题,难以捕捉长期时间关联;而结合不同的LSTM可以很好解决这个问题。
时间循环神经网络可以描述动态时间行为,因为和前馈神经网络(feedforward neural network)接受较特定结构的输入不同,RNN将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。手写识别是最早成功利用RNN的研究结果。
(6)GNN
图神经网络,图神经网络划分为五大类别,分别是:图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks)。
(7)其他神经网络。
第四点区别:产品经理驾驭难度不同
产品经理驾驭产品的难易程度参考下图:
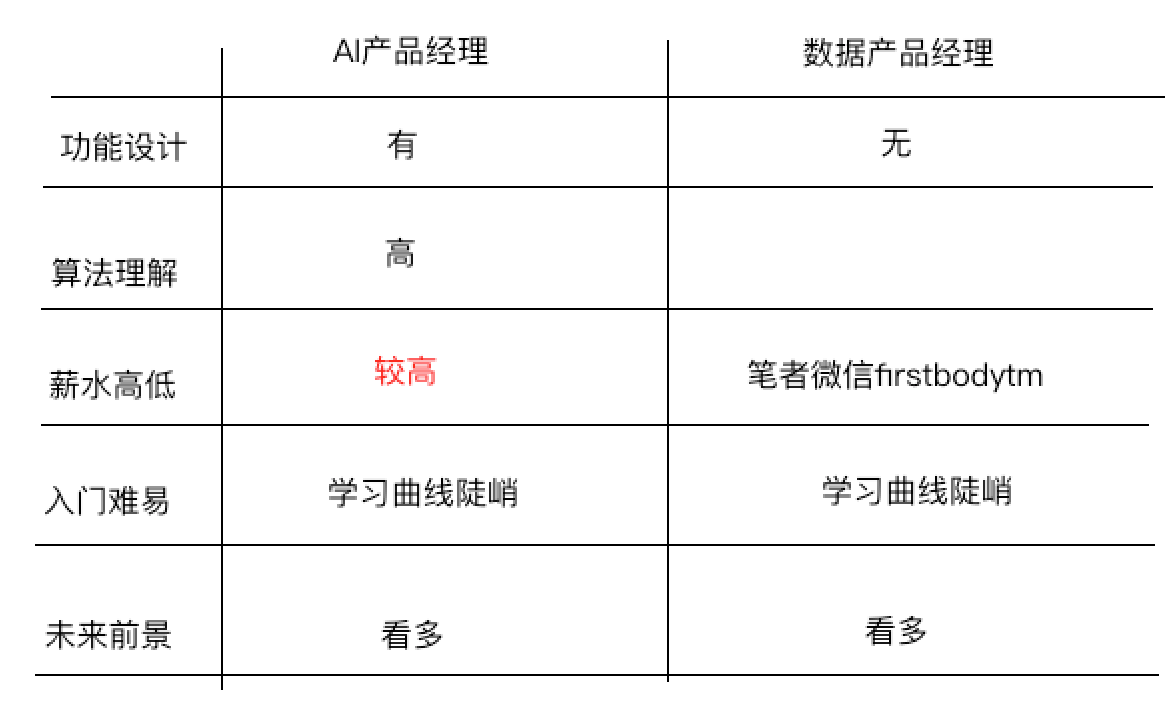
第五点联系:最后AI产品经理与数据产品经理既有区别也有联系
联系是:数据产品经理常用的元素数据是AI产品经理常用的元素数据+算法+算力三元素之一。
做好数据产品经理是为了今天的饭碗,做好AI产品经理是为了明天的希望。两者都很重要。
总之AI产品经理和数据产品经理是唇齿相依的关系!
#专栏作家#
连诗路,公众号:LineLian。人人都是产品经理专栏作家,《产品进化论:AI+时代产品经理的思维方法》一书作者,前阿里产品专家,希望与创业者多多交流。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash, 基于CC0协议









老师,好: 看到您举的例子,觉得更像数据分析师 以及 算法工程师 的工作, 那么请问 您认为 这些开发工程师 和产品的区别在哪里呢?
赞同啊。数据产品经理就是数据分析师么?AI产品经理还需要参与算法的训练么?
大家期待已久的《数据产品经理实战训练营》终于在起点学院(人人都是产品经理旗下教育机构)上线啦!经过迭代优化,现在已经第7期开启报名啦
本课程非常适合新手数据产品经理,或者想要转岗的产品经理、数据分析师、研发、产品运营等人群。
课程会从基础概念,到核心技能,再通过典型数据分析平台的实战,帮助大家构建完整的知识体系,掌握数据产品经理的基本功。
学完后你会掌握怎么建指标体系、指标字典,如何设计数据埋点、保证数据质量,规划大数据分析平台等实际工作技能~
现在就添加空空老师(微信id:anne012520),咨询课程详情并领取福利优惠吧!
连老师,我很喜欢你的课
当前公司业务系统中没有ai产品经理的业务场景,想请教一下该如何尽快入门ai或者数据产品经理呢?