
 起点课堂会员权益
起点课堂会员权益
【A/B测试算法大揭秘】第五篇:少了它,版本决策将毫无意义
 B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
从一切的根基中心极限定理,到如何根据数据分析解读最终选出真正意义上的最优版本,相信大家能够对A/B测试的原理有一个大概的了解。
关于如何避免假设检验中第I类错误,我们引入了P-value和置信区间的概念。而想要降低假设检验中第II类错误的出现概率β(Beta),就需要了解今天文章中讲解的另一个检验工具——统计功效。
什么是统计功效

在假设检验中,第II类错误的定义是:当原假设为假时没有拒绝原假设。也就是说,当两个版本确实有比较显著的差异时,我们并没有判断这两个版本有区别。
统计学中,将第II类错误的概率命名为 β(Beta),统计功效Power就是我们没有犯第II类错误的概率(1-β)。换句话说,我们设计了两个版本,需要对比两个版本带来的效应差异,如果假定的效应差异的确存在,在给定的置信水平α下,我们有多大的概率能得到统计显著性的结果,或者说我们有多大概率能发现这个差异。
为了提高原假设为假时我们做出正确判断(拒绝原假设)的概率,使结果更加可靠,统计功效的值越大越好。一般来说,当统计功效取到80%~95%时,结果就是比较可信的了。
统计功效的意义
由统计功效的计算公式可知,统计功效的值与样本量、方差、效应大小以及显著性标准α相互关联。换句话说,只要得知上述公式中的几个数据值,就可以根据公式推导,计算出想要探求的数值。
例如:通过给定的统计功效值,就可以推算出A/B测试中每个版本样本用户数的最小值。之后,将计算出的最小样本数与版本的实际用户数量进行对比。若版本用户数超过最小样本数,则说明统计功效足够,可以得出试验的最后结论。
究竟哪个版本才是值得发布的
上一章中,我们讲述了如何判断试验版本的结果是否是统计显著的。然而,只有当试验版本的结果兼备统计显著和效果显著两个特征时,才说明这个试验的结束时机已经成熟,该版本是真正值得发布的。因此,我们需要引入一个“最小重要变化”的概念来帮助我们判断和决策。
用白话翻译一下,就好比:你前期先投入了50块钱置办设备,每个包子定价5元。所以,只有在卖掉了10个包子(收入50元)之后,你策划并实施的这个事件才正式进入了盈利阶段。道理很简单,其实就是回本了嘛!那么在整个事件里,“收入50元”就是这个事件中的“最小重要变化”,也就是一个最小的可接受效果标准。
同理推论到企业的A/B测试,就更需要考虑相关的成本问题(有时甚至远不止于此)。因此,只有检测到的效果差异在“最小重要变化”的标准之上,我们才认为这个版本是有实际价值的。这个标准通常由指标的具体意义和我们的优化需求来确定,例如1%或者5%。
下面我们来看一个具体案例:
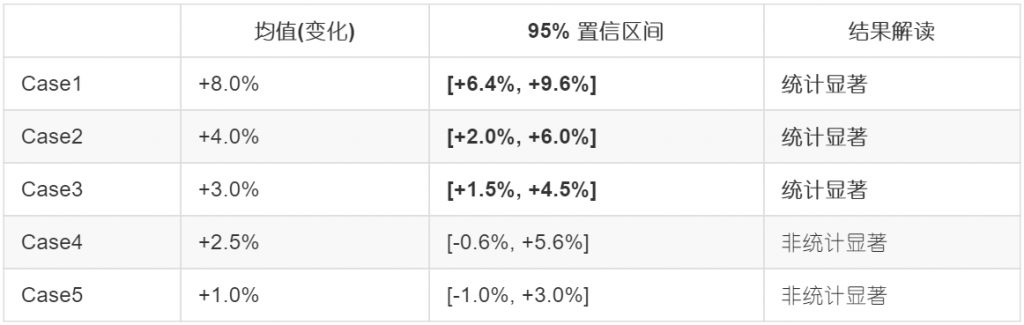
这是5个不同版本的试验数据,在最小重要变化为5%的情况下,我们可以应用这个标准来对试验数据做进一步的判断:
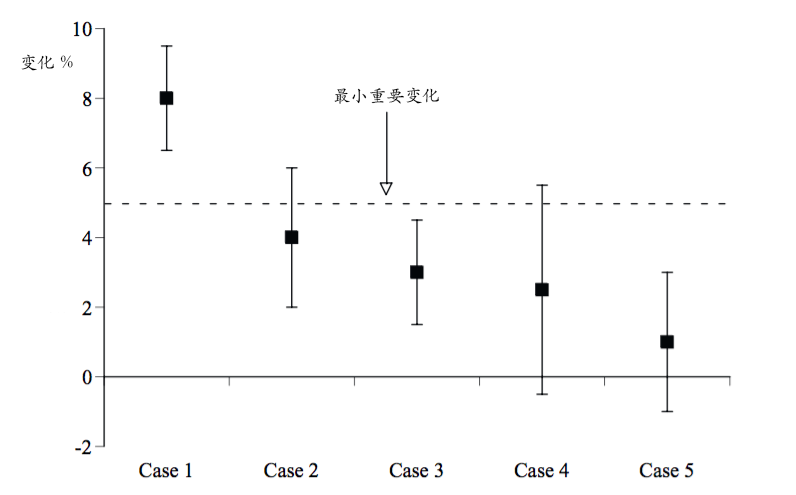
首先,观察每个版本的置信区间,发现Case4和Case5的置信区间不闭合,所以方案不可用,而Case1-3的置信区间上下限均为正,说明这三个版本相比原始版本来说都有提升。再引入最小重要变化5%,可以看到只有Case1的区间下限高于标准值。因此,我们判断,在最小重要变化为5%的情况下,只有Case1是实际效果最佳的版本。
关于置信区间的系列讲解到今天就算告一段落了,从一切的根基中心极限定理,到如何根据数据分析解读最终选出真正意义上的最优版本,相信大家能够对A/B测试的原理有一个大概的了解。
作者:吆喝科技,微信公众号(appadhoc)。
本文由 @吆喝科技 原创发布于人人都是产品经理。未经许可,禁止转载。



















测试用例