
 起点课堂会员权益
起点课堂会员权益数仓数据质量管理,需要注意哪些问题?
接着上次聊的企业数仓数据质量管理流程,我们来详细聊聊数仓数据质量管理的各个环节我们都该考虑哪些问题?做哪些事情?怎么做?

一、数据资产等级划分
1. 等级定义
根据“当数据质量不满足完整性、准确性、一致性、及时性时,对业务的影响程度大小”来划分数据的资产等级。
- 毁灭性:数据一旦出错,会引起巨大的资产损失,面临重大收益受损等。标记为L1
- 全局性:数据用于集团业务、企业级效果评估和重要决策任务等。标记为L2
- 局部性:数据用于某个业务线的日常运营、分析报告等,如果出现问题会给该业务线造成一定的影响或影响其工作效率。标记为L3
- 一般性:数据用于日常数据分析,出现问题的带来的影响很小。标记为L4
- 未知性质:无法追溯数据的应用场景。标记为Lx
重要程度:L1>L2>L3>L4>Lx。如果一份数据出现在多个应用场景中,则根据其最重要程度进行标记。
2. 等级划分
(1)分析数据链路
定义数据资产等级后,我们可以从数据流程链路开始进行数据资产等级标记,完成数据资产等级确认,给不同的数据定义不同的重要程度。
通用的数据流转链路流程如下图所示:

(2)标记数据资产等级
在所有数据链路上,整理出消费各个表的应用业务。通过给这些应用业务划分数据资产等级,结合数据的上下游依赖关系,将整个链路打上某一类资产等级标签。
举例:
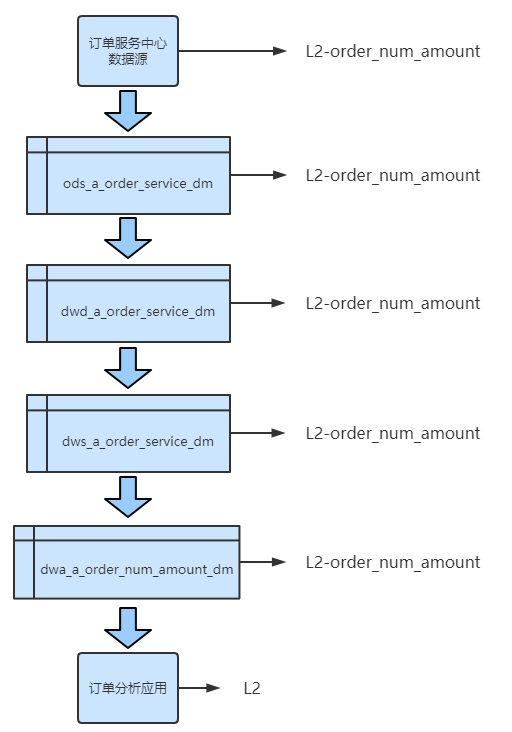
假设公司有统一的订单服务中心。应用层的应用业务是按照业务线,商品类型和地域统计公司的订单数量和订单金额,命名为order_num_amount。假设该应用汇影响到整个企业的重要业务决策,我们可以把应用定级为L2,从而整个数据链路上的表的数据等级,都可以标记为L2-order_num_amount,一直标记到源数据业务系统,如下图所示:
二、数据加工过程校验
1. 在线系统数据校验
在线业务系统声场的数据是数据仓库的主要数据来源。当在线业务系统功能迭代时,每次变更都会导致业务数据的变化。因此,数仓需要采取相应的措施来适应业务系统的复杂多变,及时保障数据的准确性。
我们可以通过工具+人员管理并行的方式来尽可能的解决以上问题:既使用工具捕捉业务的每次变更,也要求业务开发部门及时通知到数据部门所发生的业务变更内容。
(1)业务上线发布平台
监控业务上线发布平台上的重大业务变更,通过订阅这个发布过程,及时将变更内容通知到数据部门。
由于业务系统复杂多变,若日常发布变更频繁,那么每次都通知数据部门,会造成不必要的资源浪费。这时,我们可以使用之前已经完成标记的数据资产等级标签,针对涉及高等级数据应用的数据资产,整理出哪些类型的业务变更会影响数据的加工或者影响数据统计口径的调整,则这些情况都必须及时通知到数据部门。
如果公司没有自己的业务发布平台,那么就需要与业务部门约定好,针对高等级的数据资产的业务变更,需要以邮件或者其他书面的说明及时反馈到数据部门。
(2)相关操作人员管理
工具只是辅助监管的一种手段,而使用工具的人员才是核心。数据资产等级的上下游打通过程需要通知给在线业务系统开发人员,使其知道哪些是重要的核心数据资产,提高在线开发人员的数据风险意识。
可以通过培训的方式,把数据质量管理的诉求,数据质量管理的整个数据加工过程,以及数据产品的应用方式及应用场景告知在线开发人员,使其了解数据的重要性、价值及风险。确保在线开发人员在完成业务目标的同时,也要考虑数据的目标,保持业务端和数据段一致。
2. 离线数据加工校验
从数据输入到输出数据产品应用的大致流程如下图所示:
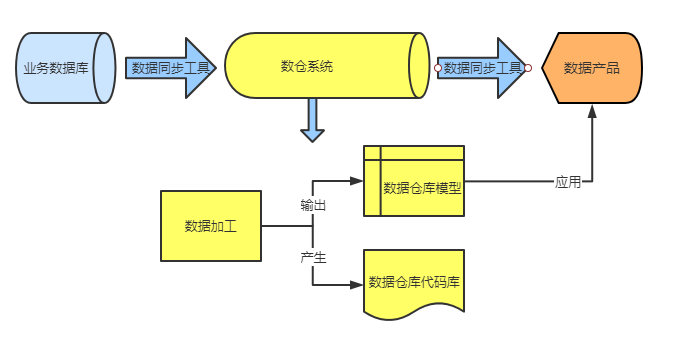
我们可以看到,数据从业务系统上产生,通过数据同步工具进入数仓系统。
数据在数仓系统中进行数据加工处理后输出一系列数据仓库模型,同时也产生了许多数据仓库代码脚本。
最终再通过数据同步工具将加工处理后的数据仓库模型同步到数据产品应用中。
因此,保障数据加工过程中的质量是保障离线数据仓库整体数据质量的重要环节。
数据加工上线流程如下图所示:

在这些环节中,我们可以采用以下方式来保障数据质量:
(1)代码提交核查
开发相关的规则引擎,辅助代码提交校验。规则分类大致为:
- 代码规范类规则:如表命名规范、字段命名规范、生命周期设置、表注释等
- 代码质量类规则:如分母为0提醒、NUll值参与计算提醒等
- 代码性能类规则:如大表提醒、重复计算监测、大小表join操作提醒等
(2)代码发布核查
加强测试环节,测试环境测试后再发布到生成环境,且生成环境测试通过后才算发布成功。
(3)任务变更或重跑数据
在进行数据更新操作前,需要通知下游数据变更原因、变更逻辑、变更时间等信息。下游没有异议后,再按照约定时间执行变更发布操作。
三、数据处理风险监控
1. 在线数据处理风险点监控
为确保在线业务系统的数据质量,对在线业务系统的数据入库进行规则校验。
如,订单记录中,不得出现下单时间大于当天时间或者下单时间小于业务系统上线时间等,若出现异常则报错。
随着业务负责程度的提升,会导致规则繁多、规则配置的运行成本增大,这时可以按照我们之前的数据资产等级有针对性的进行监控。
2. 离线数据处理风险点监控
对于离线数据处理的风险点监控主要是指:对数据调度平台上所有数据处理调度进行监控。
以阿里的DataWorks数据调度产品为例,展开介绍。
(1)数据准确性监控
DataWorks中的DQC通过配置数据质量校验规则,实现离线数据处理中的数据质量监控报警机制。
下图是DQC的工作流程图:
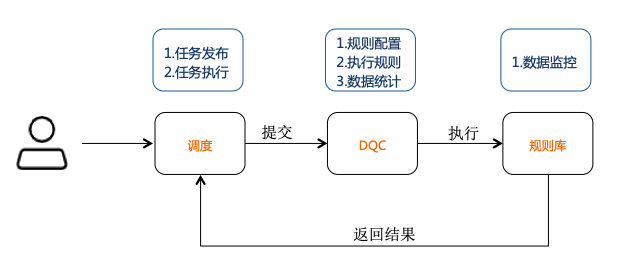
DQC数据监控规则有强规则和弱规则:
- 强规则:一旦触发报警就会阻断任务的执行(将任务置为失败状态,使下游任务不会被触发执行)。
- 弱规则:只报警但不阻断任务的执行。
DQC提供常用的规则模板,包括表行数较N天前波动率、表空间大小较N天前波动率、字段最大/最小/平均值相比N天前波动率、字段空值/唯一个数等。
过多的检查次数必然会导致整体调度任务的执行性能,因此,哪些数据需要配置DQC规则、应该配置什么规则,也需要通过数据资产等级来确定。
(2)数据及时性监控
1)任务优先级
对于DataWorks平台的调度任务,可以通过智能监控工具进行优先级设置。DataWorks的调度是一个树形结构,当配置了叶子节点的优先级,这个优先级会传递到所有的上游节点,而叶子节点通常就是服务业务的消费节点。因此,在优先级的设置上,要先确定业务的资产等级,等级越高的业务对应的消费节点优先级越高,优先调度并占用计算资源,确保高等级业务的准时产出。
总之,就是按照数据资产等级优先执行高等级数据资产的调度任务,优先保障高等级业务的数据需求。
2)任务报警
任务报警和优先级类似,通过DataWorks的智能监控工具进行配置,只需要配置叶子节点即可向上游传递报警配置。任务执行过程中,可能出错或延迟,为了保障最重要数据(即资产等级高的数据)产出,需要立即处理出错并介入处理延迟。
3)DataWorks智能监控
DataWorks进行离线任务调度时,提供智能监控工具,对调度任务进行监控告警。根据监控规则和任务运行情况,智能监控决策是否报警、何时报警、如何报警以及给谁报警。智能监控会自动选择最合理的报警时间、报警方式以及报警对象。
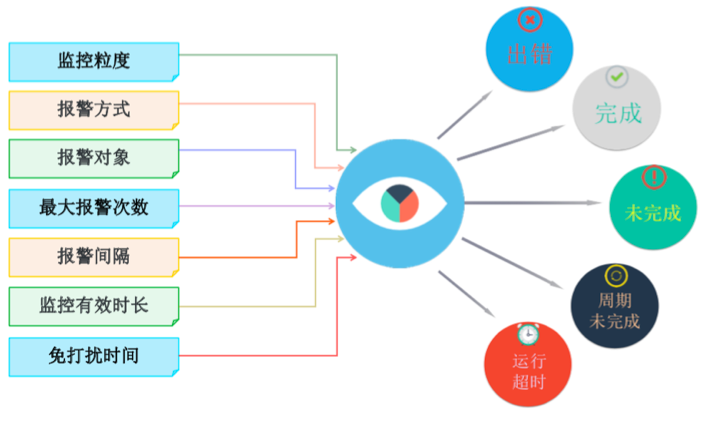
以上内容借助了阿里的DataWorks产品介绍文档,下面说一下自己的理解:
离线数据处理风险监控无外乎就是把离线数据加工过程中所遇到的问题及时反馈预警,然后人工及时进行干预并处理。
对于数据准确性的监控,要看我们规则配置引擎的强大与否,通过数据处理日志中捕捉的出错信息,我们可以不断的完善我们的规则配置引擎,从而不断的提高整个平台的产出数据的准确性。
对于数据及时性的监控,主要是调度资源的合理分配及优化和及时出错报警机制。通过平台资源的优化配置,优先产出高数据资产等级的数据,用于满足业务的数据及时性需求。
四、结语
从数仓数据质量管理的基础流程,到每个治理环节的实施方法论,从宏观上就与大家先分享这么多内容,后续,结合实际工作总数仓数据质量管理所遇到的问题,再和大家做深入的交流与探讨。也欢迎各位小伙伴与我分享自己工作中遇到的问题,共同成长,共同进步。
数据产品路上,与君共勉!
#相关阅读#
本文由 @BennettC 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。








发现有个错别字 😐 😐
😅还是没有看到
“在线业务系统生产的数据”写成了“在线业务系统声场的数据”~
哦哦,惭愧惭愧
老师好,想咨询一下实践中的问题,如果基于字段去界定,实践中,数仓的表太多了,每个表都去标记的话,工作量很大,这块如何去操作呢?
嗯嗯,是的,实际工作当中,不可能做到对每个表都去进行字段级别的规则配置。一是像您说的那样,工作量太大;二是频繁的字段校验会降低调度平台的性能;所以,这就是我们为什么要划分数据资产等级的目的,只对重大数据资产进行较细粒度的规则配置,而对于普通的数据资产进行粗粒度(一般必须保证数据的完整性即可)的规则配置即可。