
 起点课堂会员权益
起点课堂会员权益做AI推荐系统,产品经理要“能文”也要“会武”
编辑导读:文章从AI推荐系统的概况和增长压力下业务对推荐系统产品的渴求出发,介绍了介绍产品经理必懂的推荐系统技术,包含文的技术、武的技术、推荐系统框架、推荐系统大数据和推荐系统算法,其中重点讲解了宽度学习在推荐系统产品中的应用,供大家一同参考和学习。

AI推荐系统,这些年我参加过不少线下推荐系统的会,推荐系统是继数据产品经理,B端产品经理,AI产品经理之后最热门的产品经理岗位。
例如:不同年份参加有关Amazon亚马逊公司GMV有多少来自推荐系统的功劳时,据会上有关PPT显示是一年比一年高,具体如下:
- 2019年PPTAmazon40%收入来自推荐引擎;
- 2017年PPTAmazon35%收入来自推荐引擎;
- 2015年PPTAmazon25%收入来自推荐引擎;
但是做推荐系统需要产品负责人必须懂得两个方面的内容,一个方面是文,一个方面是武。
文一:标签体系
能够梳理自己的手头资料,例如,有什么内容,内容以图文为主还是以长视频和短视频为主。
会对内容进行打标签。例如:我工作过的视频APP结合硬件的公司其标签系统如下:
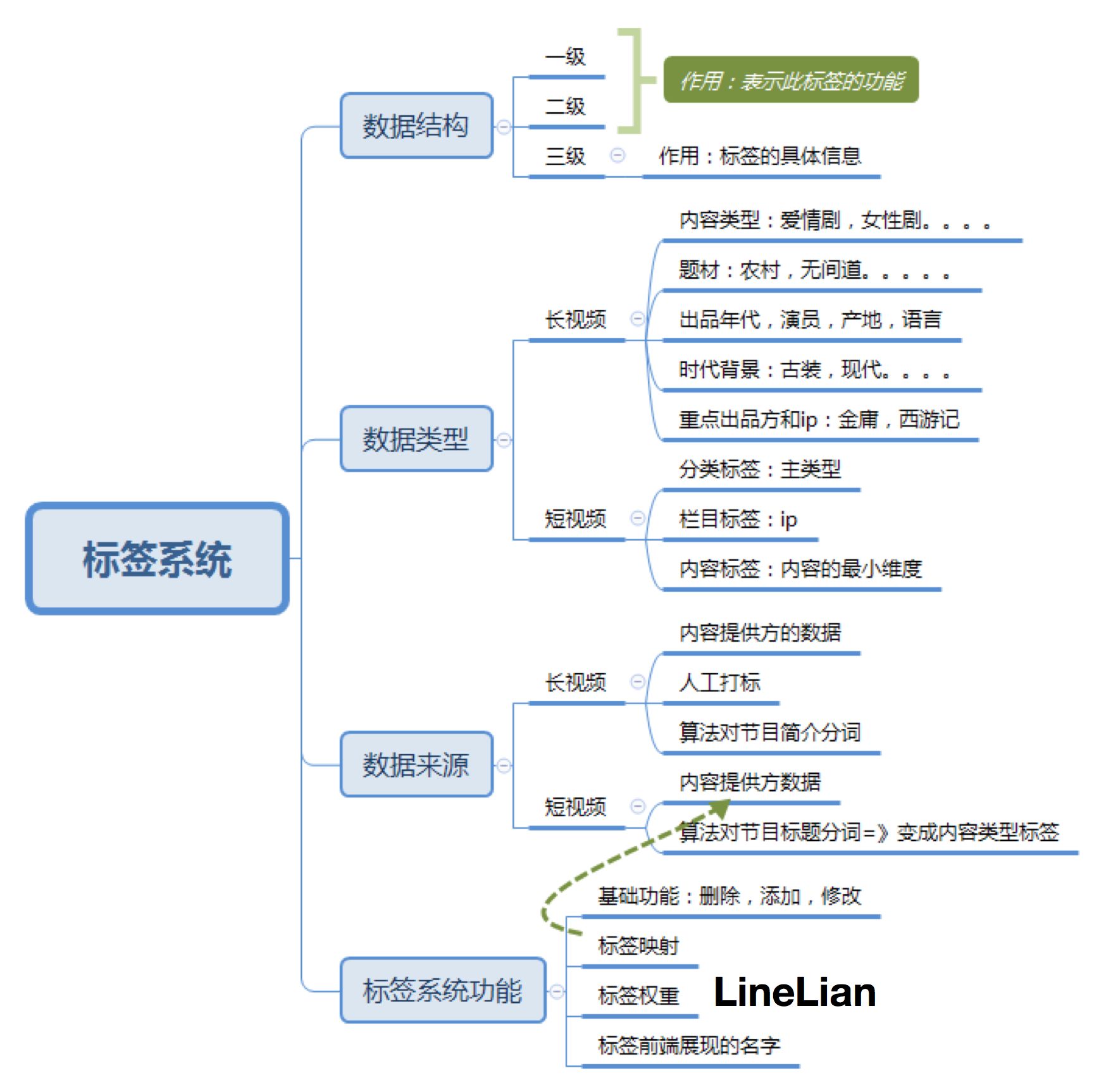
标签系统是推荐系统产品经理的基本功,属于非算法技术的模块,故此算“文”的部分。上图是视频的标签系统的业务架构逻辑。
此标签体系主要是针对视频,其中业务包含长视频和短视频,长视频:基于最细粒度标签向量,人工打权重,用向量相似计算节目相似度;短视频:基于三级标签,利用产品运营策略、规则、算法计算相似度。利用NLP从标题中提取关键词补充三级标签,建立倒查索引表,实时更新相似度。
标签系统主要分,标签的数据结构,标签的数据类型,标签的数据来源,标签的系统功能。
数据结构(英语:data structure)是计算机中存储、组织数据的方式。
标签的数据结构一般分为三级,一级,二级表示标签的功能;三级表示标签的具体信息;这种数据结构来自按业务需求进行的梳理。梳理标签分类时,尽可能按照MECE原则,相互独立,完全穷尽。每一个子集的组合都能覆盖到父集所有数据。标签深度控制在三、四级比较合适,方便管理,到了第四级就是具体的标签实例。
我们的视频标签数据结构是分为三级,例如,人口属性——性别-性别(男)这样的数据结构来梳理的。
数据类型(英语:Data type),又称数据型态、数据型别,是用来约束数据的解释。在编程语言中,常见的数据类型包括原始类型(如:整数、浮点数或字符)、多元组、记录单元、代数数据类型、抽象数据类型、参考类型、类以及函数类型。数据类型描述了数值的表示法、解释和结构,并以算法操作,或是对象在存储器中的存储区,或者其它存储设备。
在我们的标签体系中一般是指产品对应具体的业务内容,视频的产品经理一般会按照长视频,例如:短视频的变迁数据类型会分为,分类标签,栏目标签,内容标签等。分类标签是指短视频的类别,例如属于教育、音乐还是舞蹈等等,栏目标签是指某个短视频栏目,然后是具体的内容。
那么标签的数据来源是怎么来的呢?一方面是手工人工对内容进行梳理,标签化。另外一方面算法对视频标题内容和视频简介进行分词理解。
文二:用户画像
用户画像是由N维度的用户标签生成的,用户画像将推荐系统设计的焦点放在目标用户的动机和行为上,从而避免产品设计人员草率地代表用户。产品设计人员经常不自觉的把自己当作用户代表,根据自己的需求设计产品,导致无法抓住实际用户的需求。往往对产品做了很多功能的升级,用户却觉得体验变差了。
在大数据领域,用户画像的作用远不止于此。用户的行为数据无法直接用于数据分析和模型训练,我们也无法从用户的行为日志中直接获取有用的信息。而将用户的行为数据标签化以后,我们对用户就有了一个直观的认识。
同时计算机也能够理解用户,将用户的行为信息用于个性化推荐、个性化搜索、广告精准投放和智能营销等领域。
为视频做推荐系统,需要了解视频用户的特征,这些特征传统方法可以通过特征工程来做,但是有了AI后,可以用神经网络自动提取特征。如下图:
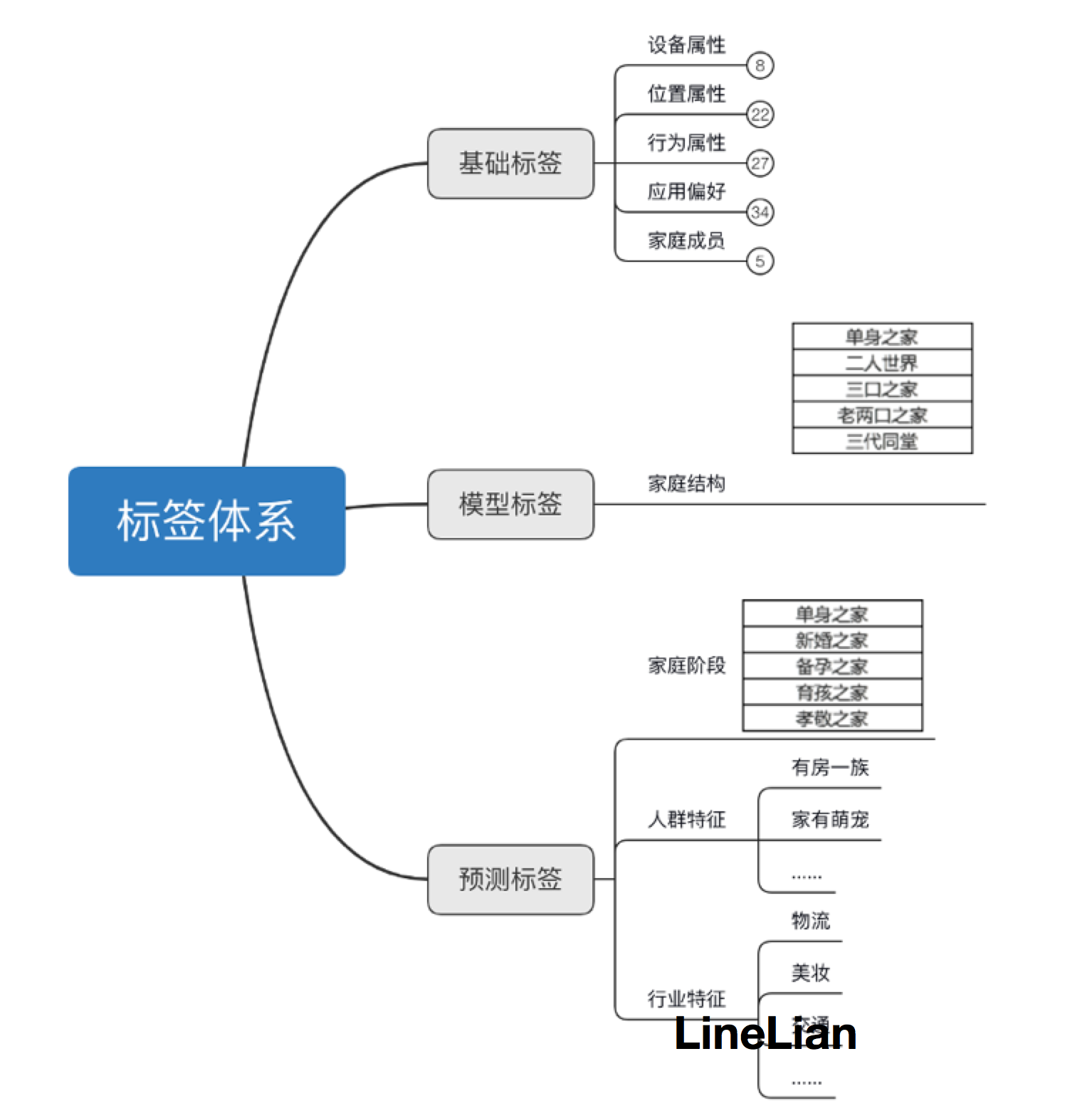
我们已经落地的视频用户的标签体系主要分为基础标签,包含设备的型号和设备的LBS位置等,以及用户的家庭结构还有核心目的预测用户的需求的标签,例如:是否已婚、是否有房、从事的行业等等。
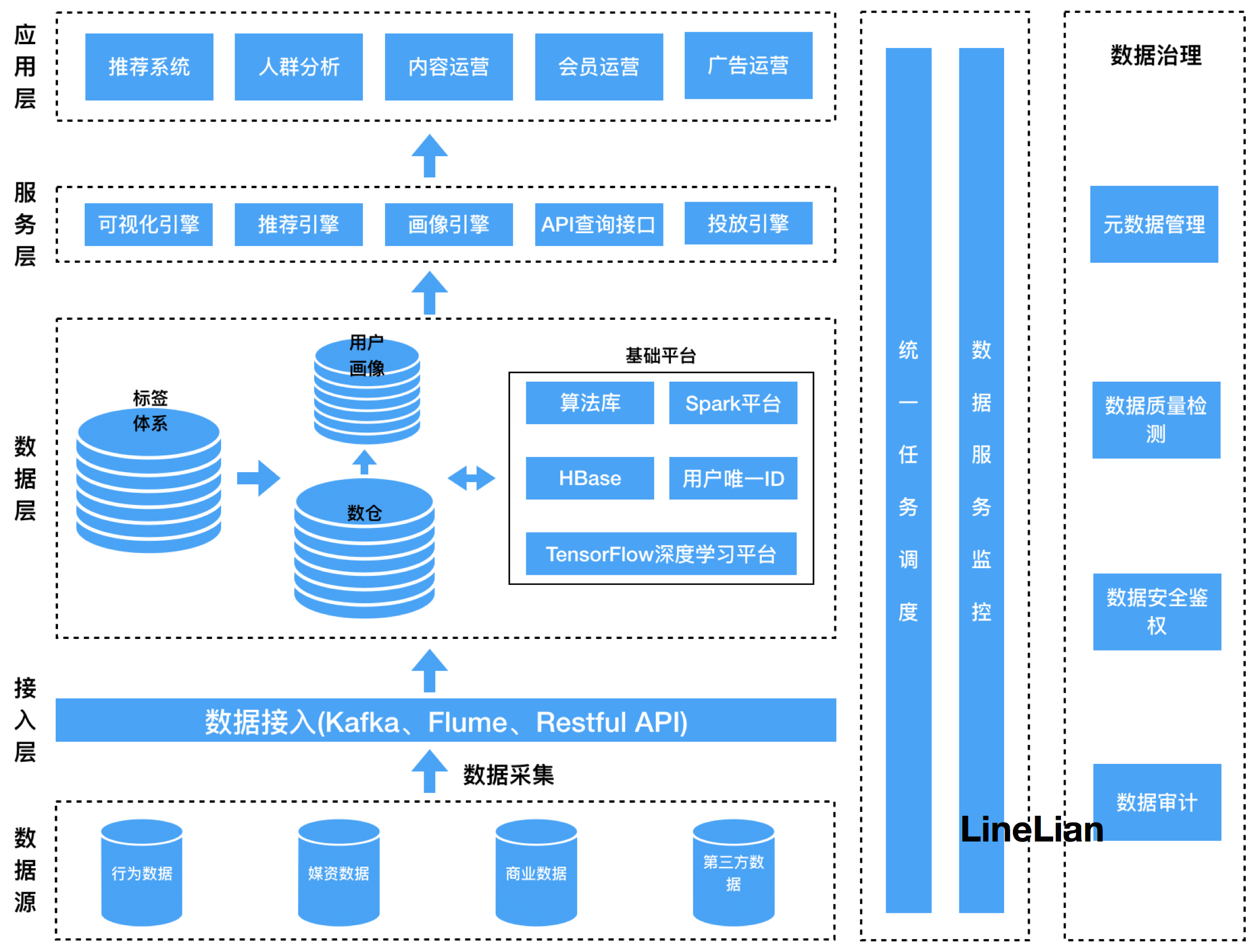
我们视频类产品用户的标签主要来自于业务系统,例如用户用过手机看视频,用户通过电视看视频,用户看广告并点击了某类型的广告,用户在第三方平台的数据等等。
然后我们将用户数据ETL进入数仓,同时也会利用AI的工具例如TensorFlow等生产出新的数据,进而形成用户画像,然后封装好供推荐系统和内容运营人员利用。
武一:懂大数据和推荐系统的关系
推荐系统是帮助人们解决信息获取问题的有效工具,对互联网产品而言用户数和信息总量通常都是巨大的,每天收集到的用户在产品上的交互行为也是海量的,这些大量的数据收集处理就涉及到大数据相关技术,所以推荐系统与大数据有天然的联系,要落地推荐系统往往需要企业具备一套完善的大数据分析平台。
推荐系统与大数据平台的依赖关系如下图。
上图显示,大数据平台包含数据中心和计算中心两大抽象,数据中心为推荐系统提供数据存储,包括训练推荐模型需要的数据,依赖的其他数据,以及推荐结果,而计算中心提供算力支持,支撑数据预处理、模型训练、模型推断 (即基于学习到的模型,为每个用户推荐) 等。
武二:推荐系统架构
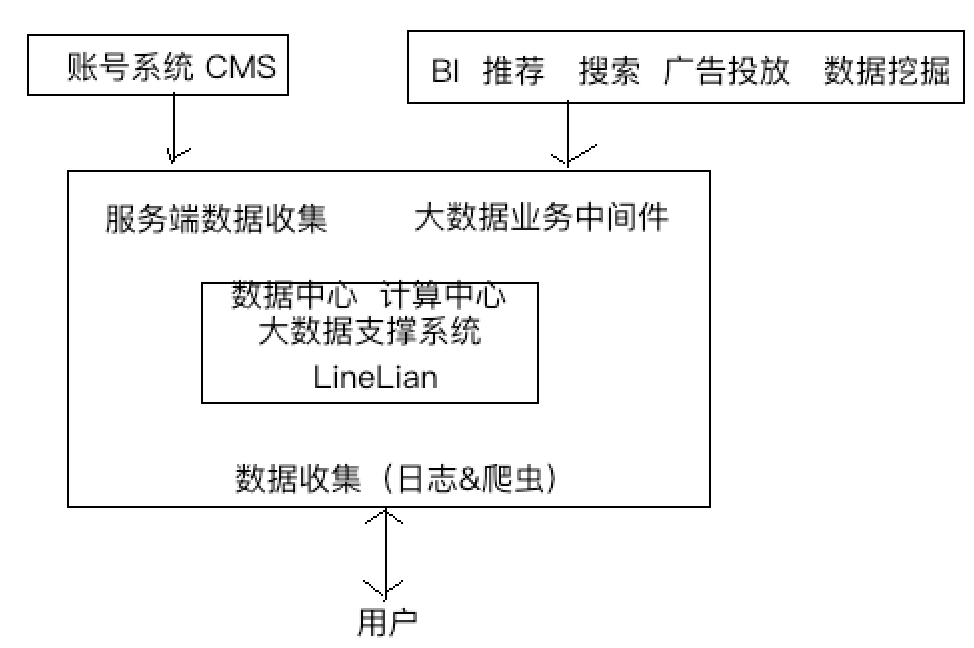
好的技术架构一定来自对业务发展的持续支撑,不仅不耽误业务发展且能够激发业务发展。我们的架构平台不是为了追随热点而是为了持续的激发业务创新,为客户用户提供搞好的有价值的内容。
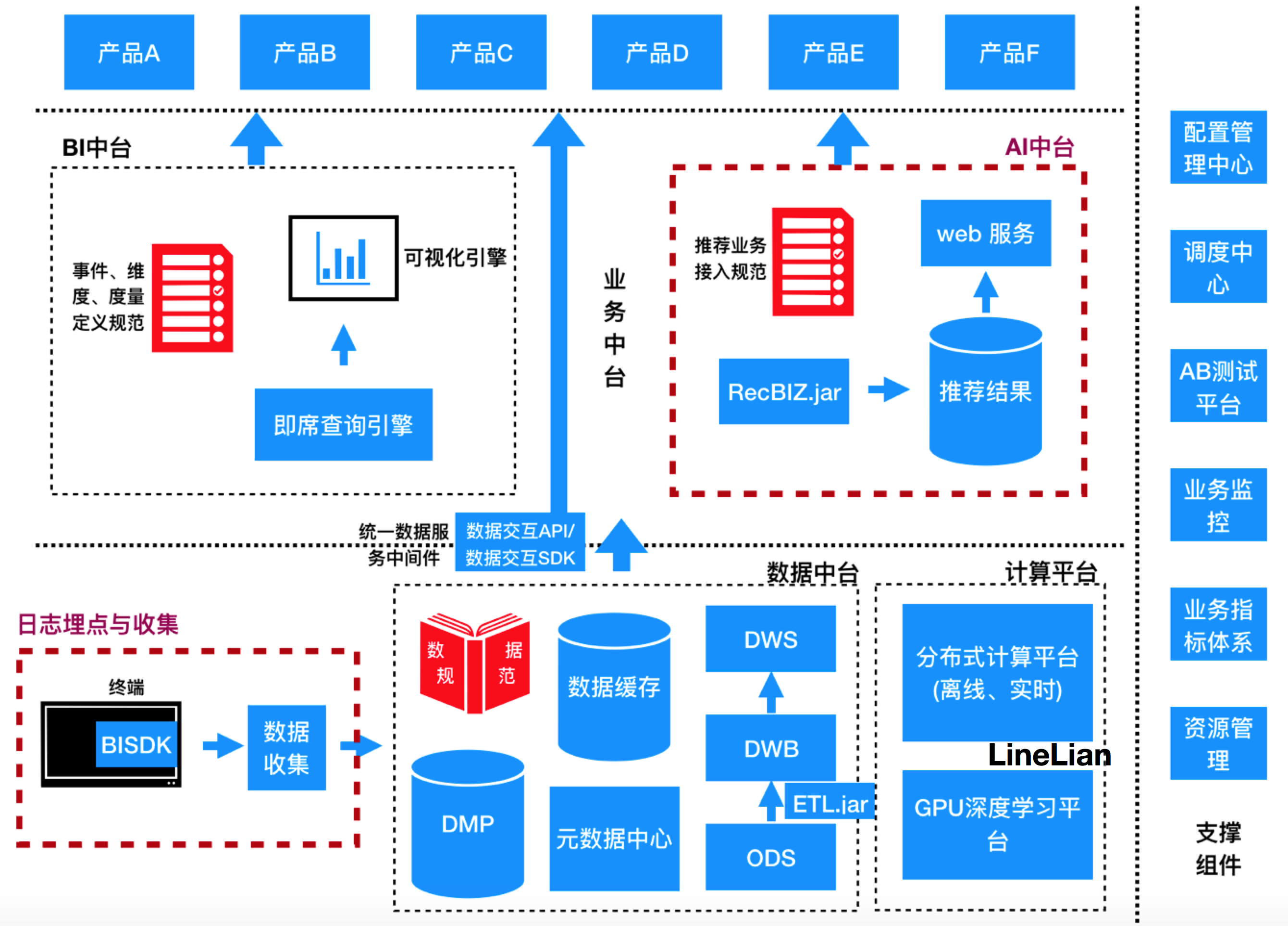
上图为我们产品,我们的产品有很多,例如有手机APP应用,有电视端应用,有爱奇艺,也有奇秀,还有奇巴布等等产品,中间左侧我们有BI中台,中间右侧我们有AI中台,包含做好的推荐结果,推荐文档等等,下面是大数据处理架构,将数据源数据进行数据清洗,然后输入到数据中台,数据中台包含数仓,下面右侧是计算平台,包含实时(流式计算)计算引擎和离线计算以及联合GPU拓展做的机器学习平台。最右侧是一些常规的例如:AB测试、业务监控、业务指标体系等等功能模块。
好的推荐系统不是计算平台里有多少前沿的未经融合的算法,也不是AI中台里面封装了多少算法模型,而是能够给用户带来喜悦感和价值,同时为公司来带业务的持续增长,否则推荐系统就仅仅放在实验室里的摆设。
武三:宽度学习
一个好的推荐系统目标是清晰的,但是在实现用户惊喜和公司业务的持续增长上完全靠机器学习有时候是不能给用户带来人性的温暖的。所以笔者提出用宽度学习来做推荐系统的想法。(当然Wide本身的灵感来自2015年谷歌的论文,只是笔者用于实践并落地了)。
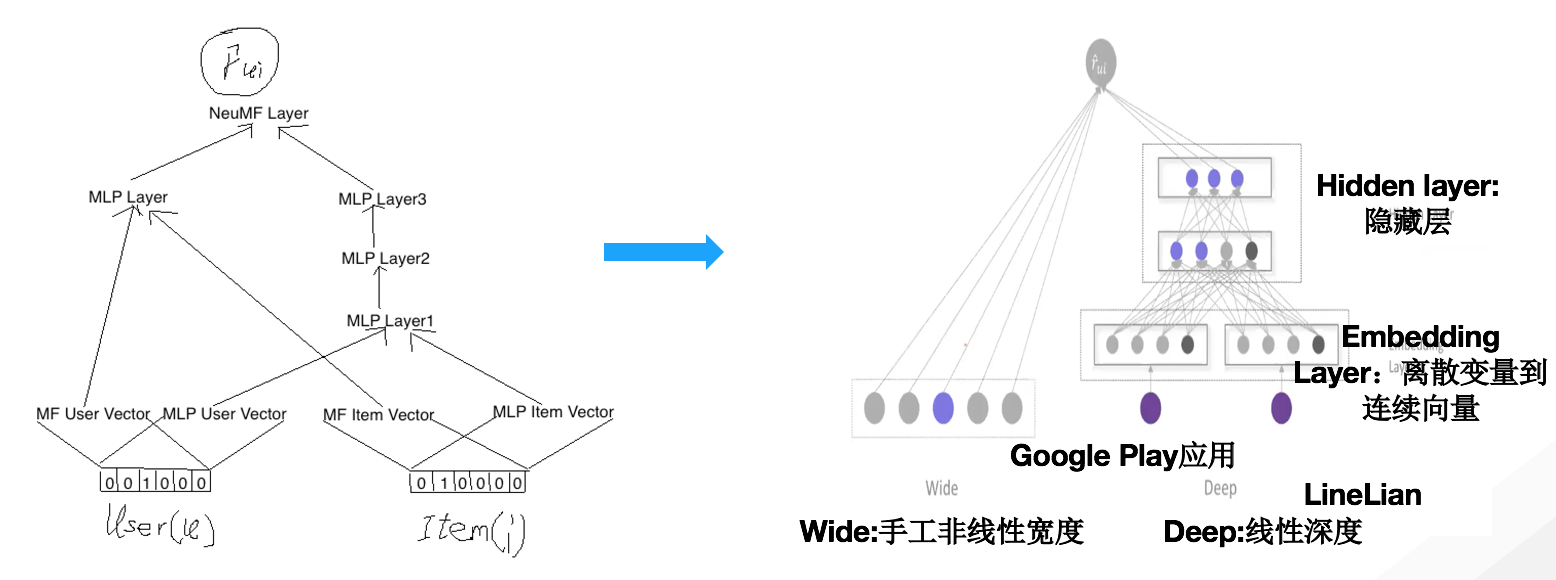
上图是笔者绘制的将宽度学习应用于推荐系统的抽象图。我们知道一般推荐系统要么基于用户进行推荐,用类似用户的相似偏好进行推荐,要么是基于物品(我们是视频)的相似度进行推荐,但是这种方式放入机器学习会有两个方面的问题:
一个是数据稀疏,例如用户没有对某物品购买够,收藏过,观看过,点赞过那么构成的用户行为数据矩阵或者物品数据矩阵里面会有很多空白。另外一个问题是总有一些维度数据缺失,目前据笔者所知淘宝可以为用户标签打到几百万维度,但是依然存在不懂用户的角度,所以这个时候就需要员工从人性的角度为推荐引擎进行协同。
所以,宽度学习应用于推荐系统是指在机器学习深度学习所搭建的推荐引擎之外搭建人工推荐引擎一融合更好的为用户带来推荐的惊喜和满意。
宽度学习宽的部分主要是指,用户年龄、用户的设备型号、用户的社会参与状况及人文背景。这样就拓展了人物在机器学习不到或者难以机器学习的地方的信息量和作为人类的心理感受参数。
最后
做出优秀的推荐系统需要克服的问题有:
- 多端设备相同用户或单端设备不同用户;
- 用户非登录;
- 新用户;
- 用户对隐私的关注;
- 算法配合UI和内容运营在边缘端呈现给用户的结果;
- 数据源的拓展;
- 另选与行业竞对的内容或者体验。
能做到以上七点的推荐系统时下应该能够获得用户的惊喜。
我有时候喜欢做工程师,喜欢这种静下来做出东西来的小成就感,我有时候喜欢市场运营喜欢那种对用户运营的套路慢慢,不论是哪种最后我们都要给客户持续带来新产品新服务和新体验。
#专栏作家#
连诗路,公众号:LineLian。人人都是产品经理专栏作家,《产品进化论:AI+时代产品经理的思维方法》一书作者,前阿里产品专家,希望与创业者多多交流。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash, 基于CC0协议









算法配合UI和内容运营在边缘端呈现给用户的结果
老师您好,这个在“边缘”端,是什么意思啊?