
 起点课堂会员权益
起点课堂会员权益产品经理视角下的自然语言处理
编辑导语:自然语言理解俗称“人机对话”,AI领域分支科学,以语言学为基础,涉及心理学、逻辑学、声学、数学和计算机科学。其算法和逻辑的设计和实现自然十分复杂和困难,作为智能语音系统的产品,本文作者今天从产品的视角和大家简单的聊一聊“自然语言理解”及其周边知识。

一、名词解释
1. 语音交互“三驾马车”
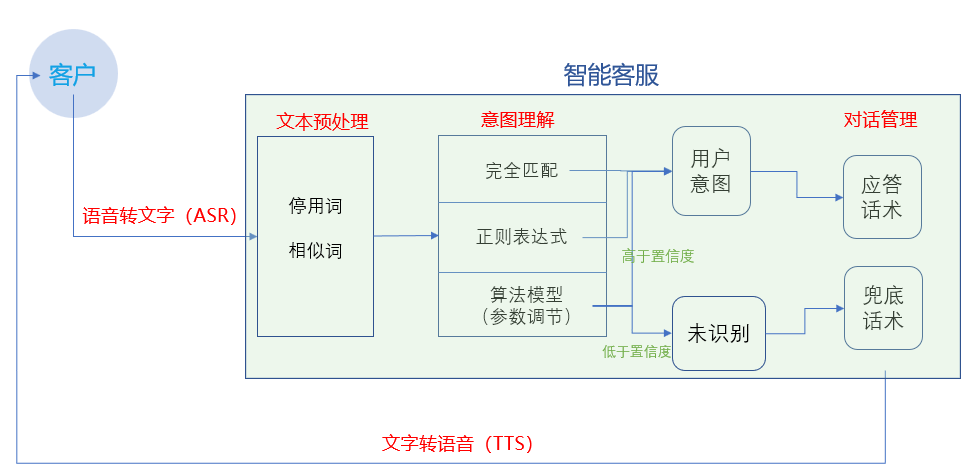
1)ASR
语音自动识别,把外界的声音转写成文字,相当于人类的耳朵。
2)NLP
分为NLU和NLG两部分, NLU负责理解内容,NLG负责生成内容。
前者是对外界输入的理解,后者是根据理解的内容生成对应的输出,相当于人类的大脑。
3)TTS
语音合成,NLG生成的文字由TTS由不同音色播报出来,相当于人类的嘴巴。
2. 自然语言理解
1)语料
语料是构成训练集和测试集的基本单位,可以是句子、短语,通过对大量语料学习帮助模型识别用户的意图。
2)训练集和测试集
顾名思义前者是用来训练模型进行意图识别的,而后者是用来测试模型学习效果如何的,二者都是由语料构成。
3)置信度
人为设定,超过了模型的置信度表示模型就会去理解(结果可能会理解错或理解对),小于置信度,强制模型不去理解。
3. 模型及算法
1)机器学习模型
通过算法使得机器能从大量历史数据中学习规律,从而对新的样本做出智能识别或对未来做出预测,相当于培养模型“举一反三”的能力。
2)神经网络模型
通过大量的简单计算单元构成的非线性系统,在一定程度上模仿了人脑神经系统的信息处理、存储和检索功能,是对人脑神经网络的某种简化、抽象和模拟,相当于“由浅入深”的学习过程。
二、语音交互的应用场景
从目前商业市场划分来看,语音交互主要应用场景及细分赛道众多:智能家居、车载场景、医疗场景、教育场景和客服场景等。
从有无硬件载体上可简单粗暴的分为两大类:
1. 聊天机器人
产品定位于日常的“人机闲聊”。
可掌控简单或复杂场景人机交互,依赖于ASR、NLP和TTS,通常使用嵌入式系统与硬件完成对接,如常见的天猫精灵、Siri和车载机器人等,主要应用在智能机器人领域。
2. 语音外呼
产品定位于“完成任务”,业务属性更强。
上游通过呼叫中心(FS)、电信运营商拿到路线和号码资源,下游触达用户完成活动营销、欠款通知和生活服务,主要应用于智能语音外呼和呼入,通常会有固定的“业务流程“作为客户引导手段。
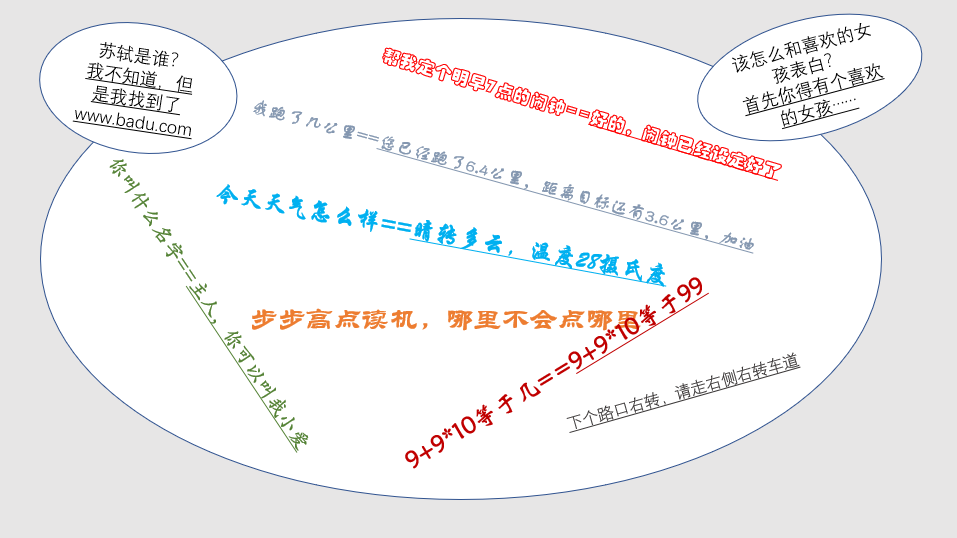
目前智能语音行业由于应用场景、业务要求、客户体验或监管要求等原因都会使用封闭问答集来约定与客户交互的边界。
如在保险营销的业务中,客户若是询问了和业务不相关的内容(今天气温是多少度?晚餐有什么推荐的吗?)机器会使用提前设定好的固定的“兜底”话术来应答(你说啥,我不懂,请回答业务相关的内容)将用户重新拉回业务流程中,而不会与客户进行“不相关领域”的闲聊。
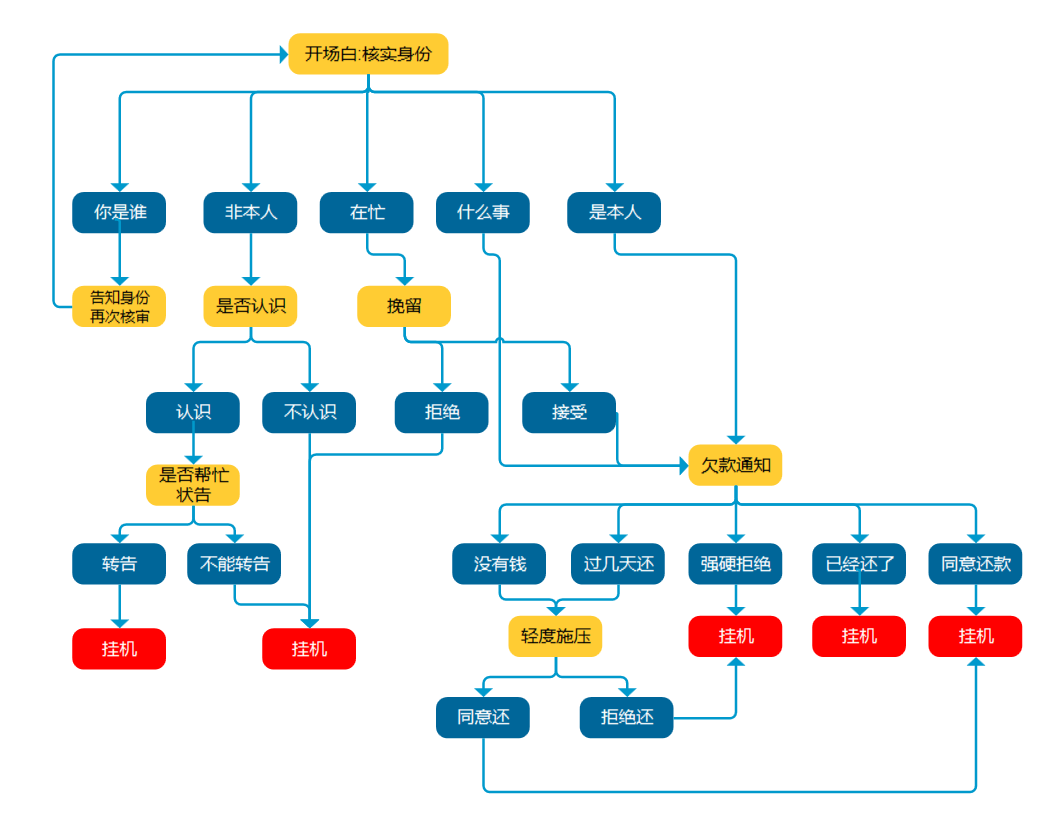
由于业务属性的特殊性,客服性质的外呼业务对监管和用户投诉格外关注,B端客户对应答话术的要求及意图识别的准确率要求较高。
所以除了使用语料来训练模型,基本上还会使用正则表达式和关键字的策略进行意图匹配的辅助。
三、自然语言理解
NLP(自然语言处理)被誉为人工智能的掌上明珠,究其原因“交流”在人类社会演进中起到了最重要的作用。
作为“交流”最重要的途径和方式之一,语言伴随着人类社会的发展,历久弥新,形成了博大精深、非常复杂的体系。
不同的职业领域、不同的历史时期、也就是我们常说的“自然语言”,就像平常妈妈和你说话一样,不需要完整的语法、不需要主谓宾定状补的限定,拟人比喻倒装夸张对偶各种修辞一起来。
让孔子来理解我们今天的“语言”他其实也不知道我们在表达什么意思,更何况是机器人呢。
和妈妈交互的场景,在机器人眼里以下对话可能是这个样子的:
- 妈:“把你那猪窝收拾收拾,和你爹一个熊样”!
- 机器人的理解:你和你爸都是熊,你俩长得很像。你养了一只猪,猪窝太乱你需要整理下。
如果没有具体的对话场景,而且对于一个没有感情的机器,很难让他理解我们人类日常生活中的语言。
但是,我们可以教他,就像儿童成长过程一样:你妈第一次骂你“和你爹一个熊样”你也不知道是什么意思,但是骂的多了加上她骂人时的表情、语气、情绪等你就知道了“和你爹一个熊样”实际上是在骂你。
四、理解和优化过程

1. 训练模型
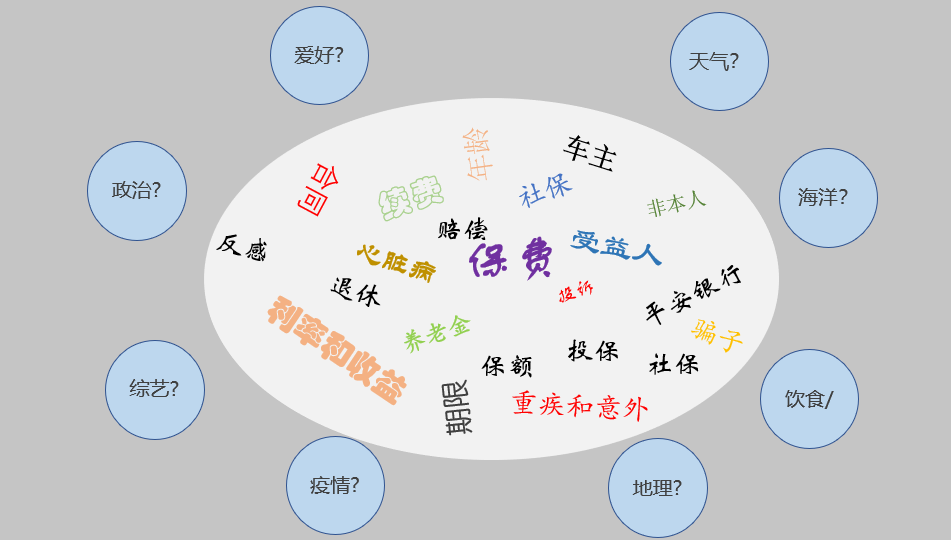
如上图“不想上班“标签的训练集的语料内容,都是表明作者不想上班的意思,并把其中的80%语料作为训练集扔给模型,让其去学习(可以抽象成将复杂的非向量化的文本内容归一化为可以计算的数学模型,之后再转换为机器可以理解的0和1,具体的实现过程作者也了解过,其中涉及到很多的数学内容,较为复杂感兴趣的同学可自行学习)。
最终,机器可以明白了其中的大部分意思。
2. 测试模型
不能机器说学会了,我们就认为它学会了,还要使用测试集对它进行“考试”,使用上述语料中剩余的20%作为测试集进行测试,得到模型的“识别率”。
识别率和“训练集”和“测试集”中的语料内容很大的关系,需要合理的进行分配。
否则结果会出现“过拟合”(考的恰好都是我会的,不会的都没考,成绩很高)和“欠拟合”(考的都不会,成绩很低)的现象。
最终考试成绩好,皆大欢喜;考试成绩不好,回家优化。
3. 模型结果优化
1)停用词
“停用词”指在一句话中没有实际意义,即使去掉对句子的整体理解(句式除外)也不会造成影响的词。
如啊、哦、吧这种语气词或是出于具体的业务考量可以忽略的词语,在语料预处理阶段会将这些词语忽略掉以增加语料的“纯粹性”。
2)添加语料
模型识别的基础是语料,尽可能多的添加优质的语料,保证模型在更好的“教育环境“下学习,通常在业务前期的语料积累阶段,添加语料是提高准确率最直接的方法。
理想的场景是在模型训练之前将完整的语料库准备好,以供第一次就可以训练好,但是语料的收集和整理也是耗时耗力且枯燥的工作,需要大量人工的投入。
3)模型参数调节
参数(超参数)不仅仅包括一些数字的调整,也包括了相关的网络结构的调整和一些函数的调整(前面的停用词也可以理解为预处理阶段的一种参数),如对学习率、正则化方法、初始化权值的调整。
不同的模型类型,可调节的参数不同,需要算法工程师给出具体的优化意见。
4. 其他手段
在对模型的优化达到瓶颈之后,若是还不能达到理想的正确率,可以从其他方面想办法和提高,如增加“完全匹配”、“正则表达式”等其他手段。
1)模型识别的问题
与语料相同的用户回答可能也不能正确识别出意图。
如:语料中有”周六怎么还要加班呢“,客户也回答”周六怎么还要加班呢“,有时并不一定会识别出“不想上班”的意思。
作者刚开始并不理解为什么会这样?
这是因为模型将所有语料都进行了向量化,所以对模型来说是不存在”相同文字“的概念。
我们可以这样想,模型对语料的训练集内容拟合为一条曲线,离曲线近的内容可以识别出来,离曲线远的内容识别不出来,完全相同的语料恰巧很远。
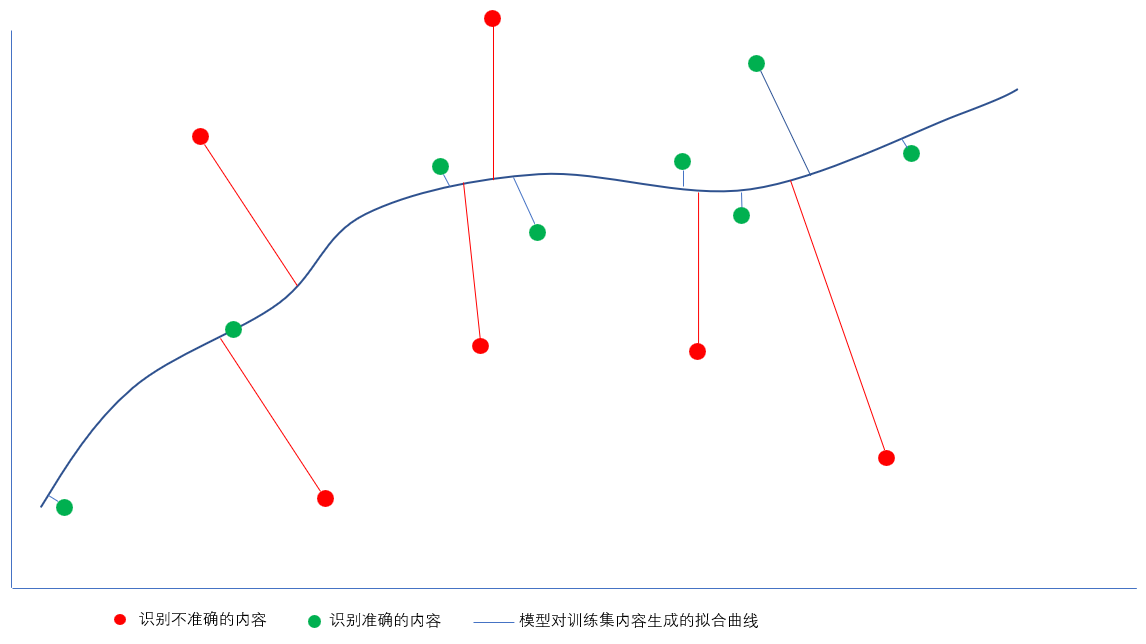
2)完全匹配
为了规避这种场景的出现,增加完全匹配,只要和语料完全相同的内容在模型之前会进行一轮意图识别。
3)正则表达式
与完全匹配类似,使用正则来表达复杂但是具有统一格式规范的句子,如<.*不想上班.*>,可匹配“我今天不想上班了”、“他们是一群不想上班的产品经理”等,可以理解为完全匹配的一种特殊形式。
正则的使用通常可以大大的简化对封闭性问题的语料编辑,节约工作量,适用于封闭性问题且需要使用着对正则有一定的书写和理解基础,不适用大规模的使用。
4.5 未识别的处理
前面所说的方案都是为了提高意图理解的准确性,即使加上了完全匹配和正则的情况下,目前不存在实际场景下100%识别准确率的模型,部分内容还是会给出错误的判断。
但是在交互过程,尤其是在真实业务场景(催收、营销、续保、欠费通知、物业报修,餐饮订座)中触达用户中“不懂装懂”可不是一个很好的现象。
- Question:“你吃饭了吗?”
- Answer:”不想上班就没人给你发工资“
这样的体验肯定是不行的,不会的问题就说不会,所以我们会设置模型的“置信度”。
模型分值高于置信度(参数的一种),我们相信模型识别对,低于置信度的我们会设定“兜底”的话术来进行应答,如“主人,我不懂你的意思唉”、“可能是信号不好,我没听清楚”,既灵活的敷衍了自己不明白的尴尬局面,又表达了你说的太难了我不懂的意思。
最后,不论是主动学习还是被动接受,语音交互已经深入到我们生活的各个角落,虽然目前语音交互过程通常会有“所闻非所答”、“这个机器人真笨”的感觉,发展过程中出现的坑,总会前赴后继的被填平并驻成山峰。
希望文章会各位在对自然语言理解的过程中有一定的帮助。
本文由 @Jira狂想曲 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Pexels,基于 CC0 协议









看完就想起了自己上学的时候做文本挖掘的亚子😂
💪💪
作者前半部分讲的自然语言处理的一些知识,通过形象的比如,简单易懂,很适合想要初步了解这块知识的人,后面关于模型优化那块感觉还可以出个后续。“离曲线近的内容可以识别出来,离曲线远的内容识别不出来,完全相同的语料恰巧很远。”——这里的“完全相同的语料恰巧很远”不是很明白
谢谢关注,在工作中我也会再深入了解算法和其中的应用的,争取后面出个后续
产品在其中主要承担哪些工作呢?需要理解机器学习的算法吗?
AI产品经理是要深入懂得算法的,我只了解NLP的浅层的问题,毕竟有时候要和开发去讨论如何进行优化。
产品在其中的工作有2方面:
1、熟悉业务:意图和功能都是为业务服务的,每个业务上算法模型大同小异的,但是业务层面有很大的差别,首先要将业务了解清楚,为之后的流程设计做好铺垫;(40%)
2、协调资源:各个阶段下的协调资源,包括前期的收集整理语料,中期的模型训练和测试,后期的持续优化运营等(60%)