
 起点课堂会员权益
起点课堂会员权益AIPM要知道的NLP知识(1):词的表达
编辑导语:NLP为Neuro-Linguistic Programming的缩写,是研究思维、语言和行为中的规律;这是一种对优秀(excellence)进行编码和复制的方式,它能使你不断达到你和你的公司想要的结果;本文是作者关于NLP知识中词的表达的分享,我们一起来看一下。

个人认为pm懂一点技术好处是大大的有。
总结这个系列,把NLP相关的常见模型进行了梳理,分为词的表达、RNN、seq2seq、transformer和bert五个部分。
基本的想法是重点理解模型是什么(what)、为什么要用这种模型(why)以及哪些场景中可以用这种模型(where),至于如何实现模型(how)可以留给RD小哥哥们。
一、词的表达
要知道计算机是看不懂人类语言的,要想让机器理解语言、实现自然语言处理,第一步就是把自然语言转化成计算机语言——数字。
由于词是人类语言表达时的一种基本单位(当然更细的单位是字或者字母),NLP处理的时候很自然的想要用一组特定的数字代表一个特定的词,这就是词的表达,把这些表示词的数字连起来就可以表达一句话、一篇文章了。
这一part里有很多常见的名词,distributed representation、word embedding、word2vec等等,它们的关系大概是这样的:

1. one-hot representation v.s. distributed representation
表达方式,我觉得就是自然语言到机器语言怎么转化的一套规则;比如“我”这个词转化到机器语言应该用“1”还是“100”表示呢?而且机器语言中代表“我”的这个数还不能和代表其他词的数重复吧,必须是一个唯一的id。
顺着id这个思路,假设我们的词典收录了10个词,那么我们就给词典里的每一个词分配一个唯一的id;词表示的时候用一个和字典一样长的向量表示,这个向量里只有id这一位为1,其他位都为0;比如说abandon这个词的id是1,那么就表示成abandon=[1 0 0 0 0 0 0 0 0 0],这就是one-hot representation。
这种表示好理解,但是也有问题:
问题一:向量会随着字典变大而变大。
很明显如果我的词典有100000个词的话,每一个词都要用长度100000的向量表示;如果一句话有20个词,那么就是一个100000*20的矩阵了,按这种操作基本就走远了。
另外一个问题是这种表示不能体现语义的相关性。
比如香蕉和苹果在人看来是非常类似的,但是用one-hot表示香蕉可能是[1,0,0,0,0],苹果可能是[0,0,1,0,0],之间没有任何相关性;这样的话如果我们用“我吃了香蕉”训练模型,结果模型可能并不能理解“我吃了苹果”,泛化能力就很差。
于是机智的大佬们提出了一个假说,就是distributed hypothesis:词的语义由其上下文决定。
基于这种假说生成的表示就叫做distributed representation,用在词表示时也就是word embedding,中文名有词向量、词嵌入;所以distributed representation≈word embedding,因为现阶段主流的nlp处理大都是基于词的,当然也有对字、句子、甚至文章进行embedding的,所以不能说完全完全相等。
至于具体如何基于这种假说实现词表示,根据模型不同可以分成基于矩阵(GloVe)、基于聚类、基于神经网络(NNLM、Word2Vec等)的方法。
2. word embedding
个人理解,从字面意思上看word embedding就是把一个one-hot这样的稀疏矩阵映射成一个更稠密的矩阵;比如上边栗子中abandon用one-hot(词典大小为10)表示为[1 0 0 0 0 0 0 0 0 0];但word embedding可能用维度为2的向量[0.4 0.5]就可以表示;解决了前边说的one-hot的维度过大问题,还增大了信息熵,所以word embedding表示信息的效率要高于one-hot。
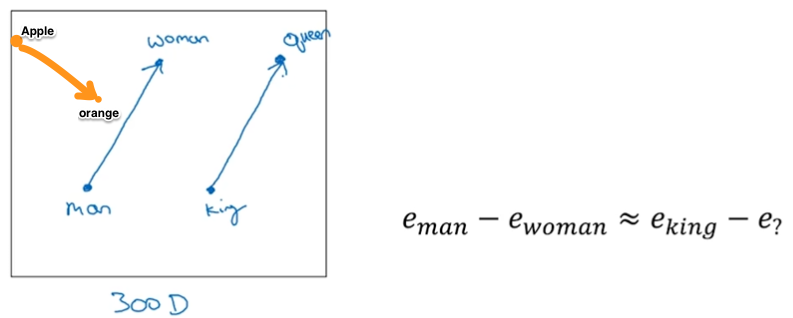
但词向量这个名字没有体现出它表示语义的本质,所以第一次看到很容易会不知所云;为了说明word embedding可以体现语义,这时候就可以搬出著名的queen、king、woman、man的栗子了。
(图来自Andrew Ng deeplearning.ai)
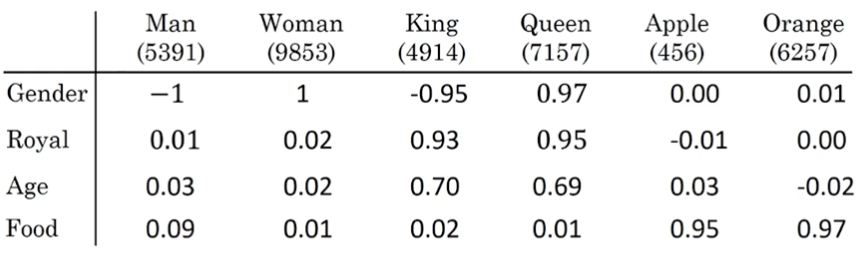
上图是通过训练得出的词向量,man=[-1 0.01 0.03 0.09],woman=[1 0.02 0.02 0.01],king=[-0.95 0.93 0.70 0.02],queen=[0.97 0.95 0.69 0.01]。
矩阵相减man-woman=[-2 -0.01 0.01 0.08],king-queen=[-1.92 -0.02 0.01 0.01],两个差值非常相近,或者说两个向量的夹角很小,可以理解为man和woman之间的关系与king和queen之间非常相近;而apple-orange=[-0.01 -0.01 0.05 -0.02]就和man-woman、king-queen相差很大。
很有意思的是最初word embedding其实是为了训练NNLM(Neural Network Language Model)得到的副产品。
训练语言模型会得到一个lookup table,这个lookup table有点像地下工作者用的密码本;通过这个密码本可以将one-hot向量转换成更低维度的word embedding向量,可见词向量实现的关键就是得到密码本lookup table。
后来更高效的得到word embedding的模型之一就是word2Vec,word2Vec又有两种模型,分别是CBOW和skip-gram;两者都可以得到lookup table,具体模型和实现不在这里展开。
word embedding可以作为判断语义相似度的一种手段,但更多的是作为其他nlp任务的第一步。
实际中如果不是特殊领域(军事、法律等)的词典,word embedding可以用别人训练好的,提高效率;所以word embedding也可以看做神经网络预处理的一种。
另外说一下,word embedding有个最大的问题是不能处理多义词。
举个栗子“苹果员工爱吃苹果”,第一个苹果是指苹果公司,第二个是指水果;但对于word embedding来说二者只能对应一个向量(比如[0.1 -0.3]),在处理后续任务时只要是苹果就对应成[0.1 -0.3],所以通过词向量并不能区分出苹果的不同词义。
总结一下,词的表达我觉得要知道:
- 为什么需要词表达。
- 几个常见名词(one-hot representation、distributed representation、word embedding、word2Vec)之间的关系。
- word embedding比one-hot强在哪里。
- word embedding有什么缺点。
本文由 @LCC 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。









特地注册账号来好评!这个解释对入门来说太友好了,顺便问下有什么入门书籍可以推荐的吗
感谢~可以看看吴恩达的在线课程讲RNN那一节
多话不说,感谢~~
技术的活pm干的那么起劲干嘛
那个。。。NLP=natural language processing。。。