
 起点课堂会员权益
起点课堂会员权益推荐算法入门:避开公式,产品经理了解这些就够了
编辑导语:推荐算法,其实早在1992年就提出来了,但是火起来却是最近这些年的事情,因为互联网的爆发,有了更大的数据量可以供我们使用,推荐算法才有了很大的用武之地。对产品经理来说,了解推荐算法也是其工作内容之一,那么应该从哪里入门呢?本文作者为我们进行了分析总结。

8月28日,商务部发布了一则公告《中国禁止出口限制出口技术目录》,第 45 条这次调整的内容,增加了多项目前最热门的技术,其中就提到了:个性化推送服务。
众所周知,这次调整是有意针对Tik Tok的出售风波,昆士兰科技大学 ( Queensland University of Technology ) 研究 Tik Tok 的研究员 Bondy Valdovinos Kaye 说:” 我个人认为,如果没有推荐算法,Tik Tok 就不会是 Tik Tok”。
从一定程度上可以说明,正是推荐算法成就了字节跳动的今天,作为当今内容型产品的“标配”,不管是业务需要还是拓宽视野,了解业界常用的推荐算法及其应用总是很有必要的。

一、协同过滤推荐算法
协同过滤推荐算法(Collaborative Filtering recommendation)是目前最流行的推荐算法。
其算法原理通俗来说就是利用那些兴趣相同的用户群体,来为目标用户推荐其感兴趣的信息,而协同过滤算法又大致可以分为基于用户(User-based)和基于物品(Item-based)两种协同过滤。
1. 基于用户的协同过滤算法(User-based):
如果说某些用户群体对某类物品的评分是相似的,那么我们可以认为这些用户属于相似用户,基于用户的协同过滤推荐算法便是通过找到与目标用户相似的其他用户,然后通过其他相似用户对某类物品的评分来预测目标用户对该物品的评分,并以此为依据进行推荐。
如果用户A喜欢项目A和项目C,用户C同样喜欢项目A与项目C,那么用户A与用户C可以被判定为相似用户,根据用户C喜欢项目D这一情况,可以推断出用户A喜欢项目D的概率较大,因此可以将项目D推荐给用户A。
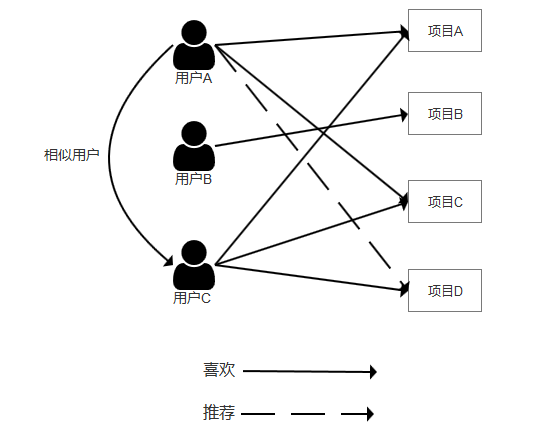
基于用户的推荐算法需要计算用户间的相似度矩阵,所以当用户数量变化很大的时候,每次都要重新计算,比较耗时,可拓展性较差。
2. 基于物品的协同过滤算法(Item-based):
很多电商网站中的商品相对于用户数量来说,变化是相对稳定的,所以物品的相似矩阵相比用户的相似矩阵来说要稳定很多。
基于物品的协同过滤算法思想就是根据所有用户的历史偏好来计算推荐物品之间的相似性,然后把与用户喜欢的物品相似的其他物品推荐给用户。
如果项目A与项目C同时被多个用户(用户A与用户C)喜欢,那么可以认为项目A与项目C是相似项目,便可以把它推荐给同样喜欢项目A的用户D。
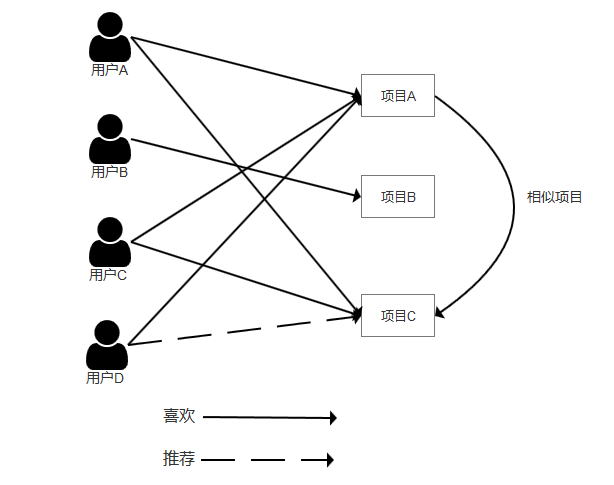
协同过滤类推荐算法特点:
- 不需要对推荐内容本身做太多了解便可以完成推荐工作;
- 能够挖掘用户的潜在兴趣;
- 需要依赖大量用户对项目的评分矩阵,存在新用户与新物品的冷启动问题。
二、基于内容的推荐算法
基于内容的推荐系统最早来自于对协同过滤算法的改进,协同过滤算法只考虑到了用户对于物品的打分,而没有考虑物品本身所具备的多种属性特征,比如该物品是一篇文章,那么它的属性特征就有作者、标题、类别等。
而基于内容的推荐则是利用这些特征来进行推荐,该推荐方法会提取物品中的内容特征,然后与用户的兴趣标签进行匹配,匹配度高的推荐物品就可以推荐给相应用户:文本A的特征词为教育、大学;文本C的特征词为教育、高校。
那么可以认为文本A与文本C为相似文本,用户A阅读了文本A以后便可认为其对教育类的文章感兴趣,从而将文本C推荐给用户A。
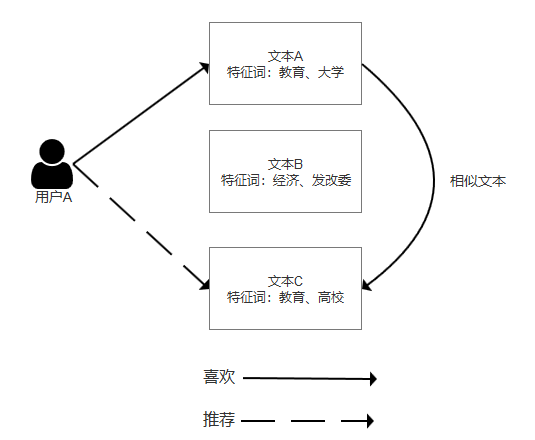
基于内容类推荐算法特点:
- 用户之间保持独立性,推荐结果与他人的行为无关;
- 新项目可以立即得到推荐,新的项目加入到系统中时,只要拥有标签,便可以和用户的兴趣模型进行匹配完成推荐;
- 新用户冷启动问题,由于新的用户没有历史行为记录,会存在冷启动问题,这也是为什么很多产品第一次登陆时都会让用户选择自己感兴趣的内容分类,就是为了快速对用户建立兴趣标签。
三、推荐算法如何被应用?
目前的主流推荐算法,大多可以归类为以上的两种策略,然而,在实际应用中只使用一种推荐策略是没有办法满足生产环境的需求的,多是将两者混合使用。
这里我用B站的推荐Feed流来简单举例(真实的工业级推荐模型要更为复杂),其中很多的推荐内容很大程度上都是通过基于内容的方法产生的。
这是充分利用到基于内容的推荐策略精细化标签描述的优势:当用户观看过感兴趣的视频后,往往更倾向于继续观看类似的内容。
比如下图中,当我在观看过几次iphone12的测评视频后,系统应该会更倾向于向我继续推荐iphone12相关的视频;但同时我们也发现,在Feed流中同样还存在着一些其他类型的视频内容,并且这些内容与我的观看历史关联度并不高,这又是为什么呢?
这里自问自答一下,这是因为如果只为用户推荐完全相似的内容,会发生推荐内容越推越窄的现象,这会大大降低用户观看内容时的新鲜感。
这个时候,便可以利用协同过滤算法来拓宽推荐的范围,于是在推荐Feed流中,我们常常既能看到与自己历史观看内容类似的视频,也能看到一些新奇的新内容(当然也会有部分新内容是通过人工干预的方式出现在你的Feed流中的)。
到这里,我们大致知道了我们平时所观看的推荐Feed流中的视频的。
四、召回与排序
像B站这样的大型内容平台,内容的数量是海量的(千万级甚至更多),所以在为用户进行内容推荐时往往会面临一个问题,即如何从海量内容中快速寻找用户感兴趣的内容,这个时候就需要用到召回与排序了:
1. 召回
召回阶段的主要职责是:从千万量级的候选物品里,采取简单模型将推荐物品候选集合快速筛减到千级别甚至百级别,这样将候选集合数量降下来,之后在排序阶段就可以上一些复杂模型,细致地对候选集进行个性化排序。
在召回阶段,工业界通用做法是多路召回,即使用不同的推荐策略来进行多路劲召回,每一个路径对应一个推荐策略,如下图所示:
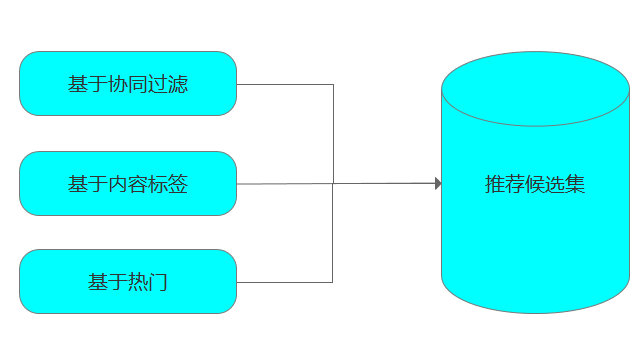
在基于内容标签的策略中,又被业界分了为两种,即长期内容标签与实时内容标签:
1)实时内容标签
多在近线部分完成,主要目的是实时收集用户行为反馈,并选择训练实例,实时抽取拼接特征,并近乎实时地更新在线推荐模型。这样做的好处是,用户的最新兴趣能够近乎实时地体现到推荐结果里。
2)长期内容标签
则在离线部分完成,通过对线上用户点击日志的存储和清理,整理离线训练数据,并周期性地更新推荐模型。对于超大规模数据和机器学习模型来说,往往需要高效地分布式机器学习平台来对离线训练进行支持。
需要注意的是,由于在召回阶段需要处理的数据集极其庞大。
所以需要尽量选择简单的模型和使用尽量少的特征,这样才可以快速有效的将内容视频的数量降下来,之后在排序过程中就可以使用一些复杂的模型来进行个性化排序。
2. 排序
由于召回阶段使用了不同的召回策略,导致了候选物的评判标准并不是唯一的,所以无法相互比较。
这里便需要使用排序,来对多个召回方法的结果进行统一打分,从召回层中选出最优的TopK,其中需要依靠各种机器学习算法与神经网络模型来对候选集中的内容进行预测打分排序,如WIDE&DEEP,LR+GBDT等。
这里我们来尽量通俗的描述一下机器学习与神经网络的在推荐中的作用:它们可以在依靠候选物品中大量的特征因子来寻找这些候选物品与用户之前的潜在联系,这里举一个简单的例子:
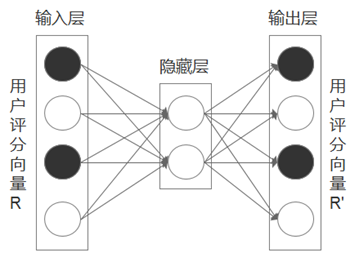
假设上图是一个自编码器推荐模型,它由输入层、隐藏层和输出层三个部分构成,假设此时在输入层中输入的是一个用户对的几个物品的评分向量R。
该评分向量中,含有用户打过分的数据(图中用黑色部分表示)和用户没有打过分的数据(图中用白色部分表示),自编码器会将输入层中的向量,通过某些规则映射到一个隐空间中(编码过程),然后再从隐空间中将其还原到原来的空间中(解码过程)。
此时会得另一个用户评分向量R’,显然两个评分向量中的数据在经过两次转换以后已经截然不同(指黑色部分),但经过转换后,在输出层的评分向量R’中,那些原本没有被打分的项目(白色部分),这次却拥有了分数。
此时我们需要做的就是通过对模型进行不断的迭代训练(即不断调整编码与解码的过程),来最小化两个评分向量之间的误差(即黑色部分输入与输出之间的误差)。
当用户的评分向量与之间的误差足够小时,R’中白色部分的评分便是该用户对这些未打分项目的预测值。
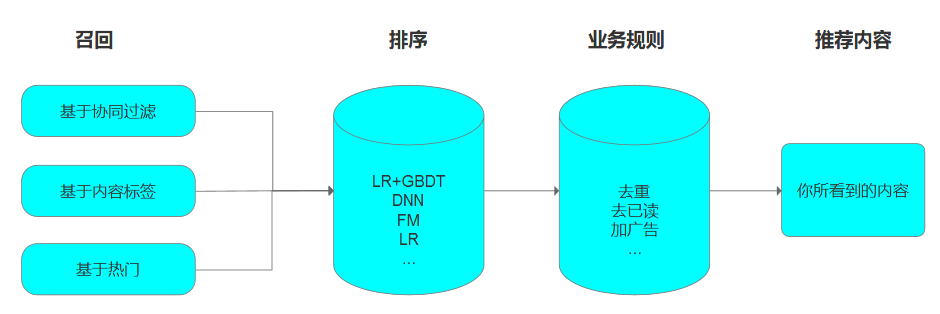
整个过程就像是一个黑盒,尽管过程不具备解释性,结果却意外的精准。在拿到侯选物的预测分之后便能以此为依据来进行开始排序,最后再加上一些业务规则如去重、去已读、加广告等,展示给用户:
五、结语
当然,真实的推荐系统是更为复杂的,这里只是为了方便理解才将其简化,省掉了很多细节,内容也是基于我自己对于推荐系统的理解,如有描述不足的地方,还请大家多多指教,共同进步!
本文由@Kazan 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash, 基于CC0协议









讲的很清晰,适合0基础的小白阅读
浅显易懂,深入浅出,赞
分析的很有道理!