
 起点课堂会员权益
起点课堂会员权益产品经理对数据库不必懂太多,这篇总结就够了!
编辑导语:中台和后台产品经理对于数据库一定不陌生,本篇文章中,作者对数据库进行了详细地总结,帮助你更好的理解和应用数据库,同时了解一些注意事项。

先把数据结构搞清楚,程序的其余部分自现。—— David Jones
对于中、后台产品经理而言,了解数据库不是为了做斜杠青年,而是因为你就在面对数据库。
本文目录:
- 产品经理对数据库掌握两点
- 理解数据库
- 注意事项和规范
- 应用数据库
- 常用查询语句
一、产品经理对数据库掌握两点
随着业务横向扩展,数据维度在扩大。随着业务纵深发展,数据量在倍增。随之而来的,是数据结构的不兼容、数据存储不够用,数据服务性能见拙,一切当初未考虑到的,都成了滋生障碍的伏笔。
产品不了解数据库原理的话,常常会与技术方案之间信息割裂。近期表现为互相扯皮,长远会引入“技术债”,并一度陷入插不上手、插不上嘴的懵逼状态。
举例两个场景:
第一:当你发现数据异常,或者你要调研一个功能的时候,需要拉一批数据做验证。
如果开发资源不够,你就要一直等着。而多数大而老的ERP系统确实惨不忍睹,整个团队很累很忙,这可能是你一段时间内不得不面对的常态。——所以你要自力更生。
第二:当你写需求的时候,在页面截图字段后画个圈丢过去,看着没毛病。但是一些值,根本不在页面。
如果你能给出一点线索,就可以让他效率高点。
所以,后端产品在工作中无法像C端产品那样做甩手掌柜:事实上往往还要产品给开发一两个建议方案,并告诉他要避免哪些坑,因为产品比开发多掌握了业务信息。
所以避不开数据库、数据表、字段这些接近技术的问题,那么作为产品要了解数据库到什么程度呢?
达到两点即可:
- 理解数据库作用原理,使你能更好与开发互相沟通,更好输出方案;
- 会用简单常用的SQL查询日常问题,实现基本的数据库应用价值。
二、理解数据库
1. 你在互联网看到一切皆“下载”
下载的就是服务器上的数据,广义地说,凡是存储数据的,都算是数据库,包括浏览器的缓存。
前端界面看到的内容,如果不是代码写死的,那么就是从数据库调取的。这就是为什么你看到页面会常常出现图片滞后,因为图片调用比较慢。
数据库就好像是一个仓库,开发用代码实现对其中数据的取值,最终给到页面呈现出来。
2. 数据库管理三个阶段
20世纪50年代中期以前,人工管理;20世纪50年代后到60年代中,文件系统阶段,数据共享性差。20世纪60年代后期以来,出现了统一管理数据的专门软件系统——DBMS。
3. 数据库模型主要三种
层次式数据库、网络式数据库和关系型数据库,现今最常用的即关系型数据库和非关系型数据库。
4. 关系型数据库
MYsql为典范,以二位报表的形式展示,因此MYSQL和PHP的组合是比较完美(报表多)。比MYsql强大的关系型数据库还有ORACLE,比如1000W条数据以上级别的数据,一般用的比较多的是ORACLE。
MYsql每张表只能有一个主键,但开发会创建多个字段的索引,目的是为了提高查询速度,至少提升上百倍查询速度。
5. 非关系型数据库(NoSQL)
NoSQL是作为传统关系型数据库的一个有效补充,处理对存储要求高,且并发处理较高的场合。
主要是数据库Mongodb,数据是散漫的,以键值对的形式存储,{ “key1”:”valude1” ,“key2”:” valude2 ” ,“key3”:” valude3”}。
6. 分布式账本数据库
区块连的数据存储方式,也有叫时间轴数据库的,一种分布式的、集体维护的、按照时间顺序将事件数据排列的“时间轴数据库”,目前还不是主流的商业价值方案。
7. 图片的存储比较特别
一种是直接把图片转换成二进制文件存储在数据库中,适合存储量少且重要的图片信息;另一种是存储图片的路径到数据库,用的时候直接调用路径给image等图像控件即可,适合存储量大但不是太重要的图片。
第二种方法常用、简单、实用。
三、注意事项和规范
1. 注意事项
- 建表的时候一般会增加冗余字段,比如 unique_code,用于存储备用字段来标定唯一性;
- 建表的时候可以增加预留字段:当数据量大的时候很难再加新字段,所以预估到数据增张较快的,一定要预留几个字段空位。便于日后数据表扩展;
- 当一个表无法再加字段的时候可以增加扩展表 ,后缀_ext ,与原表通过id关联起来;
- 新增表字段:要考虑,到历史数据初始化。比如历史数据全部为空或刷为某一个值;
- 统一规范表名前缀,比如可以定义t_前缀标示类型, f_前缀表示从其他系统获取的。
2. 命名规范
命名规范总的原则是可读性强,容易维护,具体的规范如下:
- 库名,表名,字段名,索引名统一使用小写字母,数字,以下划线分割;
- 库名,表名,字段名不要超过30个字符长度;
- 库名,表名,字段名不能单独使用DB的关键字,像lock,time,date,return,user等;
- 数据库的名称为:业务名称_[业务模块]_db,eg:oms_db,oms_history_db;
- 非唯一索引按照“idx_字段名称[_字段名称]”,唯一索引按照“uk_字段名称[_字段名称]”进行命名;
- 业务系统使用数据库账号命名为:业务名称_[r|w]。
3. 表名前缀
- 统计类数据表前缀:s
- 基础数据表前缀:b
- 基础类型维护数据表前缀:t
- 原始数据表前缀:in
- 订单数据表前缀:o
- 同步队列数据类型表前缀:iq
- 财务数据表前缀:f
4. 索引设计规范
- 单表索引个数不能超过30个;
- 关联字段,业务外键,create_time 字段必须建索引;
- 在选择性高的字段创建索引,注意组合索引的顺序,利用索引的最左原则;
- 使用复合索引,而不是添加新的索引;
- 避免冗余索引。
idx_a_b_c(a,b,c)
idx_a(a)
idx_a_b(a,b)
四、应用数据库
1. 安装数据管理系统
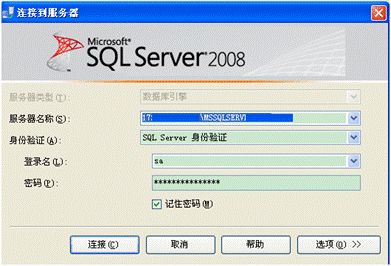
以下介绍最常用的MYSQL,首先要在PC端安装MYSQL数据库服务器,然后通过公司的数据库地址、密码连接上数据库(具体可以找开发协助完成)。
这样你就可以进入到数据库的各个表里看数据,一个公司若有多个系统,每个系统有至少一个属于自己的数据库,也有一个系统的数据分库存放的。
2. 熟悉数据库管理系统
数据库的表可以创建很多个,每个表描述一种实体与属性关系,每个属性就是一个字段。同一个数据库的表可以连表查询,不同数据库的表不能连表,因此在业务发展过程中会出现拆迁库、拆表的行为。
1)数据组成
一个基本的数据由数据类型、字段(也叫变量或者参数)、字段值组成:
CREATE TABLE `s_rule` ( `rule_id` int(11) NOT NULL AUTO_INCREMENT COMMENT ‘主键ID’, `rule_name` varchar(255) NOT NULL DEFAULT ” COMMENT ‘规则名称’, `rule_type_id` int(11) unsigned NOT NULL DEFAULT ‘0’ COMMENT ‘规则类型id,对应t_oms_rule_type表的自增id’,`solution_desc` varchar(255) NOT NULL DEFAULT ” COMMENT ‘处理方式描述’。
这里的表名是s_rule,4个字段都不允许为空。
2)字段类型
这里的字段类型是对字段值的约束,约束的根本原因是代码在执行调用取值的时候,与数据库一个约定,约定后就不会有不符合规制的数据进入,避免代码识别障碍导致报错,比如整形、字符串等。
3)主键
MYSQL每张表只能有一个主键,主键即为主关键字(primary key),可以由一个或多个字段组成,并且主关键字的列不能包含空值。
主键意义主要是用于其他表的外键关联,以及本记录的修改与删除。当两个表需要关联时,主关键字用来在一个表中引用来自于另一个表中的特定记录,一般用该表id做主键。
4) 索引
索引是由开发在设计表之后,再具体创建的,对数据库表中一或多个字段值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。例如:这样一个查询:select * from table1 where id=44。
如果没有索引,必须遍历整个表,直到ID等于44的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),直接在索引里面找44(也就是在ID这一列找),就可以得知这一行的位置,也就是找到了这一行。
可见,索引是用来定位的。索引分为聚簇索引和非聚簇索引两种,了解即可。主键唯一,但是表的索引可以有多个。
增加索引也有许多不利的方面 :
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加;
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大;
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
五、常用查询语句
1. 数据查询介绍
操作数据库的话,全世界的程序员都是统一的,都是用SQL语句来操作数据库。
产品经理一般不去建表、改表,所以create table <表名> 、alter table <表名>、drop table <表名>知道就可以。
产品更多是查询、统计,或者写出更新/插入/删除语句,让开发执行。查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
SELECT 命令可以读取一条或者多条记录:
- 可以使用星号*来代替全部字段,SELECT语句会返回表的所有字段数据;
- 可以使用 WHERE 语句来包含任何条件;
- 可以使用 LIMIT 属性来设定返回的记录数;
- 可以通过OFFSET指定SELECT语句开始查询的数据偏移量等等。
2. SQL语句技巧简介
1)where和having区别:
- where在分组前过滤,having在分组后过滤;
- having 字段必须是查询出来的,where 字段必须是数据表存在的;
- where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值;
- where 不可以使用合计函数。一般需用聚合函数才会用 having。
2)and优先级高于or,一般这种混合的句子建议用()使关系清晰,比如A>0 OR B<0 and c=0,相当于A>0 OR( B<0 and c=0)。
3)点击‘美化SQL’按钮,可以将语句断层使层次清晰,比如where name in(‘A’,’B’,’C),美化后:where goods_sn in(‘A’,’B’,’C)。
4)导出的表头换成汉字注释的方式:SELECT a.ds_sn as编码 ,a.pdt_name as 名称 FROM p_pro。
5) is和=有时是不同的,比如写作is null ,而不写=null。
6)MySQL中,null是未知的,且占用空间的。空值(”)是不占用空间的,注意空值的”之间是没有空格。
在进行count()统计某列的记录数的时候,如果采用的 NULL 值,会被系统自动忽略掉,但是空值是会进行统计到其中的。判断null使用is null或者is not null,但判断空字符使用 =”或者 <>”来进行处理。
7) 配合函数
- count():统计记录数
- avg():计算字段值的平均值
- sum():计算字段值的总和
- max():查询字段的最大值
- min():查询字段的最大值
比如:select count(id) from p_product。
8)排序:order by 字段 desc/ASC,select * from finance_order order by update_time desc limit 3。
9) 包含某个字符:select * from table where 列名 like ‘a%’(利用模糊查询)。
10) 查询表p_product中的第10、11、12、13行数据:select * from product limit 4 offset 9;或 select * from product limit 9,4。
11) 去重搜索:SELECT distinct(goods) FROM。
12) GROUP BY 语句进行组合:SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Custome。
13)查询三个字段维度 重复的数据
- select account,platform_sku,goods_sn, count(1) from t_oms_sku_map
- where id <1000000
- group by account,platform_sku,goods_sn
- having( count(1) > 1)
- limit 100
14)字段拼接
select concat(‘123′,’456’),mysql中的concat则可以拼接多个字符串。
将一个订单对应的多个产品输入在一起,select order_sn ,group concat (goods_sn)from 订单商品表。
15) in 括号内为或的关系
select name from product where goods in (‘103702505′,’103702805’) and (shelf_time > ‘2014-09-15 16:53:21’ or title like ‘_tylish%’)。
16)连表查询用join
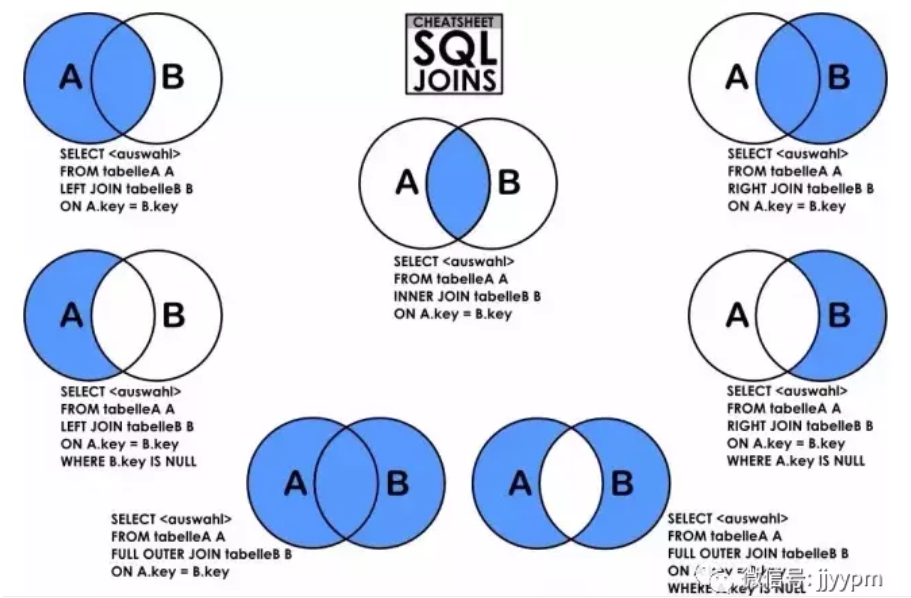
Inner Join最常见,叫做内联接,可以缩写成Join,找的是两张表共同拥有的字段。Left Join叫做左联接,以左表(join符号前的那张表)为主,返回所有的行。如果右表有共同字段,则一并返回,如果没有,则为空。
A Full Join B = A Left Join B + A Right Join B – A Inner Join B
还有其他连表方式既然用网络的图片:
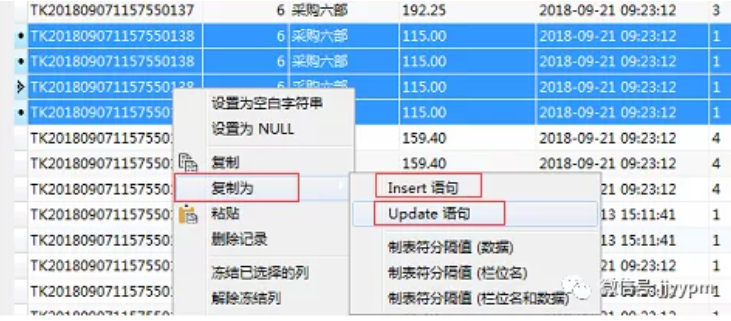
17)数据备份
选中数据,右键点击复制为insert/update,可以直接将筛选的字段备份为更新或插入语句,一旦需要还原的时候可以直接执行这几个语句。
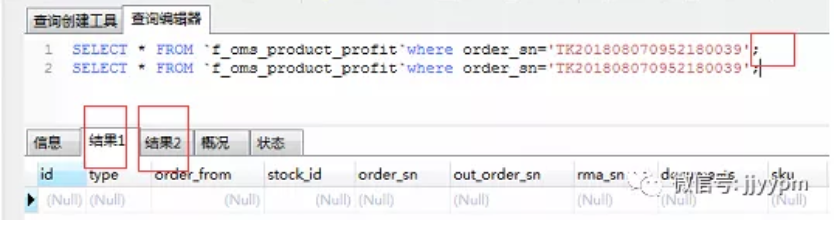
18)多个独立的查询语句之间可以用;隔开,同时执行,会分别输出。
#专栏作家#
唧唧歪歪PM,公众号:唧唧歪歪PM(ID:jjyypm),人人都是产品经理专栏作家,2019年年度作者。《后端产品经理宝典》作者,药学硕士转行互联网产品多年;熟悉跨境电商业务,医药领域;擅长大型后台体系,社交APP。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
专栏作家
唧唧歪歪PM,公众号:唧唧歪歪PM(ID:jjyypm),人人都是产品经理专栏作家,2019年年度作者。《后端产品经理宝典》作者,药学硕士转行互联网产品多年;熟悉跨境电商业务,医药领域;擅长大型后台体系,社交APP。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。










后胎昨的我头大。。
这些对于产品来说根本没有什么卵用,真正有水的是那些技术转型过去的产品经理,其他通过UI转过去的基本不懂技术,在技术面前基本不敢插话!总之知识面广对于一个产品来说非常重要!产品+技术+设计=NB
开发出身做产品,后面UI缺人,兼职搞了一下UI,小企业的产品才牛逼
小企业的产品最后基本都被逼到全栈了。