
 起点课堂会员权益
起点课堂会员权益推荐策略产品经理必读系列—第三讲推荐系统的召回(一)
编辑导语:推荐系统的7大环节中,其中非常核心的一环是召回,推荐系统中的召回策略是怎样的呢?本文重点介绍基于规则的召回,希望对你有所启发。

上一篇为大家介绍了推荐系统的整体架构,本篇为大家详细介绍推荐系统里面非常核心的一环就是召回。一共分为三篇文章来为大家详细介绍推荐系统中的召回策略。
一、主流的召回方法
目前市场上所有的召回方法都可以归纳为3大类。如下图所示:
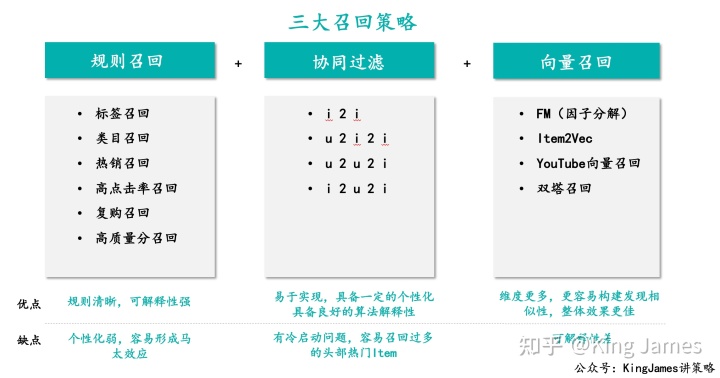
1.1 基于规则的召回
基于规则是最常用的召回策略,也是解释性最强的召回策略。常见的规则召回策略有:基于内容标签的召回,基于商品销量或者内容热度的召回,召回历史高点击率的物料,召回平台评价&质量分比较高的物料,召回用户经常购买的一些商品或者常看的物料; Part2将会针对这一部分详细展开介绍。
此种策略的优缺点:
- 优点:策略逻辑清晰明了,业务意义明确,可解释性极强;
- 缺点:个性化弱,千人一面,为每个用户推荐的商品比较类似。同时容易引起马太效应,头部的物料得到越来越多的曝光机会,尾部的物料曝光机会越来越少。
1.2 协同过滤
协同过滤的召回算法可以说是推荐系统最经典的算法了,甚至可以说有了协同过滤算法才真正代表了推荐系统的诞生。协同过滤算法最经典的是以下两个算法:
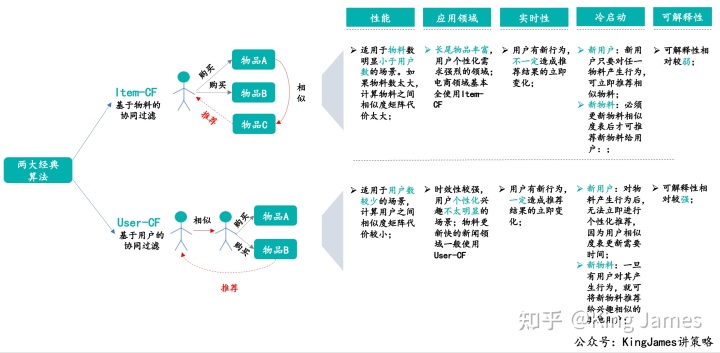
I 2 I (Item-CF):
用户A喜欢的物料a,为用户A推荐和物料a比较相似的物料b;该算法的核心问题是如何计算物料a和其他物料b,c,d,e……的相似度;该算法最早起源于电商巨头亚马逊。
U 2 U(User-CF):
用户A和用户B很相似,为用户A推荐用户B感兴趣且用户A之前没有接触过的物料a,因为二者是相似的,所以我们认为用户B感兴趣的物料用户A也会感兴趣;该算法的核心是如何计算用户与用户之间的相似度。
此种策略的优缺点:
- 优点:算法逻辑相对比较简单容易实现,但同时又有不错的效果,具备了一定的个性化。
- 缺点:和基于规则的召回具有同样的问题,冷启动的问题比较明显,同时同样会存在一定的马太效应,头部热门商品更容易和其他商品产生更多关联。但是整体协同过滤算法的出现已经让推荐系统进步了一大截;协同过滤算法下一篇文章将详细展开介绍。
1.3 基于向量的召回
其实无论是基于规则的召回,还是协同过滤算法。我们都是通过一定规则或者方法去计算物料与物料之间的相似度,用户与用户之间的相似度。协同过滤算法里面更多是一种基于统计维度的,而随着算法进步我们引入一种新的思想。基于向量去计算相似度。
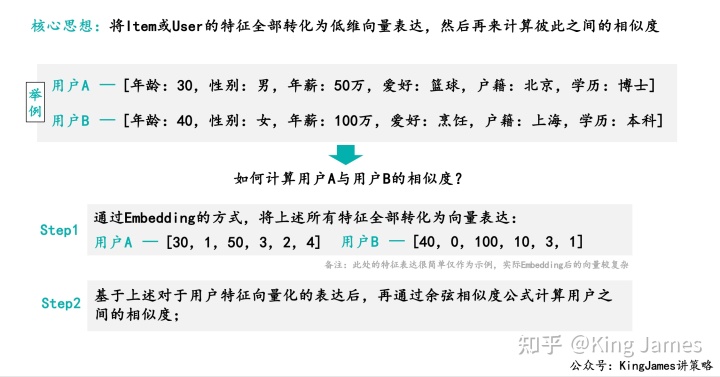
- FM:Factor Machine-因子分解机,是在2010年由谷歌推荐系统的大佬Steffen Rendle提出的。核心思想是通过对两两特征组合,引入交叉项特征;其次是通过引入隐向量(对参数矩阵进行矩阵分解),降低模型的高维灾难,完成对特征的参数估计;
- DSSM:Deep Structured Semantic Models,深度语义匹配模型,微软于2016年提出,又叫“双塔模型”。分别构建用户的user embedding和物料的item embedding,所以称为双塔。核心思想还是通过Embedding分别去表达User和Item的特征,然后再计算相似度。
此种策略的优缺点:
- 优点:特征理解更加深刻,模型效果更优。
- 缺点:模型可解释性差。
上述模型我们会在后续专门介绍向量召回的篇章中进行详细介绍。
二、基于规则的召回
下面重点详细为大家介绍基于规则召回里常见的一些召回思路。
2.1 标签召回
标签召回:推荐算法1.0时代都是基于内容的推荐,而基于内容的推荐基本上都是通过标签相似度来进行推荐。尤其是在电影&音乐网站上。比如你看过标签为“武侠”、“爱情”的电影,系统会基于这个标签给你召回相同标签的物料。
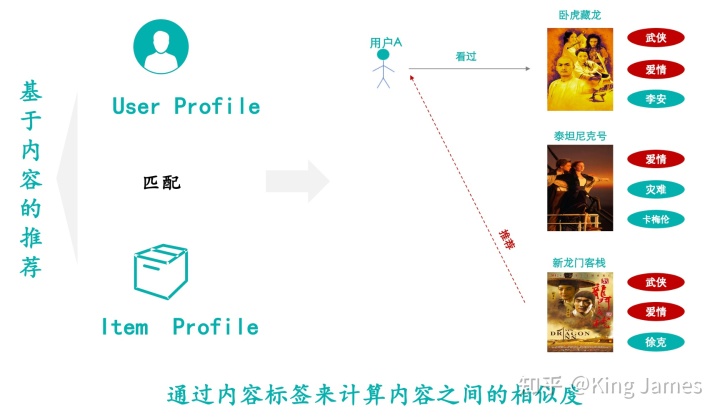
基于标签的召回核心是怎么给内容打标签,标签体系如何构建,这里面有大量的人工工作和业务经验。
2.2 Top Sale
热销召回:热销召回在电商领域比较多,基于商品的销量召回一些大家都比较喜欢,销量高的商品。这种召回策略应对冷启用户特别好用。同时扩展到内容领域逻辑也是一样,只是这里的“热销”可以换成“热度”。把销量的因素换成比如观看次数等等。
这里抛一个问题比如热销召回里“销量”如何定义?多长时间段的比较合适?如何既考虑长期销量,又考虑近期爆款?如何去除大促订单的影响?
2.3 Top CTR
高点击率商品召回:推荐系统核心还是要不断提升场景里面的点击率,所以我们在召回时就需要有专门的路去召回那些历史物料中点击率比较高的商品。当然这一路需要和其他路进行融合,不然会造成非常强的马太效应。这里继续抛一个问题:点击率的统计周期多久的比较合适?
2.4 Top Quality
高质量分的物料:此类物料是最适合用于冷启,在电商领域当一个新的用户访问系统不知道为他推荐什么商品时,我们可以为他推荐历史评价、销量、收藏、点赞等都反响比较好的商品。我们会对商品综合考虑上述因素计算一个商品的质量分,然后为其推荐排名Top K的商品。
2.5 Rebuy
复购的物料:这一路在生鲜电商里面经常用,很多用户每天买的蔬菜肉类都比较相似,所以推荐系统会专门有一路召回为用户推荐他历史购买过的商品。但是复购这一路召回在综合性电商里基本不用,比如淘宝&京东?大家可以思考一下为什么?
以上就是为大家整体介绍了推荐系统召回的主流思想,本篇重点介绍基于规则的召回。下面两篇分别详细介绍基于协同过滤的召回和基于向量的召回,敬请期待。
本文由 @King James 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议









此外,出于平台收入角度,由于展位是需要商家竞争获得,复购队列相当于给予了商家更多的免费流量资源,即导致了马太效应,挤压了同品类新商家的生存空间,又降低了平台的流量收入,于平台商家生态、平台收入、用户ctr三方面都没有收益
对于“复购这一路召回在综合性电商里基本不用,比如淘宝&京东”这一问题,私以为是由于这一路召回已经包含在了用户历史偏好这一路召回中,其复购周期性特征也包含在了其中,因此不需要重复性的再开发一路复购召回
怎么进群
如果不同时段的销量都要考虑的话,那就给时间区间加权重?大促时段的订单销量值给一个较低的权重系数,非大促时段的订单销量给一个较高的权重。
我不是做这方面的产品,不知道回答的在不在点子上,辛苦作者大佬解答哇
销量那个统计问题:
一些节日搞的这种大促活动带动的销量,不能反映平常的销量。
因此,在用作推荐使用的这个TOPN销量计算的时候,应当将一些大促时段的订单给去掉。
同时,可以考虑分类统计销量,然后最后拉齐到一个战线上才比较公平。(不同品类的销量在客观事实上,可能就不在一个维度上。比如电视购买频率低于衣服购买频率)
最后一个问题,粗浅回答下:
这是由于用户对购买的东西的消耗程度决定的。
用户在淘宝上多买的是衣物/鞋/电子产品,通常买完一件后,同样的品牌颜色款式不需要再买第二件。消耗慢。
而用户在生鲜电商平台上买的是 肉蛋蔬菜水果,消耗很快。平台为了提升用户体验,快点促成交易,很自然地可以为用户推荐其历史购买过的菜品。