
 起点课堂会员权益
起点课堂会员权益神器来了|这神器可以追寻各大网站的历史版本,2008年的京东居然长这样!

欢迎收看:神器来了
该栏目旨在搜罗产品经理、运营宝宝需要的各大神器工具,每周一荐。
来源起点学院(微信公众号:qidianxueyuan666)
最近天天听起点学院的导师讲,看一个产品,就要看它的1.0版本,那才是它最核心的价值所在,当然不排除跑偏的那些。
今天推荐一个神器,可以追寻到各大网站的所有历史版本,简直了活脱脱的一部活地图。
隆重推出!本期推荐神器!!!
Archive:互联网网站历史档案馆
网站地址:https://web.archive.org/
上线时间:1996年
Archive(archive.org)创建于1996年,由Alexa创始人布鲁斯特·卡利(Brewster Kahle)创办,是一个公益性质的计划。它通过定期收录和抓取全球网站的信息,并进行保存。
截至目前,他们已经保存了从1996年至今的超过2730亿个过往的网络页面或者网页快照。
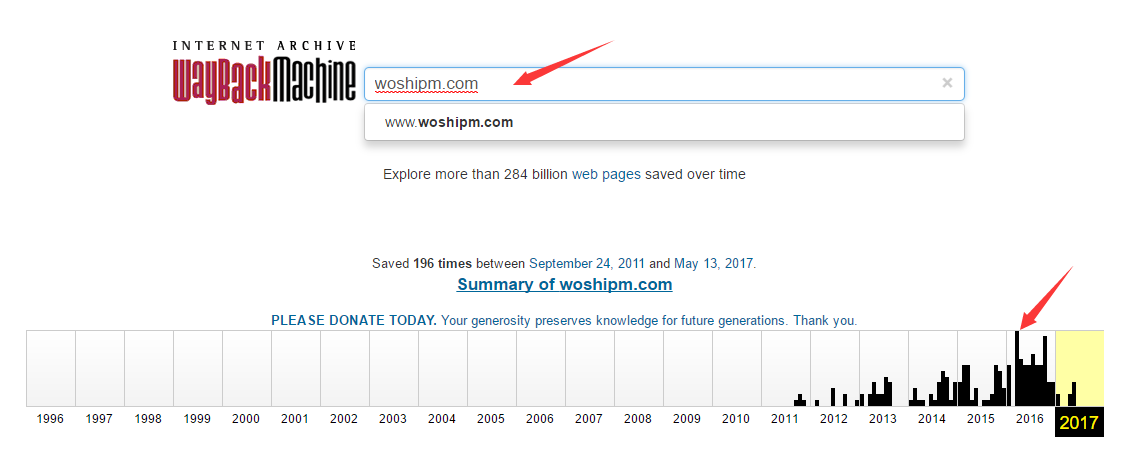
Come on,试验一下
曾经的人人都是产品经理社区:输入woshipm.com,下边出现的条状就是版本数,每一个小更新都会被记录
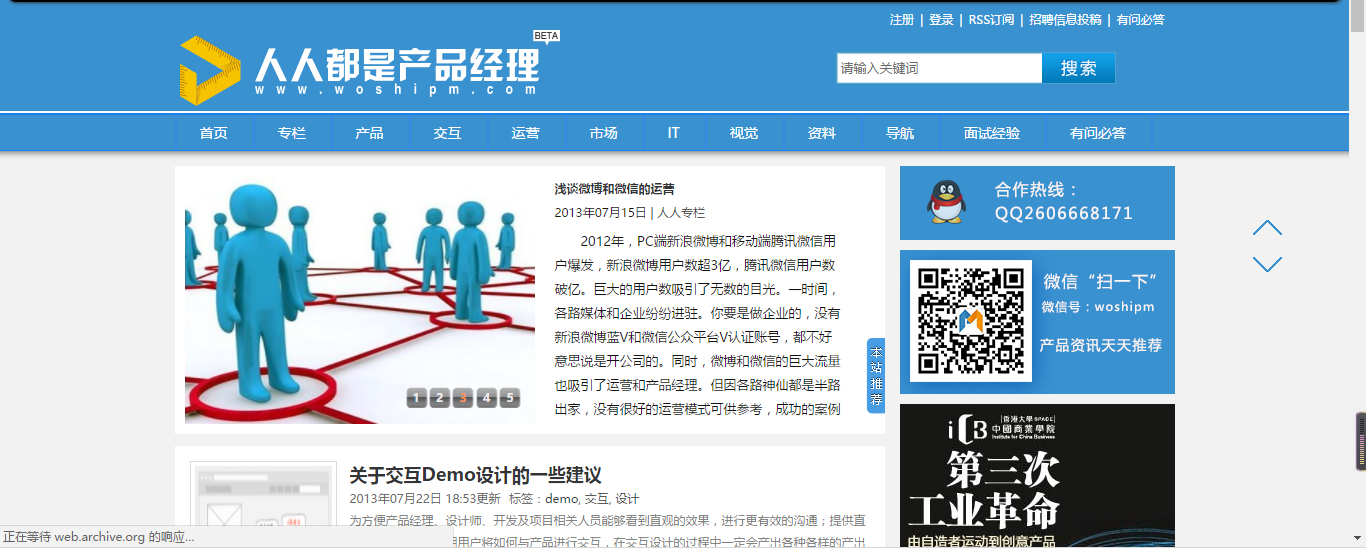
2013年的人人都是产品经理社区↓↓
很easy,对吧,再来顺手扒几个现在很6的互联网公司曾经的黑历史。
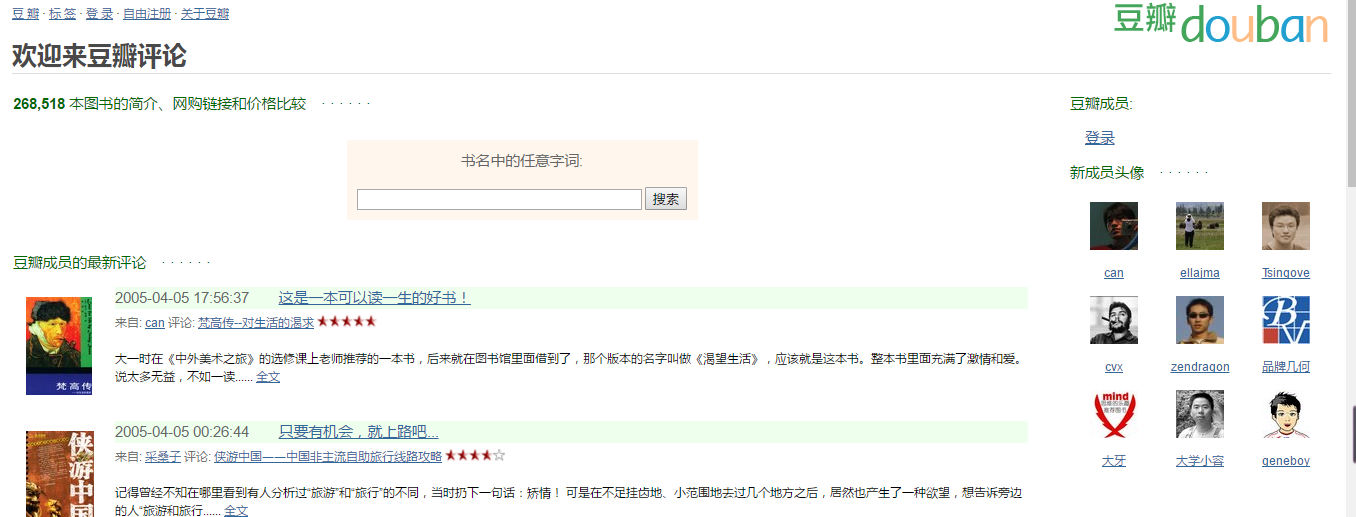
2014年的豆瓣,典型的图书集合社区↓↓
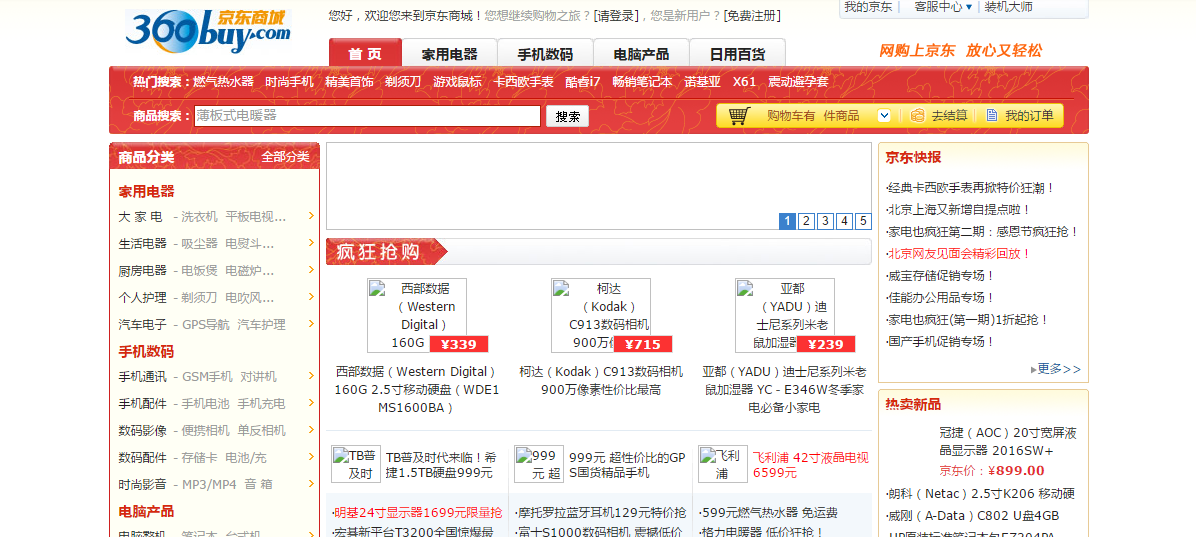
2008年的京东,还是3C产品的天下↓↓
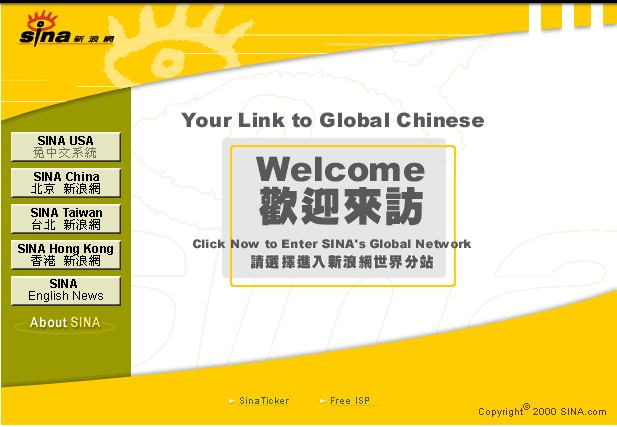
2000年的新浪网,你见过这样的新浪网吗?↓↓
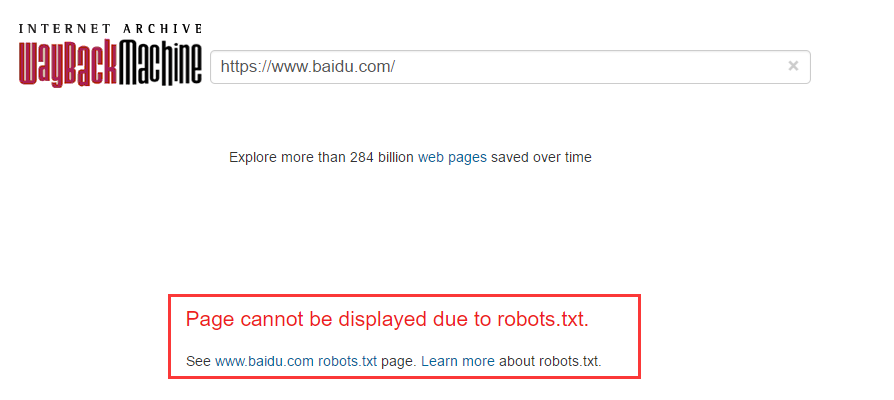
好吧,到这里我要认输了,大百度和大淘宝的历史版本都没有找到
看红色字体,应该是有技术限制了。
(此处求技术咖解释。。。)
88~本期推荐到此结束,各位玩好~
本期推荐神器:世界网站历史档案馆
https://web.archive.org/
注注注意:此神器为国外网站
每周推荐一款神器
更多神器推荐关注“起点学院”
起点学院微信公众号:qidianxueyuan666









不太好用,近期的网站版本都看不了,很多都是JS脚本的。只能看纯html
哈哈,好玩好玩
rotbot协议可以禁止爬虫抓取指定的页面、目录、甚至是全站。
原来如此
好东西,但需要翻墙 😎
要梯子么? 😐
已有梯子 😳 ,只是觉得麻烦