
 起点课堂会员权益
起点课堂会员权益技能Get:卡诺模型的运用实操

卡诺模型根据客户满意度和功能具备程度两个维度,对功能进行分类。
在工作中你可能经常遇到下面这几种情形:
- 在开发资源不够时,要在有限的时间里上线核心功能,从而更快地获取精准用户。
- 在产品从0开始,你可能有一堆想上线的功能,这时候需要你对所有的功能做一个排期。
- 需求堆积,你难以拒绝各方大佬的需求,比如运营,客户,老板等,你需要用数据来说明哪些需求是不合理的,哪些需求是当前阶段可以不用满足的。
这时候你就需要用到卡诺模型了,一个项目排期和需求管理的利器。那什么是卡诺模型呢?

简介
卡诺模型根据客户满意度和功能具备程度两个维度,对功能进行分类。一直以来我们都以为满意度是一维的,所以总是在产品上不停地加上新功能,然而有些功能不仅不会提升满意度,反而会降低满意度。不同属性的功能随着具备程度的变化,满意度的变化会有各自的特点。
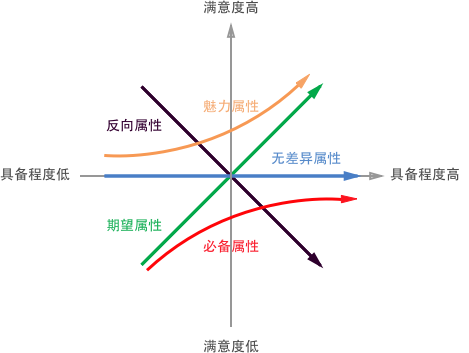
KANO模型
看上面的图,我将依次介绍这5种属性:
- 无差异属性:无论提供或不提供此功能,用户满意度不会改变,用户根本不在意有没有这个功能。这种费力不讨好的属性是需要尽力避免的。
- 魅力属性:让用户感到惊喜的属性,如果不提供此属性,不会降低用户的满意度,一旦提供魅力属性,用户满意度会大幅提升。
- 期望属性:如果提供该功能,客户满意度提高,如果不提供该功能,客户满意度会随之下降。
- 必备属性:这是产品的基本要求,如果不满足该需求,用户满意度会大幅降低。但是无论必备属性如何提升,客户都会有满意度的上限。
- 反向属性:用户根本都没有此需求,提供后用户满意度反而会下降。
举个栗子,吸引求职者的要素就可以用卡诺模型进行分类。
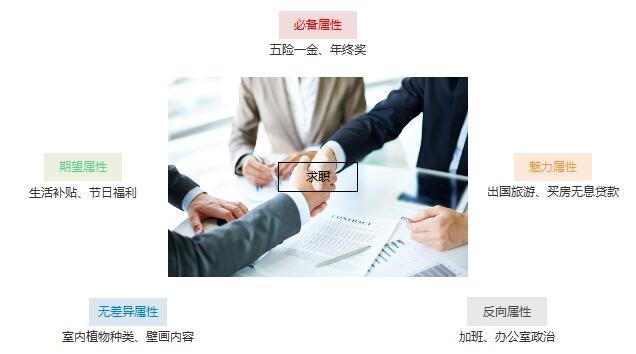
吸引求职者的要素
在运用卡诺模型时,有几点要注意的:
- 时间差异。没有一成不变的属性,很可能有一天魅力属性变成了必备属性,像指纹识别解锁。不能将当前时刻的卡诺模型分析结果作为永久的依据,即时性很重要。
- 用户群差异。不同的用户群所得到的结果可能不同,如果你要在相差较大的模块都加上该功能,比如企业版和个人版,最好区分用户群进行调查。
- 文化差异。不同的文化背景对功能属性的定义不同。比如对于报表的设计,中国人会习惯斜线表头,但是外国人可能难以接受。
接下来我要通过实际案例,详细介绍如何运用卡诺模型分析需求。
1.需求沟通
- 先筛选比较难以判断的需求,问题不宜过多,3~5个为宜。不然用户容易产生疲劳,输出不精准的答案。
- 再分析业务场景,是否适合使用卡诺模型。
- 适合:1)需求排期。2)理直气壮地砍需求。
- 不适合:1)不可量化满意度的需求,评估抽象的要素。比如调查提高品牌影响度,用户的满意度。2)仅用来测量用户满意度。卡诺模型是根据功能具备程度和客户满意度的关系对功能进行“分类”的工具。
- 确定调查用户,如果你的用户群相差较大,要根据模块或人物角色划分用户群,从每个用户群中抽取相同人数进行调查。细分用户群,可以更容易找出功能属性特点。
2.设置问卷
- 首先我们要对每个功能进行描述,所以你的问题要言简意赅,方便用户理解。
- 从正反两面去问用户对于该功能的满意度情况。
- 在问卷填写之前对每个选项进行统一说明。因为每个人的主观感受因为性格可能有较大差异,提前定义好每个选项可以减少误差。
- 追问每个功能对于用户的重要程度。可以用来区分功能对用户的影响程度。设置从非常重要过渡到非常不重要的5个选项。
- 如果无法描述清楚你的功能,试着贴张原型图或者画个示意图可以更直观表示。
举个栗子,如果要对微信的“看一看”功能进行卡诺模型分析,如下图。

问卷示例
完整的卡诺模型标准调查问卷链接:https://sojump.com/jq/15102379.aspx
3.属性归类分析
正反方向问题的答案可以组成一个二维属性表,每个单元格都代表一种答案类型,每个属性的总和为相同颜色单元格之和。
数据清洗:将全部选择我很喜欢或我很不喜欢的答案列为可疑答案,避免乱答数据影响分析结果。如果可疑结果过多,则你的问卷可能存在问题,比如功能描述不清。
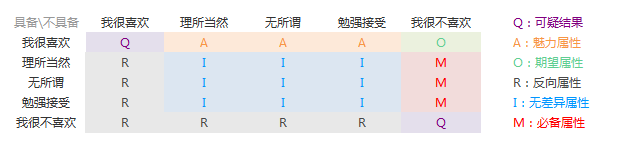
属性归类表-模版
由此我们可以看到每个属性所占百分比,占比最高的我们认为该功能的该属性因素最多。在样本量为50的问卷调查中,我们可以看到微信“看一看”功能的无差异属性较多。(样本量不足,仅作示范,有兴趣的旁友可以继续调查。)
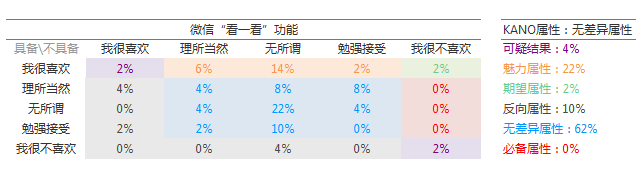
属性归类表-微信“看一看”功能
最后统计所有功能答案,得到每个功能的属性,以及每个功能的重要程度。
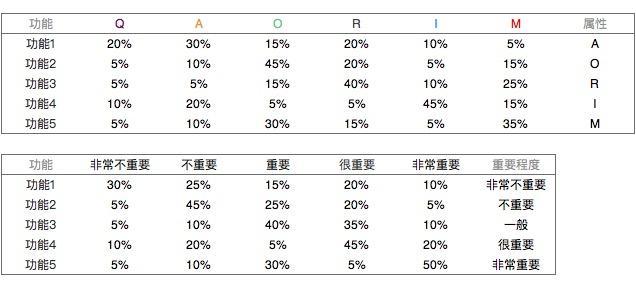
问卷统计结果
4.Better-Worse系数分析
对功能的属性进行归类后,我们要利用Better-Worse系数增加判断影响程度。
Better-Worse系数,表示某功能可以增加满意或者消除很不喜欢的影响程度。
- Better是增加后的满意系数。其数值通常为正,数值越大,用户满意度会提升越快。
- Worse是消除后的不满意系数。其数值通常为负,数值越小,用户满意度会下降越快。
根据Better-worse系数,优先满足系数绝对分值较高的功能或需求。
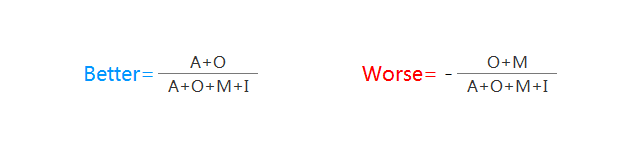
Better-Worse系数计算公式
根据微信“看一看”问卷分类对照表,进行Better-Worse系数分析。
- 增加该功能后的满意系数Better:(22%+2%)/(22%+2%+62%+0%)=28%
- 消除该功能后的满意系数Worse:-(2%+0%)/(22%+2%+62%+0%)=-2%
将每个功能的Better值和Worse绝对值作为气泡图的纵坐标和横坐标,气泡大小代表重要程度。落入不同区域代表所归属的属性。
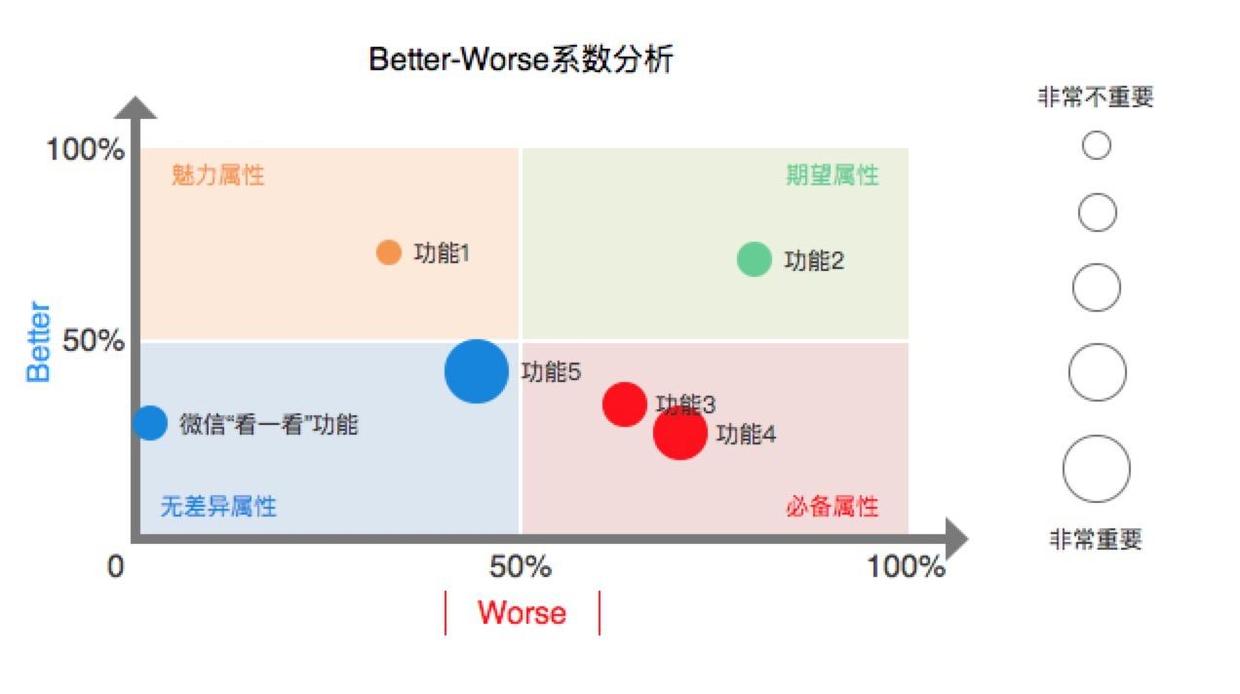
Brtter-Worse系数分析散点图
根据better-worse系数值,将散点图划分为四个象限。微信“看一看”功能落入了无差异属性的象限,丰富了我们之前用属性归类表的做的判断。无差异属性象限:Better系数值和Worse系数绝对值都很低的情况,即无论提供或不提供这些功能,用户满意度都不会有改变。
5.应用实践
得到分析结果后,我们就可以进行好好“收拾”需求了,需求的优先级顺序:必备属性>期望属性>魅力属性>无差异属性。
- 必备属性,产品开发中基本的需求都不能满足,而去实现其他需求,则是捡了芝麻丢了西瓜。
- 期望属性,具备程度越高,用户满意度越高。
- 魅力属性,超出用户期望的功能可以成为产品的亮点。但是亮点能不能脱颖而出而打动用户,对于初创团队是一场豪赌,所以优先级低于期望属性。
- 无差异属性,不管有没有,用户的满意度都不会提升,应尽力避免,在企业有余力的时候可以考虑开发。
- 反向属性,有这个功能,用户满意度反而下降,这是要极力避免的。
如果是相似或相同属性的话,我们可以结合重要程度进行判断。像功能3和功能4相差不大,但是功能4的重要程度明显高于功能3,则我们可以将功能4的优先级排在功能3之前。
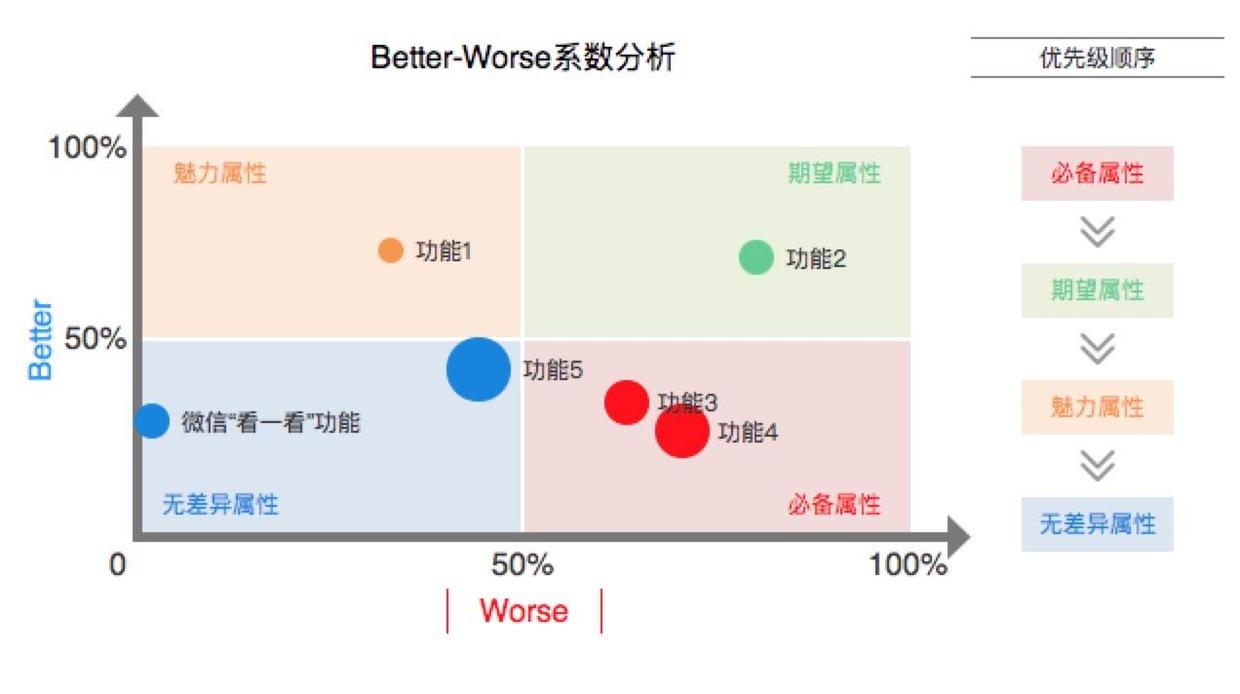
优先级顺序分析图
根据调研结果给所有的需求排定优先级,再将结果与相关方进行讨论,结合项目实际情况进行稍微调整,比如开发实现难度等。
PS:善于运用工具,而不是被工具所禁锢,也是一门学问哈哈。
作者:安琪Angela,公众号:idatadesign。互联网数据行业UX&PM,参与过数据分析saas平台和商业智能平台等产品设计。关注商业智能、人工智能和互联网金融。欢迎大家一起交流~
本文由 @安琪Angela 原创发布于人人都是产品经理。未经许可,禁止转载。









作者你好:Brtter-Worse系数分析散点图的“功能4”和“功能5”的Worse坐标值是不是计算错了?我根据你的问卷统计结果中第一张图计算出 “功能4”的Better值 =( 20% + 5%)/ ( 20%+5%+15%+45% ) ≈ 29%,Worse值 = -1*(5%+15%)/(20%+5%+15%+45%)的绝对值 ≈ 23%; “功能5”的Better值 = (10% + 30%)/(10%+30%+35%+5%)≈ 50%; Worse值 =-1*(30%+35%)/(10%+30%+35%+5%)的绝对值≈ 81%;
一键三连!
非常有用,而且很具有实际操作性~感谢这么详细地总结!
那重要程度根据什么来评定?Better-Worse图中的同属必备象限中的多个功能之间的优先级,怎么排?
和我一样第三步看了几遍没看懂的盆友,可以戳这个链接了解,来自智库百科的解释http://wiki.mbalib.com/wiki/KANO%E6%A8%A1%E5%9E%8B
为啥不是期望需求高于必备需求呢,他们都是没有的话用户满意度急剧降低,但期望需求一旦具备,用户满意度会提高,而必备需求不会提高,所以是不是期望需求优先级最高?
一个吃不饱的人不会去想怎么才能吃得健康营养
手动给你点赞~~~👍👍👍
谢谢分享~~一直想做这个~~
哈哈 😉
第一个需求沟通的合适不合适,有点看不明白。
简单来说,适合“归类”,不适合“测量”
总结的不错,终于有个实操版的了
感谢认可 😉
第三步已经得出的结论干嘛第四步还验证一遍,是不是多此一举了。
第四步是对第三步的丰富判断。第三步是对属性进行归类,第四步是深入研究某功能可以增加满意或者消除很不喜欢的“影响程度”。用物理学的概念来解释,第三步如果是“速度”的概念的话,第四步就是“加速度”的概念。