
 起点课堂会员权益
起点课堂会员权益
产品经理需要了解的算法——热度算法和个性化推荐
 产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
本文作者以新闻产品为例,并结合自己之前产品从零积累用户的经验,从而整理了作为PM需要了解的基本算法知识和实操。enjoy~
今日头条的走红带动了“个性化推荐”的概念,自此之后,内容型的产品,个性化算法就逐渐从卖点变为标配。伴随着“机器学习”,“大数据”之类的热词和概念,产品的档次瞬间提高了很多。而各种推荐算法绝不仅仅是研发自己的任务,作为产品经理,必须深入到算法内部,参与算法的设计,以及结合内容对算法不断“调教”,才能让产品的推荐算法不断完善,最终与自己的内容双剑合璧。
本文以新闻产品为例,结合了我之前产品从零积累用户的经验,整理了作为PM需要了解的基本算法知识和实操。
1. 算法的发展阶段
个性化推荐不是产品首次发布时就能带的,无论是基于用户行为的个性化,还是基于内容相似度的个性化,都建立在大量的用户数和内容的基础上。产品发布之初,一般两边的数据都有残缺,因此个性化推荐也无法开展。
所以在产品发展的初期,推荐内容一般采用更加聚合的“热度算法”,顾名思义就是把热点的内容优先推荐给用户。虽然无法做到基于兴趣和习惯为每一个用户做到精准化的推荐,但能覆盖到大部分的内容需求,而且启动成本比个性化推荐算法低太多。
因此内容型产品,推荐在发布初期用热度算法实现冷启动,积累了一定量级以后,才能逐渐开展个性化推荐算法。
2. 热度算法
2.1 热度算法基本原理
需要了解的是,热度算法也是需要不断优化去完善的,基本原理:
新闻热度分 = 初始热度分 + 用户交互产生的热度分 – 随时间衰减的热度分
Score = S0 + S(Users) – S(Time)
新闻入库后,系统为之赋予一个初始热度值,该新闻就进入了推荐列表进行排序;随着新闻不断被用户点击阅读,收藏,分享等,这些用户行为被视作帮助新闻提升热度,系统需要为每一种新闻赋予热度值;同时,新闻是有较强时效性的内容,因此新闻发布之后,热度必须随着新闻变得陈旧而衰减。
新闻的热度就在这些算法的综合作用下不断变化,推荐列表的排序也就不断变化。
2.2 初始热度不应该一致
上面的算法为每一条入库的新闻赋予了同样的热度值,但在现实使用后发现行不通,例如娱乐类别比文化类别受欢迎程度本身就高很多;或者突发了严重的灾害或事故;或是奥运会期间,体育类别的关注度突然高了起来;而此时如果还是每条新闻给同样的热度就不能贴合实际了。
解决办法就是把初始热度设置为变量:
(1)按照新闻类别给予新闻不同的初始热度,让用户关注度高的类别获得更高的初始热度分,从而获得更多的曝光,例如:

(2)对于重大事件的报道,如何让它入库时就有更高的热度,我们采用的是热词匹配的方式。
即对大型新闻站点的头条,Twitter热点,竞品的头条做监控和扒取,并将这批新闻的关键词维护到热词库并保持更新;每条新闻入库的时候,让新闻的关键词去匹配热词库,匹配度越高,就有越高的初始热度分。
这样处理后,重大事件发生时,Twitter和门户网站的争相报道会导致热词集中化,所有匹配到这些热词的新闻,即报道同样事件的新闻,会获得很高的初始热度分。
2.3 用户行为分规则不是固定不变的
解决了新闻入库的初始分之后,接下来是新闻热度分的变化。先要明确用户的的哪些行为会提高新闻的热度值,然后对这些行为赋予一定的得分规则。例如对于单条新闻,用户可以点击阅读(click),收藏(favor),分享(share),评论(comment)这四种行为,我们为不同的行为赋予分数,就能得到新闻的实时用户行为分为:
S(Users) = 1*click + 5*favor + 10*comment + 20*share
这里对不同行为赋予的分数为1,5,10,20,但这个值不能是一成不变的;当用户规模小的时候,各项事件都小,此时需要提高每个事件的行为分来提升用户行为的影响力;当用户规模变大时,行为分也应该慢慢降低,因此做内容运营时,应该对行为分不断调整。
当然也有偷懒的办法,那就是把用户规模考虑进去,算固定用户数的行为分,即:
S(Users) = (1*click + 5*favor + 10*comment + 20*share)/DAU * N(固定数)
这样就保证了在不同用户规模下,用户行为产生的行为分基本稳定。
2.4 热度随时间的衰减不是线性的
由于新闻的强时效性,已经发布的新闻的热度值必须随着时间流逝而衰减,并且趋势应该是衰减越来越快,直至趋近于零热度。换句话说,如果一条新闻要一直处于很靠前的位置,随着时间的推移它必须要有越来越多的用户来维持。
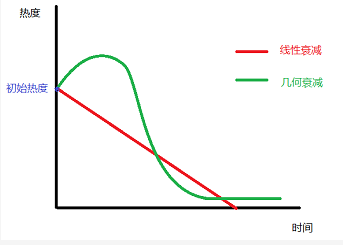
我们要求推荐给用户的新闻必须是24h以内,所以理论上讲,衰减算法必须保证在24h后新闻的热度一定会衰减到很低,如果是线性衰减,当某些新闻突然有大量用户阅读,获得很高的热度分时,可能会持续排名靠前很久,让用户觉得内容更新过慢。
参考牛顿冷却定律,时间衰减因子应该是一个类似于指数函数:
T(Time) = e ^ (k*(T1 – T0))
其中T0是新闻发布时间,T1是当前时间。
而由于热度的发展最终是一个无限趋近于零热度的结果,最终的新闻的热度算法也调整为:
Score = ( S0(Type) + S(Users) ) / T(Time)
2.5 其他影响因素
很多新闻产品会给用户“赞”,“踩”或“不在推荐此类”的选项,这些功能不仅适用于个性化推荐,对热度算法也有一定的作用。
新闻的推送会造成大量的打开,在计算热度的时候需要排除掉相关的影响。类似于这样的因素,都会对热度算法产生影响,因此热度算法上线后,依然需要不断地“调教”。建议把所有的调整指标做成可配项,例如初始热度分,行为事件分,衰减因子等,从而让产品和运营能实时调整和验证效果,达到最佳状态。
3. 基于内容的推荐算法
现在,你的内容产品顺利度过了早期阶段,拥有了几万甚至十几万级别的日活。这时候,你发现热度算法导致用户的阅读内容过于集中,而个性化和长尾化的内容却鲜有人看,看来是时候开展个性化推荐,让用户不仅能读到大家都喜欢的内容,也能读到只有自己感兴趣的内容。
个性化推荐一般有两种通用的解决方案,一是基于内容的相关推荐,二是基于用户的协同过滤。由于基于用户的协同过滤对用户规模有较高要求,因此更多使用基于内容的相关推荐来切入。
这里引入一个概念叫“新闻特征向量”来标识新闻的属性,以及用来对比新闻之间的相似度。我们把新闻看作是所有关键词(标签)的合集,理论上,如果两个新闻的关键词越类似,那两个新闻是相关内容的可能性更高。 新闻特征向量是由新闻包含的所有关键词决定的。得到新闻特征向量的第一步,是要对新闻内容进行到关键词级别的拆分。
3.1 分词
分词需要有两个库,即正常的词库和停用词库。正常词库类似于一本词典,是把内容拆解为词语的标准;停用词库则是在分词过程中需要首先弃掉的内容。
停用词主要是没有实际含义的,例如“The”,“That”,“are”之类的助词;表达两个词直接关系的,例如“behind”,“under”之类的介词,以及很多常用的高频但没有偏向性的动词,例如“think”“give”之类。显而易见,这些词语对于分词没有任何作用,因此在分词前,先把这些内容剔除。
剩下对的内容则使用标准词库进行拆词,拆词方法包含正向匹配拆分,逆向匹配拆分,最少切分等常用算法,这里不做展开。
因为网络世界热词频出, 标准词库和停用词库也需要不断更新和维护,例如“蓝瘦香菇”,“套路满满”之类的词语,可能对最终的效果会产生影响,如果不及时更新到词库里,算法就会“一脸懵逼”了。
因此,推荐在网上查找或购买那些能随时更新的词库,各种语种都有。
3.2 关键词指标
前面已经说过,新闻特征向量是该新闻的关键词合集,那关键词的重合度就是非常重要的衡量指标了。
那么问题来了,如果两条新闻的关键词重合度达到80%,是否说明两条新闻有80%的相关性呢?
其实不是,举个例子:
(1)一条“广州摩拜单车投放量激增”的新闻,主要讲摩拜单车的投放情况,这篇新闻里“摩拜单车”是一个非常高频的词汇,新闻在结尾有一句“最近广州天气不错,大家可以骑单车出去散心”。因此“广州天气”这个关键词也被收录进了特征向量。
(2)另外一条新闻“广州回南天即将结束,天气持续好转”,这篇新闻结尾有一句“天气好转,大家可以骑个摩拜单车出门溜溜啦”,新闻里面“广州天气”是非常高频的词汇,“摩拜单车”尽管被收录,但只出现了一次。
这两个新闻的关键词虽然类似,讲的却是完全不同的内容,相关性很弱。如果只是看关键词重合度,出现错误判断的可能性就很高;所以特征向量还需要有第二个关键词的指标,叫新闻内频率,称之为TF(Term Frequency),衡量每个关键词在新闻里面是否高频。
那么问题来了,如果两条新闻的关键词重合度高,新闻中关键词的频率也相差无几,是否说明相关性很强呢?
理论上是的,但又存在另外一种情况:如果我们新闻库里所有的新闻都是讲广州的,广州天气,广州交通,广州经济,广州体育等,他们都是讲广州相关的情况,关键词都包含广州,天河,越秀,海珠(广州各区)等,并且有着类似的频率,因此算法很容易将它们判断为强相关新闻;从地域角度讲,这种相关性确实很强,但从内容类别层面,其实没有太多相关性,如果我是一个体育迷,你给我推荐天气,交通之类的内容,就没多大意义了。
因此引入第三个关键词的指标,即关键词在在所有文档中出现的频率的相反值,称之为IDF(Inverse Document Frequency)。为什么会是相反值?因为一个关键词在某条新闻出现的频率最大,在所有文档中出现的频率越小,该关键词对这条新闻的特征标识作用越大。
这样每个关键词对新闻的作用就能被衡量出来即TFIDF=TF * IDF,这也就是著名的TF-IDF模型。
3.3 相关性算法
做完分词和关键词指标后,每一篇新闻的特征就能用关键词的集合来标识了:
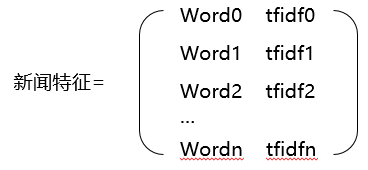
其中word0,1,2……n是新闻的所有关键词,tfidf0,1,2……n则是每个关键词的tfidf值。
两个新闻的相似度就能通过重合的关键词的tfidf值来衡量了。根据之前所学的知识,几何中夹角余弦可以用来衡量两个向量的方向的差异性,因此在我们的算法中使用夹角余弦来计算新闻关键词的相似度。夹角越小,相似度越高。
有了关键词和各关键词的tfidf之后,就可以计算新闻的相似度了。假设两条新闻的特征列表如下:
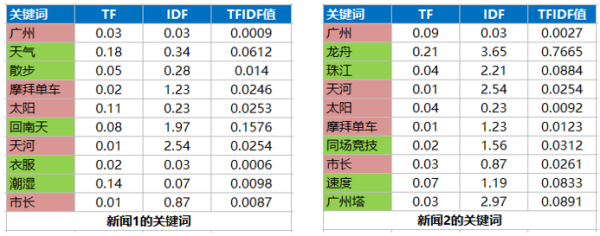
可以看到两条新闻有5个重合的关键词:广州,摩拜单车,太阳,天河和市长,因此两条新闻的相关性由这5个关键词决定,计算方式如下:
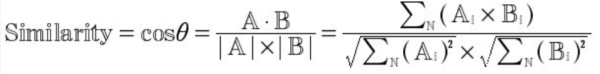
得出两条新闻的相关性最终值;用同样的方法能得出一条新闻与新闻库里面所有内容的相关性。
3.4 用户特征
得到新闻特征以后,还需要得到用户特征才能对两者进行匹配和推荐,那怎么获得用户特征呢?
需要通过用户的行为来获得,用户通过阅读,点赞,评论,分享来表达自己对新闻内容的喜爱;跟热度排名类似,我们对用户的各种行为赋予一定的“喜爱分”,例如阅读1分,点赞2分,评论5分等,这样新闻特征跟用户行为结合后,就能得到用户的特征分。
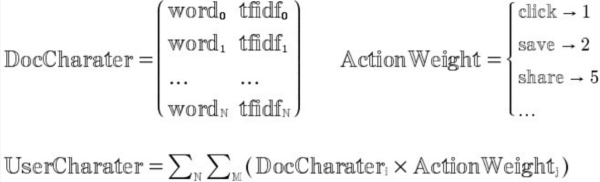
而随着用户阅读的新闻数越来越多,该用户的标签也越来越多,并且越发精准。
从而当我们拿到新闻的特征后,就能与用户的关键词列表做匹配,得出新闻与用户阅读特征的匹配度,做出个性化推荐。
3.5 其他运用
除了个性化推荐,基于内容的相关性算法能精准地给出一篇新闻的相关推荐列表,对相关阅读的实现非常有意义。此外,标签系统对新闻分类的实现和提升准确性,也有重要的意义。
3.6 优缺点
基于内容的推荐算法有几个明显优点:
- 对用户数量没有要求,无论日活几千或是几百万,均可以采用;因此个性化推荐早期一般采用这种方式;
- 每个用户的特征都是由自己的行为来决定的,是独立存在的,不会有互相干扰,因此恶意刷阅读等新闻不会影响到推荐算法。
而最主要的缺点就是确定性太强了,所有推荐的内容都是由用户的阅读历史决定,所以没办法挖掘用户的潜在兴趣;也就是由于这一点,基于内容的推荐一般与其他推荐算法同时存在。
4. 基于用户的协同推荐
终于,经过团队的努力,你的产品已经有了大量活跃用户了,这时候你开始不满足于现有的算法。虽然基于内容的推荐已经很精准了,但总是少了那么一点性感。因为你所有给用户的内容都是基于他们的阅读习惯推荐的,没能给用户“不期而遇”的感觉。
于是,你就开始做基于用户的协同过滤了。
基于用户的协同过滤推荐算法,简单来讲就是依据用户A的阅读喜好,为A找到与他兴趣最接近的群体,所谓“人以群分”,然后把这个群体里其他人喜欢的,但是A没有阅读过的内容推荐给A;举例我是一个足球迷,系统找到与我类似的用户都是足球的重度阅读者,但与此同时,这些“足球群体”中有一部分人有看NBA新闻的习惯,系统就可能会给我推荐NBA内容,很可能我也对NBA也感兴趣,这样我在后台的兴趣图谱就更完善了。
4.1 用户群体划分
做基于用户的协同过滤,首先就要做用户的划分,可以从三方面着手:
(1)外部数据的借用
这里使用社交平台数据的居多,现在产品的登录体系一般都借用第三方社媒的登录体系,如国外的Facebook、Twitter,国内的微信、微博,借用第三方账户的好处多多,例如降低门槛,方便传播等,还能对个性化推荐起到重要作用。因为第三方账户都是授权获取部分用户信息的,往往包括性别,年龄,工作甚至社交关系等,这些信息对用户群划分很有意义。
此外还有其他的一些数据也能借用,例如IP地址,手机语种等。
使用这些数据,你很容易就能得到一个用户是北京的还是上海的,是大学生还是创业者,并依据这些属性做准确的大类划分。比如一篇行业投资分析出来后,“上海创业圈”这个群体80%的用户都看过,那就可以推荐给剩下的20%。
(2)产品内主动询问
常见在产品首次启动的时候,弹框询问用户是男是女,职业等,这样能对内容推荐的冷启动提供一些帮助。但总体来说,性价比偏低,只能询问两三个问题并对用户的推荐内容做非常粗略的划分,同时要避免打扰到用户;这种做法算是基于用户个性化的雏形。
(3)对比用户特征
前文已经提到过,新闻的特征加用户的阅读数据能得到用户的特征,那就可以通过用户特征的相似性来划分群体。
4.2 内容推荐实施
我们结合一个很小的实例来了解用户协同过滤的原理,包括如何计算用户之间的相似性和如何做出推荐。假设有A、B、C、D和E共5个用户,他们各自阅读了几篇新闻并做出了阅读,赞,收藏,评论,分享操作,我们对这几种行为赋予的分数分别为1分、2分、3分、4分和5分,这样用户对每条新闻都有自己的得分,其中“-”表示未阅读,得分如下:
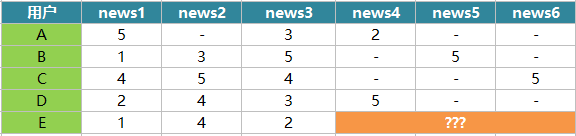
接下来,我们需要给用户E推荐4,5,6中的哪一篇?
用户的阅读特征向量由用户所有的阅读数据决定,我们以用户E阅读过的新闻数据作为参考标准,来找到与E最相似的用户。
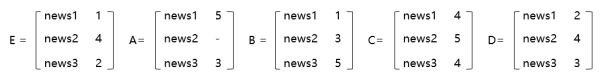
多维向量的距离需要通过欧几里得距离公式来计算,数值越小,向量距离约接近。
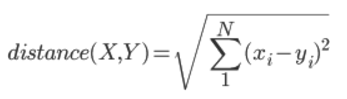
算出结果:
- distance(E,A)=4.123 (用户A没有阅读news2,因此news2的数据不能用来计算与用户E的相似度,这里取1,3)
- distance(E,B)=3.162
- distance(E,C)=3.742
- distance(E,D)=1.414
因此得出结果:用户D是与用户E阅读喜好最接近的那个,应该优先归为同一类用户。最终结论根据用户D的阅读数据,优先推荐news4。
4.3 内容选取
我们通过阅读特征向量把用户做群体划分后,接下来就是如何获取新闻推荐的优先级。上面的例子里面只需要选出一个相似用户,并且用户A,B,C,D都只阅读news4,5,6中的一条,所以比较简单,但现实情况中,同一个用户群体阅读的新闻多且随机,用户交互更是错综复杂,如何得出推荐新闻的优先级呢?
假设用户X在系统归属于群体A,这个群体有n个用户,分别为A0,A1,A2……An,这些用户的集合用S(X,n)表示。
- 首先,我们需要把集合中所有用户交互过(阅读,评论等)的新闻提取出来;
- 需要剔除掉用户X已经看过的新闻,这些就不用再推荐了,剩下的新闻集合有m条,用N(X,m)来表示;
- 对余下的新闻进行评分和相似度加权的计算,计算包括两部分,一是用户X与S(X,n) 每一个用户的相似性,二是每个用户对新闻集N(X,m)中每条新闻的喜好,这样就能得到每条新闻相对于用户X的最终得分;
- 将N(X,m)中的新闻列表按照得分高低的顺序推荐给用户。
4.4 优缺点
相比于基于内容的推荐算法,基于用户的协同过滤同样优缺点明显。
优点主要在于对分词等算法的精确度无太大要求,推荐都是基于用户的行为数据去不断学习和完善;同时能发现用户的潜在阅读兴趣,能“制造惊喜”。
而缺点则是启动的门槛高,用户量不够时几乎无法开展;并且学习量不够时推荐结果较差。
5. 总结
关于个性化推荐的算法,在网上有很多资料,也有很多其他的实现方法,因为笔者了解也有限,所以也不敢描述。如有兴趣可以自行搜索。热度和个性化推荐算法,作为大部分内容型产品的核心卖点之一,依然在不断地进化和完善中。没有哪种算法是完美的,甚至没有哪种算法是一定优于其他的,在实际使用中,很多产品都是多算法结合去做好内容推荐。
而产品经理在算法的实施中,绝对不是一句“我们要做个性化推荐”就完事的,必须深入算法内部,对算法的原理做深入了解,然后结合自己的产品特征来部署和优化。
因此我站在产品经理的角度,整理了这一篇初步的算法相关的介绍,如有对文中内容感兴趣的,欢迎探讨!如有描述不当之初,敬请指正,感激不尽!
最后,需要对我的团队表示感谢,飞哥在算法的研究中打了头阵并给出了细致的分享,宗荣对算法进行了无数轮的调整和优化,凯华在关键词的部署和效果验证中付出了很多心血……喜欢那些日子里大家一起从零开始学习和实现算法,让推荐效果越来越好。
作者:卢争超,前UC,腾讯海外产品经理,负责UC Browser,微信支付等产品的国际化,现创业中。多年产品策划运营和管理经验,在工具,支付,内容,企业服务型产品的策划和运营领域经验丰富。
本文由 @卢争超 原创发布于人人都是产品经理。未经许可,禁止转载。


















第一篇文章,10W+, 大厂思维真是恐怖如斯。
有做内容产品的吗 可以一起交流下吗
这是一条硬科普
写的还是蛮好
产品小白也看懂了,深入浅出,超级赞
太赞了
学习了
基于数据的算
干货满满,学习了,谢谢分享!
目前算法团队已经将文中的框架基本实现,面对的问题主要是:1.如何判断每一篇文章的时效?(因为文章特征千差万别,为了资源有效利用不能统一按固定时间处理,导致不少线上case);2.除了点击外,用户点赞/分享/评论的行为过于稀疏,尤其是非垂直领域内容平台,用户往往表现的并非真实兴趣,导致一些兴趣探索不能得到很好的效果,有什么好的解决办法呢?谢谢!
另外希望作者有时间多多更新呀~
产品经理写到prd里的个性化推荐要怎么写
想问下k值是多少呀
同问
k值应该指的是冷却系数。如果假定一篇新文章的初始分数是100分,24小时之后”冷却”为1分,那么可以计算得到”冷却系数”约等于0.192 如果你想放慢”热文排名”的更新率,”冷却系数”就取一个较小的值,否则就取一个较大的值(节选自 https://blog.csdn.net/zhuhengv/article/details/50476306)
写得很好,请问下有没有相关得书籍推荐
同求。