
 起点课堂会员权益
起点课堂会员权益识别王者英雄:一个 PM 的机器学习入门之旅

学习,是一个 PM 永远不该停下的生存技巧。
基础概念
上个月开始从原理层面了解机器学习,选了一本在线电子书《Neural Networks and Deep Learning》作为教材,事实证明该书实在不错,让一个毫无神经网络、机器学习背景知识的 PM 很快就读懂了其中的基本原理。
附上此书第一章我的读书笔记,对于 PM 而言,读完第一章就够了,基本概念和方法论在这章里解释得十分清楚。读完之后有一种打开新世界大门的感觉。
行动诱因
上周末看到 Twitch 做的 ClipMine,基于游戏直播画面识别出守望先锋、炉石传说中玩家正在玩的英雄和段位,供观众在多个主播间筛选自己想看的英雄。顿时手痒,想着这样的需求在国内直播行业里其实也是存在的,比如将几千个正在直播的王者荣耀直播流识别出当前在玩的英雄,这样观众就可以选择自己想看的英雄专注的看了。
手痒,又碰上周末,看来不得不做点啥了。
工程分析
王者荣耀这款游戏,想要识别其中正在玩的英雄,有几个思路:
1. 游戏开始前选择英雄的界面
2. 游戏开始后加载资源时的 Loading 界面
3. 游戏进行中屏幕正中央的英雄本身
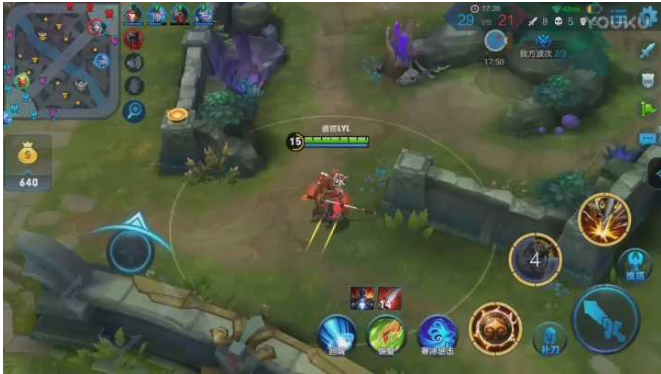
4. 游戏进行中屏幕右下角的技能图标

分析如下:
- 在整个直播时长中,1 和 2 的时间占比是很短的,而且如果玩家直接直播游戏进行中的画面,那就没法获取英雄信息了。
- 并且 1 和 2 的界面里,当前玩家所处的位置并不固定,如果还要加上玩家位置的判定,工程复杂度上升不止一点点。
- 因为英雄在游戏中永远处于正中央,所以 3 其实挺适合用来做训练素材。但考虑到英雄有不同的动作和朝向,最重要的是这个游戏单一英雄还有不同的皮肤。各种条件综合起来,一方面需要提供更多的训练素材,一方面也加大了机器学习的难度。
- 而 4 这个界面,英雄的技能在较长的时间段内是不会变的,而且位置稳定,在整个直播时长里出现的时间占比也很高,唯一变化较大的是技能发动间歇里的读秒倒计时。综合考虑,4 是最适合用来做训练素材的。
确定了这点后,就能理清整个项目的运转流程了:
- 获取 60 几个英雄对应的游戏进行中图片,每个英雄不少于 1000 张(拍脑袋的,我也不知道多少张合适)
- 将 1 中图片的右下角截取出来,作为机器学习的训练资料
- 运行机器学习代码,训练出可以识别不同英雄技能的模型
- 从待识别的直播流中抽取画面,截取右下角的技能画面,用 3 中的模型去识别看是哪个英雄的技能,从而完成对直播流英雄的识别
流程已然清晰,但后面的工作量才是最大的,先来看看如何获取训练资料吧。
收集素材
做机器学习的都知道,写代码不是最难的部分,收集优质的训练素材才是。如何能够快速获得 60 多个英雄分别对应的 1000 张图片呢?且不说找到 6 万多张图片的难度,找到后难道要我人肉来标记哪张图片是哪个英雄?如果真要这么做,估计一个人是很难完成了。
这一次想出的取巧方法是直接去优酷上搜索「王者荣耀」+「英雄名字」,就能搜到很多玩家录好的英雄视频。于是让团队里的同学帮忙,很快收集齐了所有英雄的对战视频各 1 个。然后用 Adapter 这样的软件将视频按一秒一帧转化为几千张图片。(不过一开始没有发现 Adapter 这个软件,当时是用 OpenCV 去一帧帧把视频里的画面读取出来的。)
唯一的坑是优酷上的视频往往并不只是对战过程本身,还会有一些制作者加入的视频特效、文字、转场动画啥的。一开始没留意,污染了一小批训练素材,后来重新找了几个干净的视频解决此问题。
于是就这样,轻松获得了含有英雄标记信息的近 10 万张图片。
后面的事情就简单了,用 OpenCV 统一对图片进行裁剪。一开始是裁到三个技能的区域,但因为这个区域覆盖的面积较大,会包含进来很多不必要的图像信息,导致训练出来的结果不理想。在后期调优时,想到每个英雄的技能其实是唯一的,没必要识别全部,于是将素材全都裁剪到第二个技能,果然大大提升了识别准确度。
技术实施
早有耳闻 Google 家 TensorFlow 上手容易且性能还不错,加上是 G 家产品,自然和 Python 配合度最好,适合常年写 Python 的我。于是果断开始读 TensorFlow 的文档。
不得不说周末那个晚上有很多时间花在了如何在 virtualenv 里安装 TensorFlow 和 OpenCV。网上的教程没有一个是可以完全顺利在 Mac 上跑完的,还好最后在 Google 和 Stack Overflow 的双重加持下,这俩个组件都在我 Mac 上编译成功了。
很快,在 TensorFlow 官方教程里找到一篇关于图片识别的文章。跑了一下 demo,运行正常。于是开始研究如何训练自己的模型。
既然都按照官方教程走了,所以直接用了 Inception V3 的网络结构。近 10 万张图片,在没有 GPU 加持的 Macbook Pro 上,差不多得跑 10 个小时才能跑完第一次训练。
不过其中最耗时是计算 Bottleneck 值,因为这个值在每次训练时其实都不会变。所以教程中会让在第一次计算每张图片的 Bottleneck 值后,将之保存下来,这样下次训练只需要计算新增图片素材的 Bottleneck 值即可,不需要每次都全量计算。这样优化之后,效率飞升。
到此时,已经是周日凌晨 3 点了,赶紧让模型跑起来,睡觉去。
性能调优
周日中午醒来,第一次训练已经跑完了,赶紧拿新模型去做各种测试,准确率超乎想象的高。但如「收集素材」那一段里提到,一开始是识别三个技能,所以在某些英雄的识别上不太理想。
将所有素材调整为单个技能截图后,又跑了一次,出结果时已经是周日晚上。这个时候的准确率靠我找到的测试图片已经没有失败的例子了。
截止这个时候,识别单张图片大概需要 5 秒,倒也不是不能接受,但还想更快。在没有 Nvidia 显卡的情况下,只能依赖于在本地编译 TensorFlow,从而让 TensorFlow 能用上本地 CPU 的 SSE、AVX 这类指令,加快运算速度。如何在 Mac 上编译 TensorFlow,可以参考这里。
附加功能
在本地已经能完美识别英雄了,但总想着让更多的同事能体验这个功能。周二晚回家想起了之前用 itchat 写的微信机器人,于是立马将机器人和王者识别代码结合起来,实现了在微信里给机器人发游戏图片,机器人立即回复这个图片里的英雄是谁。
结语
实际的学习和开发时间就是周六晚 8 点到凌晨 3 点。这 8 个小时让我从原理及代码层面认识到了机器学习的魅力和实施细节,真真切切的看到了另一个世界的入口以及未来无穷的可能性。
最大的触动是开始思考未来产品经理在设计产品逻辑时,如果理解机器学习,那么很多以往被认为不可能的事情,都将成为产品逻辑的一部分。而能否建立这种新的认知,运用好新的工具,将在未来某些领域里区分出产品经理的高下。
学习,是一个 PM 永远不该停下的生存技巧。
作者:张涛
来源:https://zhuanlan.zhihu.com/p/28731349
本文由 @张涛 授权发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自PEXELS,基于CC0协议









基础太好了,想到就干,很强大
完蛋了我。我都看不懂了