
 起点课堂会员权益
起点课堂会员权益4个方面,聊聊如何做一次更高效的可用性测试

前段时间做过了一次比较系统的可用性测试。因此写了这篇文章作为个人对可用性测试的梳理和反思。
可用性测试是一个体量很大的学科,仅仅从形式和平台两个维度去分,就可以细分出十几种不同的可用性测试,而每种不同的测试其研究方法还有相当大的不同。
而且我相信,即使是同样的一个目标,由不同的角色去设计和执行(比如咨询公司的用研人员,某些公司专门的用研部门,或者业务线上的产品经理)也会有不同的方法和侧重点,因此本文数千字的篇幅是不可能涵盖可用性测试的方方面面的,甚至连作为某一种特定的可用性测试的工具书都不够详尽。
这里只是我作为一个业务部门里的交互设计师,就我们采用的实验室的可用性分析(usability lab studies)来谈一谈进行可用性测试的一些技巧和需要注意的点——总的来说,站在测试的大目标下,我们的每一个决定和方法都需要紧贴在目标上,每一个步骤都需要有合理的前因后果和清晰地逻辑。
本文分为“可用性测试的时机”,“可用性测试的目标”,“以目标为导向的方案设计”和“测试的过程”四个部分。
可用性测试的时机
广义的可用性分析是指让用户使用真实材料(包括真实的产品,模块,页面,原型,概念等)来探索其可用性的研究。包括了概念测试(concept testing),实验室的可用性分析(usability lab studies),远程的有指引可用性测试(moderated remote usability studies),快速迭代的测试和评估(rapid iterative testing and evaluation),眼动分析(eyetracking)等。
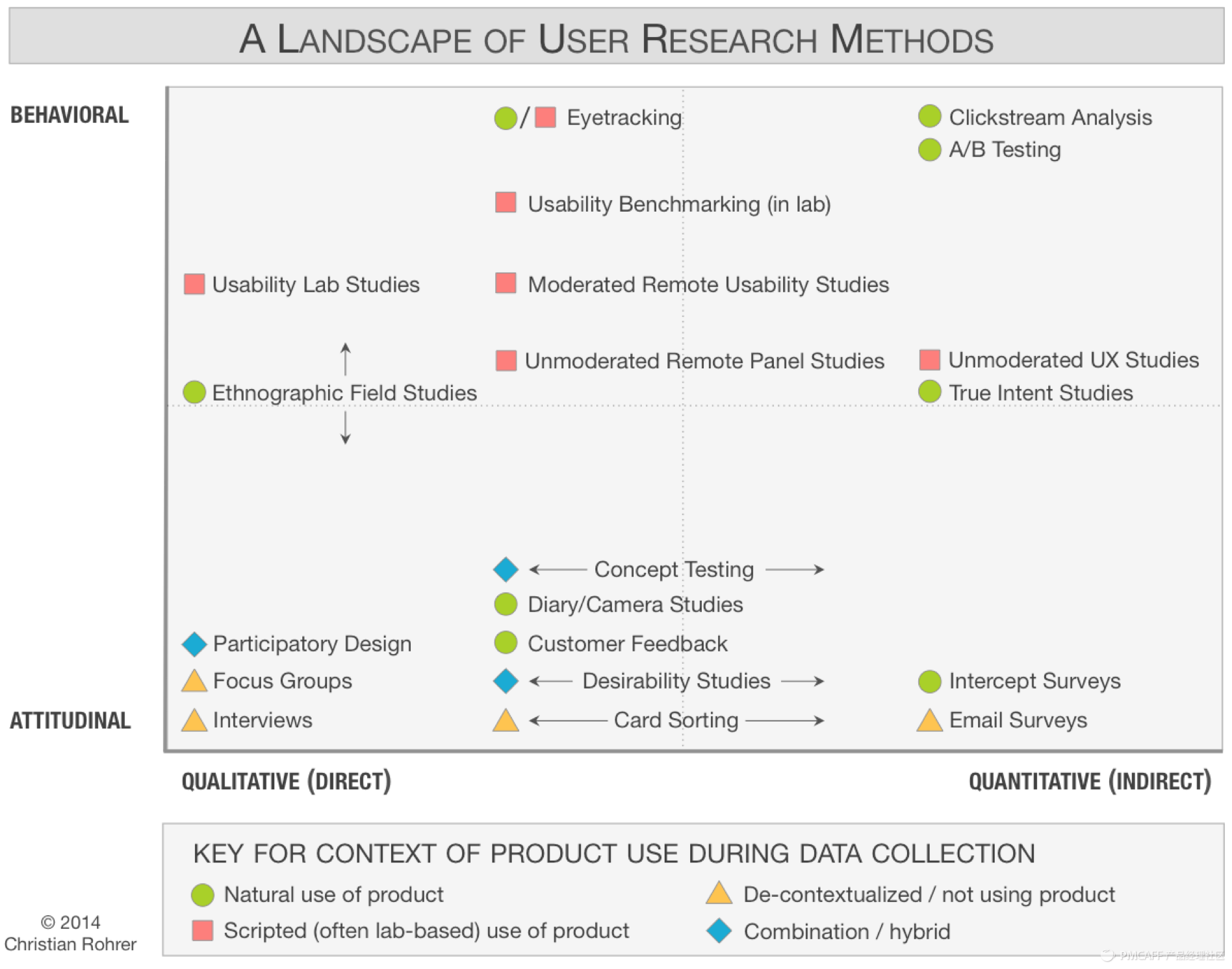
我们将这些可用性测试的方法放到用户研究方法的“定性—定量/态度-行为”坐标系中,我们发现各种可用性测试方法涵盖了定性到定量的整个坐标轴,而在纵坐标轴上,可以看到可用性测试是偏向行为的。
因此,不论是要对系统的可用性得到一个概括性的结论,还是要针对一个模块的可用性进行精确的数据分析,我们都可以通过不同的测试方法来完成。然而不论是哪一种方法,可用性测试的核心都是建立在观察上的。
那么,我们应该在什么时候去发起一次可用性测试?NNG的联合创始人Jacob Nielsen列出了以下三个场景:
- 在迭代的过程中,特别是两个迭代之间的时候。我们需要知道我们本期的设计是否解决了之前的问题,或者我们还需要继续改进我们的设计方案。
- 数据不会骗人——对于竞品的可用性分析,可用性测试得到的指标是非常有用的。
- 在每一次新的发布之前,我们需要在脑海中有一个清晰的目标。当我们对现在的设计方案没有很大的把握的时候,一次可用性测试可以告诉我们,新的版本是不是已经准备好发布了。
总的来说,可用性测试最好是发生在整个设计周期里的研究阶段(在连续迭代的过程中,研究可以被看作是一个设计周期的第一环,也可以是发布后的最后一环)在我们拥有一个真正的产品之前,我们需要知道一个方案是否可行,此时需要注意的是,我们需要平衡可用性测试材料的保真度。
我们可以用一个尽量轻量级的原型来进行,这样就可以尽快的对设计方案进行迭代;当然,它也要有足够的细节来让用户明白我们到底做了一个什么东西,并且能够被带入到我们预设的场景里。再就是在我们发布产品之后对于设计的评估和梳理,这个时候的可用性测试相当于一次低配版的田野观察。
可用性测试的目标
这一部分我分两点来说,第一是什么是可用性以及我们是怎么用可用性测试来衡量它的,第二是可用性测试是用来做什么。
usability.gov为可用性给出的定义是“用户与一个系统交互时体验的质量”,而构成可用性的三个因素包括效度,效率和主观满意度。一般来说,我们通过以下的几个维度来衡量系统的可用性:
- 设计的直观性:产品的整体架构符合用户的心智模型,换句话说,用户可以轻松直观的了解产品的结构,并利用导航系统在界面间清晰的移动
- 清晰性:界面元素表意清晰,交互方式和结果符合用户的预期
- 可寻性:用户可以快速准确的找到界面的关键信息
- 易学性:一个新用户可以轻松的完成一个任务
- 使用的高效性:一个老用户可以用系统高效的解决问题
- 可记忆性:在第一次访问这个系统后,用户可以记住足够的内容来帮助他在以后使用的时候可以高效的使用
- 发生错误的频率和严重性:用户在使用系统时发生错误的频率,这些错误的严重性,以及用户能否修正这些错误
- 主观满意度:用户在使用时的总体体验,以及他们有多喜爱这个系统
……
那么问题来了:我们是怎么来衡量这些可用性指标的呢?我反思了我们之前做过的可用性测试,在所有的这些测试里,我们招募的都是从未使用过系统的目标用户。
这样做的好处在于:上述的1-4点可以得到优质的结果。这样的做法更适用于对设计概念和新功能的验证,但是我们经常忽略的是——其实也是更难做的是——对旧功能的可用性测试。因为在平时的设计过程中,我意识到有的功能,即使是可用性很差,但是用户在一段时间的使用后也可以正确的完成任务。或者是说,有的功能是为多次使用而设计的,这些功能模块可能相当复杂或者有很长的操作路径,特别是一些B端的产品,页面的信息密度还相当的大,此时采用新用户来进行可用性测试,不一定会得到准确的结论。
然而对于已有功能的可用性测试是必须而且重要的。
举例来说,我们有一个对对象进行批量操作的模块,用户需要对相似的对象进行多次的重复操作,此时的可用性就和上述的1-4点没有多大关系了,而需要度量的是系统的效率和容错性。此时就需要对可用性测试的思路进行一定的调整了,比如说,我们可以为我们的设计设定一个指标,来观察我们的设计能否达到这个指标。
比如:我们的目标是一个熟练的用户可以在1分钟内处理10个对象;在没有办法制定指标的时候,我们可以引入两个方案的对比,从而选取更好的一个。
当然,我们还需要随时保持这样一个意识,就是在具体的场景下,可用性测试是否是最好的方式,还是刚才那个例子,如果我们确定上面的1-4点都没有问题,并且埋点数据的分析就可以回答现有的设计下用户每分钟处理对象的数量,那么就没有必要去进行一场可用性测试了。
所以最后就是关于可用性测试的使用场景,可用性测试主要有以下两个作用:
- 衡量产品的可用性
- 定位产品问题及产生的原因。总的来说,可用性测试用于优化产品,但是不能告诉我们应该去做什么需求,或者是用户想要什么。
比如说,我正在设计一个帮助用户进行锻炼的应用,系统里有一张汇总用户每日跑步详情的月汇总表,可用性测试不会告诉我们用户为什么会去关心这张表,或者这张表会为系统带来怎样的价值——你需要通过一本叫做Hooked的书或者一些深度访谈来回答这些问题。
请注意下面这个例子:可用性测试不回答用户会去关心这张表里的哪些字段,只有在我们预设某一个字段是重要的的时候,我们可以通过可用性测试来验证我们的设计是否能让用户直观的接受这个字段信息。我们用数据埋点,点击分析和问卷来了解产品里发生了什么,用深度访谈来了解用户的动机,态度,想法和体验。而可用性测试的意义在于告诉我们一个问题为什么发生。
因此,我们不会去询问用户对这个产品的看法,而是将产品交给用户,给他们布置一个任务,去观察他们是如何与系统交互的,再通过这样一些行为数据去了解系统中存在哪一些问题。比如说,我们通过埋点数据发现在一个复杂的注册流程中的用户资料上传页面存在巨大的跳出率,我们就需要可用性测试来告诉我们为什么会有这样的跳出发生,以及如何修正这个问题。
以目标为导向的方案设计
以目标为导向其实是我一直非常认可的一种设计思想,这种思想同样也体现在了我的用户研究上。这里也分为两个方面:
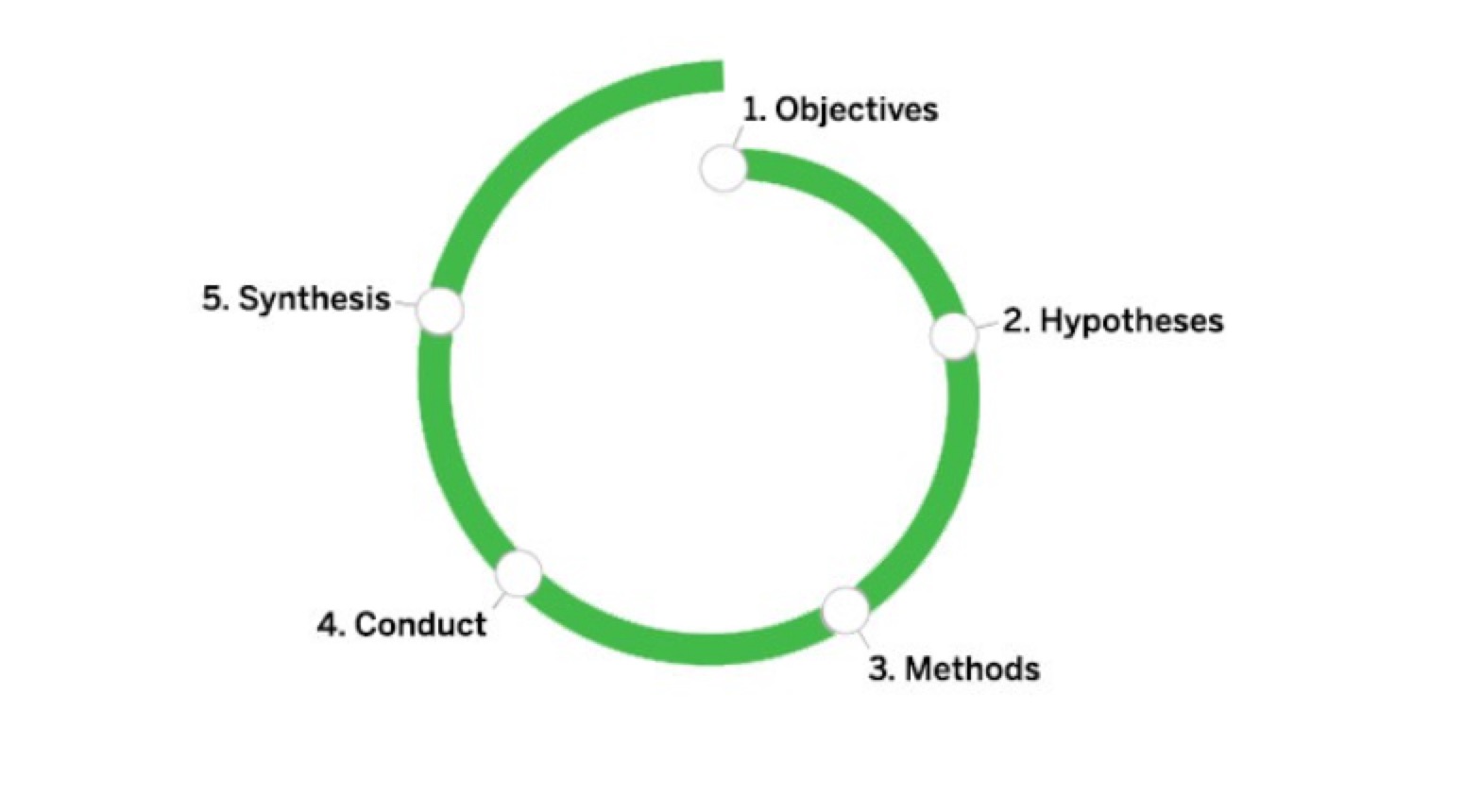
- 一是和其他所有的用户研究方法一样,我们采用研究学习螺旋模型来规划我们的可用性测试。这种模式的核心在于,研究的每一步都是建立在目标之上的;
- 二是,我们方案里的每个行为都必须是有目的的——在我刚开始做用户研究的时候,常犯的一个错误就是全套照搬别人的流程,然而在研究结束后的反思里才意识到,每一个行为都应该是有意义的,根据实际情况的不同,我们也需要对标准的流程进行修改或者补充。
设计了一个好的研究方案,就成功了一大半了。如上文所说,可用性测试的最大目的就是:
- 研究用户是否能顺利的通过系统达成目的
- 定位问题。第一点比较简单,第二点稍微复杂一些。
先讲第一点:在我们开始思考任何的方法和拟定任何的方案之前,我们需要先把本次测试的目标定清楚,在制定研究目标的时候,我建议根据上文列出的8个维度来思考(当然你也可以列出更多的维度)。
比如,如果需要测试一个网站导航系统的可用性,那么我更倾向于去关注系统的“设计的直观性”,如果我需要测试一个新用户是否能顺利的预订酒店,那么我需要关注的可能就是系统的“清晰性”,“可寻性”和“易学性”。
我们需要一个清晰的框架来帮助我们梳理我们的研究目的,这样才能保证我们可以找到一个研究对象最关键的点,并且在后续的步骤中不会遗漏掉可能出现的问题。在这里我们也可以看到,目标其实是和大小无关的:测试一整个预订流程是否流畅是一个合理的目标,测试一个按钮组的呈现方式是否足够直观也是一个合理的目标。
第二点就是定位问题,为了精准的定位到问题出现的原因,我的做法是将观察的粒度拆得尽量细。而这样的细分其实是分为两个部分的:
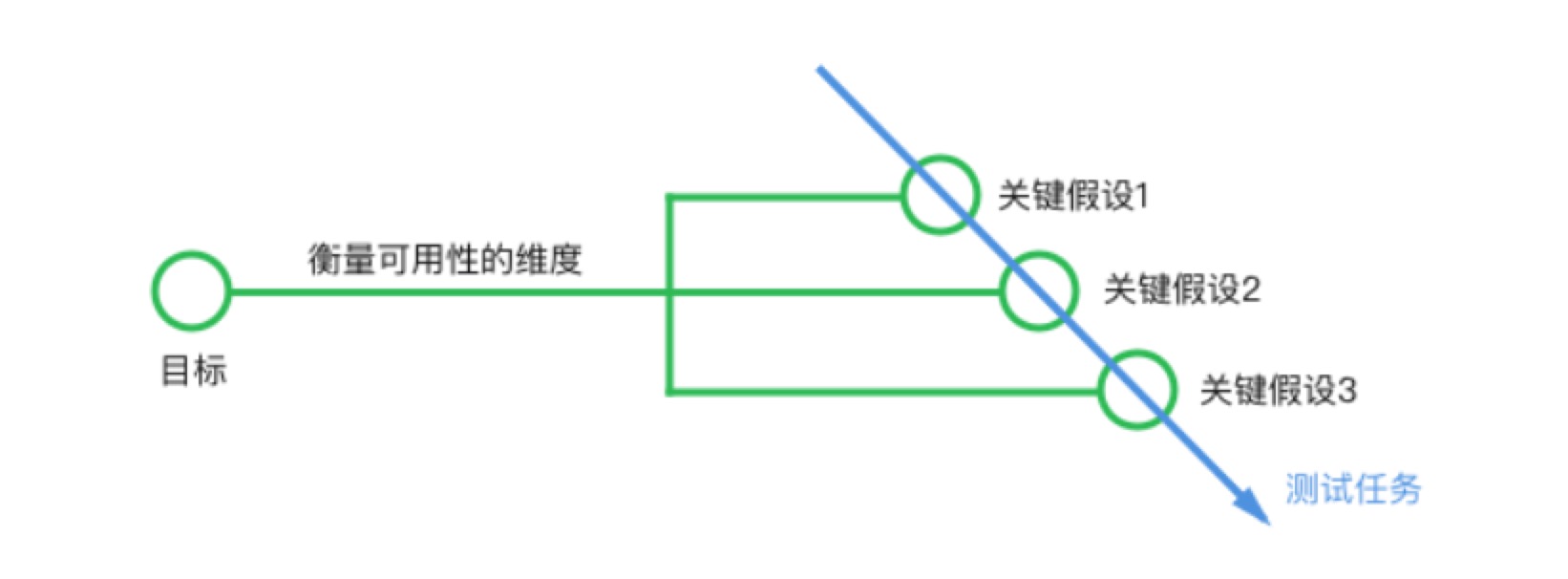
- 通过关键假设将目标拆分为可以度量的条目
- 在完成了任务的设计后,需要在任务流程里设置详细的观察点。
先说关键假设,其实假设是我们在做用户研究的时候很容易忽略的一个步骤。这个步骤的含义是,我们在提出了目标之后,需要理清关于目标,我们(认为自己)已经知道的事情,我们预期用户的行为是什么,我们认为哪些地方会出现问题,以及我们可能会怎么去解决这些问题。
Frog的一个设计研究负责人Jon Freach提出,在研究的早期,假设可以帮助我们感知和思考我们需要去解决的问题,更好的选择研究方案。
具体到我们的可用性测试来说,除了上述的作用,关键假设还可以为我们带来这样的价值:我们在第一步提出的目标其实是不能直接和具体的方法联系起来的,这个时候,关键假设可以帮助我们将目标拆分为更容易被翻译成具体任务的条目。
比如:我的目标是“测试用户是否在酒店列表里能找到合适的酒店”,我的关注点是页面信息的“清晰性”,“可寻性”,那么我的关键假设可能就是:
- 用户可以清晰的理解每条记录里具体信息的意义
- 我们提供的按价格,评分,星级的排序机制可以满足用户需求的
- 用户在寻找左侧边栏的筛选控件时会遇到困难。那么根据这样一些假设,我们只要设计出可以全部覆盖它们的任务流程,就可以很顺利的达成目标了。
至此,我们已经走在了正确的道路上,我们的任务可以覆盖我们目标可能存在的所有问题。现在再来回想一下我们在一场可用性测试里的目的:精准的定位问题,以及挖掘问题发生的原因。
那么,我们还需要一些方法来将测试的过程更加的精细化。在这里我采用了设置观察点的方法,这种方法的机制是:尽量将页面上可能的触点罗列出来,而所有的触点分为和任务主流程有关的触点(A)和无关的触点(B)。
在用户完成任务时,我们需要观察所有的触点,此时对A类触点的观察可以覆盖到所有和测试目标有关的用户行为,而对B类触点的观察可以覆盖到系统里一些其他的可用性问题。
在用户完成任务后的复盘过程中,我们需要就关键的,以及刚才出现问题的触点与用户进行访谈,以便确认问题发生的原因。这个方法的意义在于,在访谈的过程中,观察者可以带着目的和清晰地条例去观察用户行为,在之后的复盘中,可以更加系统的去还原用户的行为,特别是那些通过直接观察没有办法得出结论的点。
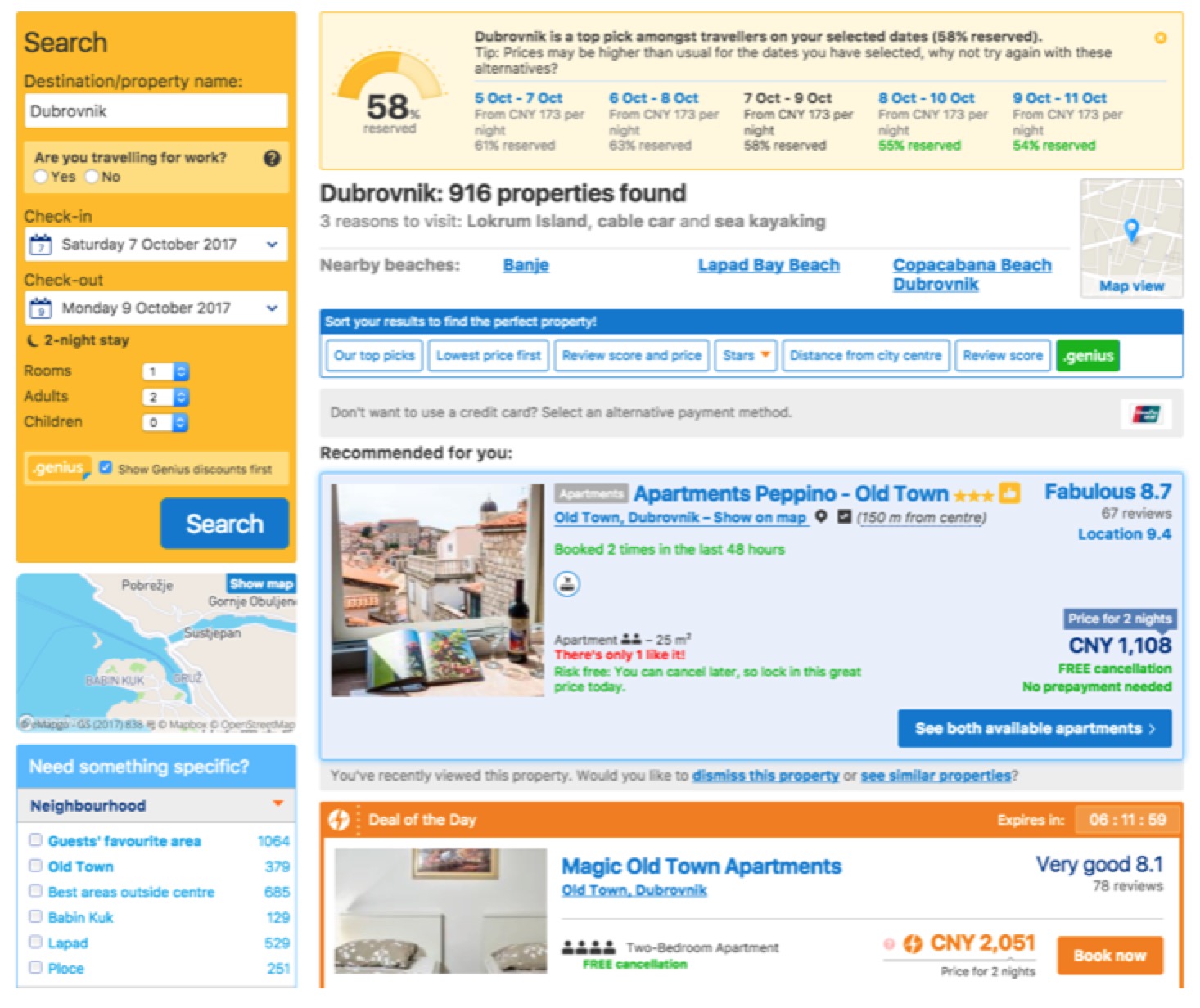
打个比方:如下图所示:还是预订酒店的例子。
我们的目标是测试酒店搜索结果页对于一个新用户的的可用性,用户任务是在该页面找到一家价格适中,位置靠近老城,评价优异,可供全家4人住宿的房间。
在酒店信息页,可能的A类观察点就包括了展示酒店信息的所有卡片;卡片内的所有字段,链接,标签,图标,按钮;筛选控件;排序控件;地图入口;切换浏览方式的控件等。可能的B类观察点就包括了重新搜索的控件,该目的地其他日期的预定情况等。
在一场真实的可用性测试中,我们需要知道完成任务的所有路径,以及最高效的那些路径,而用户很有可能会采用一些更低效的路径,我们需要去观察用户是如何做出这样的选择的,并且在测试完成之后的复盘中,我们需要去向用户了解是如何去认知其他的路径的。
比如在这个例子中,如果用户想要高效的找到合适的住宿,他可能需要采用地图视图,价格筛选器,以及按照用户评分对列表进行排序。而在实际的操作中,用户有可能不会用到这些组件,他们甚至可能会不对列表进行任何操作就直接在列表中逐项浏览。那么在测试的过程中,我们就需要去留意用户是怎样选择并使用了一个组件,在过程中是否有误操作,犹豫等。
在测试完成后,需要去询问用户“请问你注意到列表上方的排序控件了吗?”,“我注意到你刚才想要去点击地图,但是最后放弃了,这是为什么呢?”,“你有没有想过需要将可以住4人的酒店筛选出来呢?你觉得你应该怎样去操作才能完成筛选呢?”等。
在完成了目标,关键假设和观察点的梳理后,我们就可以开始拿着我们的测试计划开始准备材料,数据,脚本以及用户招募了。但是在走进房间开始和用户进行近距离接触之前,我通常会建议团队再做以下这件事情:对可用性测试的计划本身进行一次测试。一是为了保证测试过程的流畅,二是为了再次检查我们的测试方案是否已经足够细致和全面了。
在这样一个非正式的测试里,我们通常会邀请一个同事(被试者对系统的熟悉程度需要根据测试目的来定),并严格按照正式测试的环境和流程进行。
在这个流程中,我们可以看到准备的材料和数据是否合理,能否覆盖我们的测试目的;对于那些设计多平台多设备多端口的任务,我们需要去保证数据和流程的流转可以正常的进行。在这样的测试里,得到的关于可用性的结论是没有太大参考意义的,但是我们可以通过走完一个完整的流程对之前列出的观察点进行查漏补缺。
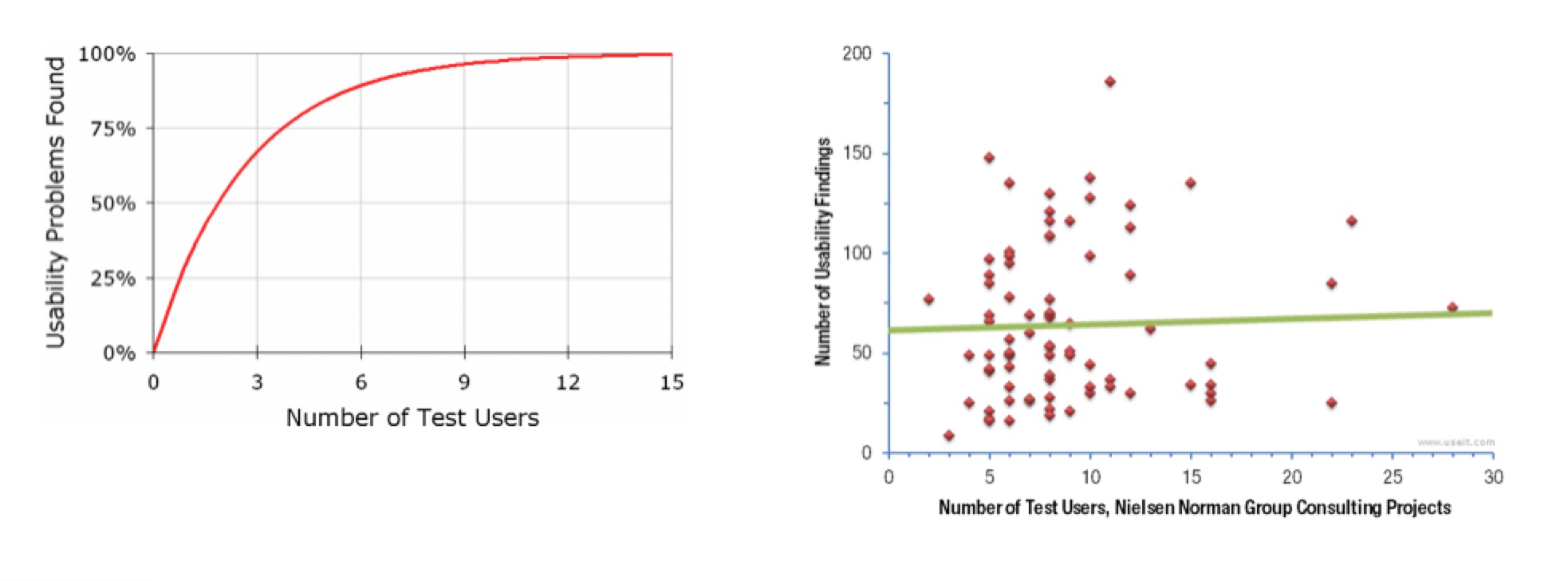
最后就是招募用户的数量。根据Nielsen和Landauer的研究,可用性测试发现系统中问题数量与测试人数遵循以下公式:
P=N (1-(1- L ) n )
其中P为发现问题的数量,N是系统中存在问题的总量,L是通过研究单个用户可以发现的用户比例,根据经验L的值一般被定义为31%。
此时我们可以绘制出P关于n的曲线,如下左图所示。
此外,Nielsen还给出了以下的一份数据:根据83例NNgroup最近进行过的可用性咨询的案例分析可以得出下右图的可用性问题数量——招募用户数量的关系。我们可以看到,在招募5-8名用户的时候,就足以暴露出系统中的大部分可用性问题了。而此时再测试更多的用户,并不会为我们的洞察带来明显的提升。
因此在我们的可用性测试中,我通常会遵循以下的原则——这也是其他定性用户研究用户招募的一个通用原则——至少对5名用户进行测试,当测试完第五名用户的时候,如果我们发现问题的分布足够集中,或者是不再出现新的问题,那么针对这个目标的可用性测试就可以结束了。如果此时还在暴露出新的问题,那么我们就还需要继续进行测试,直到不再暴露明显的新问题为止。
测试的过程
关于测试的过程我就不在这里详细描写一次可用性测试所有的步骤了,下面列出几个我认为可以最大程度上提升研究质量的点。
不要试图去消灭测试的“人为因素”
一次典型的实验室环境的可用性测试包括了一把椅子,一张桌子,用户坐在屏幕前完成任务,由录像机和各种传感器来追踪所有发生的事情——包括眼动,面部表情,身体语言等等。这样做的目标就是试图消灭掉试验中的一切实验因素。甚至有一些用研人员建议“不要和用户说话”。
虽然我完全同意倾听多于说话的观点,但是——即使我完全保持沉默,甚至是躲在另外一个房间,用户总是会知道他们是正在被观察着的,我不用做任何事情,我的身份就是一个观察者,这个时候适得其反的事情就发生了。
- 用户会把我视作一个标杆或者权威,他们会用他们的答案和行为来取悦我
- 因为他们惧怕在我眼中显得愚蠢,因此他们会惧怕犯错
- 他们的行为模式会和自然状态下截然不同,他们会使用一些前所未有的方式去和我们的产品交互
我们需要意识到的是,可用性测试对于用户来说本来就是一件不自然的事情——包括马上我要说的Think Out Loud——就像洗澡的时候突然有人拉开浴帘问我水温如何一样。因此,我认为消灭测试的“人为因素”是一件徒劳的事情,相反,我们应该向前一步,去接受实验环境和现实不同的这个事实。
去扮演一个友好的角色,我习惯于在正式的测试开始之前和用户有一个简短的寒暄,讲两个适当的段子,一些和用户贴近的小问题,注意自己的语气和身体语言——事实上,这样的开场适合于所有的定性研究。
总之,创造一个轻松的氛围,让自己看上去亲和友好,向用户传达我们是多么高兴他可以帮助我们发现系统的问题。当用户愿意走出他的舒适区时,我们就可以得到更多有价值的信息了。
Think Out Loud&测试后的复盘
测试的目的之一是挖掘出更多的信息,而用户的操作只能展示出测试时所发生的事情的很小一部分,除了仔细的观察之外,我们会要求用户在使用时将自己的思考/决策过程说出来,包括
- 当进入这个页面的时候,我首先注意到了哪些东西?
- 我认为这个页面是做什么用的
- 我下一步想做什么?我觉得页面上哪些元素可以帮助我?
- 当我完成某一操作后,我预期会有怎样的反馈?那真实的反馈是怎样的?
- 界面上有哪些元素是我不明白的?
- 我进行了误操作,我应该怎么消除这个错误?
- ……
这样,我们就可以保证我们设置的观察点得到了充分的覆盖,并且可以帮助我们对界面以及产品结构进行更全面的洞察。当然,Think Out Loud是建立在第一条的基础上的,只有当用户在一个足够放松和信任的状态下,他才会保持一个说话的状态。
在用户完成任务之后,我们已经收集到了足够多的信息,但是如何保证信息的精确性呢?我使用的方法是进行一次复盘。我们需要回顾用户刚才的路径和所有操作,去确认每一个决定的原因,以及用户没有说出来的东西,比如:
- 你为什么要点击多次撤销,而不去点击清空按钮呢?
- 我注意到你将鼠标移到了A按钮上,但是最后又没有点击呢?
- 我注意到你在进行B操作的时候显得有些焦躁,这是为什么呢?
- ……
保证信息的完整和精确,我们就可以告诉用户说今天你的测试已近完成了。
对测试方案的迭代
如果我说“我需要在研究的过程中修改我的研究方案”,很多研究者心中的第一反应多半是WTF?我理解很多人将中途修改方案视为洪水猛兽,因为这和“得到一个客观的结论”的目的似乎是相悖的。他们说你需要5名用户去做一模一样的任务,这样才能得到一个有意义的结论。
我当然同意要想办法得到更客观的答案,但是这并不意味着我们的研究方案就自始至终一成不变的了。我们应该在保证目标和关键假设不变的前提下,在每一次测试之后,对我们的观察点以及复盘时的问题进行迭代——这个习惯同样适用于其他的定性用户研究方法——因为我们的观察点和问题的拟定都建立在我们对系统了解的基础上,但是有的时候,用户和我们设计的体验是两回事情,曾经有同事反馈说,自己设置的观察点很多都没有用上,而用户的很多行为完全出乎了他的意料。
打个比方,如果前两个用户在任务的最开始都统统选择了一条我们预料之外的路径,而我们都没有在这条路径上设置任何的观察点与问题。那么,如果我们不在后续的研究上加上“你为什么会点击这个入口”这样的问题,那么我们永远也不会知道用户这样奇怪举动背后的原因。
参考文献
- Usability Engineering, 1993, Jakob Nielsen
- Qualitative Research Design, 1996, Maxwell, https://www.sagepub.com/sites/default/files/upm-binaries/5057_Maxwell_Chapter_5.pdf
- UX Research Cheat Sheet, 2017, Susan Farrell, https://www.nngroup.com/articles/ux-research-cheat-sheet/
- How Many Test Users in a Usability Study, 2012, Jakob Nielsen, https://www.nngroup.com/articles/how-many-test-users/
- Why You Only Need to Test with 5 Users, 2000, Jakob Nielsen, https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users/
- How Do I Do User Research, 2014, Katerena Kuksenok, https://medium.com/hci-design-at-uw/how-i-do-user-research-fabc89acc7c9
- Don’t Listen to Users and 4 Other Myths About Usability Testing, 2016, Icon8, https://uxplanet.org/dont-listen-to-users-and-4-other-myths-about-usability-testing-a061a0b746b8
- UX Design Process Best Practices, UXPin, https://www.uxpin.com/studio/ebooks/ux-design-process-documentation-best-practices/
- The Guide to Usability Testing, UXPin, https://www.uxpin.com/studio/ebooks/guide-to-usability-testing/
- A 5-Step Process For Conducting User Research, David Sherwin, 2013, https://www.smashingmagazine.com/2013/09/5-step-process-conducting-user-research/
本文由 @J.Yang 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自unsplash,基于CC0协议






- 目前还没评论,等你发挥!


