
 起点课堂会员权益
起点课堂会员权益互联网大数据发展下的信用体系建设现状(另附线性回归模型建模方法)

通过本文,一起来了解下大数据发展下的信用体系建设现状。
一、背景及现状
2015年1月5日,央行印发《关于做好个人征信业务准备工作的通知》,要求芝麻信用管理有限公司、腾讯征信有限公司、拉卡拉信用管理有限公司等8家机构做好个人征信业务的准备工作。
2017年4月21日,央行征信局局长万存知在个人信息保护与征信管理国际研讨会上透露,:综合判断,8家进行个人征信开业准备的机构目前没有一家合格,在达不到监管标准情况下不能把牌照发出去。
对于这8家机构存在的问题,每一家机构都想追求依托互联网形成自己业务的闭环,但每一家信息覆盖范围都有限,信息不广、不全面,导致产品有效性不足,不利于信息共享。
2017年12月4日讯,中国互联网金融协会第一届常务理事会2017年第四次会议,审议并通过了协会参与发起设立个人征信机构(简称“信联”)的事项。“信联”由互金协会与8家个人征信业务机构共同发起成立。“信联”将纳入央行征信中心未能覆盖到的个人客户金融信用数据,构建一个国家级的基础数据库,实现行业的信息共享,以有效降低风险成本。
二、国外信用评分FICO Score
FICO评分系统采集客户的人口统计学信息、历史贷款还款信息、历史金融交易信息、人民银行征信信息等解释变量。违约率即为被解释变量。通过逻辑回归模型计算客户的还款能力,预测客户在未来一段时间的违约概率。经由违约率对应的信用分数,最终输出最终分数并确定不同自变量对违约率的影响程度。
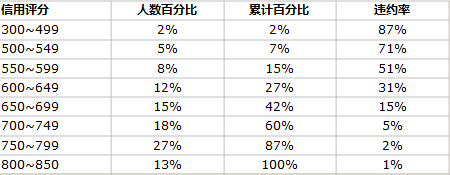
- 违约历史(Payment history),权重 35%
- 债务负担(Debt Burden),权重 30%。
- 信用历史(Length of credit history),权重 15%
- 信用种类(Types of credit used),权重10%。
- 新申请信用(Recent searches for credit),权重10%。

三、国内个人征信业发展情况
中国首批8家个人征信公司
芝麻信用管理有限公司:
蚂蚁金服旗下,阿里体系;芝麻信用分”于2015年1月28日正式上线;
腾讯征信有限公司:
腾讯旗下;”腾讯信用分“于2017年8月8日上线,目前信用分产品公测中;
北京华道征信有限公司:
银之杰、北京创恒鼎盛、清控三联、新奥资本分别持有北京华道征信40%、30%、15%、15%的股权。清华控股集团持有清控三联100%的股权;
中诚信征信有限公司:
隶属于中国诚信信用管理集团(该集团成立于1992年,前身是经中国人民银行总行批准设立的中国诚信证券评估有限公司)
深圳前海征信中心股份有限公司:
平安旗下全资子公司
中智诚征信有限公司:
董事长是盛希泰,全国青联常委并金融界别秘书长,中央国家机关青联副主席。曾任华泰联合证券有限责任公司董事长;
鹏元征信有限公司:
是中国最早成立的商业征信机构之一,其最早建设的“深圳市个人信用征信系统”从2002年8月开始运行,目前所能提供的个人和企业征信服务已经覆盖全国;
拉卡拉信用管理有限公司:
联想系;
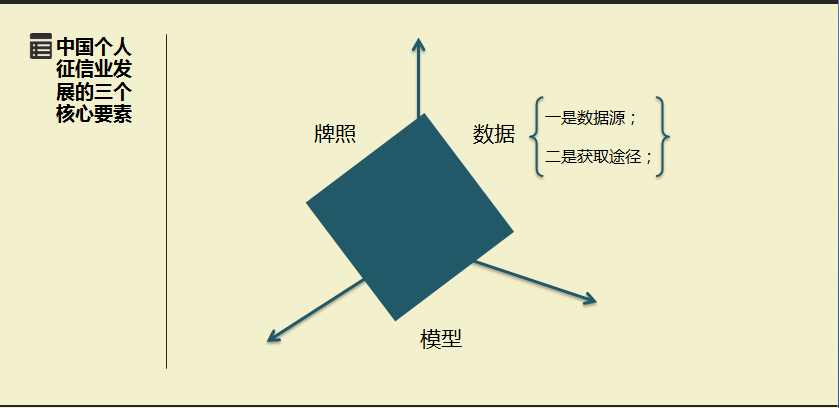
中国个人征信业发展的三个核心要素
芝麻信用—数据来源
- 基本信息:学历,单位邮箱,职业信息,驾驶证
- 资产情况:车辆信息,房产信息,公积金、支付宝账户余额
- 信用消费:信用卡账单、微贷还款记录、水电煤缴费、罚单
- 消费数据:账户活跃度、消费层次、缴费层次、消费偏好
- 信用足迹:花呗履约,蚂蚁借呗履约,未来酒店履约
负面记录:
- 其他授权管理
- 人行征信报告:杭州数立信息技术有限公司提供
- 城市信用报告:杭州市公共信用信息平台:五险一金,信用记录,
- 淘宝消费行为及银行征信系统;
……
芝麻信用—主要评级要素及模型原理

四、当前P2P小额贷款APP风控模式
- 有数据基础及能力的:自行构建自家产品的征信系统用于风控;
- 无数据基础及能力的:接入有能力的平台,(芝麻信用等8家,或同盾等其他反欺诈大数据公司);
- 接入央行征信系统;
- 接入商业银行小额贷款规则+自家数据及黑白名单;
五、引申:风控(信用分数)模型建立方法
数据收集:假设收集10万条数据,每个数据包括5*10(5个大类,每类10个指标)个属性(样本空间即属性空间为50),标记信息为:要预测的变量。(违约率,还款能力)
数据清洗及处理:清除非规范值,缺失值,异常值等。
机器建模学习过程:将数据随机抽取分成训练集及测试集,其中用以学习模型的训练集占85%(8万5000条),用于验证模型的占15%(1万5000条)。
逻辑回归建模:采用逻辑回归进行建模,采用 BIC 的方法选择模型,通过模型得到每个变量对是否违约的影响系数。同时归纳出违约用户及非违约用户的特征。
衡量模型的预测效果:采用指标 ROC(Receiver Operating Characteristic)曲线或者 AUC(Area Under Curve)值等数据模型效验逻辑回归模型结果。
得出信用分:通过线性变换可以将预测概率 P 转化为 350 至 900 的用户得分 Q,Q=X+Y×P。输入一个新用户的50个数据指标,从而得出对应的预测概率P,从而得出信用分Q
不断训练及优化模型:用户不断的更新新的数据指标,每个指标下不断积累新的数据量,同时不断的新的用户进来。通过新的数据训练优化逻辑回归模型。
参考资料:https://cosx.org/2016/05/credit-scoring-model-in-internet-credit-reporting
FICO Score体系详解:https://www.cnblogs.com/nxld/p/6364341.html
作者:阿发 ,3年互联网用户运营/会员运营经验
本文由 @阿发 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自unsplash,基于CC0协议









看到标题进来的,果然是标题党。前面的现状暂且不论,后面的建模的论述太简单。1、说的是线性回归,文章里面,连LR都没描述;2、数据收集,收据来源,数据的定义是什么;3、数据清洗和处理,除了你简单说的,还有数据尺度的调整,比如正太化数据,标准化数据等;4、建模学习过程,不是LinearRegresion,怎么又成了LogisticRgegrsion了,并且分离训练数据集和评估数据集的方式有很多,即便采用你的分离训练数据的方法,训练数据集和评估数据集的比例也存在问题,建议0.67:0.33的比例;5、衡量模型的预测效果,这个描述问题就更大了,ROC和AUC是评价分类器的指标,分类器的指标… 最近一直在学习相关的东西,不小心多说了一些..
标题太大,内容太简单