
 起点课堂会员权益
起点课堂会员权益NLP基本功-文本相似度 | AI产品经理需要了解的AI技术通识

本文侧重讲述逻辑和使用场景,尝试将算法通俗化,尽量多举例,降低理解门槛。希望读完本文,大家可以对文本相似度有一个完整而深刻的理解,最好能在非代码维度上超过开发人员(达到了这种水平,输出的需求自然会得到开发同学最大的尊重和认同)。
1. 背景介绍
因为之前做过个性化推荐相关的项目,最近产品的其中一个模块也需要用到文本相似度,趁此机会做一个全面的整理。
CSDN及各类技术博客上有很多文本相似度方面的文章,但它们的侧重点是代码,目标受众是开发人员,代码基础薄弱的话看起来会比较吃力。
本文侧重讲述逻辑和使用场景,尝试将算法通俗化,尽量多举例,降低理解门槛。希望读完本文,大家可以对文本相似度有一个完整而深刻的理解,最好能在非代码维度上超过开发人员(达到了这种水平,输出的需求自然会得到开发同学最大的尊重和认同)。
文本相似度,顾名思义是指两个文本(文章)之间的相似度,在搜索引擎、推荐系统、论文鉴定、机器翻译、自动应答、命名实体识别、拼写纠错等领域有广泛的应用。
总的来说,文本相似度是自然语言处理(NLP)中必不可少的重要环节,几乎所有NLP的领域都会涉及到!
与之相对应的,还有一个概念——文本距离——指的是两个文本之间的距离。文本距离和文本相似度是负相关的——距离小,“离得近”,相似度高;距离大,“离得远”,相似度低。业务上不会对这两个概念进行严格区分,有时用文本距离,有时则会用文本相似度。
2. 各类算法
2.1 欧氏距离
数学中的一个非常经典的距离,公式如下:
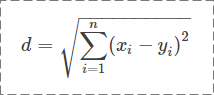
例1:计算“产品经理”和“产业经理是什么”之间的欧氏距离
过程如下:
- 文本向量A=(产,品,经,理),即x1=产,x2=品,x3=经,x4=理,x5、x6、x7均为空;
- 文本向量B=(产,业,经,理,是,什,么),即y1=产,y2=业,y3=经,y4=理,y5=是,y6=什,y7=么。
这里规定,若xi=yi,则xi-yi=0;
若xi≠yi,|xi-yi|=1。
所以,欧氏距离是2
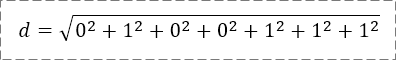
(1)适用场景
编码检测等类似领域。两串编码必须完全一致,才能通过检测,这时一个移位或者一个错字,可能会造成非常严重的后果。比如下图第一个二维码是“这是一篇文本相似度的文章”,第二个是“这是一篇文本相似度文章”。从人的理解来看,这两句话相似度非常高,但是生成的二维码却千差万别。

扫描后,显示“这是一个文本相似度文章”

扫描后,显示“这是一个文本相似度的文章”
(2)不适用场景
文本相似度,意味着要能区分相似/差异的程度,而欧氏距离更多的只能区分出是否完全一样。而且,欧氏距离对位置、顺序非常敏感,比如“我的名字是孙行者”和“孙行者是我的名字”,在人看来,相似度非常高,但是用欧氏距离计算,两个文本向量每个位置的值都不同,即完全不匹配。
2.2 曼哈顿距离
和欧氏距离非常相似(把平方换成了绝对值,拿掉了根号),公式如下:
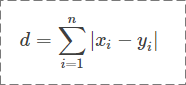
适用场景同欧氏距离。
2.3 编辑距离(Levenshtein距离、莱文斯坦距离)
顾名思义,编辑距离指的是将文本A编辑成文本B需要的最少变动次数(每次只能增加、删除或修改一个字)。
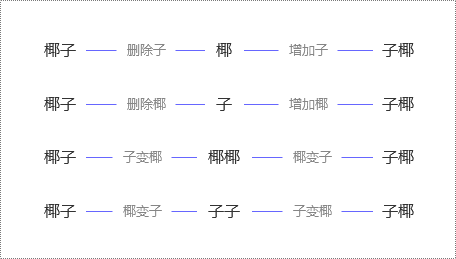
例2:计算“椰子”和“椰子树”之间的编辑距离。
因为将“椰子”转化成“椰子树”,至少需要且只需要1次改动(反过来,将“椰子树”转化成“椰子”,也至少需要1次改动,如下图),所以它们的编辑距离是1。
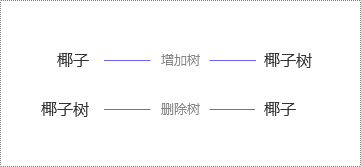
因此,编辑距离是对称的,即将A转化成B的最小变动次数和将B转化成A的最小变动次数是相等的。
同时,编辑距离与文本的顺序有关。
比如,“椰子”和“子椰”,虽然都是由“椰”“子”组成,但因为顺序变了,编辑距离是2(如下图),而不是0。
(1)适用场景
编辑距离算出来很小,文本相似度肯定很高。如果用算法语言来说的话,就是精确率很高(即虽然会漏掉一些好的case,但可以确保选出来的case一定非常好)。
(2)不适用场景
反过来说,虽然精确率很高,但召回率不高(准确率、精确率、召回率的定义见文章底部外链)。在某些业务场景中,漏掉的case会引起严重后果,比如“批发零售”和“零售批发”,人的理解应该非常相似,可编辑距离却是4,相当于完全不匹配,这显然不符合预期。
2.4 Jaccard相似度(杰卡德相似度)
杰卡德相似度,指的是文本A与文本B中交集的字数除以并集的字数,公式非常简单:
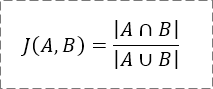
例3:计算“荒野求生”和“绝地求生”的杰卡德相似度。
因为它们交集是{求,生},并集是{荒,野,求,生,绝,地},所以它们的杰卡德相似度=2/6=1/3。
杰卡德相似度与文本的位置、顺序均无关,比如“王者荣耀”和“荣耀王者”的相似度是100%。无论“王者荣耀”这4个字怎么排列,最终相似度都是100%。
在某些情况下,会先将文本分词,再以词为单位计算相似度。比如将“王者荣耀”切分成“王者/荣耀”,将“荣耀王者”切分成“荣耀/王者”,那么交集就是{王者,荣耀},并集也是{王者,荣耀},相似度恰好仍是100%。
(1)适用场景
- 对字/词的顺序不敏感的文本,比如前述的“零售批发”和“批发零售”,可以很好地兼容。
- 长文本,比如一篇论文,甚至一本书。如果两篇论文相似度较高,说明交集比较大,很多用词是重复的,存在抄袭嫌疑。
(2)不适用场景
- 重复字符较多的文本,比如“这是是是是是是一个文本”和“这是一个文文文文文文本”,这两个文本有很多字不一样,直观感受相似度不会太高,但计算出来的相似度却是100%(交集=并集)。
- 对文字顺序很敏感的场景,比如“一九三八年”和“一八三九年”,杰卡德相似度是100%,意思却完全不同。
如果要计算Jaccard距离,公式稍作变更即可:
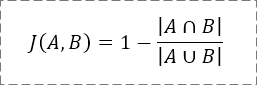
2.5 余弦相似度
余弦相似度的灵感来自于数学中的余弦定理,这里对数学内容不做过多解释,直接上公式:
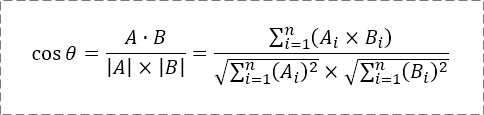
其中,A、B分别是文本一、文本二对应的n维向量,取值方式用语言比较难描述,直接看例子吧:
例4:文本一是“一个雨伞”,文本二是“下雨了开雨伞”,计算它们的余弦相似度。
它们的并集是{一,个,雨,伞,下,了,开},共7个字。
- 若并集中的第1个字符在文本一中出现了n次,则A1=n(n=0,1,2……)。
- 若并集中的第2个字符在文本一中出现了n次,则A2=n(n=0,1,2……)。
依此类推,算出A3、A4、……、A7,B1、B2、……、B7,最终得到:
- A=(1,1,1,1,0,0,0)。
- B=(0,0,2,1,1,1,1)。
将A、B代入计算公式,得到
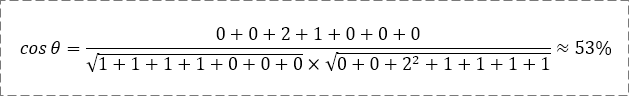
(1)适用场景
余弦相似度和杰卡德相似度虽然计算方式差异较大,但性质上很类似(与文本的交集高度相关),所以适用场景也非常类似。
余弦相似度相比杰卡德相似度最大的不同在于它考虑到了文本的频次,比如上面例子出现了2次“雨”,和只出现1次“雨”,相似度是不同的;再比如“这是是是是是是一个文本”和“这是一个文文文文文文本”,余弦相似度是39%,整体上符合“相同的内容少于一半,但超过1/3”的观感(仅从文本来看,不考虑语义)。
(2)不适用场景
向量之间方向相同,但大小不同的情况(这种情况下余弦相似度是100%)。
比如“太棒了”和“太棒了太棒了太棒了”,向量分别是(1,1,1)和(3,3,3),计算出的相似度是100%。这时候要根据业务场景进行取舍,有些场景下我们认为它们意思差不多,只是语气程度不一样,这时候余弦相似度是很给力的;有些场景下我们认为它们差异很大,哪怕意思差不多,但从文本的角度来看相似度并不高(最直白的,一个3个字,一个9个字),这时候余弦相似度就爱莫能助了。
2.6 Jaro相似度
Jaro相似度据说是用来判定健康记录上两个名字是否相同,公式如下:
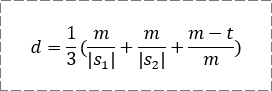
其中,m是两个字符串中相互匹配的字符数量;|s1|和|s2|表示两个字符串的长度(字符数量);t是换位数量。
这里着重说一下“匹配”和“换位”的概念,先列一个公式,我称之为“匹配阈值”:
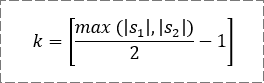
当s1中某字符与s2中某字符相同,且它们的位置相距小于等于k时,就说它们是匹配的。
比如“我明白了”和“快一点告诉我”,按公式算出k=2。虽然两个字符串中都有“我”字,但一个在第1位,另一个在第6位,相距为5,大于k值,所以这两个字符串没有任何一个字符是匹配的。
再比如“我明白了”和“明白了我”,k=1,所以这两个字符串的“明”“白”“了”是匹配的,但是“我”是不匹配的,所以它们有3个字符是匹配的。
换位的意思,是将s1和s2匹配的字符依次抽出来,看它们顺序不一样的字符有多少个,这个数就是换位数量。
例5:计算“我表白了一个女孩”和“近几天我白表了一次情”的Jaro相似度。
|s1|=8,|s2|=10,k=4,匹配的字符有5个,即m=5,分别是“我”“表”“白”“了”“一”。
将s1中的匹配字符依次抽出来,得到一个向量r1=(我,表,白,了,一)。
将s2中的匹配字符依次抽出来,得到一个向量r2=(我,白,表,了,一)。
比对r1和r2,发现有2个位置的值不一样(第2位和第3位),所以换位数t=2。
于是,d=1/3[5/8+5/10+(5-2)/5]=57.5%。
(1)适用场景
对位置、顺序敏感的文本。
文本位置的偏移,很容易使匹配字符数m变少;文本顺序的变换,会使换位数量t增大。它们都会使Jaro相似度减小。换句话说,如果某业务场景下需要考虑文本位置偏移、顺序变换的影响,既不希望位置或顺序变了相似度却保持不变,又不希望直接一刀切将相似度变为0,那Jaro距离是十分合适的。
(2)不适用场景
未知(什么!作者这么任性的吗?)。
其实,我自己确实没想清楚,也没有在实践中使用过这个算法。
整体来说,Jaro距离是比较综合的文本相似度算法,从换位字符数来看,有点像编辑距离;从匹配字符的抽取来看,又有点像“交集”。
最后,对例5做个横向对比:
- 编辑距离算出来是8,s1长度是8,s2长度是10,编辑距离等于8,从数据上看非常不相似,与人的感官差异很大。
- 杰卡德相似度算出来是38.5%,数值比较低,和人的感官差异较大。
- 余弦相似度算出来是55.9%,和Jaro距离算出来差不多,都是50%+,比较符合人的感官——超过一半的内容是相同的,同时有将近一半内容是不同的。
- 如果在此例中,调整字符顺序,让换位数量t变大,匹配数量m变小,余弦相似度不变,Jaro相似度会降低。
3. 拓展阅读
3.1 名词解释
算法中的重要概念(指标)——准确率、精确率、召回率。其中准确率和精确率很容易混淆,详细差别可以点开以下链接:http://t.cn/R6y8ay9
3.2 贝叶斯公式
NLP领域,我个人认为有两个非常重要的、频繁出现的基本公式,一个是前述的文本相似度,另一个就是贝叶斯公式了。对这块有兴趣的同学,可以阅读下文:http://t.cn/haY0x
作者写的非常易于理解——我在《深度学习》这本书里看NLP相关内容时,有几个公式怎么都理解不了,看这篇文章简直是秒懂。
3.3 代码
编辑距离的代码见百度百科最底部,有兴趣的同学可以扩展阅读:http://t.cn/R850kBe
余弦相似度的代码见这篇CSDN博客 ,写的比较详细:http://t.cn/R850ru8
切记,一定要在电脑上打开链接查看代码(别问我怎么知道的)。
PS. 代码这一块我就意思一下,不是重点,不再每个算法都一一列举了。
作者:Insight,“AI产品经理大本营”成员之一
本文由人人都是产品经理专栏作家 @黄钊 授权发布于人人都是产品经理,未经作者许可,禁止转载。
题图由作者提供









所以最后个性化推荐用的哪种方法呢?
一看这么好的文章正要收藏,才发现又是这个作者!
非常好,受教了