
 起点课堂会员权益
起点课堂会员权益机器学习与神经网络

作为产品经理起码要了解算法的原理以及它的边界和优势,能够知道在不同场景下应用什么算法什么模型可以达到目的。
一、机器学习的现状和瓶颈
机器学习如今已算是在互联网圈家喻户晓的名词了。现实生活中其实也早有很多应用,什么无人驾驶,人脸识别,智能音响等等。去年七月国家发布了《新一代人工智能发展规划》,说明人工智能领域已经上升到了国家战略层面。身边一直羡慕的土豪朋友们五年后的长线股也都已经买好了。五年后的事情我不知道,但是对我印象最深的就是去年互联网大会,原先人们口中的互联网现在都改名叫传统互联网了。当我们还在理解什么是机器学习的时候,别人已经开公司帮人制定解决方案了。
实际上当前机器学习作为工具商业化较为广泛的还是在B端,比如一些金融公司会输出自己的风控能力、反作弊能力。在一些高精密工业领域通过AR+AI的技术,已经可以帮助技术人员迅速测量出仪器的指标,并将相关数据回传至控制系统中。大大滴减少了技术人员手工测量的工作,同时也减少了人工测量数据的误差。更多的应用场景比如安防领域,通过人脸识别技术可以快速记录出入人员,从而把非结构化数据变成结构化。
不过机器学习也并不是在所有领域都能发挥出巨大作用,起码是在现在这个阶段。机器学习很多情况是需要很多标注数据来供机器进行学习,通过对标注数据不断的学习和优化从而使其建立一个泛化的模型,当新的数据通过这个模型时机器便会对其进行分类或者预测。
比如说如果要判断一个病人是否患有血管癌,就需要有大量被标注的血管病变数据。但这些标注数据的工作是需要非常有临床经验的医生一个一个的去判断和标注的。一方面是有经验的专家医生很少,另一方面对于这类数据本身数量也有限。另外医疗行业对于模型的准确率要求肯定不会亚于无人驾驶。所以不可否认机器学习的应用的确有它的强大之处,但在不同领域中充满的挑战也非常多。
二、神经网络算法
按照惯例,简单介绍一下神经网络。
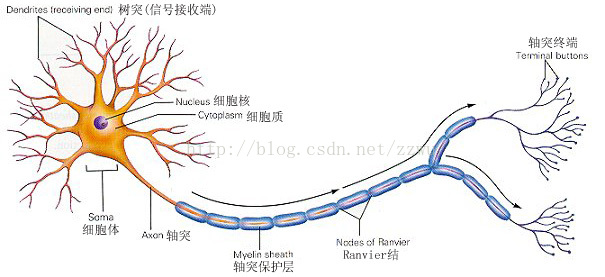
1、神经元
人类对事物的感知是通过无数个神经元通过彼此链接而形成的一个巨大神经网络,然后每层神经元会将接收到的信号经过处理后逐层传递给大脑,最后再由大脑做出下一步决策。神经网络算法实际上就是在模仿这一生物原理。
2、监督无监督
神经网络算法是属于有监督学习的一种。有监督学习实际上就是需要有大量的被标注数据供其学习。反之无监督就是不需要事先对数据进行标注,而是利用算法挖掘数据中潜在的规律,比如一些聚类算法。那么半监督学习,相信也不难理解。
3、权重参数
神经网络算法中的最小单元即为神经元,一个神经元可能会接受到n个传递过来的数据。每条数据在输入神经元时都需要乘以一个权重值w,然后将n个数据求和,在加上偏置量b。这时得到的值与该神经元的阈值进行比较,最后在通过激活函数输出处理结果。
4、线性与非线性
实际上算法本身最核心的是一个线性函数y=wx+b。w为权重值,b为偏置量,x为输入数据,y为输出数据。当我们在处理某些数据时,理想情况是这些数据为线性可分的。这样只要我们找到这条直线的w和b就可以作为某个模型来对数据进行分类或预测了。如下图:
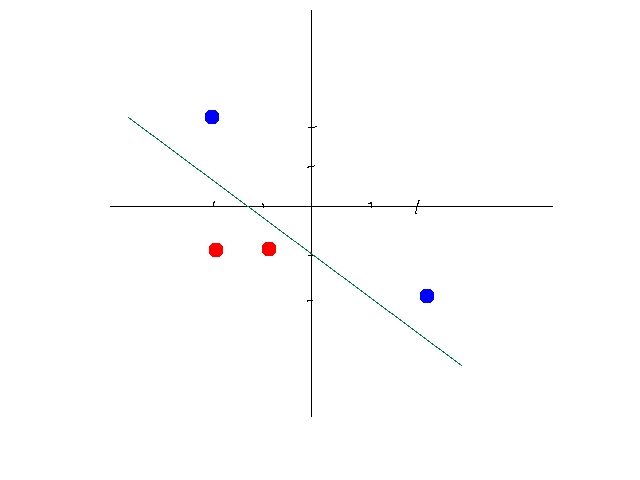
但事实上大部分的数据并不是线性可分的,或者说一条直线无法很好的表达这些数据集。这时候怎么办呢?这时候一般情况下就会通过增加多个神经元以及激活函数来使模型拟合数据集。
5、激活函数
那么,什么是激活函数?说白了,激活函数就是一个能把线性函数掰弯的函数。比如下面的这组数据我们是无法通过一条直线将红蓝两种数据分隔开。但是通过激活函数,我们甚至可以将一条直线掰成一个圆。这样我们就可以将两组数据分隔开了。
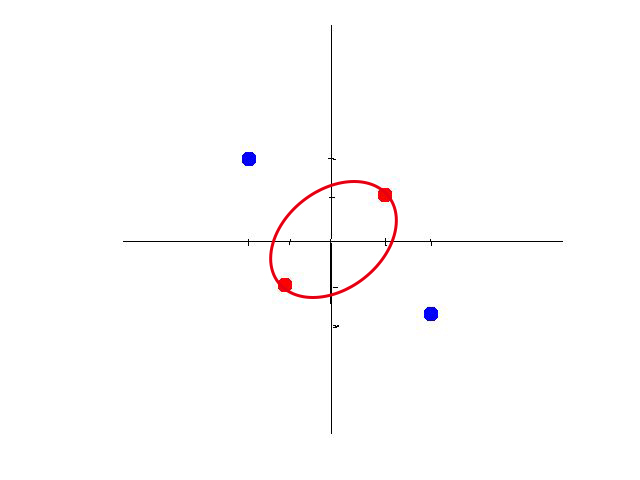
所以理论上,我们可以将一条直线做任意的变化使其更加贴近数据集,并选取一条最优曲线即为我们期望的最终训练模型。那么我们的目标就很明确了。
6、优化器
但是如何才能找到这么一条曲线?这时候我们可以引入一系列的优化算法,比如梯度下降。通过优化算法对函数求导我们可以使模型中的参数逐渐贴近真实值。同时在优化过程中还需要加入损失函数。
7、损失函数
什么是损失函数?损失函数说白了可以理解成为一个验收者。损失函数会去衡量测试数据中的结果与实际值的偏差情况。如果偏差较大就要告诉优化函数继续优化直到模型完全收敛。常用的损失函数如:交叉熵、平方差等。
8、过拟合欠拟合
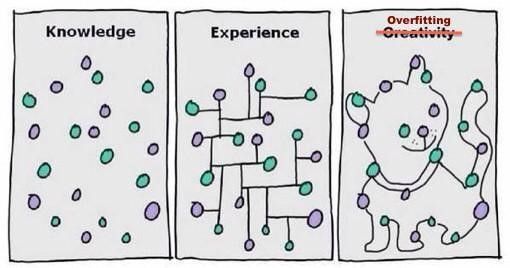
不过需要注意的是,如果我们的曲线完美的拟合了所有数据,那么这条曲线是否即为我们模型的最优曲线呢?答案是否定的。这里我们还需要考虑一个模型泛化的问题。如果我们训练了一个模型,但是这个模型仅能在训练数据集中发挥很大效用,那么它实际的应用意义其实并不大。我们需要的是通过这个模型能够让我们了解到我们未知的信息,而不是已知的。所以我们并不希望这条曲线能够穿过所有的数据,而是让它尽可能的描绘出这个数据集。为了防止模型过拟合可以尝试增加训练数据同时减小模型复杂度。同样我们也不可能让这条曲线完全偏离数据集。
三、深度学习框架
自己推导算法?自己设计模型?不存在的…大神们早就帮你封装好了。安心做一个调包侠吧。
没有训练数据?没有测试样本?不存在的…大神们早就帮你准备好了。安心做一个调参狗吧。
什么?还是不知道怎么做?不存在的!下面让你秒变机器学习大神(装逼狗)。
Keras
机器学习的框架这里就不枚举了,不过Keras还是非常值得提一下。相比Tensorflow,Keras更容易新手上手,封装的更加高级。建议在尝试使用框架前先了解或学习一下python,然后直接Keras中文文档吧。
那么如何秒变大神?Keras框架中其实已经内置了很多预训练好的模型,如ResNet50图片分类器。你只需要将下图中的代码复制到你的Keras框架中并运行。然后泡一杯咖啡,想象自己已经成为吴恩达一样的大神。静静的等待着深藏功与名的那一刻的到来。
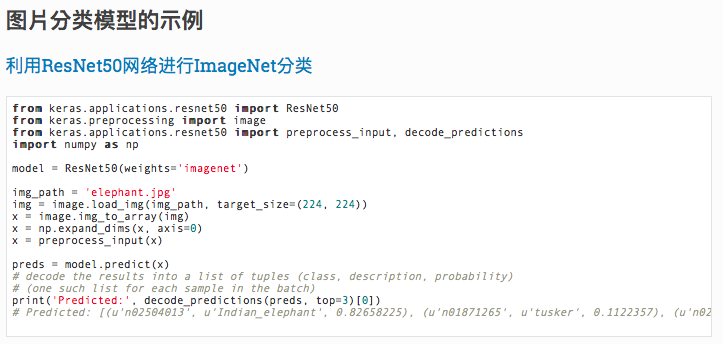
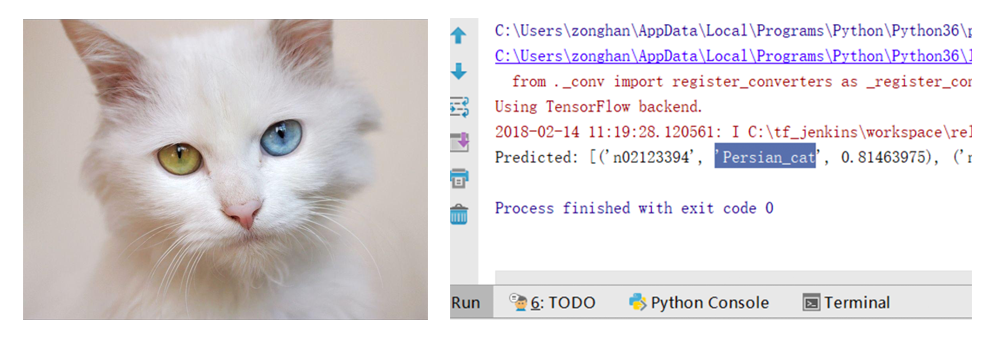
大概半小时的时间,模型下载安装完毕。激动人心的时刻终于来临,赶快来测一下这个模型。从百度上随便搜索了一张猫的图片,并将图片的大小改为224*224像素。然后将图片放到项目的根目录中(不要忘记修改代码中的图片名称),最后运行程序。你会发现模型不仅能识别出来是一只猫,并且还知道是一只波斯猫。惊不惊喜?刺不刺激?是不是有很多小图片想要尝试?赶快玩起来吧。
通过对这个模型的封装以及作为产品经理的你,相信也可以YY出很多好玩的应用。虽然通过Keras中的预置模型可以让我们快速体验机器学习的能力,但是个人建议最好还是自己手动搭建一套简单的模型会更加帮助理解。Keras是通过Sequential模型线性堆叠网络层。其中一些常用的层Keras已经封装好了,同时上面说到的激活函数、优化器、损失函数等等也都是任君挑选的。所以想要通过Keras搭建自己的模型其实也不难。上述内容实际上也只是一个抛砖引玉,至少个人也是通过这些才开始对机器学习感兴趣的。
想要成为机器学习大神?困难的确存在。不过,作为产品经理起码要了解算法的原理以及它的边界和优势,能够知道在不同场景下应用什么算法什么模型可以达到目的。
最后感谢大家的浏览,若文中存在理解有误的地方还望大神指出。
本文由 @宗瀚zone 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Pixabay,基于 CC0 协议









只想喊一句:大神
想问一下“每条数据在输入神经元时都需要乘以一个权重值w,然后将n个数据求和,在加上偏置量b。这时得到的值与该神经元的阈值进行比较,最后在通过激活函数输出处理结果。”阈值不是所谓的偏置值bm吗?
打错了 是b不是bm
厉害,膜拜,求更多产出
先收藏