
 起点课堂会员权益
起点课堂会员权益LLM-Native产品的变与不变(下)
LLM-Native产品的变与不变是一个持续的过程,始终以用户需求和品质要求为出发点,根据技术的发展进行相应的更新和适配。本文讲述相关内容,希望对你有帮助。

一、创建LLM-Native产品的几个原则
以下是一些进行LLM-Native产品设计时可能有用的建议:
1. LLM-Native与模型自由
《Does One Large Model Rule Them All? Predictions on the Future AI Ecosystem》(作者:谷歌前CEO Eric Schmidt、Databricks首席科学家、斯坦福教授Matei Zaharia和Samaya AI创始人Maithra Raghu)这篇文章写于今年4月初,在当时GPT-4封神、GPT-5呼之欲出的舆论环境下,几位大佬提出了一个非常不合时宜的行业非共识:未来的AI生态中,通用大模型负责解决长尾问题,高价值的业务场景将由专业AI系统来解决,具体表示为下图:

模型类型-问题价值曲线以这篇文章的内容为出发点,我们认为:从产品工作的视角来看,LLM-Native产品必须拥有自己的模型。而这并不意味着通用模型和垂直模型是非此即彼的竞争关系,事实上我们相信在较长的一段时间内,我们都会看到智慧程度更高的通用底层模型与业务能力更强的垂直模型展现出某种合作关系,具体来说:
- 垂直模型面向应用,用更低的成本以及更好的业务效果为特定场景服务。
- 通用模型面向模型生产,用更强的智慧水平提高垂直模型生产的效率。
所以对于LLM-Native产品的工作来说,首先应该将专业模型加入工作计划表,其次要善于借助通用模型,最后要记住不要过分依赖通用模型。
2. 找到自己的LLMs的能力光谱
我们在前文提到过“需求即能力”这一LLMs技术的特点,这个特点决定了不同的LLM-Native产品因其面向场景、解决的问题、面向的用户群体不同,而对模型能力的要求有所差异。一个形象的比喻是:原子的特征光谱。即当我们将某种LLM-Native的产品对应到LLMs时,就像不同原子会显示出不同的特征光谱一样,此时应该能够列出一个明确的模型能力规格说明书,通过这份说明我们可以:
- 知道自己需要什么样的模型。
- 能够评价不同模型对业务的价值。
- 可以指导模型效果的优化方向。
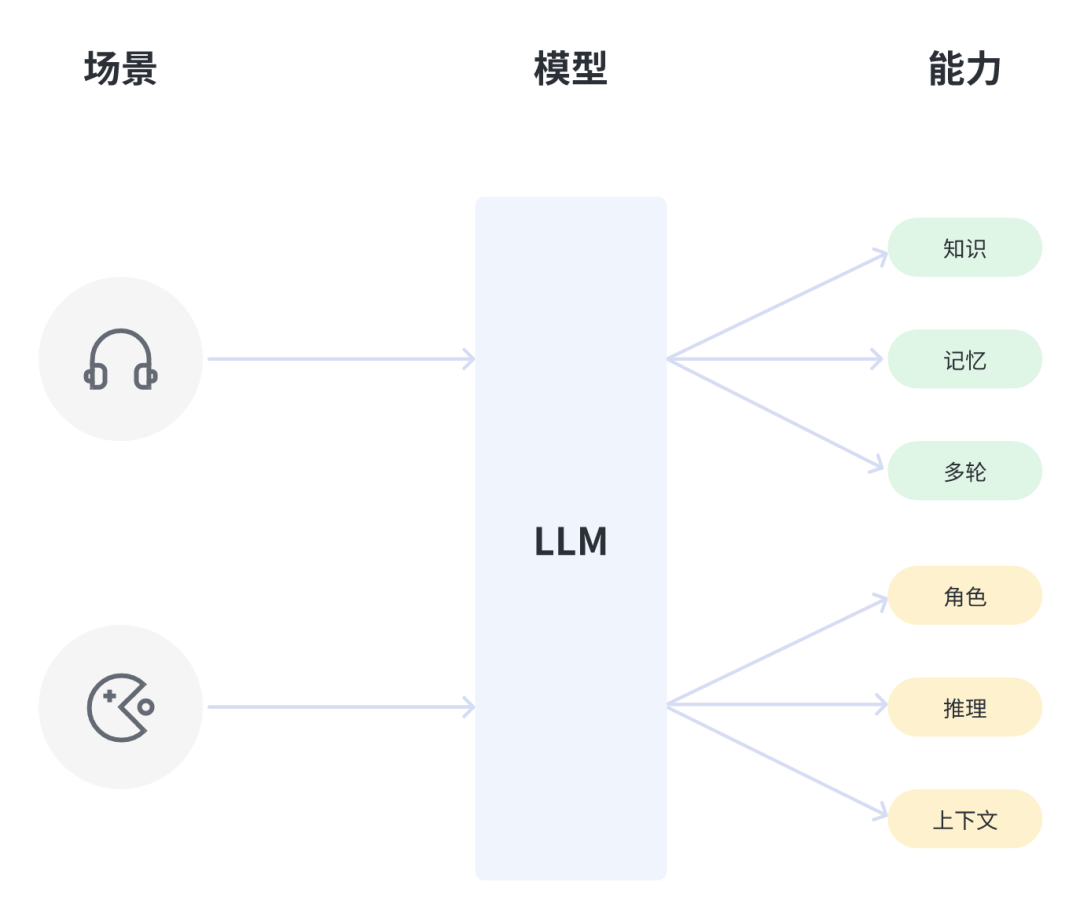
不同的场景对模型的能力要求会有很大的差别所以,未来LLM-Native产品经理可能会有一项工作就是定义出自己场景的模型能力光谱,而这将是整个产品设计工作的起点。
3. 利用LLMs的优势而非劣势
任何一项技术都有其技术优劣势,所以产品设计者一定要懂得扬长避短、顺势而为。比如相对于PC互联网,移动互联网有随时可使用、位置信息、设备绑定、相机陀螺仪等硬件优势,同样也有展示空间有限、文字输入不便等弱点,所以在扬长避短的原则下,出现了面向碎片化时间的产品(feed流类产品)、出现了基于位置信息的产品(打车)等,在设计上也会用更轻的交互来避免文字输入。对于LLM-Native产品也是一样,我们需要找到LLMs的优点,基于这些优点来设计,并同时识别出技术的弱项,从而在产品设计时尽量规避,比如我们很容易可以整理出一些可以供参考的优劣势:
优势:
- 能力是一个开放域
- 通过自然语言完成交互
- 内容是动态可操作的
- ……
劣势:
- 内容不可控
- 实时生成速度慢
- 模型更新、使用成本高
- ……
比如A16Z最近提出的AIGC应该面向概率型产品(probabilistic products)进行设计的观点,就是试图利用模型优势进行设计的一种尝试。
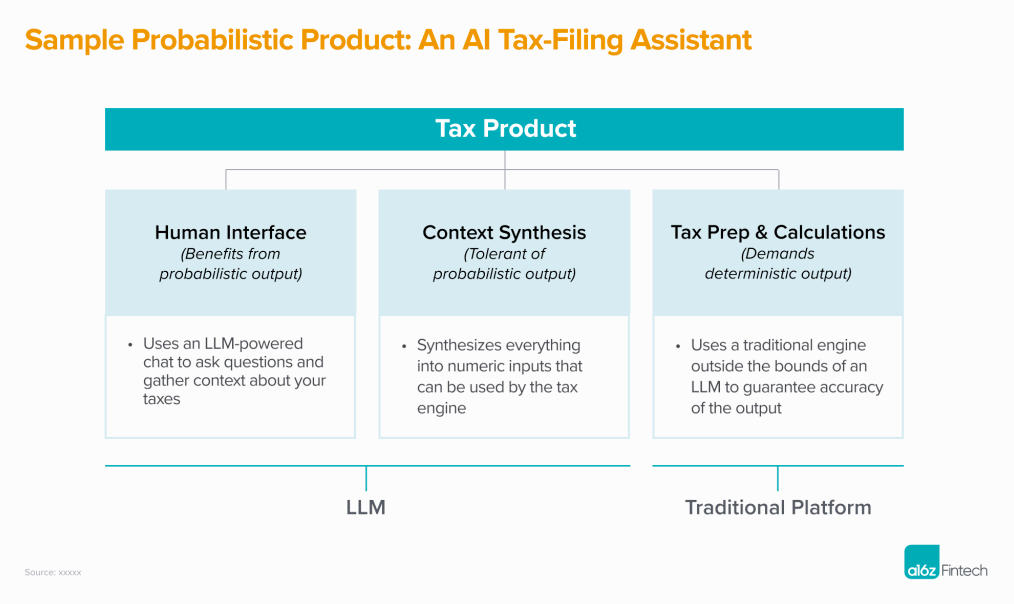
如何利用模型的概率性进行产品设计也许,未来每个LLM-Native的产品经理都应维护一份LLMs的优劣势清单,在确定产品的功能设计后,都应该从LLMs技术的优劣势进行一次审核,看看是否做到了“趋利避害”。
4. 生成器和系统2
使用LLMs进行生成是以指令为起点的,即:指令->LLMs->内容&行动最直观的指令是用户的prompt,也就是使用自然语言将需求表述出来,此时,需求=指令,但随着LLMs技术的发展,我们会发现:
- 由于模型能力的开放性,相同需求的不同指令差距会很大。
- 除了prompt外的其他要素也会加入指令被输入模型,比如外部知识库、工具接口等。
- 模型能力越来越强,对应的指令也会越来越复杂,这也是上文提到的“语言即代码”特性的必然结果。
一个愈发明显的趋势是用户需求和指令的分离,即会有一个专门的指令生成环节来连接用户需求和LLMs(Agent便是这种趋势下的必然产物)。
这里我们将接收用户需求并翻译为大模型指令的工作环节称为生成器:一个面向特定任务设计的,能够将用户的需求最大限度转化为模型生成时应当执行的行动集合的指令的工作模块。
生成器将用户的需求经过处理变成大模型的可执行的生成指令,生成器可以很简单,比如一个prompt模板,也可以很复杂,比如一个Agent再加上数据库,甚至也可以是一个模型,比如生成prompt。
「生成器与底层模型共同完成生成过程」这一范式具有更深的底层逻辑,即《思考,快与慢》一书中提出的系统1和系统2,底层模型将作为系统1,而生成器将作为系统2,二者形成一个整体系统,并分别适合用来解决不同类型的问题,系统1和系统2的概念也被OpenAI联合创始人Andrej Karpthy用来解释GPT的原理,与人类的系统1与系统2更加独立的关系不同,LLMs的两个系统存在显著的转化关系:系统2的能力会不断被系统1内化,所以系统2需要不断被设计,而系统1则会不断增强。作为用户需求的翻译者,生成器将会在很长一段时间内成为LLM-Native产品的关键设计环节,结合上文的信息,产品设计工作将从功能性设计转向模型能力+生成器的建设:
- 设计产品就是设计模型
- 设计产品就是设计生成器
二、LLM-Native产品的特点
下面我们将试图抽象出LLM-Native产品可能具有的特点,理解这些特点可以让产品方向的选择以及设计工作更容易和科学。
1. 新问题
首先是新问题,LLM-Native产品需要面向新问题所对应的需求进行设计。什么是新问题呢?我们知道所有产品的价值基础都来自于对某种用户问题的解决,而新的技术范式通常会带来两类问题,即:
- 什么会更好:如何通过新技术更好的解决已有问题。
- 什么会出现:拥有新技术后有哪些之前无法解决的问题变得可解了。
结合在前文市场熵的部分我们已经做过的说明,我们可以分析出这两类问题有如下特点:
- 第一类问题:需求容易被发现,很快就能有收益,但解决的是存量需求,通常会表现为某种形式的降本,需求的价值上限低。
- 第二类问题:需求通常是被隐藏或者压抑的,需要被挖掘,通常需要更长的产品周期才能兑现收益,解决的是增量需求,带来的也是社会整体价值的增加,比如创造新职业,甚至新行业,需求的价值上限更高。
很明显,第二类问题才是LLM-Native产品要面向的新问题。那么如何找到这类新问题?这里提供一些可供参考的定位方法:
- 拥有新技术才能解决,比如短视频产品需要同时具备智能手机+4G网络才会出现。
- 将已有产品的底层需求代入新技术,比如个人知识库在表面解决的是信息存储和处理的问题,而其底层则包含着如何有效的使用这些信息的需求,从这个底层需求出发,就能发现LLMs的生成能力与这个需求天然契合。
- 从新技术的特点出发,我们上文提到了一些LLMs技术的特点,那么用这些特点来对应用户问题也是一个可行的思路,比如LLMs可以生成如何行动的信息,那么对应的问题便是计划类、行动类问题,相比上一代AI解决感知型、决策型问题而言,就是新问题。
通过技术、底层需求两个思考维度,我们还可以发现更多定义新问题的方法,这里由于篇幅原因不做赘述。
2. 新形态
如同PC时代的网站、移动时代的APP一样,我们相信LLM-Native产品也会诞生自己的产品形态,虽然现在无法判断这个形态到底会是什么,但是已经有一些正在形成的演变趋势。
极简设计这里的极简指的是产品表现层体现出的极简,更准确的描述应该是:极简设计+丰富能力用看似简单的产品形态来实现复杂多样的功能,这已经成为以LLMs为核心产品的特点,如果对这类产品进行功能清单梳理,大家会发现其核心使用流程所对应的功能都非常简洁,而其能够完成的任务或者具有的能力又极其丰富
这种趋势是由前文提到的「需求即功能」特性决定的,由于LLMs理论上可以将任何信息通过压缩+预测next token的范式进行生成,所以大量的产品功能无需暴露给用户。但是值得注意的是,极简设计并不意味着能够帮助用户更快完成需求传递的功能和产品界面不再被需要,他们会以另一种形态存在于LLM-Native产品中。
动态功能动态功能是指LLMs产品在使用时,其展现给用户的功能、界面并非是提前设计的,而是可以根据用户当时的需求进行动态生成,这个特点同样具有必然性:
- LLMs的开放域使用方式,要求其必须拥有无限的功能与界面,而这些功能与界面显然是无法通过人工设计来满足的,所以从技术的特性上其具有必然性。
- LLMs的「语言即代码」特性则提供了动态功能的可行性,在这个特性下,用户的需求以自然语言的形式进行转化和加工后,可以直接生成对应的功能或者界面。动态功能和界面将是LLMs相关产品的重要发展方向,也许未来我们可以用动态功能在产品中的占比来衡量
一个产品的LLM-Native程度,推荐系统作为对检索系统的个性化,在移动互联网开创了一个全新的产品时代,我们有理由相信LLMs的动态功能特性也将开启一个新的产品时代——个人定制化产品时代。
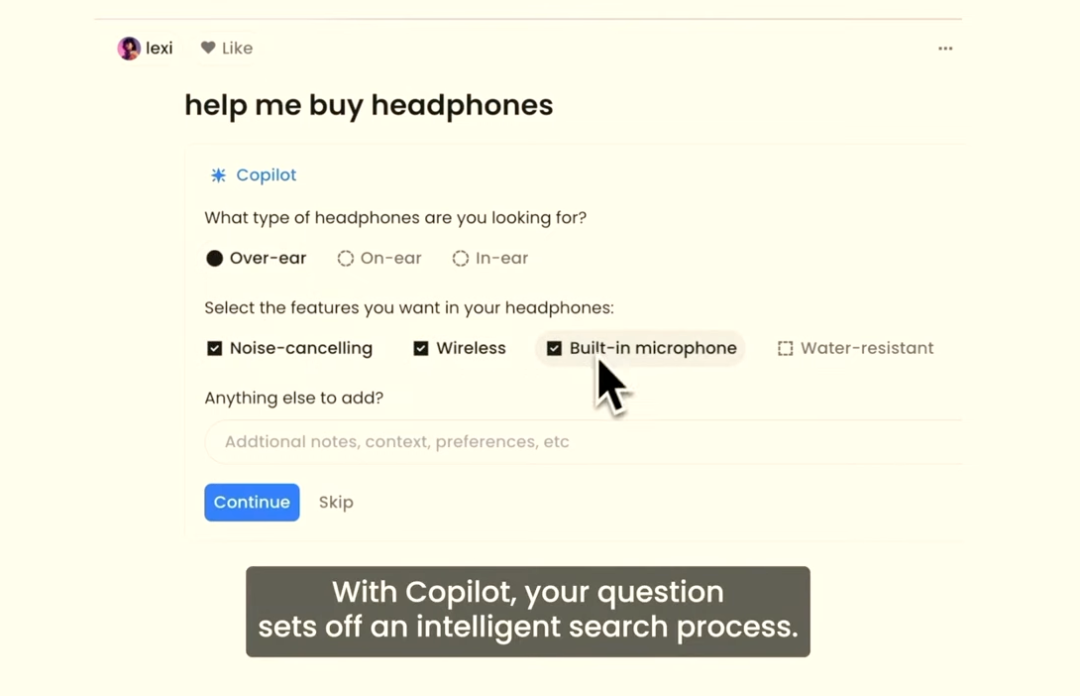
Perplexity的Copilot功能:根据用户输入生成动态表单来明确需求定制化产品如同推荐带来了信息内容的个性化,我们相信LLMs技术将带来产品的个性化。
产品的标准化和需求的个性化是一组产品设计中的基本矛盾,用户天然希望产品为自己量身定做,而产品提供者则需要通过标准化来确保产品的生产和运营成本,我们在前文「用户需求的无损传递」中已经涉及到这个问题的讨论。
相比于软件范式下产品必须标准化不同,LLMs带来了「产品说不定也可以个性化」的全新机会,那么这将带来内容个性化后的新一轮产品革命,围绕「个人定制化产品」的理念,所有的已知产品都存在升级迭代的可能。
3. 新交互
关于LLM-Native产品的交互工作变化是近期被讨论比较多的一个话题,有不少文章进行进行了很好的说明,在此我们提供几个交互设计工作中原则性的特点:从告诉机器怎么做到告诉机器要什么全球顶级的用户体验研究机构Nielsen Norman Group在6月的一篇文章中提出,LLMs为核心的AI技术将带来计算机出现后的新一次交互范式革命,之所以称之为革命的关键原因在于交互设计工作的目标发生了变化:上一个交互范式的工作目标为「如何更好的告诉机器该如何遵循用户指令」(Command-Based Interaction Design),而新的AI交互范式下,工作目标将更新为「如何更好让机器知道用户想要什么」(Intent-Based Outcome Specification)。

人机交互的三种范式自然语言成为一个新的交互维度,但不是交互本身我们上文提到过LLMs具有通过自然语言来驱动产品使用流程的特点,这意味着自然语言从交互的内容成为了一种交互设计的维度。而随着ChatGPT的出现,产品的设计出现了一种“万物皆为Chatbot”的设计趋势,但是实际上Chatbot只是LLMs在交互中的一种展现形式,更为本质的问题在于自然语言从交互的内容变成了交互的方式。对此问题,Notion的UX研究员Linus Lee在其《Generative Interfaces Beyond Chat》的talk中有过论述,其核心观点为:
- 自然语言作为交互方式有优点(更高的灵活性)也有弱点(可理解性)。
- LLMs对交互设计来说,其价值在于增加了一种新的维度,应当与其他的交互维度(如GUI)配合使用。

自然语言交互提供了更好的灵活性,但也损失了产品的可理解性
所以对于LLM-Native产品来说,一方面我们将显著的观察到,自然语言将在交互中出现并承担重要的角色,但同时我们也应尽量避免陷入「LLM-Native=Chatbot」的设计误区。面向不确定性进行设计在前文中,我们提到过LLMs具有能力黑盒和生成内容不可控等特点,这些特点将带来产品使用过程中的巨大不确定性。对于传统的软件产品思路,交互一定要是清晰、准确、具体的,而这与LLMs的生成技术显然存在冲突,所以LLM-Native产品势必会展现出一种新的交互思想,即:面向不确定性设计,这将展现出的工作特点为:
- 尽可能减少对用户行为的约束。
- 会有更多设计被用于帮助和引导用户理解和调起模型能力。
- 对模型输出会有更多的引导和约束从而确保结果的可控。
三 、早期LLM-Native产品的观察
已经有越来越多令人兴奋的的新产品开始出现,下面将从一些可观察的市场信息中尝试抽象出某些共性和趋势,以期为正在面向LLM-Native理念进行设计的产品工作提供一些有价值参考。
1. 社交
马克思曾说「人的本质是一切社会关系的总和」,从这个角度而言,LLMs的出现对社交产生的一个重大影响在于:在社会关系中,增加了AI这一全新的社交维度。这使得社交产品有了全新的想象空间,具体表现为除了人-人社交的角度外,我们还可以从如下角度进行设计:
- 人-机社交:人类与AI进行社交,比如Character.ai,Replika。
- 机-机社交:AI与AI进行社交,人类进行观察或者参与,比如chirper。
注:机-机社交是一个尚未得到足够重视的方向,该方向下人类可以为AI智能体们设计各种活动和任务,并以上帝视角进行观察和干预实验,比如用LLMs模拟人类成长过程中不同类型事件对其后续行为可能产生的影响。
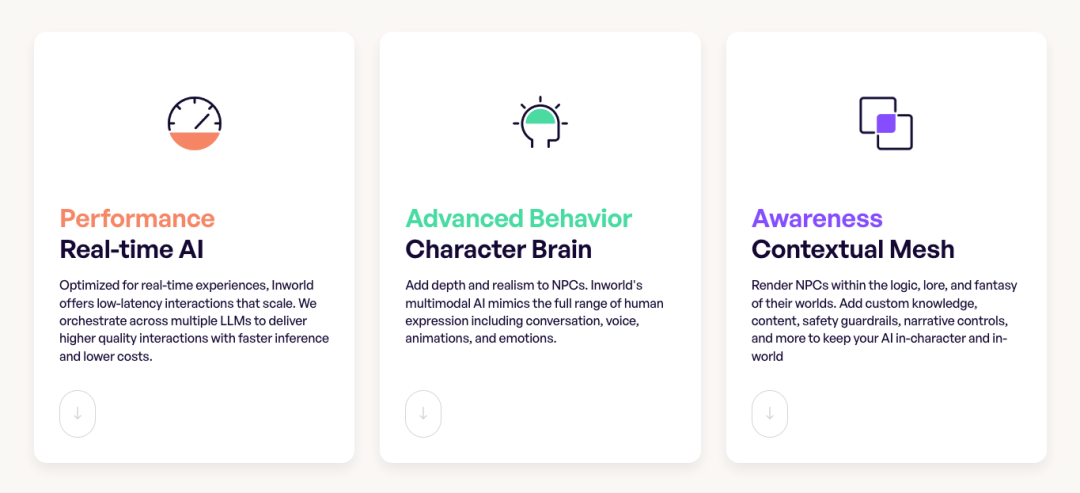
Inworld:提供游戏中的智能NPC服务,已经具备了机-机交互的观测价值从产品价值维度来看,目前的社交服务主要提供两种价值:
- 交换信息:即提供效率价值
- 找到同类(from 张小龙):即提供情绪价值
那么AI维度的加入后,我们可以得到这样一张有趣的产品定位表,并能够对已有的产品进行定位:

社交产品设计的维度变得更加丰富所以对于LLM-Native的社交产品来说,我们显然将面向一个更加广阔的设计空间,比如设计一个能在图中覆盖多个社交维度以及价值维度的新型产品。
2. 内容
前文中已经提到过,LLMs技术将为信息内容产品在生产端、消费端带来一系列变化。目前我们已经能够看到基于这些变化进行的早期尝试,比如一些Demo中,KOL将自己的文章、对话、资料等数据作为知识库并连接ChatGPT接口,从而让读者能够实时、无限制地获取带有自己知识和语言风格的新内容。这当然只是一个很初级的产品化尝试,LLM-Native的内容产品更大的想象力在于,当更多垂直的LLMs在各自领域开始落地、不同模态的生成能力正在产品端进行融合、LLMs的生产和推理成本大幅降低时,我们应当能够看到与现在完全不同的内容产品形态,也许是:
- 可以自定义剧情的多模态内容”小说“。
- 可以按需生产的新型”短视频“内容。
- 可以结合用户画像以及其需求描述的实时生成的资讯内容。
- …
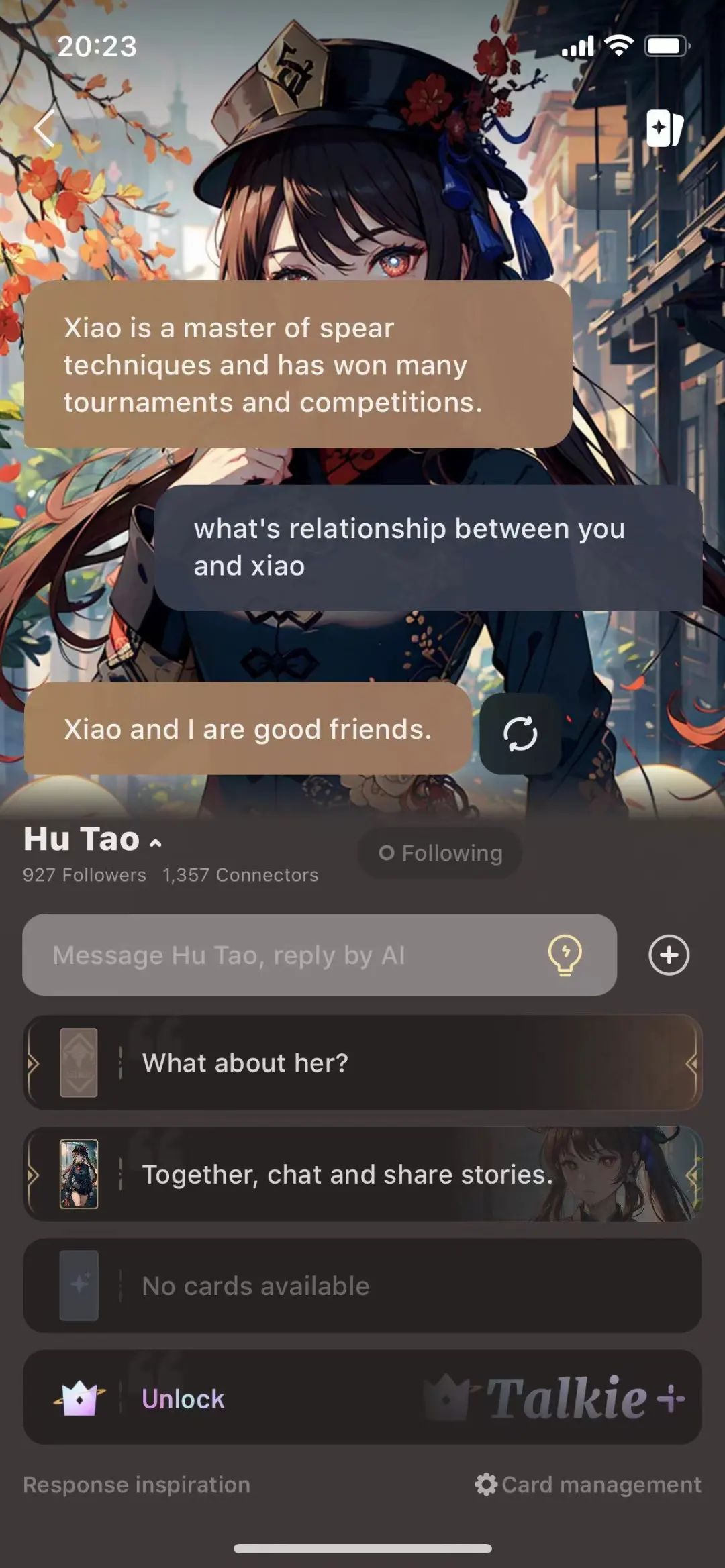
Talkie:提供了一种基于角色扮演的多模态游戏化内容形式
3. 工具
对于效率工具来说,一个显著的产品趋势是:以Copilot产品形态为过渡,实现AI-worker。这里的底层逻辑在于上文中提到的一个概念:模型需要对某种程度的人类智慧数据进行压缩,才有可能涌现出同水平或者更高水平的智能。显然对于效率工具类产品来说,如何对AI生成的内容进行处理、优化从而成为人类标准可用的工作成果,就是一种智慧程度更高,并且尚未被信息化的数据。所以Copilot产品形态将会以已有的LLMs模型能力为基础,通过人机协作工作方式提升效率的同时,搜集更高智慧程度数据搜集的产品,而这也将成为「从LLM-Native走向AGI」的必由之路。Copilot产品形态的要点在于:
- 确实能够在LLMs的能力下提供更高的工作效率。
- 被集成在现有的工作流中并能够获取工作流中的用户操作信息。
- 用户操作信息是已有LLMs能力的衍生。
对于LLM-Native的效率工具产品来说,可能的产品设计思路会分为三个模块:
- 对某个场景有效的LLMs能力建设。
- 以尽可能高效获取工作流中的更高智慧信息为目标进行Copilot产品形态设计。
- 优化LLMs能力直至成为AI-worker。
相信一段较长的时间内,我们应该会看到效率工具中Copilot形态的大爆发,实际上目前各类工具中集成Chatbot只是这个趋势的开始,因为chat的交互方式并不本质,Copilot形态的本质应当是如何获取工作流中对LLMs内容的处理和优化数据。
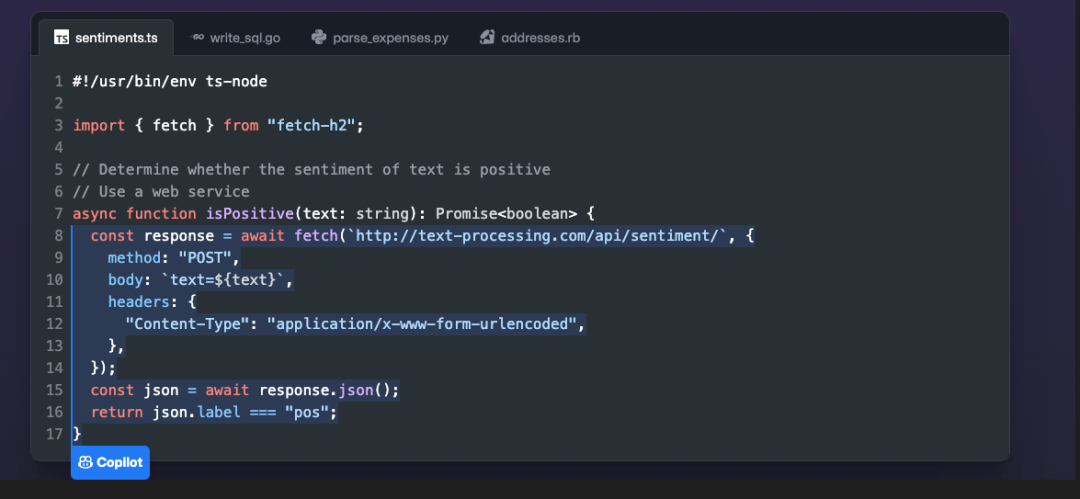
Github Copilot:最早也是最为典型的Copilot产品
总结
本文尝试对基于LLMs技术的LLM-Native产品进行分析,试图探讨如下几个问题:
- LLM-Native产品有何不同
- LLM-Native产品的独特性从何而来
- 在进行LLM-Native产品时应当注意哪些问题
具体而言:我们从使用产品视角出发,尝试对LLMs技术在产品维度的特点进行抽象,并基于这些特点对LLMs技术对产品工作可能带来的变化进行了推演,结合在新技术冲击下依然有效的产品逻辑,我们给出了一些创建LLM-Native应用的可能原则以及目前可见的LLM-Native产品特点,最终通过对几个经典产品方向上LLM-Native产品的观察尝试给出未来的产品工作建议。
需要强调的是,LLM-Native产品将是一个至少与互联网产品、移动互联网产品同等级别的宏大主题并正处于高速发展中,我们既难以观察其全貌,也无法对其发展进行有效判断,所以本文的目标是提供一些对LLM-Native产品工作有价值的问题并提供对这些问题可能有帮助的观察和思考,而非输出观点和提供预测。
希望以此文为基础,能够与更多关注、从事LLM-Native产品工作的朋友们进行交流探讨。感谢Kiwi参与创作,文中的很多观点来自与行业内投资人、产品经理以及算法工程师朋友们的讨论,在此不再一一致谢。
作者:冠叔;公众号:OneMoreAI(ID:OneMoreAI1956),硅基生命观察团,发现、探索、分享AI的one more thing。
本文由 @OneMoreAI 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









q
w