
 起点课堂会员权益
起点课堂会员权益
拆解腾讯的“大模型观”

就在国内大量大模型产品争相亮相时,可以注意到,腾讯却一直保持着自己的节奏。而就在最近,腾讯混元大模型也终于亮相了,那么如何解读这“迟来”的到场?这篇文章里,作者尝试拆解了腾讯的“大模型观”,一起来看一下。

在《5000天后的世界》中,著名未来学家凯文·凯利预言:“在未来的50年里,AI将成为可以与自动化和产业革命相提并论的,不,应该是影响更为深远的趋势。”
而今,大模型似乎就是那根杠杆。自ChatGPT问世以来,“工业革命级的生产力工具”“有史以来最大的平台革命”“新范式的新拐点”之类的说法,已将大模型“封神”。
公开数据显示,截至今年7月底,国内已经有130个大模型产品亮相或宣布。“百模大战”中的“百”,已非虚指。
有意思的是,在大厂们争前恐后入局之时,腾讯却一直保持自己的节奏。
9月7日,在2023腾讯全球数字生态大会上,腾讯混元大模型正式亮相,腾讯宣告全面拥抱大模型。
在厂商们争抢头啖汤时不出来,在大模型密集发布期不出来,等大模型的喧闹消退后终于现身。
有人说这是“迟”,虽迟但到的迟,但腾讯方面更想说它是“实”,脚踏实地的实。这跟腾讯的“大模型观”有些内在相通——它追求的就是实用至上。
01
说到“混元”,许多人可能会想到道家的“混元即无极,无极生太极”。混元所指,是鸿蒙状态,是万物根源。
道可道,非常道。道家始祖老子曾说过“我有三宝,持而保之”,其中之一就是信奉敢为天下后。
而在“中国巴菲特”段永平的阐释中,“敢为天下后”还有后半句:后中争先。

腾讯早在2021年就推出了千亿和万亿参数的NLP(自然语言处理)稀疏大模型,打破了CLUE三大榜单记录,但混元大模型的推出也是千呼万唤始出来。
“做三四月的事情,在八九月自有答案。”有些玩家在打通概念炒作跟对韭当割链路后一哄而上,“三四月”的事情刚开始做就掏出了PPT,腾讯却在“六七月”里不事张扬,直到“八九月”有了答案才让其面世。
腾讯董事会主席兼CEO马化腾的那番话,为此提供了解释:“我们最开始以为这(指AI大模型)是互联网十年不遇的机会,但是越想越觉得这是几百年不遇的、类似发明电的工业革命一样的机遇。”
他认为,“对于工业革命来讲,早一个月把电灯泡拿出来,在长的时间跨度上来看是不那么重要的。关键还是要把底层的算法、算力和数据扎扎实实做好。”
马拉松长跑中,方向对、策略准往往比起步快更重要。
腾讯的通用大模型发布节奏,也被解读为以慢为快,后中争先。
混元大模型参数展示的朴实,似乎可堪佐证——没有狂堆参数,也没展示打了多少榜,腾讯方面主要披露了两个数字:超千亿参数规模,几乎是当前通用大模型的标配;预训练语料超2万亿tokens,和目前最强开源模型Llama 2持平。
与朴实对应的是实用取向:混元大模型不追求Chat(聊天)上的花哨,而追求应用场景上的实效;不是基于国外开源模型训练求快,而是从零开始、全链路自研。
02
实用取向,指向的是让大模型从“可用”变为“好用”。
不得不说,当下的大模型正陷入“又强大,又弱鸡”的悖论:一方面,很多大模型在问答时能秀得一手好打油诗、抖出一番机灵,另一方面,在行业应用中又没太多实质性用处。
大模型研究者李莉就认为,现在很多模型的研究者和应用的制作者,考虑的是如何让别人记住自己,所以效果特别视觉化,“每个视频让人看得血脉贲张,我们纷纷表示太酷炫了,但是静下心来,我们对于技术该怎么用一般都没有答案……如果真正放到经济中,你会发现根本用不上。”
这正是ChatGPT热度滑坡的主要原因:前不久,Newsweek调查显示,ChatGPT的用户数量已经比今年年初高峰时期下降了近95%。用户选的最多的理由就是,感觉“ChatGPT对工作的促进能力没有想象那么强”。
这难言奇怪:在行业应用场景中,用户在意的,可不是大模型能玩什么梗、扯什么淡,而是能否提供专业知识和行业数据。“大”不是最重要的,“专”才是。ChatGPT上生成的很多回答,就被指看上去专业,专业人士一看却似是而非。
而今,随着大模型进入Gartner曲线的相对冷静阶段,越来越多的人已意识到,应用场景是决定大模型能否走远的关键因素。没有落地场景,就没商业前景,也就难以走远。
正因如此,大模型行业正在从拼参数变为拼落地,B端行业应用已成主战场。这勾勒出的,是大模型正从“技术力”转向“生产力”的商业化图谱。
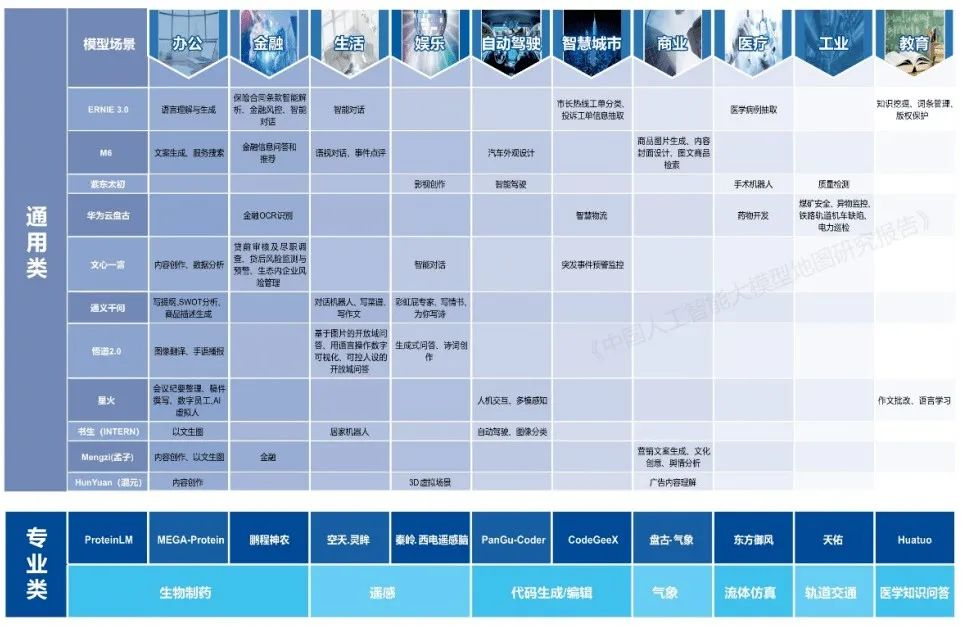
▲中国大模型,很多都很注重跟应用场景结合。
很早之前,腾讯对大模型的认知就是:大模型的长期价值将通过行业应用来体现,绝不仅限于聊天机器人这样简单的问答场景。
这次发布会上,腾讯就强调面向产业,明确要以提效为第一要义。腾讯高级执行副总裁、云与智慧产业事业群CEO汤道生就表示,“大模型需要基于产业场景,与企业数据融合,才能释放出最大的价值。”
以垂(垂直大模型)应垂(垂直细分行业的需求),方为实用。今年6月,腾讯云从产业客户需求场景出发,依托腾讯云TI平台打造模型精选商店。这次发布的混元大模型,则将作为腾讯云MaaS服务的底座,为各业务领域提供支持。
推出的是为应用而生的“从实践中来,到实践中去”的实用级大模型,而非花里胡哨的AI“大玩具”,就是“实”的体现。
03
实用取向,内在要求是让大模型更成熟更靠谱。
大模型要走入行业产业场景,就得减少“幻觉(即胡言乱语)”、避免“诱导(即诱导偏见或欺骗等)”。
克劳德·香农认为,信息的本质是消除不确定性。但体验过的用户都知道,当下的大模型都有着很强的“不确定性”——它经常会变成CheatGPT,给你胡编乱造一通。
若这只是大模型跟用户相互“调戏”,那无非是提供了些笑料,可行业场景专业度要求高、边际容错率低,若是提供了错误信息,很可能引发严重后果。
正因如此,面向产业的大模型必须变得更专业更成熟更靠谱,不能是初看什么都懂、细看什么都不“专”。
腾讯为此采取的策略可以归结为两点:1,全链路自研;2,将内部业务场景当“磨刀石”。
腾讯的混元大模型,从高速网络、底层服务器到网卡、高速组网和平台、模型、算法都是自研,AI基础设施、机器学习框架、语料库与模型算法等也是从零训练。
腾讯解锁全链路自研,瞄准的既是运用自身的技术栈体系,实现根本的业务技术能力突破,也是利用自主体系的研发道路,更好地应对旗下海量高并发业务的冲击。
客观上讲,基于国外开源模型进行“本土化改良”固然是一条更容易的路子,可大模型既然是工业革命级的机会,只依靠国外的“开源模型”远不够。
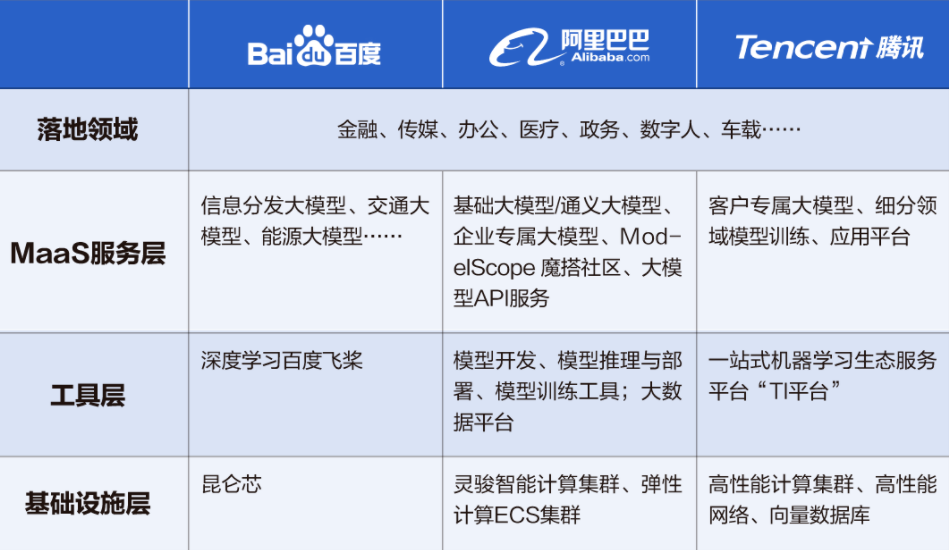
▲BAT大模型的对照。
腾讯集团副总裁蒋杰说:“外界其实一般多会用到知识图谱,甚至搜索外挂来让模型的检索支持能力变得更强,腾讯也会用,但不能用的比例很高。我们一定要在整个的大模型的预训练阶段把这个问题解决掉,控制掉。”依托自研的“探真”算法,混元大模型幻觉比例比其他开源大模型下降了30%到50%。
腾讯还在向外部推出大模型前,将其在腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ浏览器等50多个内部业务中先行验证。
先打磨好大模型产品,再拿出来服务行业产业,看上去,也是主打一个“实”。
04
实用取向,还得让大模型回归服务属性。
汤道生说:“从一个大模型,到提供一个用户可以感受到的服务,中间有很多的环节和工序。腾讯其实是提供整个端到端的AI服务流程中所需要的‘全链条工具’。我们的TI平台就是一个能满足整个工序、环节的需求,给客户提供高效模型搭建服务的重要工具。这可能是大家比较少从友商那里听到的。”
将基于自研的大模型技术能力开放,将其用于从田间到产线的很多角落,这注重的还是落地效果。
大模型很热,但本质上,大模型是信息化的下一幕。过去十多年的信息化对应的时代大幕上,写着的主题是“数字化”。大模型同样是数智化变革的助推器。
只不过,以往互联网发展撬动的是流通环节减少、流通效率提升,以AI为代表的数字化工具要介入的层次更深——其核心是要增加基础价值。
这就需要,将数字化触角伸向生产端与供应侧,覆盖包括从工业制造到冶金采矿、从港口运输到农林牧副渔的各行各业。
这对国内大模型的发展不无启示:自从ChatGPT面世后,中国大模型厂商跟OpenAI差距有多远,就成了行业关心的话题。
应用场景,或许正是中国大模型弯道超车的突破口。
国家信息中心专家张振翼就指出,当前美国在大模型发展中具备一定的领先优势,我国需要加强自身独特优势的探索。在他看来,当前我国发展大模型人工智能主要有三个方面的优势:应用场景资源极为丰富、数据要素政策设计较为领先、在相关领域的技术创新上已经具有一定积累等。
可以看到,在移动互联网时代,中国互联网企业就凭着衣食住行康乐教和产业领域的丰富场景,跑通了模式,做大了规模。
在今天,中国庞大市场上积累了海量数据,包括物流、电商、医疗等各个领域的,各个行业数字化转型的强烈需要,又为大模型落地提供了需求端支撑。
顺势而为,以实用实干之“实”,加速大模型的产业应用,中国大模型从跟跑到并跑再到领跑的图景,才会愈发可期。
作者:佘宗明
来源公众号:数字力场(ID:shuzilichang),抵抗熵增,打捞有趣。
本文由人人都是产品经理合作媒体 @数字力场 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









