
 起点课堂会员权益
起点课堂会员权益互联网时代,没有数据能力,你还怎么升职加薪?
在互联网行业,“数据导向”是一个非常大的特点,产品的运营与迭代都需要用到数据。那么,掌握数据分析能力能给帮助我们在职场上更胜一筹。业务同学掌握基础数据分析,只需要两步,一起来看看吧。
互联网行业一个非常大的特点就是「数据导向」,因为线上的服务和产品非常容易获取用户的数据,同时依赖这些数据,可以非常高效地迭代产品和相关线上服务。
因此,在互联网行业,数据能力是一项非常重要的能力,特别是对于运营,产品,增长等业务岗位。掌握必备的数据能力(SQL能力),是当今互联网各大厂的加分项,拥有数据能力的运营和产品更容易升职加薪,也更容易找到心仪的工作。
那么对于产品/运营/增长同学,需要达到真正的数据分析师的数据能力吗?我跟很多业务同学聊过,很多同学不愿意学习SQL,主要是觉得可能太复杂和专业,但其实不是这样的。
对于业务同学来说,我们没有必要花费大量时间完整地学习SQL语言和数据库知识。但是,从业务角度出发,日常工作中,遇到一些基础数据分析,业务同学如果能自己处理可以更加高效和直接,大大提高工作效率和业务判断专业度,而达到这种程度的数据能力,其实只需要熟悉SQL的一些业务高频使用场景,就基本能覆盖日常90%以上的数据工作。
我有幸跟几个头部大厂的专业的数据分析师/分析负责人讨论过,也在实际中在我们自己的团队里实验过,业务同学掌握基础数据分析,只需要以下两步:
第一步:花30分钟,阅读完下面的SQL基础语法知识介绍。
第二步:花半天,自主完成高频场景测试题。
第一步
1、数据基础概念介绍
首先,什么是SQL?
SQL,全称Structured Query Language(结构化查询语言),它本质是一种计算机语言,就像python,C++等计算机语言一样。但这种语言可以帮我们去数据库中查询我们想要的数据。
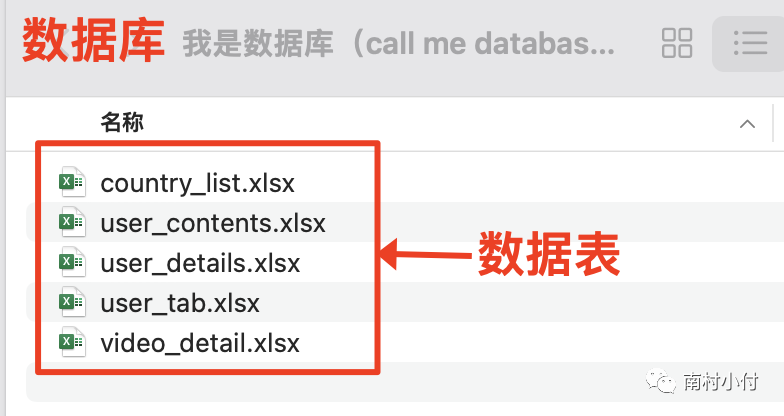
接着上述定义,我们再理解下什么是数据库,数据库可以简单的理解就是一个电脑的文件夹,这个文件夹里放着很多张数据表,数据表很好理解,就类似我们平时使用的Excel文件。
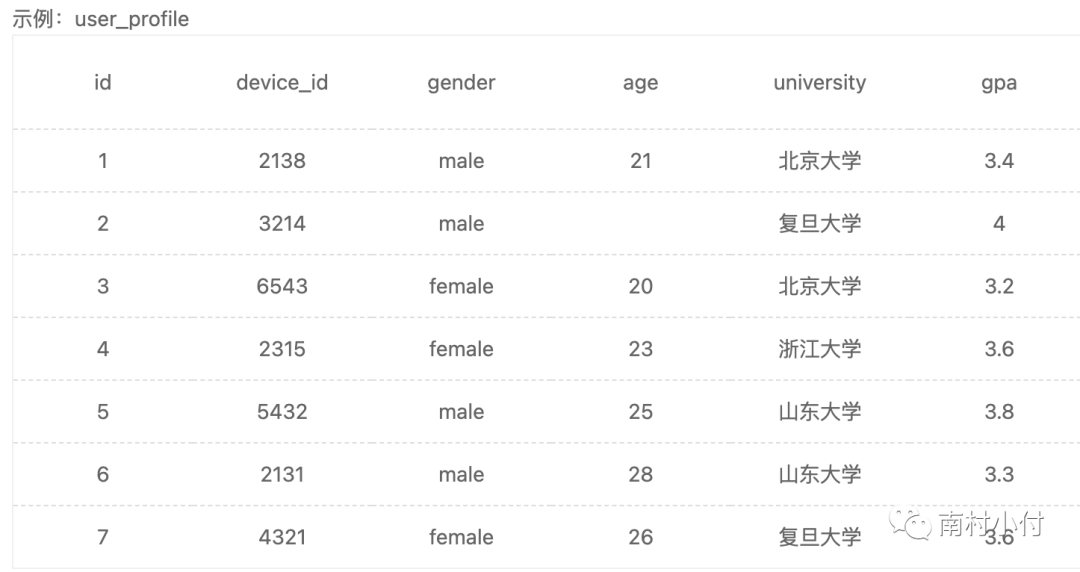
在数据表里,(也就Excel文件里),我们会有很多数据列,每一列一般都会有一个列标题,如下图所示,user_name, age, gender, scrore 这些就是字段,然后每个字段下面的就是具体的数据。

总结来说,我们一切数据/分析能力的基础:就是利用SQL语言从特定的数据表中,查询对应的数据字段,并做一定的后续处理,得到我们想要的结果。
以上就是最核心的三个概念:数据库,数据表和字段。
2、SQL基础语法介绍
SQL的基础语法组成如下,可以简单的理解成,我们通过这段代码,告诉计算机,我们需要FROM (从)某个数据表,去SELECT(选择)某些字段。选择的时候,可以加一些WHERE conditon(筛选条件),也可以进行适当分组,和结果排序,筛选处理。下面的语法中,中括号部分都是非必须的。

下面通过Case的方式给大家展示具体使用方法,帮助大家更好的理解这些基础语法。
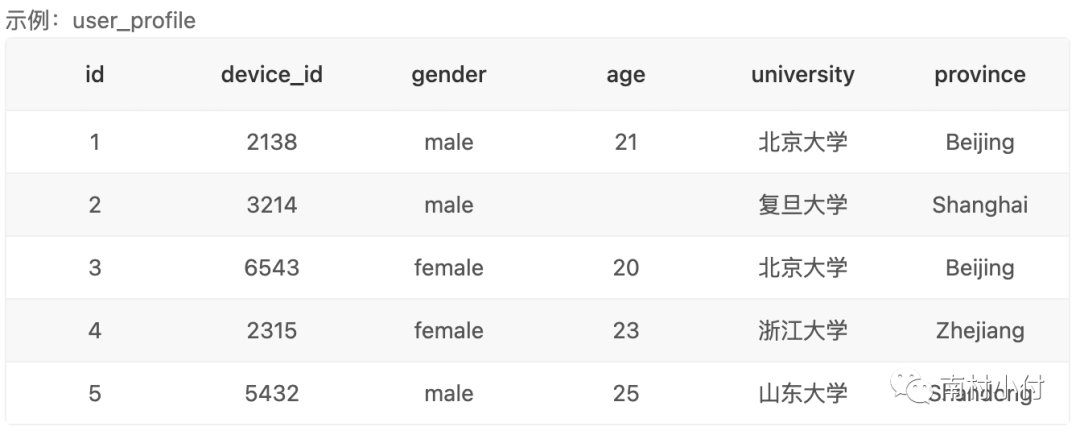
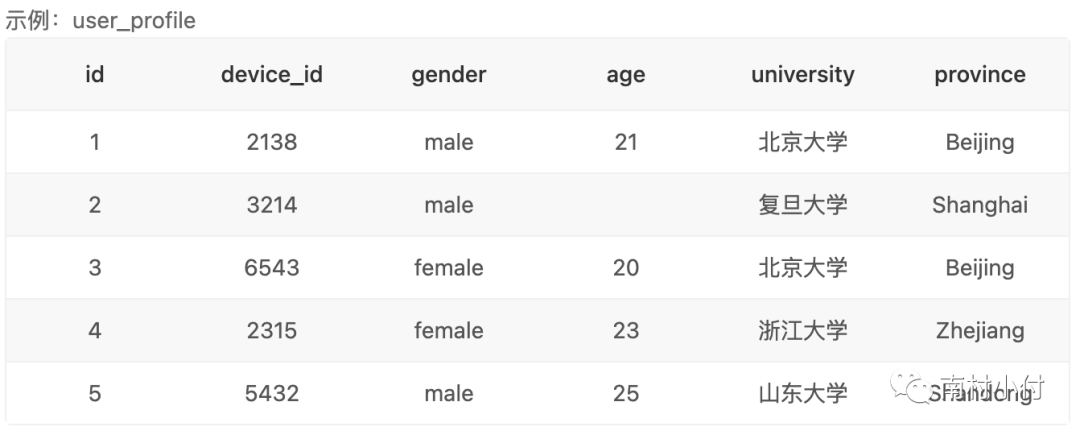
Case1、查询多列
从下图的user_profile数据表中,取出用户的设备id(device_id)对应的性别(gender)、年龄(age)和学校(university)的字段数据。
select device_id,gender,age,university //选择查询的字段
fromuser_profile //从指定的数据表中
得到的结果如下:
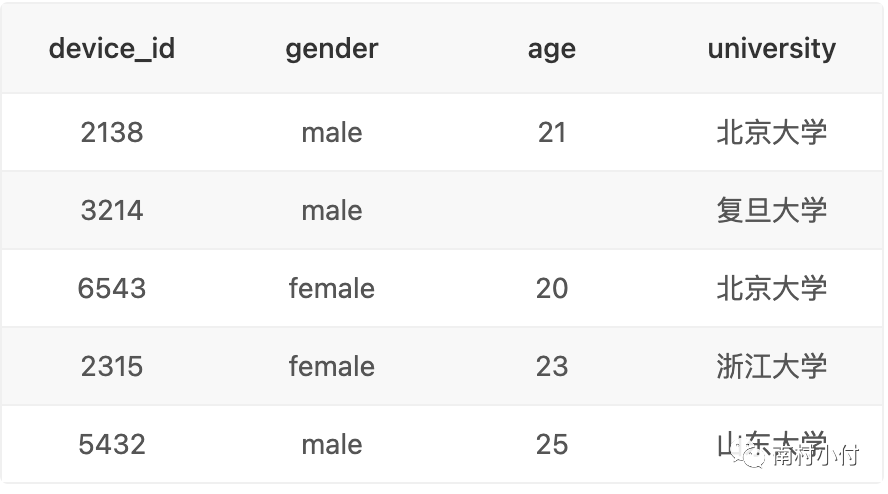
这就是最基础的select 语句,从特定表取特定字段的数据。
Case2、简单处理查询结果:限制返回行数/列重命名
从表user_profile中,查看前2个用户明细设备ID数据,并将列名改为 ‘user_infos_example’, 请你从用户信息表取出相应结果。
select device_idasuser_infos_example
from user_profile
limit 2
得到结果如下:

这里主要是通过 as 给取出来字段重新命名,同时limit限制返回的行数。
Case3、条件查询
从Case2中的user_profile表中,查询除复旦大学以外的所有用户明细,请你取出相应数据,并按照age进行从小到大的排序。
select*//* 代表所有字段
from user_profile
where universitynotin(‘复旦大学’)//where筛选条件,过滤复旦大学的数据
orderbyage//按照age进行排序,order默认升序
查询结果如下:

这里在取数前,使用where 条件来进行数据过滤,再通过age进行排序。
Case4、分组后条件过滤
从下面的user_profile查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
select university, avg(question_cnt) as avg_question_cnt, avg(answer_cnt) as avg_answer_cnt
// avg()是求列平均值的函数,将一列数据返回一个数值,这里在执行时,先用group by 对university进行分组,
// 然后avg()计算的为分组后的每个universtiy的发帖和回帖数的平均数
from user_profile
group by university // 以university进行分组聚合,把相同学校聚合在一起
having avg_question_cnt<2 or avg_answer_cnt<20 // having只能和group by一起用,用户分组计算后,对均发帖和回帖进行条件过滤
得到结果如下:

3、SQL多表查询
通过前面部分,我们大概了解了如何进行基础的表数据查询,在日常工作中,我们经常遇到的问题是,很多相关数据,不是都存在同一张表里,很多时候是分散在多个相关的表里,因此我们在查询的时候,就需要利用JOIN来联表查询。

如上表,我们需要查询users表中的device_id在devices表中的user_country信息。这个就需要继续联表查询。
语法如下:

得到结果如下:

已经将a表的device id和b表进行了关联。但1106这个device_id对应的b表的数据为null。这是因为什么呢?
这是不同join用法带来的差别。join有以下几种常见用法,前面示例代码中,使用了left join,也就是左关联,保持a表的device_id行数不变,从b表中,寻找相同的进行关联,如果关联不到,依然保留,但数据就为空。
和left join相对的就是right join,还是前面的例子,如果改成right join,结果如下:

除了left/right join之外,还有inner join(内关联)和full join(全关联)
效果分别如下:inner join,结果如下,只取两边都有数据的行,没有null

full join 就是a表和b表所有列都保留,具体结果,你尝试想想,答案私信我告诉你。
关于者几种JOIN还有一个更直观的示意图,如下图,JOIN的用法介绍,这篇文章讲解的更好,可以参考:https://zhuanlan.zhihu.com/p/29234064

为了更好地理解join,我们来看一个具体的Case
Case5、联表查询
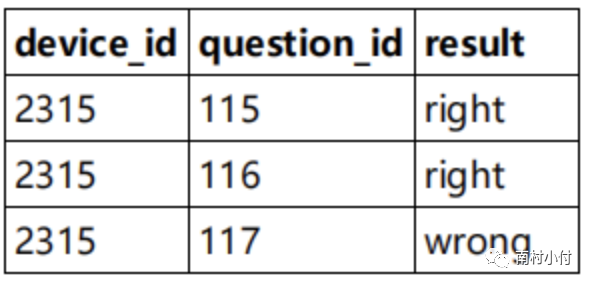
有下面两张表,question_practice_detail和user_profile,第一张表里,存储的是用户id,设备id和对应的答题的question_id,以及答题的结果result;user_profile存储用户的基本信息。现在要查看所有来自浙江大学的用户题目回答明细情况,请你取出相应数据,查询结果按照question_id升序。
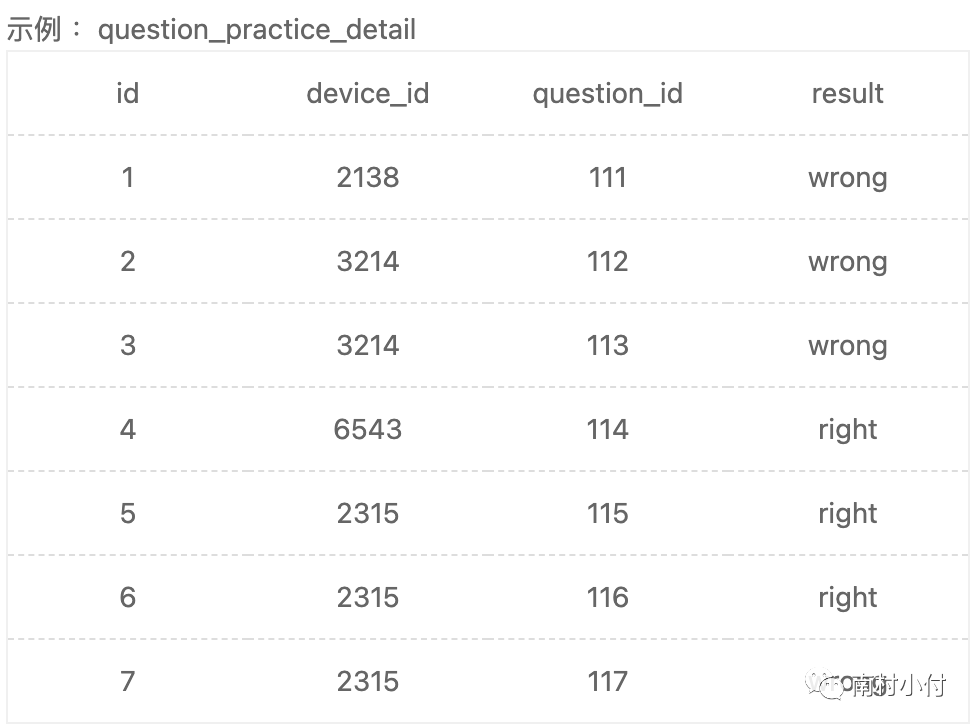

代码如下:

查询结果如下:
4、常用函数介绍
Case6、聚合函数(with 分组)
聚合函数就是将多行数据,按照一定规则聚合为一行,不能显示聚合前的数据。常见的聚合函数,比如count()–计数,sum()–求和, avg()–求平均,max()–求最大值,min()–求最小值等。
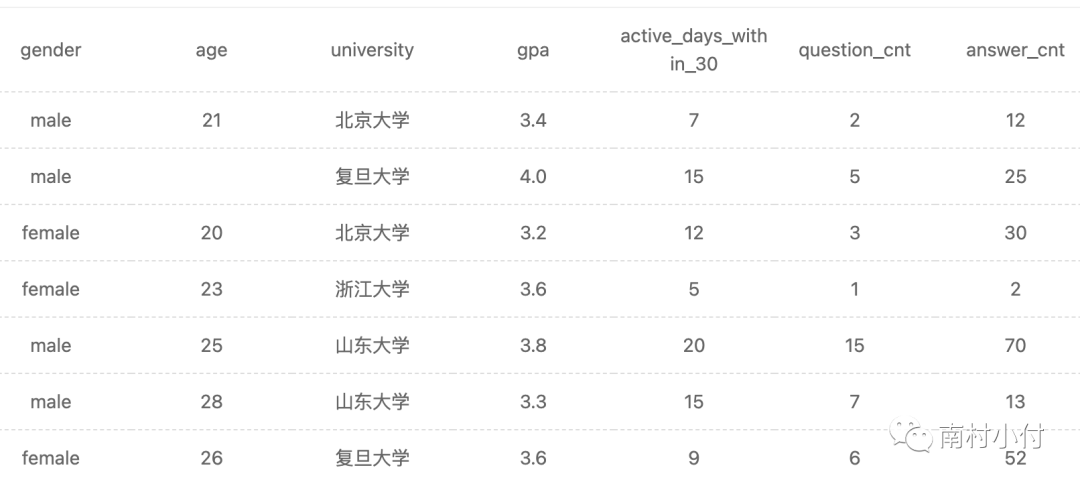
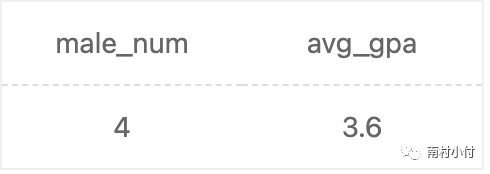
举一个简单的例子,要看一下下表中男性用户有多少人以及他们的平均gpa是多少?

具体方式如下:
select count(1) as male_num, avg(gpa) as avg_gpa
from user_profile
where gender=’male’
结果如下:
和聚合函数经常高频使用的是分组group by,如前面的例子,如果要统计不同学校男生的数量和平均gpa,就需要用到group by对学校进行分组,再用聚合函数进行计算。代码如下:
select universtiy, count(1) as male_num, avg(gpa) as avg_gpa
from user_profile
where gender=’male’
group by university
结果如下:

在大部分情况下,聚合函数都会搭配分组来使用。需要注意的是,执行顺序,是先按照分组(group by),再分组去执行聚合函数,得到每个分组的聚合结果。
Case7、窗口函数
在我们日常工作中,经常会遇到求分组内排名的问题,比如每个城市的TOP 100活跃用户,每个部门的绩效排名等。面对这种问题,就需要使用窗口函数来解决。
窗口函数的基本语法是:
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
在<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,包括rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum. avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
来看具体的例子:
从下面的user_profile表中,将每个学校分别按照gpa进行排名。
解题的思路就是找到,每个学校的gpa排名,然后分别找到排名第一的学生device_id, 先通过窗口函数找到每个学校的排名:
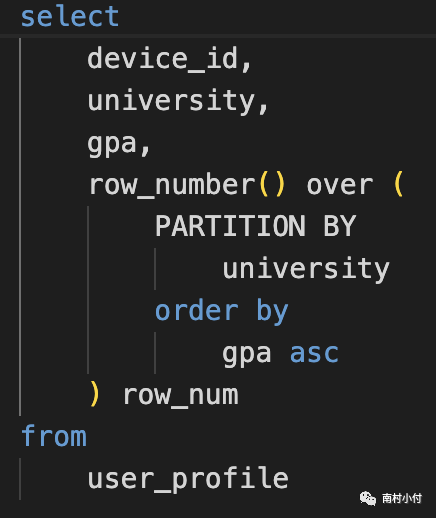
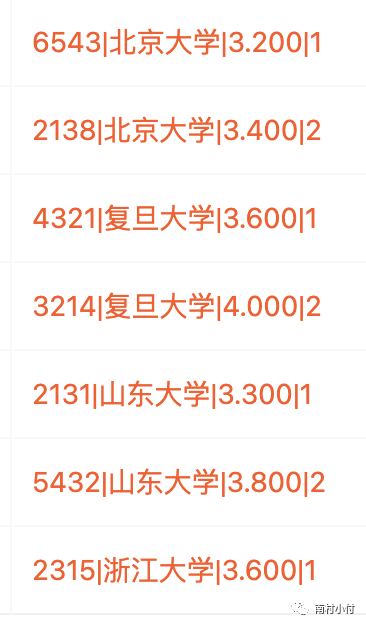
在窗口函数中,使用了row_number() 用来返回对应行的行数,因为每个窗口分组里,是按照gpa降序排列的,因此这里的行数就是排名数。
得到结果如下:
关于窗口函数,下面这篇文章讲解的更为详细,可参考:https://www.zhihu.com/tardis/zm/art/92654574?source_id=1003
Case8、条件函数
常用的条件函数主要有IF 和CASE WHEN,主要用于对查询结果进行条件判断。其中IF函数的语法是:
IF(条件表达式, 值1, 值2)
如果条件表达式为True,返回值1,为False,返回值2。
返回值可以是任何值,比如:数值、文本、日期、空值NULL、数学表达式、函数等。
CASE WHEN的语法是:
CASE WHEN condition THEN result1 ELSE result2END
我们来看一个例子:从下面的user_profile表中,将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量

分别用IF函数和CASE WHEN函数来实现:


结果如下:

第二步
在掌握前面step1部分的知识点后,下面当然就是开始刷题了,我为大家找了一些不错的在线刷题站点,建议收藏本篇文章,在pc端打开后,开始做题。
题库1: 牛客网的SQL练习:https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=199
题库2: leetcode :https://leetcode.cn/problemset/database/
题库3: https://sqlzoo.net/wiki/SQL_Tutorial
SQLZOO包括了 SQL 学习的教程和参考资料,支持多国语言,每一个语法配套一个教程、一份数据和一个测验,非常适合初学者使用,因为可以一边通过教程学习语法知识,再通过测验巩固。
后记
1、SQL入门比较简单,但想要真的写好,挑战很大,还需要多练习,在工作中多实战。
2、SQL本质还是一种取数的工具,对于数据能力更高的要求是明白需要取什么数,以及什么样的数能表征业务的状态或者发现业务存在的问题。
3、我整理常见的SQL取数和分析模板,有计算用户留存率,各种功能渗透率,用户活跃度分层分析等等。
专栏作家
南村小付,微信公众号:南村小付,人人都是产品经理专栏作家。快手高级产品经理,曾任职阿里,欢聚时代,7年互联网产品设计运营经验。
本文原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


