
 起点课堂会员权益
起点课堂会员权益AI分类模型评估指标:混淆矩阵、KS、AUC
分类模型的评估指标有混淆矩阵、KS、AUC等指标,而回归模型的评估指标又有许多。那么,怎么理解这些指标呢?这篇文章里,作者针对相关指标做了解析,一起来看看吧。

上文介绍了模型构建的5个环节,在模型验证环节,提到了评估模型性能的指标,其中分类模型的评估指标有混淆矩阵、KS、AUC等指标,而回归模型的评估指标有MSE、RMSE、MAE等指标。
今天我们就来详细了解一下分类模型的评估指标。
一、混淆矩阵
混淆矩阵是分类模型评估最基础的指标,我们可以通过混淆矩阵直观的看出分类模型预测准确和不准确的结果数量,进而简单计算出找到了多少比例的坏人(召回率)、找到的坏人里面真正坏人的比例(精确率)、模型判断正确的比例(准确率)等,而AUC、KS等高阶指标的计算也依赖于混淆矩阵的数据。
那么到底什么是混淆矩阵呢?
还是以前文的薅羊毛项目为例,当然薅羊毛项目是多分类模型,我们这里简化成二分类,便于理解。
我们选取了100名测试用户信息,其中有30个薅羊毛用户,我们称之为“坏人”,70个正常的“好人”。模型预测结果分数的范围是0到100分,技术同学给的参考阈值为60分,即60分以上的为“坏人”,60分以下的为“好人”。
输入到模型后得到了100个预测结果,假设模型预测出了40个坏人,在这40个坏人中,有25个预测对了,15个预测错了。
接下来,我们就可以把真实值和模型预测值,通过阈值得到的分类,填入到下表的混淆矩阵中:

混淆矩阵中,Positive表示正例,就是我们想要找出来的那个分类,Negative表示负例。结合薅羊毛项目,我们要找的“坏人”就对应了混淆矩阵的正例,“好人”对应了负例。
上表中得到了以下4种情况:
- TP(true positive):true表示模型预测结果是正确的,positive表示模型预测结果为正例(坏人),实际也是正例(坏人),那么TP值就是预测正确的坏人数=25人
- FP(false positive):false表示模型预测结果是错误的,positive表示模型预测结果为正例(坏人),实际上是负例(好人),那么FP值就是被误判为坏人的好人数=15人(被误伤、被误判)
- FN(false negative):false表示模型预测结果是错误的,negative表示模型预测结果为负例(好人),实际上是正例(坏人),那么FN值就是被误判为好人的坏人数=总坏人数30-预测正确坏人数25=5人(漏网之鱼)
- TN(true negative):true表示模型预测结果是正确的,negative表示模型预测结果为负例(好人),实际也是负例(好人),那么TN值就是预测正确的好人数=总好人数70-被误伤的好人数15=55人
所以,T和F代表模型预测结果的对错,P和N代表模型预测结果是正例还是负例。
理论上,我们期望模型的TP值尽可能大,同时FP值尽可能小,就是尽可能多的找出真坏人,同时尽可能少的误伤好人。
以上就是混淆矩阵的简单介绍,我们会发现混淆矩阵中都是具体的数值,而数值是无法直接评估模型的好坏的,所以我们会在此基础上,延伸出以比率来形容模型好坏的多项指标。
二、混淆矩阵的评估指标:准确率、精确率、召回率、F1
- 为了更直观的评估模型,我们基于混淆矩阵延伸出了以下指标:
准确率(Accuracy):表示从全局的角度,模型分类正确的比率。模型正确分类人员(TP+TN)占全部人员(TP+TN+FP+FN)的比例,准确率=(25+55)/(25+55+15+5)=80% - 精确率(Precision):表示模型预测精度的指标。模型找出的总坏人数(TP+FP)中,真坏人数(TP)所占的比例,精确率=25/(25+15)=62.5%
- 召回率(Recall):也叫查全率,是判断模型预测广度的指标。模型找出的真坏人数(TP)占实际总坏人数(TP+FN)的比例,召回率=25/(25+5)=83.33%
准确率可以从全局的角度描述模型正确分类的能力,但在样本数据不均衡的情况下,无法区分TP和TN的实际贡献分别是多少,全局的准确率并没有很强的“说服力”。
精确率用来描述模型识别的精确度,在扫脸、指纹识别等确定性要求较高的场景下,“宁缺毋滥”,可以侧重考虑精确率的指标。
召回率用来描述模型识别的广度,在薅羊毛项目的场景下,我们就要求“宁可错杀一千,不可放过一个”,追求“除恶务尽”。
需要注意的是,精确率和召回率大概率是成反比的,想提升精确率,那么召回率就可能受影响,反之亦然。所以我们要结合具体的业务场景,找到两个指标的平衡点。
而F1值就是用来综合反映精确率和召回率的指标,F1=(2 x 精确率 x 召回率)/ (精确率 + 召回率),该值越大,说明精确率和召回率的综合表现越好。
三、构建KS和AUC的基础指标:TPR、FPR
KS和AUC是分类模型中常用的两个综合性指标,计算它们依然需要依赖混淆矩阵的基础指标:TPR和FPR。
- TPR(True Positive Rate):也叫真正率、真阳率、灵敏度(Sensitivity),用来评估模型正确预测的能力。也就是模型找到真坏人(TP)占实际总坏人数(TP+FN)的比例,即 TP/(TP+FN),细心的朋友可能会注意到,这个公式就是召回率的公式,所以TPR也可以叫做召回率。
- FPR(False Positive Rate):也叫假正率、假阳率,用来评估模型误伤好人的比率。也就是被模型误伤的好人(FP)占实际总好人数(FP+TN)的比例,即FP/(FP+TN),也可以叫做误伤率,更好理解一些。
四、绘制ROC曲线&计算AUC指标
构建模型的目的,肯定是期望尽可能多的找出真坏人,同时尽可能少的误伤好人,也就是TPR越高越好、FPR越低越好。
ROC曲线就是用来表达TPR和FPR之间关系的曲线,接下来我们来看一下ROC曲线的绘制过程。
刚才得到混淆矩阵数据的时候,技术同学给了一个参考的阈值60分,我们根据阈值计算出了混淆矩阵的各项指标。
假设我们没有确定的阈值,我们可以每10分进行分段(0、10、20、…100),逐一作为阈值,来分别计算TPR和FPR。那么情况大概有以下三类
- 阈值为0分时,即所有人的分数都超过阈值,所有人都被判断为好人,此时没有找到任何坏人,即TPR为0;没有任何好人被误判为坏人,所以FPR为0
- 阈值为100分时,所有人都被判断为坏人,此时所有坏人全部落网,即TPR=1;所有好人全部被误判为坏人,即FPR=1
- 阈值为0到100分之间的分数时,每一个阈值都会得到对应的TPR和FPR值,比如TPR=0.7,FPR=0.4
我们依次把阈值依次定位0、10、20,一直到100,就会得到一串TPR和FPR数据的集合,然后我们把FPR作为横轴,TPR作为纵轴,把这些点在坐标系中连起来,就可以得到一条ROC曲线:
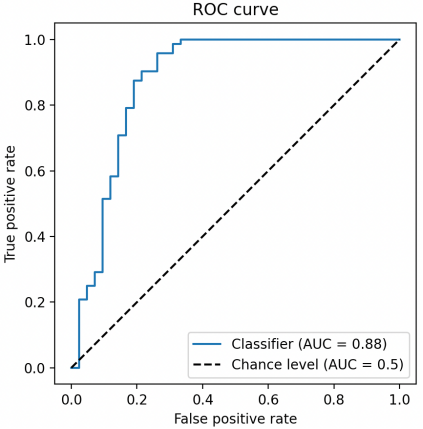
图中蓝色的曲线就是ROC曲线,图中的虚线是随机线,随机线上每个点TPR和FPR的值都是一样的,和瞎猜的效果差不多,所以我们以随机线为基准,ROC曲线越贴近于随机线说明效果越差,越贴近于左上方,说明效果越好,因为这意味着TPR更大,FPR更小。
我们可以把两个ROC曲线放在一个坐标系内做比较,确实可以看出来哪个模型更好,但是图像化的比较方式依然不够直观,所以我们需要想办法将ROC曲线转化成一个数字,方便沟通和比较。
这个值就是AUC指标,AUC指标其实就是ROC曲线右下方和横坐标轴闭合起来的面积大小,这个面积越大,意味着越靠近左上方,召回率越大且误伤率越小,效果也越好。
五、KS指标
KS曲线与ROC曲线非常相像,二者区别如下:
- ROC曲线的横轴与纵轴分别是混淆矩阵中的FPR与TPR。而线上的每一个点,都是在不同阈值下得到的FPR与TPR的集合
- KS曲线就是把ROC曲线由原先的一条曲线拆解成了两条曲线,原先ROC的横轴(FPR)与纵轴(TPR)都在KS中变成了纵轴,而横轴变成了不同的阈值
这样我们就可以得到如下的KS曲线:
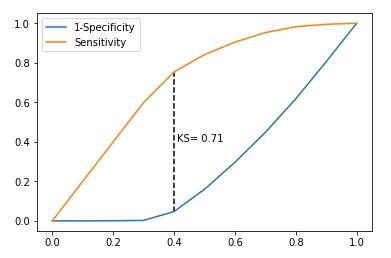
我们简单了解一下纵轴的两个指标:
- 灵敏度(Sensitivity),前面提到过,也就是TPR,对应图中的黄色曲线
- 特异性(Specificity),也称为真反例率(True Negative Rate,TNR),是真反例占所有实际为反例的比例,其计算公式为: Specificity = TN / (TN + FP),而FPR=FP/(FP+TN),所以FPR=1-Specificity,对应图中的蓝色曲线
总的来说,KS曲线是两条线,其横轴是阈值,纵轴是TPR与FPR。两条曲线之间之间相距最远的地方对应的阈值,就是最能划分模型的阈值。
而KS值是MAX(TPR – FPR),即两曲线相距最远的距离。
不同的产品,合适的KS值范围都不一样,需要结合实际情况去摸索。
一旦确定合适的KS值范围之后,如果模型的KS值过低,说明模型欠拟合,基本不可用,但KS值非常高也不一定是好事情,我们可能需要分析原因,判断是否是因为数据问题导致的异常情况。
总结
本文介绍了分类模型常用的评估指标,让大家对模型评估有了一个初步的概念。
下篇文章,我会详细介绍回归模型的评估指标,敬请期待。
本文由 @AI小当家 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









有一点没懂,如何确定阈值?
阈值是自己根据业务情况定的,比如你们可以自己定50分,那么模型预测结果为55分时,判断为positive,但是如果你们定的60分为阈值,那同样的预测结果就判断为negative了。阈值到底定多少应该可以通过计算不同阈值对模型结果准确度的影响来反推出最合理的阈值。应该是这个意思。
现实中你可以直接知道这个人是好人还是坏人,但是在系统中系统不知道,系统只会判断。
根据算法对一个人的特征打分,0-100分,此时你要告诉系统究竟多少分是好人和坏人的分界线,但是你也不知道,你需要一套判断依据定一个最优解。
判断依据就是召回率(准确率)尽量高并且误杀率尽量小,这就是AUC(算法没看懂)。
你先拿0进去试(高于0分就是坏人),计算AUC1;再拿0.1去试,计算AUC1;再拿0.2去试,计算AUC3……..找出一个最大的AUC,对应的投入的值就是阈值。