
 起点课堂会员权益
起点课堂会员权益“文心、通义和混元”们的2023:道阻且长,仍向远方
作为LLM应用爆发的这一年,国产AI在今年基本上是全面开花,不做个大模型都不好意思出去打招呼。2023年已经结束,在在AI发展的三驾马车——算力、数据、算法上,“国产派”遇到了哪些问题,取得了哪些突破,又有着怎样的思考?我们来看看作者如何分析。

随着2024年的钟声即将敲响,站在这个历史的节点上,回望过去一年,发展、进步、改变、革新最大的行业非人工智能莫属,AI的快速进步如同翻江倒海一般,激荡着无数的可能性。
其中,2023年里国产大模型的喷涌出现和快速发展,作为最引人瞩目的焦点,为我们每个人的工作与生活带来前所未有的新奇体验,并开启了一波AI发展的浪潮。
它们的出现,标志着人工智能从单一的任务处理,朝着多任务、复杂任务甚至多模态任务处理的方向迈进。这些大模型不仅能够理解和生成人类的语言,还能够理解和生成图像、视频等多种类型的数据,甚至能够在多个任务之间进行迁移学习,展现出了惊人的灵活性和适应性。
然而,能力的跃迁进步,并不意味着大模型的发展就能一帆风顺。
庞大的参数量和计算需求,使得训练和部署这些大模型成为了一项极具挑战性的任务,而国产大模型在算力层面被封锁、的情况下则显得更加窘迫。同时,大模型强大的能力与真正落地生产生活也有着不小的距离,如何能将其快速、准确、低成本地投放至应有之处,也成为了众多大模型厂商们思考的问题。
尽管如此,我们不能否认大模型带来的巨大潜力。它们为我们打开了一个全新的世界,让我们有机会以前所未有的方式理解和利用数据。
那么,回望2023年,在AI发展的三驾马车——算力、数据、算法上,“国产派”遇到了哪些问题,取得了哪些突破,又有着怎样的思考?在百模大战甚至千模大战的背景下,各家厂商推出了怎样的大模型?面对大模型能力投放难、落地难的问题,企业又该如何解决呢?
一、大模型三驾马车发展情况
在前置端,算力、数据、算法作为大模型的三大支柱,都是不可或缺的因素,在2023年中,它们在各自的道路上都有着长足的进步,也面临着不少的发展困难。
其中,算力作为实现大模型的基础,发展基调可以用“外部制裁,内部发展,夹缝求生”来概括。
2022年8月底,美官方命令芯片厂商英伟达停止向中国销售部分高性能GPU,而另一家超威半导体也收到了相关的禁止命令。
而在一年之后的10月17日,美国商务部继续延长了2022年10月首次实行的全面出口管制,继续收紧对尖端人工智能芯片的出口管制,在新规之下,英伟达旗下最新的H200自然无望卖给中国,就连在去年新规管制之后专门为中国设计的“特供版”GPU A800与H800,也将无法进口。
同时,伴随着管制规则的更新,除去直接可用的产品外,还扩大了芯片制造工具出口限制清单,中国的两家国产GPU制造商——摩尔线程、壁仞科技均被列入“实体清单”,大模型发展的必备算力,受到了极大的限制。
但也正是在此次禁令的推动之下,国产GPU芯片终于不再被NV与AMD两家“骑在头上”,得到了快速发展的最佳窗口期,其中华为昇腾、寒武纪思元等国产加速芯片也在本次禁令的推动之下迎来春天。
在与华为有关人士的交流中,对方表示,华为昇腾910于2019年发布,并于今年10月发布了最新的910B芯片,相比于上一代获得了FP32的性能提升。而科大讯飞副总裁江涛在Q3业绩说明会也透露,目前华为昇腾910B能力已经基本做到可对标英伟达A100。
但在谈及昇腾910B的应用时,对方也表示昇腾还有着许多急需进步的地方,例如当前的互联网公司更加追求性价比和易用性,而目前华为的服务器产品还是以鲲鹏为基础,导致了业务迁移的高成本,所以目前还处于前期的POC阶段,真正的上量起码要在2024年或更久的未来。
除被认为是“中国NV”的华为昇腾外,被称作“中国AMD”的寒武纪也在加码AI算力芯片的研发和推进。
据媒体报道,百度内部的测试结果显示,寒武纪最好的产品思元590,最高性能已经接近A100 90%的性能,综合性能也与A100 80%的水平相差无几,但由于寒武纪采用了ASIC的架构,导致通用性较差,当前仍然无法大规模地投入到训练之中。
而在华为与寒武纪之外,其实还有很多很多的国产厂商在大力推进AI芯片的发展,譬如海光的DCU、天数智芯的天垓100、燧原的云燧、璧仞的BR100,都有着很强的竞争力,作为后发者,虽然在能力和适用性上与英伟达最新的加速卡相比可以称得上有天壤之别,但也在通过不断的技术创新和市场拓展,展现出自身的竞争力。
与国产厂商大力推进AI芯片进步的同时,面对着当下海量的需求和短期内只会越来越强的AI芯片封禁,中国几大公有云厂商也在通过“集中算力,以云代卡”的方法解决算力问题。
“集中算力,以云代卡”,顾名思义,就是将很多AI芯片汇集到一处地方,再通过云的方法将算力传输至需要的地方,这样可以提高算力基础设施的质量与效率、实现资源的优化配置与共享,这也是为什么2023年中小企业很难拿到加速卡,而是由几大公有云厂商竞争搭建算力池的原因。
根据IDC数据,2023上半年中国AI服务器已经使用50万块自主开发的AI加速器芯片。华为已经推出昇腾AI云服务,提供自主AI算力服务。在东数西算背景下,各地建立一批采用自主AI算力的AI计算中心,保障云端AI算力稳定可靠供给。
总的来说,算力作为被围追堵截最严重的地方,2023年国产大模型厂商们也在东拼西凑之中拮据存活了下来,但面对着越拉越大的算力差距,将会更明显地成为中国AI追赶世界顶尖水平的绊脚石,所以在未来算力层面的企业也将会被多次拉出炒作,可注意相关投资机会。
如果说算力决定了大模型是否能面世,那么数据才是决定大模型优质与否的关键要素。
所有人都明白,数据数量越多越好、数据多样性越多越好、数据质量越高越好,所以目标是一致的,而方法也相差不大。
而目前国内科技互联网头部企业主要基于公开数据及自身特有数据差异化训练大模型, 譬如百度文心主要依靠的是万亿级别的网页数据、搜索数据,阿里通义则主要来源于阿里达摩院,腾讯混元的训练数据大多取自微信公众号、微信搜索等处,但此类信息大多都有着互联互通,所以截至目前,国内大模型整体的数据规模、质量也不会相差甚远。
但有一个在发展第一年中尚未察觉的隐患,那就是高质量的语言数据与图像数据或将耗尽,据机构预测,全球英文语言数据将于2030~2040年耗尽,其中能训练出更好性能的高质量语言数据将于2026年耗尽。
与英文语言数据相比,中文优质数据集更加稀缺,尽管国内数据资源丰富,合成数据也有不少,但由于挖掘不足导致优质数据无法在市场上自由流动,未来如果厂商想要大模型更进一步,或许就需要将资金投入至寻找优质数据的道路中,未来手握巨大优质数据的如知乎、豆瓣等企业,与挖掘、合成数据的企业,也将获得一定的发展空间。
而在算法层面,当前许多都是基于谷歌提出的Transformer模型构建的,仍在不断地更新迭代中,但这并非是一定一成不变或必须要走的道路。
在AICC 2023人工智能计算大会上,浪潮信息人工智能软件研发总监吴韶华表示,如果想接近甚至超越GPT4的能力,一定要同时考虑算法和数据。首先是算法,不能一味地使用LIama结构或者Transformer结构,而不做任何创新。
譬如,在考虑到算力不足之时,在相同的架构下可以尽可能地降低参数量,这样能提升参数效率,也能节省算力,相当于从算法层面考虑算力的开销,而此类算法更新改进的思路,也是大厂们一直在做的事情。
二、模型进步双轮驱动 基础与行业并重
而在底层技术迭代的同时,各家大模型不断地发布自然成为了最引人注目的事情。
继3月百度发布文心大模型以来,围绕在我们耳边的一直就是华为、阿里、腾讯等互联网大厂,三六零、科大讯飞等AI企业,还有清华大学、复旦大学等高校科研机构推出的大模型及相关升级进展,截至目前,市场上出现的各类大模型已经超过240个,正在供用户们使用。
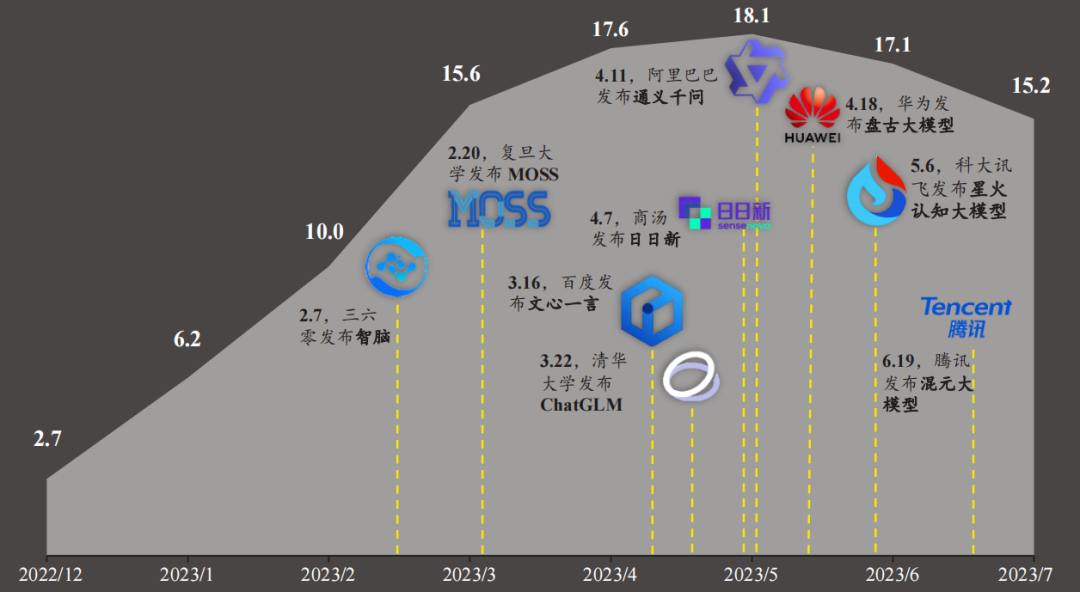
图源:头豹研究
但这么多的大模型,从属性上来进行区分,一般都可以分为基础大模型和行业大模型两大类。
其中,基础大模型是指通用性强、适用范围广的大模型,可以用于多个领域和任务,也可以在其基础上进行特定数据的训练与调教,使其变为朝向某个方向或某个行业的专用大模型。
但基础大模型的入场门槛较高,往往需要大量的计算资源和训练数据方可进行开发和优化。以当前国内能力最强的基础大模型——文心大模型为例,其参数量已经飙升至万亿级别,相关算力也是由万卡AI集群提供,相关的成本大幅增加。
同时,在具体的落地使用方面,很多人会发现历经一年打磨、升级后的文心4.0、迭代后的通义千问、进步后的混元大模型的能力与一些行业专有大模型甚至都有着一定的差距,便认为基础大模型的能力或许没有那么重要,训练好每个行业的大模型快速应用于生产中才是正道,但这样的想法是十分错误的。
与行业大模型相比,基础大模型的参数量超过某个阈值后,AI效果将不再是随机概率事件,此时再将其训练为行业大模型,将更容易获得准确的结果。同样的,基础大模型也是其下所有行业模型的中心与核心,只要“大脑”有任何哪怕一丁点进步,都会引起整个模型群能力的提升,以百度为例,文心大模型4.0升级将会提升所有千帆智能平台上的行业模型的落地能力。
此外,行业模型大多依靠人工标注与调优,有着成本高、周期长、效率低的缺点,但基础大模型则能够进行自我学习、自我监督、自我更正,可以显著地加速训练成果,还能总结不同情况下的通用能力,如此训练才有机会让电影里无所不知的人工智能的落地成为真正的可能。
所以说,在基础大模型尚不牢靠之时,就放弃基础大模型的探索转向行业大模型的发展实在是有“短视”之嫌,持续加码基础大模型的或许将为未来行业大模型的发展起到事半功倍的作用。
但作为门槛极高、花费极大的赛道,就交由大厂们去卷吧,而我们在2023年中也能欣慰地看到,BAT、华为等大模型第一梯队企业,在布局行业大模型、应用生态的过程中,并没有放松加速迭代基础大模型的速度,而未来伴随着基础大模型的突破,中国大模型的能力有机会得到“飞升”的机会。
不过,基础大模型的建设固然重要,但是并不影响行业大模型的发展,与之相反的是,在巨大对于大模型能力的需求之下,年内,在金融、消费、能源行业中,都有着十分优秀的落地案例。
在金融行业中,百度旗下度小满以“通用大模型+自有行业数据”的方式构建了金融行业的垂直大模型“轩辕”。
在金融应用场景中,传统的通用大模型由于其训练数据很少接触金融行业内的专业术语、业务逻辑和公式计算,导致其在具体问题上表现不佳。
而“轩辕70B”的强项就在于其专业的金融能力,受益于预训练和微调阶段中海量金融专业语料库的训练,无论是注册会计师考试(CPA)、银行/证券/保险/基金/期货从业资格、理财规划师、经济师等金融领域十大类权威考试,都能提供专业的支持和解答。
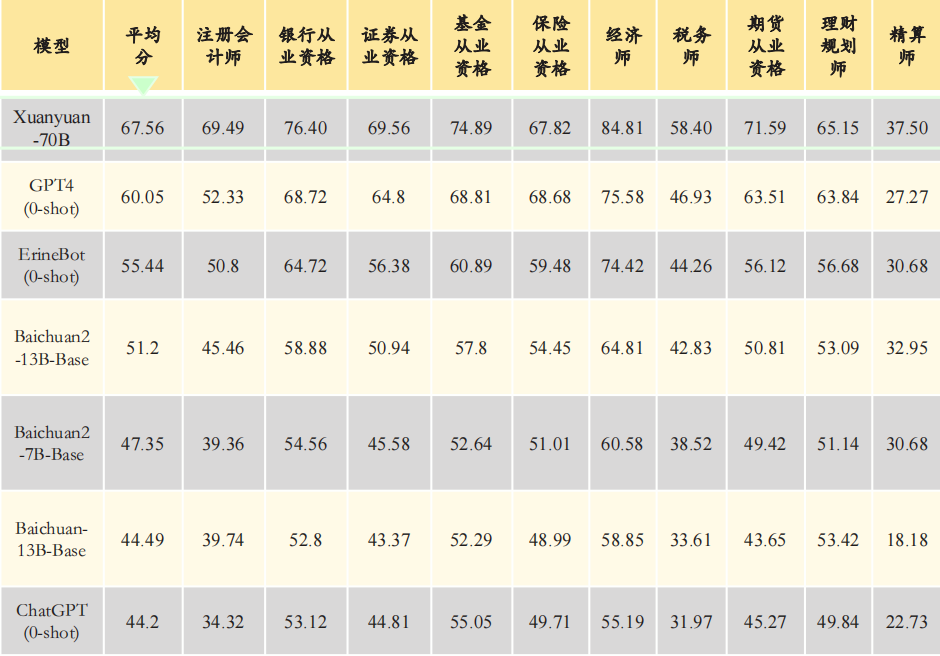
图源:头豹研究院
但轩辕能扮演的角色更像一个助手,提供的价值更多停留在工具层。而在未来,伴随着金融行业大模型数据合规、隐私安全等问题得到解决后,将会应用于交互性更强的场景,赋能金融行业的数字化发展。
而在泛消费领域中,阿里、京东等依靠电商起家的大厂,都有着客服机器人、营销数字人等行业大模型的应用。
在电商中,客服一直是最为依赖人工的环节,在双十一、六一八等购物节期间,需要24小时保持即时回复,也因为依赖人工,导致客服团队的效率极低、难以满足客户需求。
但今年双十一期间,京东与淘宝等平台都引入了智能客服,以京东为例,“京小智”可以几十分之一人工的价格,为用户提供即时的服务,而在接入京东言犀大模型后,可以与消费者丝滑交流。
在智能客服外,在直播中京东数字人也让人眼前一亮,其形象可以根据企业需求进行定制,音色、形象、身高、体型等项目都可以根据企业需求进行个性化设置,可以与真人主播搭配轮班,甚至完全替代真人主播。

京东数字人
此外,导购服务也是大模型接入电商行业后带来的新功能,今年9月淘宝接入通义千问后,淘宝问问可以面向C端用户提供智能导购服务,只要消费者问出相关问题,AI可以迅速给出所需购买的产品、相关视频介绍、商品链接等,成为新的流量入口,让商家、平台和消费者完成三赢。
而在更加“硬核”的能源行业生产场景中,华为与商汤科技等厂商则有着很深的造诣。
在能源电力行业中,从业者过去常常面临一个问题,如何将在能源紧缺时分配至最需要的地方,又如何在能源充裕时储存起来,这就涉及到了虚拟电厂的调度问题了,而引入大模型后,可以对电力供给、需求端进行精确的把控,起到“削峰填谷”的作用。
据头豹研究院报道,目前华为、商汤科技等厂商开发出的针对电力行业的AI大模型已经投入了应用中。
例如,华为基于L1级别盘古电力大模型,推出无人机电力巡检、电力缺陷识别等场景模型。商汤科技则基于AI大模型的底座,提供电力系统大模型解决方案,向电力能源行业持续输出高质量的AI算法和算力,赋能电力系统多域智能化升级。
这样的行业大模型及具体的应用还有很多很多,而这只是其能力落地的第一年,未来还会有更多的应用出现在我们身边,并伴随着大模型能力的进化而不断迭代,并经历神化到祛魅的完整过程,真正成为人类的最好帮手。
三、云模结合的新投放方式——MaaS加速生长
伴随着2023年中各家大模型的密集发布与快速成长,一个新的问题摆在了各家大厂的面前,那就是如何将大模型的能力简单快速地投送至其应处的地方,毕竟如果在产业落地的环节出了问题,那么有关大模型的一切都只是空谈。
但也就在此时,MaaS(Model as a Service)——模型即服务的概念,火了起来。
MaaS是指将大模型封装成可调用的云服务,通过云计算平台提供给用户使用,这种服务化的模型部署方式通过将模型和计算资源放置在云端,用户可以通过简单的API接口调用模型,无需关注底层的模型训练和部署细节,同时可以根据需求自动扩展计算资源,实现弹性扩展和高可用性。
而像MaaS这样将AI同云结合后再投放的形式,无论从需求、供给还是已有的云基础设施建设来看,都有着出现的必然性。
从需求端来看,当前企业仍然处于朝向数智化转型的阶段中,许多生产场景都如干涸的土地一般,在等待人工智能的雨露助力效率的提升;而在供给端,受计算资源与存储资源的影响,无法做到“家家有卡,人人会用”,只能采用集中算力再投放的方法;而在基础设施端,在过去十年中,我们已经搭建起了一套有关云的完整体系,而MaaS刚好可以作为SaaS的替代品接替上位。
于是,截至目前,几乎所有兼备云和大模型的厂商都发布了自己的MaaS平台——百度千帆、字节火山方舟、腾讯云MaaS平台、阿里云MaaS平台……都已经推出。
以百度千帆为例,其内置了百余款Prompt模板,包含对话、编程、电商、医疗、游戏、翻译、演讲等十余个场景,相关企业可以直接选择某一个模型或者在已有模型的基础上再根据自身的要求加入数据进行微调。
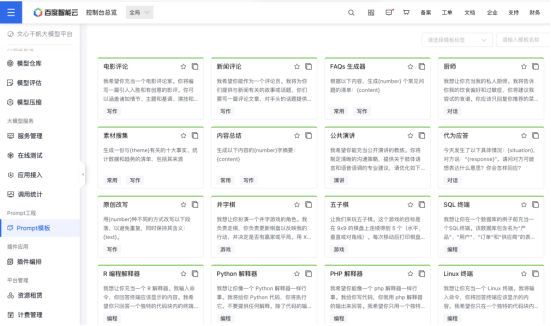
腾讯云MaaS的服务也大抵相同,可为金融、文旅、传媒、政务、教育等10大行业提供了超过50个大模型解决方案,供客户调用。

而在百度与腾讯之外的其他MaaS平台,建设思路与打法也都大同小异,都是利用基础设施和行业理解的优势,提供一整套的开发工具与套件,保证不同体量不同需求客户的完美交付。
但是,2023年MaaS的发展还远远称不上完备,最多只能说是搭起了往后发展的模板,仍然还有着很多很多需要更迭的地方。
其中最让厂商们头疼的点,就是基础大模型与行业大模型之间的鸿沟。俗话说的好,“三百六十行,行行出状元”,但在现实生活的行业中远远不止这个数字,让大厂们去卷基础大模型还好,但要让那数万甚至数千的开发人员去接触每一个行业,定制每一个方向的专用大模型,无异于痴人说梦。
而这就需要真正的从业人员参与到其中,但这个难度也着实不小,可以说这个问题还将困扰厂商、行业甚至社会很久很久的时间。
此外,MaaS本身作为一种云服务模式,算力是其提供服务的基础,随着MaaS的发展,云服务市场对算力的需求呈现爆发式增长趋势,厂商们尚未跑通的商业化逻辑、大模型逐渐增长的数据还有价格逐渐增加的算力,成为了限制MaaS发展的一大难题。
而在这两大痛点之外,用户的教育也需要时间来堆砌。
据脑极体报道,包括了数据标注、训练、评估、测试和部署等全套工具的腾讯云TI平台,即使交到了行业客户和伙伴手中,没有技术专家深入指导,没有产品经理、项目经理、运营、程序员等手把手教学,很难搞定定制化需求。
但无论怎么说,MaaS这样的服务模式正处于发展的早期阶段,尚未形成较为成熟的模式,未来大厂们若跑通商业模式,算力紧缺问题有所解决,客户教育逐渐进步,属于MaaS的春天才正式来到。
四、写在最后
2023年,对于国产大模型的发展来说是充满机遇与挑战的一年。在算力、数据、算法等“AI三驾马车”的推动下,国产大模型取得了显著的进步,但同时也面临着诸多困难。
但令人欣慰的是,大模型作为这样一个新兴事物,快速完成了商业模式的基础闭环,虽然当前仍有重重困难,但在起步之年能做到此种程度已经体现了国内互联网、科技大厂们的实力。
而在未来,伴随着底层技术、大模型能力、投送能力和商业化模式的进一步发展,人工智能将不断深入我们的生活当中,成为每个人都可借用的强大生产力工具。
参考资料:
1.《MaaS,云厂商在打一场“翻身仗”》,脑极体;
2.《云计算服务新范式:MaaS有望改变云服务厂商的商业模式》,赛迪顾问;
3.《英伟达A800、H800将被出口管制,国产GPU能否顶起一片天?》,科技云报道;
4.《AICC圆桌对话:打破跟随,实现大模型创新能力突破 》,科技知多少;
5.《数据要素专题研究报告:大模型与数据共振,数据要素市场方兴未艾》,国金证券;
6.《2023年中国AI大模型应用研究报告》,头豹研究院。
作者:叶子,编辑:钊
来源公众号:奇偶派(ID:jioupai),讲述商业故事,厘清商业逻辑,探索商业模式
本文由人人都是产品经理合作媒体 @奇偶派 授权发布,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


