
 起点课堂会员权益
起点课堂会员权益SuperApp的未来展望:吴恩达预测的社区如何与AI共生
吴恩达:我们需要社区。拥有朋友和盟友的人比孤身前行的人表现得会更好。即便人工智能领域每周都带来突破性进展,拥有朋友帮助你分辨真实和炒作、测试你的想法、提供相互支持,并与之共同创造,将使你处于更有利的地位。

在上一篇(非共识解读:Perplexity.AI vs 天工AI)文末,小编抛出了关于基于大模型的知识搜索能力,在国内C端市场通过构建从“工具价值(低溢价)→ 流程价值(低溢价)→ 知识价值(高溢价)→ 人脉价值(高溢价)”的SuperApp的产品idea。由于上一篇的篇幅问题,没有针对这个产品idea 进行展开分享。恰好这两天看到吴恩达老师的“2024年预测:关于AI,这些事未来十年不会变”中提到的“AI社区”重要性。小编就此也延续上篇最后的话题 “SuperApp:知识共享&交易”。
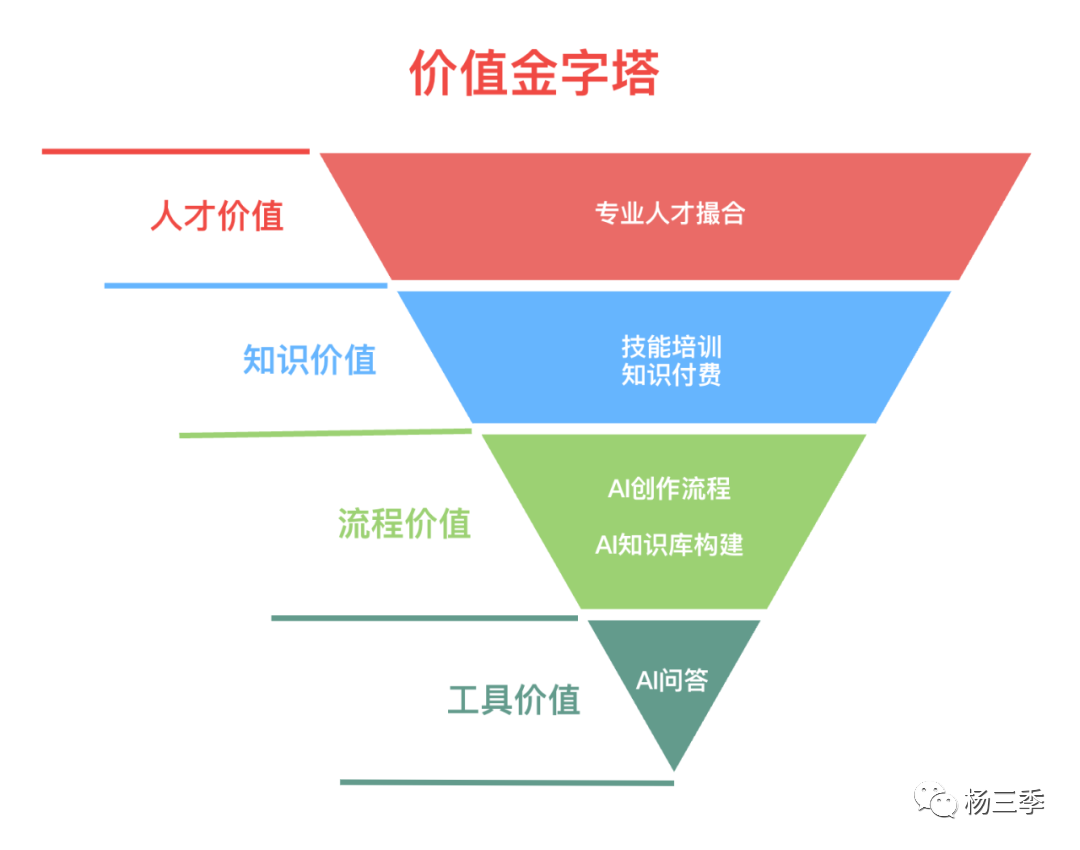
本文将围绕以下几个问题对这个产品 idea 进行思考和分享。
- 在什么赛道中,知识问答是刚需?
- 在这个赛道中,用户痛点分别是什么?
- 在这些痛点中,大模型能力可以做什么?
- 如果要解决这些痛点,需要什么,卡点在哪?
在开始前,小编重述在上一篇中,分享的两点非共识认知:
- 在国内市场,基于大模型搜索能力的SuperApp 面向C端消费侧用户一定是免费模式。
- 在国内C端市场,基于大模型搜索能力的SuperApp 的产品价值不止是工具价值,而是通过满足多方需求,完成资源撮合所带来的高溢价变现。
一、在什么赛道中,知识问答是刚需?
1. 在国内,什么赛道对知识问答的需求是刚需?
不论是创业或者打造一个全新应用,首先一定要借势。今天很多应用借着AI2.0的势,破圈甚至站住脚。比如妙鸭相机、通义听悟、Midjourney。那除了AI2.0 是今年爆火之外,还有什么赛道在这两年爆火起来了呢?
- 知识付费:2022年中国知识付费市场规模将达1126.5亿元,2025年将达2808.8亿元。
- 超级个体:2022年国内灵活就业人员约为2亿人(7.5亿总就业人口),18.6%的2022届高校毕业生选择了自由职业,较去年提高3个百分点。
中国互联网在后疫情时代,就业市场低迷的情况下,打工者的心态发生了巨大的转变。很多85后,90后甚至95后打工人开始意识到只有一份主业情况,可能在当下这极具变化的市场中,难保障会有一个稳定的明天。一个新的名词被很多人提及与关注,“超级个体”!
而小编更关心的是,超级个体中与互联网关联度最高的知识类超级个体,俗称:知识IP。
知识类超级个体:
通常是指那些在某个领域拥有深厚专业知识和技能,并且能够通过知识付费的方式进行商业变现的个体。他们不仅精通一项或多项专业技能,而且能够将这些技能应用到实际生活和工作中,从而实现商业变现。
你可能会疑问,“知识IP的问答服务场景”跟“AI搜索引擎的问答场景”的好像不是同一类场景吧?
没错!头部知识IP的问答场景,目前主流场景是在私域平台通过直播,或1对1服务进行问答服务。
但小编关注的并不是头部知识IP,因为小编思考的:是一个面向C端的AI Native 应用idea,那就一定要关注其目标用户量的覆盖广度。
借用Midjourney的产品思路(通过AI能力辅助UGC用户,使其转变为PUGC,并可将少部分用户提升至PGC的水平)。
所以小编真正关注的是:
- 已然是知识IP,但处于腰部及以下的用户;
- 想要通过成为知识IP,为个人职场开启第二增长曲线的用户。
这两类用户都有两个核心且具有共性的痛点:自我提升 & 精准链接
为什么小编这么说呢?
供给侧用户需求:
- 精准链接:通过各大流量平台触达有需求的消费侧用户,进行知识赋能,逐步建立自己的领域影响力。
- 自我提升:通过不停破圈、向上社交,提高眼界与认知,反复打磨自己技能,提高知识变现的能力。
消费侧用户需求:
- 自我提升:基于各大流量平台筛选出满足自身知识需求的知识IP,通过付费等方式,获取知识,提高自己的职场竞争力。
- 精准链接:通过向上社交、横向破圈的策略,获取信息差和知识,提高个人能力。
如果要让小编举例,那最近的“如何跨界至AI 2.0 做产品经理”可以说是职场人中最热门的话题之一。
小编作为一个幸运的跨界成功者,从开始跨界直至今日,每天都会思考的两个核心点:
- 如何保障自己在一个正确的学习姿态,获取对我有价值的信息差?
- 如何让自己可以精准的触达对我有价值的人脉资源,而非想割韭菜的人?
2. 这个赛道,为什么有机会出现 SuperApp?
王小川:人需要有三个东西:一个是自己有创造力、第二个是需要健康、第三个需要快乐。
宛辰 Moonshot,公众号:极客公园《对话王小川:大模型创业核心,是想好技术如何匹配产品》
2.1. 感性层面:
小编在构思出这个产品后,一直在反问自己“这个产品到底解决用户的什么根本需求?”在看到王小川老师分享的这句话后,小编有了些许答案。用户通过知识获取后的自我能力提升,本身就会给自身带来快乐和成就感。而当用户将这些知识赋能给其他人或事时,本身也是创造力的表现。
当一个App能满足用户三个基本需求中的两点时,这个App就有其存在的价值了。
上一代被称为超级应用的产品基本上都是“链接”类型的产品,无论是熟人社交还是陌生人社交,用户使用这些产品的首要任务是获取更多的链接。
我们后来发现,新一代的超级应用可能更多地是为用户提供一个游乐场(Playground):每个用户可以在其中创造和生成自己的东西。
Z计划,公众号:质朴发言《对 SuperApp 的想象无限 & 大模型能力有限|Z 沙龙第 4 期》
2.2. 理性层面:
通过“质谱发言的Z 沙龙”中某VC合伙人的发言中,超级应用在上一代的核心价值是“链接”,而在这一代的核心价值是“创造力”。而不管是“链接”还是“创造力”,超级个体这类用户都满足其条件。
知识类超级个体通过“知识”与消费侧用户产生了“链接”,并在这一过程中,通过不断对“知识”的理解和应用(创造力),产生价值的赋能。
当下大模型的技术边界(幻觉、缺乏可解释性、灾难性遗忘等)在小编的产品构建中,通过场景细分后可以被巧妙的规避,或基于用户数据的辅助进行一定程度上的优化。
二、在这个赛道中,用户痛点分别是什么?
说到用户痛点,那必须要提到用户场景。在个人自我提升这个用户需求的方向下。用户场景是怎么样的呢?
看到小编在上一篇中提到的:“数据获取 → 信息区分 → 知识归类 → 技能总结 → 知识获利”后,你可能会产生疑惑?“知识归类 → 知识获利 很好理解,那数据获取和信息区分有什么区别?我平常不都是知识学习和通过实践提升技能吗?”
这里小编,就要来聊一下在很久之前的一篇分享中,小编提到的智慧模型Plus版本了~
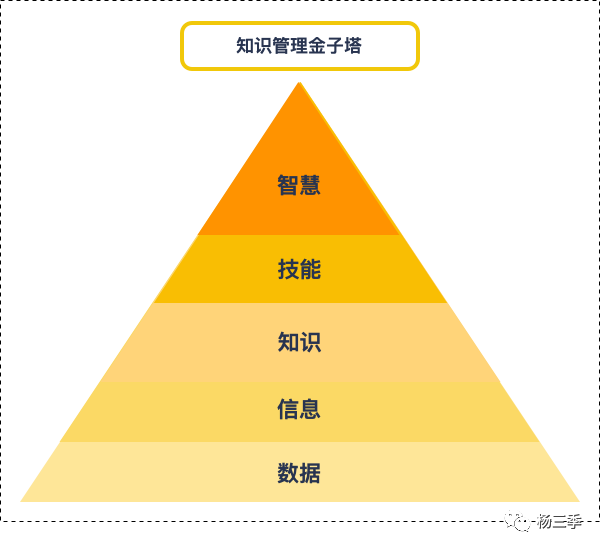
在过去十年,很多入行互联网的朋友,在初入职场时,通过看书、文献、速成培训快速得到行业前辈们的总结的成熟方法论(知识&技能),并直接使用在工作场景中。久而久之,养成了“授人以渔不如授人以鱼”的拿来主义习惯。
而在最近这两年,就业市场低迷,AI 2.0 爆发,超级个体崛起等冲击,有些读者朋友不得不开始努力提升个人技能。这时候发现前辈们的方法论到自己手里就没那么好用了。所以开始疯狂的关注各类知识IP,加入各种技能分享社群,期望能提高自己的职场竞争力。
场景一:数据获取 → 信息区分
因此第一个细分的用户场景就出现了“数据获取 → 信息区分”:
场景举例:
作为在努力提升个人认知和职场竞争力的朋友,是否每天都会在不同的渠道(微信公号、36氪、虎嗅、知识星球等)看到很多文章,但由于时间、惰性、缺乏工具等问题,就会出现:
- 有时候只能简单看一下 → 收藏 → 有时间再看 → 根本想不起有这事 / 收藏太多,是哪个来着;
- 有时候认真看过后 → 收藏 → 有时间再写个笔记 → 根本没时间写;
- 有时候看着看着突然想到一个启发 → 收藏 → 一会把这个idea记下来 → 完了那个idea是啥来着;
以上这些痛点够刚吗?够普遍吗?AI 2.0 之前,受限于技术能力,这些问题没办法通过产品能力实现,现在呢?
可能对AI工具足够热爱的朋友,会想到印象笔记的大象AI、知了阅读、天工AI助手的AI阅读等产品目前针对这类需求提供了应用App。
但体验后,小编总结了3个待解决的问题:
- 场景切入不精准:比如天工AI助手的AI阅读,用户主场景是微信公号,36氪等APP,你竟然让我手动复制 → 跳出当前APP → 打开天工AI → 打开AI阅读 → 粘贴链接;
- 付费降低留存:产品受限于边际成本影响(算力),用户无法大量的&免费的使用工具,比如知了阅读,免费额度仅够两三篇内容总结,面向C端用户,不免费难增长;
- 技术导致体验差:产品受限于算力资源和技术能力,AI总结体验差,比如大象AI,使用AI阅读时,不是崩了,就是等了1分钟才能出现总结质量较差的内容;
用户痛点:
- 用户人工判断出的有价值的数据(文章/视频),需要能被快速“转存”到“个人信息库”;
- 用户人工判断的有兴趣的数据(文章/视频),需要能被快速“辨识”出有价值的“信息”;
产品价值:
- 用户流量入口:用户的知识学习&自我能力提升的链路原点;
- 私域数据获取:大模型搜索目前仅能通过公域数据获取,来进行用户问题解答解决。公号等私域数据获取困难。
- 更好的用户体验前提:更容易拿到用户的偏好信息,为后续用户粘性(热点推荐),交易撮合(内容供给侧的创作偏好)等环节提供价值。
场景二:信息区分 → 知识归类
如果第一个场景的用户痛点解决后,作为读者朋友的你,接下来会干什么?
用户场景:
可能会在某个你有时间学习或有某个紧急事件需要你去查阅你的知识库(或素材库)时,来使用这个“个人数据库”。
- 小编要开始写东西了,需要一些信息参考。
- 小编在社群里跟朋友交流,我对一个观点需要补充说明,我记得我之前看到一段内容是关于这个观点。
- 我现在要做AI漫画视频,关于AI输出连续有关联的画面的技巧分享,我记得在哪里看过。
这里就涉及到了“个人信息库 → 个人知识库”的转变,即“信息区分 → 知识归类”。
用户痛点:
- 用户可通过自然语言或业务标签,快速找到在“个人信息库”中对标的“信息”;
- 用户可基于已找到的“信息”,快速在公域和产品私域中找到相关信息,进行知识补全;
- 用户可将这次使用的“信息”,快速总结,并补齐到“个人知识库”对应的知识点下;
产品价值:
- 用户流失率降低:由于上一场景,用户留存了大量的个人数据,这一场景中,通过AI能力+产品策略,可以进一步让用户提高沉默成本,降低流失概率。
- 产品认可度提高:由于产品可帮用户梳理其知识,提高认知,让用户感到个人创造力的提升;产品在这个阶段还可以通过“学友”机制,让用户找到“知己”,让用户感到快乐;
场景三:知识归类 → 技能总结
这个场景和前两个场景最大的区别,是这个场景对于用户来说,是一个偏线下场景。因为“知识归类 → 技能总结”再进行细拆其实是“归类 → 试错 → 实践 → 总结 → 执行 → 复盘 → 审查 → 检视”。
对知识点进行试错,排除无关知识,对有关知识进行实践,通过实践总结出认知偏差,不断的通过PDCA策略,进行技能打磨和迭代。
用户痛点主要来自两方面:
- 线上工具:用的顺手的梳理工具 → 文本创作、版本管理、逻辑梳理;
- 线下行动:找到可实践的应用场景 → 实践完成经验积累 or 借鉴他人实践经验;
在这个环节,要采用扬长避短的策略。为什么这么说呢?因为工具层面,各垂类方向都有用户粘性很高的应用:比如飞书文档、Xmind、石墨、印象笔记。让用户从这些应用中迁移到我的产品进行内容创作中是一个性价比很低(用户迁移概率 / 应用研发成本)的事件。
因此在这个场景中,产品调性并不是用户在产品中完成原生内容的创作。而是让用户在三方工具完成内容创作后,将这些内容数据重新输入到产品中。
这时候,你会问:用户为什么会多此一举?
因为在AI 2.0 之前,各类文本创作工具虽在产品内提供了全局搜索的能力,但从本质上并没有解决的问题是“基于一个信息点或知识点,将涉及的内容关联起来,形成一个知识图谱。”
而我所构思的这个产品,恰好能截止大模型的快速学习能力,加上知识图谱等深度学习的技术,完成用户的个人“技能树”的搭建。
试问:如果有一个产品能将你平时零散的思考、idea、总结的内容等通过思维导图等方式串联起来,而你的操作成本仅是将这些内容快速的导入,将AI打标后标签简单校对一下,你会不会用呢?
这里提到的“技能树”怎么理解?通俗的说就是一张思维导图。比如当下爆火的“长文转视频”这个技能。虽然在AI 2.0 时代中AI视频生成极大的提高了创作者效率。但“剧本→视频”这个技能已经存在很久了。所以这个“技能树”本身并不是一个新生产物。仅是通过AI能力将这个技能树上的知识点进行简化处理。但如果你作为一个“AI视频生成”的业务高手,你不懂传统流程能行吗?怎么通过知识赋能其他人呢?
产品价值:
- 大模型幻觉概率降低:通过用户梳理的“技能树”,进一步提高大模型对某一类定向问题的回答精准性,减少幻觉偏差;
- 第二场景的产品价值进一步提高。
PS:这个场景中,小编的一位朋友曾提出过一个观点“越标准化的内容,越没有AI整合的价值。”
在我与这位朋友交流后,这位友人想表达的观点是“越标准化的知识,越没有AI整合的价值。”小编是认可这个观点的,但这里小编想表达的是“知识是有标准,但技能不是。” 就好比说“一个APP的注册登录模块是有功能定义的,但如何设计让用户体验更好,这个是没有固定答案的。”
因此小编的“技能树”策略是在为用户补全其“知识”的认知差外,还在逐步为用户提高其某项“技能”的能力天花板。
场景四:技能总结 → 知识获利
首先要强调一下,这里小编描述的是“知识获利”,而非“知识变现”,知识变现是聚焦于经济层面。而获利则可以理解为:自我精神的自我满足、人脉资源的有效扩展、经济收入的明显提高;
用户场景:
- 腰部知识IP:有一技之长,但由于其行业影响力和口碑不足,无法触及到精准的消费端用户。
- 消费端用户:有明确的知识获取需求,但由于难辨别知识IP的服务能力,导致常被割韭菜,无法相对公正的获得有价值的知识信息。
用户痛点:
在当下市场中,只有少量头部的知识IP或者机构可以通过知识付费完成经济收入的明显提高。
造成这一问题的原因是什么?
- 头部知识IP:对普通用户带来的“权威效应”,导致大多数用户因“安全心理”“从众心理”“认知失调”等原因,过分依赖头部知识IP的权威;
- 腰部及以下的知识IP:因对于个人影响力的不足,导致消费侧用户无法通过口碑了解“腰部IP”是否能满足消费侧用户的知识需求。
换句大白话说:“作为一个求知者,小编在需要通过付费获取某个知识IP的知识服务前,最大的考量是这个钱花的值不值?我会不会被割韭菜。”而如何判断这个事情,传统的方式只能是打听他的口碑,或者看他过往的分享,学员的反馈。
而在小编构想的这个产品中,这一传统习惯将被变革,在这个产品中所有的知识需求方都可以成为知识供给方(三人行必有我师),因为从“数据获取→技能总结”这个过程中,大模型虽然在为用户提供服务,但反过来大模型也可以通过这些数据判断用户的擅长能力,擅长程度。
这件事在AI 2.0 之前,互联网应用几乎无法做到这一点。
而当大模型可以通过数据及业务标签,相对清晰的计算出用户的竞争优缺点后:
- 对于技能短板部分,可以引入三方教培机构和高于用户能力的其他用户进行交易撮合。
- 对于技能长板部分,可以引流至企业招聘领域。
产品价值:
变现方式:通过完成知识付费的供需两端的资源撮合服务,为产品带来实际经济价值。
三、在这些痛点中,大模型能力可以做什么?
在上一节中,其实每一个场景都有提到大模型能力,也可以说整个产品是基于大模型能力而构建的。换言之:如果没有大模型能力,这个产品是无法落地的。
这里小编简述一下,在用户场景中依赖大模型能力的几个核心功能:
3.1. AI文章总结(场景1&3)
相信用过印象笔记的大象AI、知了阅读、天工AI助手的AI阅读等产品的朋友,都知道其产品的核心功能就是AI总结(AI摘要)能力。在信息区分、知识归类、技能总结这几个场景中,这个依托于大模型的产品能力非常重要。
目前这几家的这个功能设计中,小编认为可能由于算力成本、技术能力、场景分析等原因并没有将这个功能做好。关于这个功能的详细分析,小编在上一篇分享中“天工AI”篇内已对“AI速读”和“AI精读”场景进行详细阐述,这里就不在赘述了。
3.2. AI知识搜索(场景1-3)
不论海外的ChatGPT、PerplexityAI,还是国内的文心一言、百川等都提供了AI知识搜索引擎的服务。在小编的产品构思中,信息区分中的AI精读、知识归类&技能总结中知识补全都需要AI知识搜索的能力。
在这个功能中,由于产品本身沉淀的用户数据(热点信息、知识归类、技能树节点)可以反向为依托于大模型的知识搜索进行赋能,降低其在幻觉、缺乏可解释性、灾难性遗忘等问题出现的概率。这也是目前的AI知识搜索引擎所遇到的问题。
3.3. AI信息打标(场景1-4)
通过AI技术进行数据打标这事,早在AI 1.0 时代就已经存在了。但哪怕是国际公认最权威的医学知识图谱(SNOMED-CT)也无法100%覆盖所有的医学问答场景。
因此小编构建的产品中,AI信息打标并不是替代用户完成“信息→知识→技能”的数据分类。而是通过AI打标先将庞大杂乱的数据进行初筛,用户基于初筛后的结果再进行人工校正的过程。
这里小编要提出两个非共识认知:
- AI可以替代用户完成某些极度标准化的工作流程,但无法替代用户完成非标准化的工作任务;
- 当AI可以100%替代用户完成某领域的复杂任务时,那这类用户在这一领域将没有竞争力可言。
3.4. AI匹配学友(场景2-4)
对于绝大多数的普通人来说,由于职场压力,需要通过学习,走出自己的舒适区,完成自我提升。并不是一个快乐的过程,也可能被视为一种痛苦。
因此小编构建的这个产品中,除了通过工具为用户提供一个从“信息→知识→技能”全链路服务外,另一个核心能力就是通过AI进行“学友”匹配的服务。让用户在自我提升的过程中链接到合适的良师益友,降低用户流失,并从而为产品构建知识价值&人脉价值。
“学友”策略:小编将其定位于人与人通过知识需求的精准链接。而非传统意义通过话题社区/社群进行模糊链接。
这里你可能有两个问题:
- 为什么不在沿用话题社群的方式进行人与人的链接?
- 如果通过知识需求进行人与人精准链接,如何解决需求个性化导致匹配度低的问题?
对于第一个问题,小编通过一个现象来说明:小编在进行AIGC2.0学习时,加入相关私域社群10+个,但获取到有价值的信息差还不如我通过看深度文献/视频获取的多。
对于第二个问题,小编认为首先要拉齐一个认知:什么是需求个性化?它的颗粒度是多少?
在知识赋能这个领域中,用户的需求并不是千变万化,无迹可寻的。
用户的需求来自于他所在的行业,所处的职位,所需的技能等方面而产生的。用户对“求知”这个需求的个性化是在以上这些维度综合后所总结的结果的认知偏差所导致的。
产品可以通过AI技术对用户的个人信息、偏好、技术树等数据,推算出用户当前的知识需求,并在用户路径的恰当节点上为其进行“学友”匹配。当然这个匹配一定会存在误差范围。但这个功能为用户带来的成本只要比用户通过流量平台、私域社群找到“学友”的效果相似或更好,但成本更低。用户就会使用这个功能。
四、要构建这个产品,团队需要的是什么?
从上文的分析中,不难看出整个产品是依托于大模型能力而构建的,每个场景中都涉及了大量的大模型调用和定向场景的模型能力微调。因此构建这个产品的重要前提一:
1)团队自身需要具备大模型研发能力。
由于产品是面向国内的C端市场,向用户收费的策略难以带来增长。而如果使用大模型供应商的API服务,普通应用厂在中短期无法承担算力成本消耗。因此构建这个产品的重要前提二:
2)团队自身需要具备算力资源。
因此想要实现这样的一个产品构建,除了拥有大模型自研能力的互联网大厂,就是模型厂了。
而对于模型厂,这样的产品在中短期内能带来的价值:
- 在场景一就可以通过快速切入用户痛点,获得用户主动的为大模型输入“定向领域&人工判断有价值的”数据,且基于大模型总结后,人工对输出数据进行标注,大模型可通过“白嫖”的方式获得大量有价值的、标注好的数据,从而提高自身的大模型服务能力。
- 当全链路构建完成后,大模型面向C端的商业模式,从工具服务订阅制转变为撮合交易。(低溢价的工具付费 → 高溢价的知识&人脉付费)
不论是文心一言、通义千问,亦或是百川大模型、月之暗面等模型厂,都面向国内C端用户提供了信息搜索服务,但这个服务除了释放团队在关注“国内C端的大模型应用能力”的信号,给企业自身带来的价值是什么?是期望用户会主动的标注错误答案吗?还是期望通过用户广泛使用分析出有价值的用户场景?小编在这个问题上认知浅显,就不再班门弄斧了。
本次分享就到这里,全文没提到商业模式和变现方式,这个不是小编没考虑到。只是由于篇幅问题,本次就不展开了。简单说,当用户对产品产生粘性后,就可以通过订阅制、匹配席位数、消费端流量变现等的方式开始“卖人”了。至于怎么卖?小编也已构思了全案,有兴趣的朋友,可以跟小编私聊。
参考文章
对话王小川:大模型创业核心,是想好技术如何匹配产品
对 SuperApp 的想象无限 & 大模型能力有限|Z 沙龙第 4 期
艾媒咨询|2022-2023年中国知识付费行业研究及消费者行为分析报告
幸好,这是超级个体的时代
专栏作家
杨三季,微信公众号:杨三季,人人都是产品经理专栏作家。8年互联网经验的高级产品官,深耕内容领域,ex阿里AIGC.PM,现某垂类领域头部企业 AI2.0 PM。
本文原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


