
 起点课堂会员权益
起点课堂会员权益如何做数据标准化:哪类数据需要标准化处理
将一个东西标准化,可以提高生产效率,数据也是如此。但在开始化之前,我们需要先来看看,哪些数据需要进行标准化处理,以及如何处理。

关于“数据标准化”,MBA智库百科的解释如下:
数据标准化是指研究、制定和推广应用统一的数据分类分级、记录格式及转换、编码等技术标准的过程。
主要指的是数据治理中的数据标准化工作,包括数据交换、数据质量和数据标准等一系列内容,可称之为“数据标准化体系建设”。在这个内涵下,要做好数据标准化,需要做:
- 建立数据模型标准并落地标准化建模流程
- 建立数据编码标准
- 系统集成标准化
但我们今天所说的,并不是这个“数据标准化”。而是“数据预处理(也称 数据清洗)”中的一种数据处理手段。
在说“什么是数据标准化”之前,我们先来说说“为什么要做数据标准化”。
回想一下人类发展史,可以了解到,开启工业化时代的必要条件之一是——零件标准化。
没错,只有当工厂实现了“零件标准化”,才真正算是步入了工业化时代,生产效率得到了极大的提升。
为什么零件标准化能带来这么大的增效呢?
因为有了它,工厂生产零件可以完全按照图纸规范来,并且就算是不同厂家生产的零件,只要是按照图纸规范来的,都是可以通用的。此举大大提高了零件的质量和可用性,并且使得工厂之间的协同和合作变得尤为高效,零件再组装成更大的可用商品也就更高效和保质保量了。
对于数据来说,同样地,实现数据标准化,能够为整个数据生产链条带来效率的提升和质量的保证。
数据标准化需要将数据对象按照我们后续处理的要求切成所需的形态,我们要做的,就是定义这个“模具”并让它开始工作。
在讲到“如何做数据标准化”之前,我们需要先来看看,哪些数据需要进行标准化处理。
一、量级不一数据
比如现在要分析门店销售额和店均销量对门店竞争力的影响。在业务认知上,此两者的权重应是相当的。但数值的量级却是不一样的。
试想一下,如果让门店销售额和店均销量直接参与计算,会发生什么事?
门店销售额的数值量级远大于店均销量,必然就会导致店均销量对结果的影响被拉得微乎其微,而这并不符合业务实际,也不符合我们想要的影响因子系数配比。
那么这时候,就需要对这类数据进行“去量纲化”这种数据标准化的处理。
1. 去量纲化
那么“去量纲化”又怎么做呢?有哪些方法可以用?罗列如下。
min-max标准化
首先,我们需要确定一个原则,既然是“去量钢化”,那么我们要做的就是:把所有参与计算的自变量的取值区间拉到同一个区间。
min-max标准化这个方法即是将这个统一取值区间定义为:[0,1]。不管原本多大量级的指标,都需要经过处理后落在这个区间内。
问题又来了,如何处理能达到这个效果呢?
这里有个公式:(X-min)/(max-min),所有数据经过这个公式的运算后都可以落在[0,1]区间上。属于最简单的线性变换法。
z-score标准化
z-score标准化这个方法即是将这个统一取值区间定义为:围绕0上下波动。主要是基于均值判断单个具体值是偏高还是偏低。
这里的公式是:(X-Mean)/Std。大于0说明高于平均水平,小于0说明低于平均水平。
归一化
归一化与“min-max标准化”类似,都是使处理后的数据落在[0,1]区间。
公式:X / (x1+x2+…Xn)。对正数进行变换,将数值的绝对值变成相对值关系。
其他方法
其他的方法还有如中心化、均值化、区间化等都可以实现将数据处理到期望的确定范围内。
- 中心化:X-Mean(让数据变成平均值为0的一组数据)
- 均值化:X/Mean
- 区间化:a+(b-a)*(X-Min)/(Max-Min)【可将数据压缩到区间[a,b]中】
二、指标作用方向不一数据
比如现在要分析不同商品的优劣,从而用于选品的决策。而评价商品的优劣则需要从多维度来评估,涉及到若干个指标。常见的,如动销和同质化。在业务认知上,代表动销的指标动销率、销量等,数值越高则商品表现越好;代表同质化的同功效SKU数,数值越低说明同质化程度越低则商品表现(稀缺性优势)越好。到这里,各位看官应该可以看出来,这两种指标的作用方向是不一样的,即:一个是越高越好,另一个是越低越好。
那么,如果让动销率和同功效SKU数直接参与计算,又会发生什么事?
商品评分随动销率的增高而增高,这没问题。但商品评分随同功效SKU数的增高而增高就不合理了,同质化程度的增加只能说明该商品的稀缺性和独特竞争优势走弱,商品评分应该随之降低才是符合业务实际的。
那么这时候,就需要对这类数据进行“负向指标正向化”这种数据标准化的处理。
1. 负向指标正向化
对于“同功效SKU数”这类负向指标,我们的处理方式是,套入如下公式:
(max-X)/ (max-min)
经过如此数据处理后,便可将负向指标转为正向指标,且结果将落在[0,1]区间内,从而实现了数据的标准化。
2. 中间型指标处理
作为负向指标正向化的变种,对于存在理想中间值的情况,可以采用如下方式:
公式:
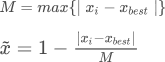
作用:对中间型指标数据的线性变换,使结果落到[0,1]区间。原数据等于理想值,处理结果为1;原数据越靠近理想值,处理结果值就越接近1。
3. 区间型指标处理
除中间型指标处理外,还存在另一变种——区间型指标处理。公式如下:
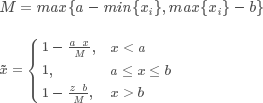
在此方法里,[a,b]是假设的最佳区间。
作用:对区间型指标数据的线性变换,使结果落到[0,1]区间。原数据若在理想区间内,处理结果为1;原数据越靠近理想区间范围,处理结果值就越接近1。
对于这两类“不够标准化”的数据,经过以上两种处理之后,则满足了数据应用的标准,可以进行下一步使用了。这便是“数据生产链”中“数据标准化”工作的意义与常见的方法。希望对各位理解数据工作的具体内容有所帮助。
本文由 @maggieC 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


