
 起点课堂会员权益
起点课堂会员权益决策树与随机森林算法:可视化的决策过程
决策树既可以计算出结果,还能够清晰地告诉我们得到这个结果的原因。那么在决策中,可以如何应用决策树与随机森林算法?本文对此进行了解析,一起来看看吧。

上篇文章我们介绍了逻辑回归算法,今天我们接着来学习另一个基础的分类和回归方法,决策树。
决策树既可以输出计算结果,还能很清楚的告诉我们为什么会得到这个结果。
如果对一棵决策树的效果不够满意,还可以使用多棵决策树来协同解决问题,这就是随机森林,属于集成学习的一种。
而随机森林这样的集成学习算法,融合了多个模型的优点,所以在遇到分类问题的场景时,决策树和随机森林常被当做机器学习的首选算法。
一、初识决策树
举个栗子,我们要判断一个物体是否属于鸟类,一般会看它是否会飞、是否有羽毛等条件,如果它既会飞又有羽毛,那么大概率就是鸟类了。
我整理了几条样本数据,如下表所示:

基于表格里的数据,我们可以根据每个条件的结果,画出如下的决策树:
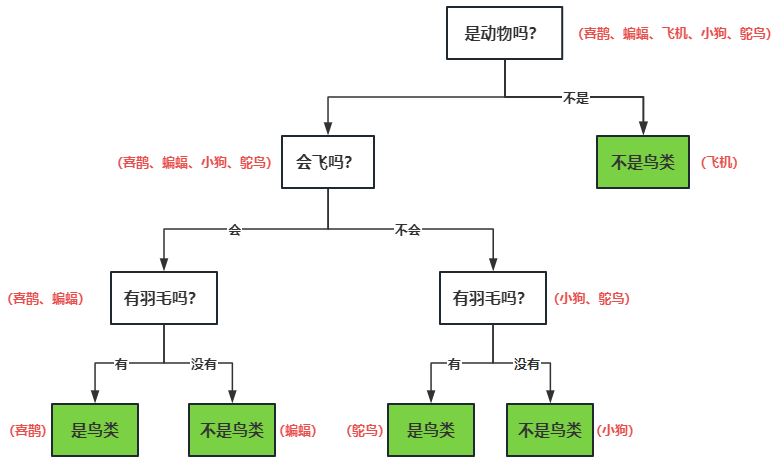
如上图所示,决策树(Decision Tree)就是一种树形结构的算法,每个节点对应了算法的一个特征(是否会飞等),节点上的每一个分支(会飞、不会飞)对应了特征的不同种类,最后绿色的叶子节点对应了最终决策结果(是否鸟类)。
有了这个决策树之后,再有新的数据进来,沿着决策树自上而下的走一圈,就能得到决策结果,而且决策过程清晰明了。
二、信息熵
仔细观察上图的决策树,我们可以发现,不同的决策条件会导致其得到的子节点数据是完全不同的,从而得到完全不同的决策树结构,那么我们如何快速找到最优的决策条件,使决策树的效率和准确率更高呢?
这里需要引入信息熵的概念了:信息熵(Entropy)是衡量一个节点内不确定性的度量。
怎么理解呢?我们对刚才的决策树做一些改变,只保留两层节点,去掉“是否有羽毛”条件,如下图所示。那么最终的黄色叶子节点里,就会同时存在是鸟类和不是鸟类的样本数据,这个节点的不确定性就增加了,也就是信息熵变高了。
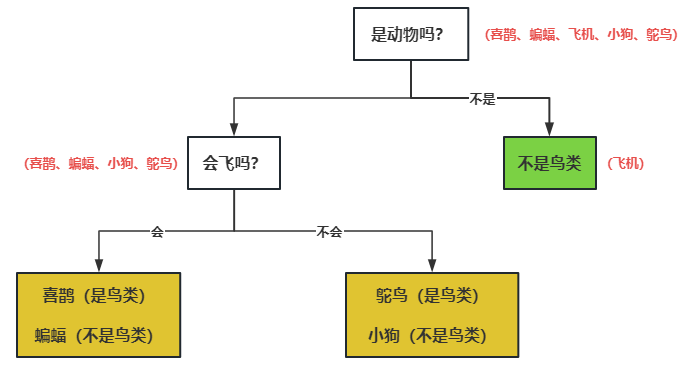
我们肯定希望决策树每次划分的时候,最终的叶子节点信息熵更低,这样每个叶子节点内的样本纯度也就越高,最终生成的决策树的确定性更强,效率会更高。
在构建决策树的时候,一般通过信息熵来筛选出更重要的特征,并把更重要的特征放到更靠前的节点上去。
三、如何生成决策树?
生成决策树包括特征选择、决策树生成、决策树剪枝等三个步骤。
在特征选择和决策树生成阶段,最重要的任务就是通过信息熵来筛选出更重要的特征,并把更重要的特征放到更靠前的节点上去。
决策树会评估每一个特征划分后系统的“信息熵指标”,“信息熵指标”最低的特征越靠近根节点,这样一来,决策树的复杂度和计算时间就会减少,模型就会更高效。
不同的决策树算法,所谓的“信息熵指标”也不一样,比如ID3算法使用的是信息增益,C4.5算法使用的是信息增益率,目前使用较多的CART算法使用的是Gini系数,这里不再赘述,感兴趣的话可以自己查一下相关资料。
上图的决策树,根据“信息熵指标”优化后的结果如下:
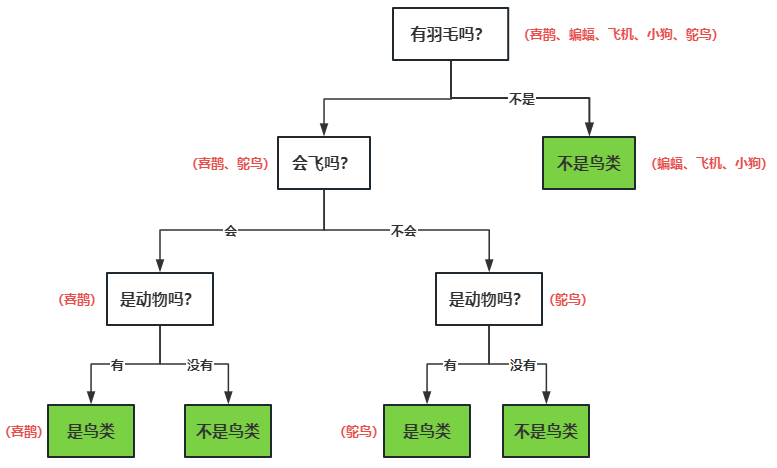
由于决策树很容易出现过拟合的现象,我们还需要对决策树进行剪枝操作。
剪枝操作可以降低决策树的复杂性,提升模型的泛化能力,基本原理就是判断把某节点去掉之后,模型准确度是否大幅下降,如果没有下降,就可以剪掉这个节点。
比如优化后的决策树,把是否是动物节点去掉后,并不影响模型的准确度,那就可以对其做剪枝处理,从而得到新的决策树。
四、应用场景
决策树的可解释性非常高,可以很容易的解释清楚其计算逻辑,所以适合各种需要强解释性的应用场景,比如咨询、金融等领域。
- 金融领域:决策树可以用于信用评分、风险评估、欺诈检测等金融领域的问题。
- 医疗诊断:决策树可以用于医疗诊断,如疾病诊断、药物选择等。
- 市场营销:决策树可以用于市场营销中的用户分类、客户细分等问题。
- 生物医学领域:决策树可以用于基因表达数据分析、蛋白质结构预测等生物医学领域的问题。
- 电子商务:决策树可以用于推荐系统、用户行为分析等电子商务领域的问题。
五、优缺点
决策树的优点:
- 可解释性强:决策树的生成过程可以直观地表示为一棵树形结构,易于理解和解释。每个节点代表一个特征,每个分支代表一个特征取值,叶子节点代表一个类别或一个决策结果。
- 适用性广泛:决策树可以用于分类和回归任务,可以处理离散型和连续型特征,也可以处理多分类和多输出问题。
- 数据预处理简单:决策树对于缺失值和异常值具有较好的容忍性,不需要对数据进行严格的预处理。
- 特征选择自动化:决策树可以自动选择最重要的特征进行分裂,能够处理高维数据和特征选择问题。
- 处理非线性关系:决策树可以处理非线性关系,不需要对数据进行线性化处理。
决策树的缺点:
- 容易过拟合:决策树容易过度拟合训练数据,特别是当树的深度较大或训练样本较少时。过拟合会导致模型在新数据上的泛化能力较差。
- 不稳定性:决策树对于数据的微小变化非常敏感,即使数据发生轻微的变化,生成的决策树可能完全不同。
- 忽略特征间的相关性:决策树在生成过程中只考虑了单个特征的重要性,忽略了特征之间的相关性。这可能导致决策树在处理某些问题时效果不佳。
- 难以处理连续型特征:决策树对于连续型特征的处理相对困难,需要进行离散化或采用其他方法进行处理。
- 生成过程不稳定:决策树的生成过程是基于启发式算法的,不同的启发式算法可能生成不同的决策树,导致结果的不稳定性。
六、随机森林:三个臭皮匠,赛过诸葛亮
单棵决策树容易出现过拟合的情况,并且结果也较不稳定,这时候我们可以使用多棵决策树来共同解决问题,这就是就是随机森林。
随机森林(Random Forest)是一种集成学习方法,通过组合多个决策树来进行分类或回归任务。
每棵决策树都随机抽取不同的样本进行训练,我们会得到三个不同的决策树,再综合考虑三棵树的决策结果,就能得到最终的决策结果了。
由于是根据多个决策树的结果共同决策,所以随机森林具有“起点高、上限低”的特点。
与单棵决策树相比,随机森林具有以下优点:
- 高准确性:随机森林通过集成多个决策树的预测结果,可以获得更准确的分类或回归结果。
- 可处理大规模数据:随机森林可以并行生成多棵决策树,因此在处理大规模数据时具有较高的计算效率。
- 不容易过拟合:随机森林引入了随机性,通过随机选择样本和特征子集来生成决策树,减少了过拟合的风险。
相应的,随机森林也有以下缺点:
- 计算复杂度高:随机森林需要生成多棵决策树,并且每棵决策树都需要考虑随机选择的样本和特征子集,因此计算复杂度较高。
- 可解释性相对较差:随机森林生成的模型是一个集成模型,由多棵决策树组成,因此模型的解释性较差,不如单棵决策树直观。
七、总结
本文我们介绍了决策树和随机森林的原理、应用场景和优缺点,同时决策树也有升级版本,比如XGBoost等,可以自己查一下。
下篇文章,我们来聊一聊支持向量机算法,敬请期待。
本文由 @AI小当家 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


