
 起点课堂会员权益
起点课堂会员权益如何设计一款有温度的AI产品?(二)
如何设计一款有温度的AI产品?在这篇文章里,作者接着就技术实现部分做了梳理和分享,一起来看看本文的思路。

四、技术实现
1. APP端实现
笔者调研了原生及跨端方案,加之控制成本的原因,选择了跨端Flutter的实现。
1)首页开发

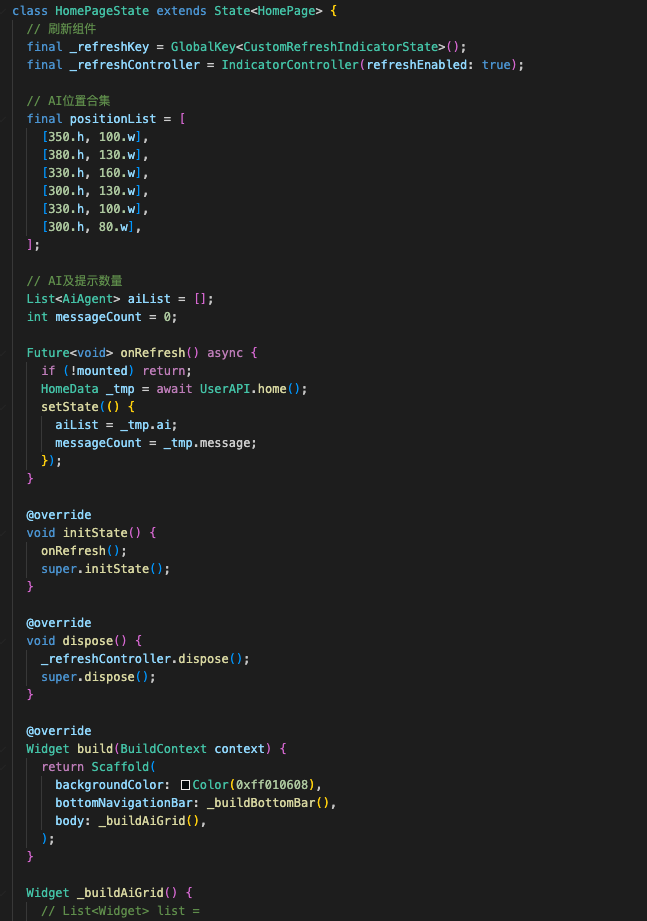
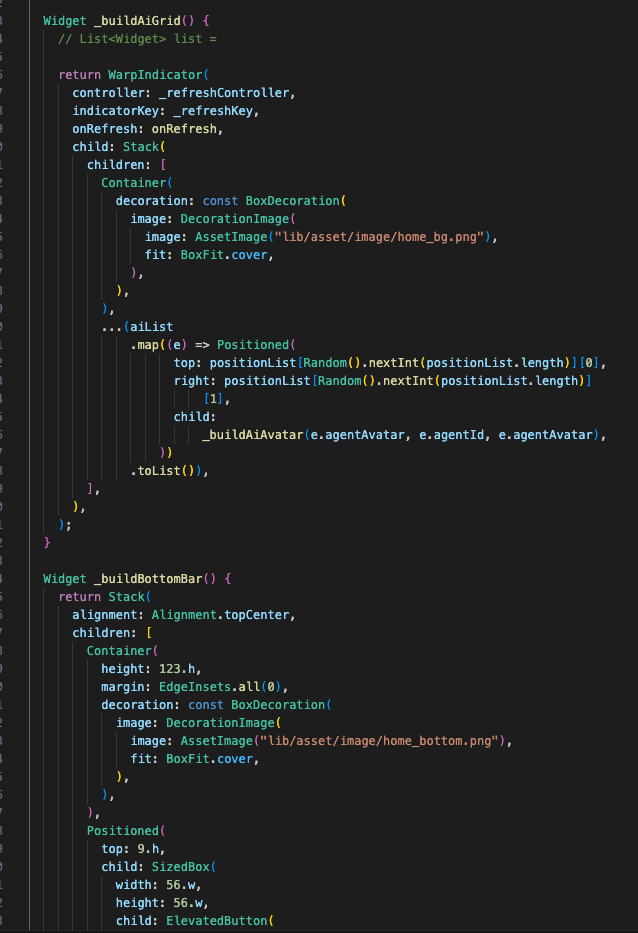
笔者采用了慕客作为协作的UI标注平台,分析布局后,应采用的布局方式:
- Scaffold 页面
- Body使用整张图片铺满,以宽作为平铺依据
- 不规则位置头像采用 Stack 布局,预设最多30个位置,随机展示
- 底部BottomBar,采用定位方式,弧度背景为图片,添加按钮采用 ElevatedButton
具体代码细节如下(系列文章完结后,会把源码开源出来,留言评论的我提前发下)
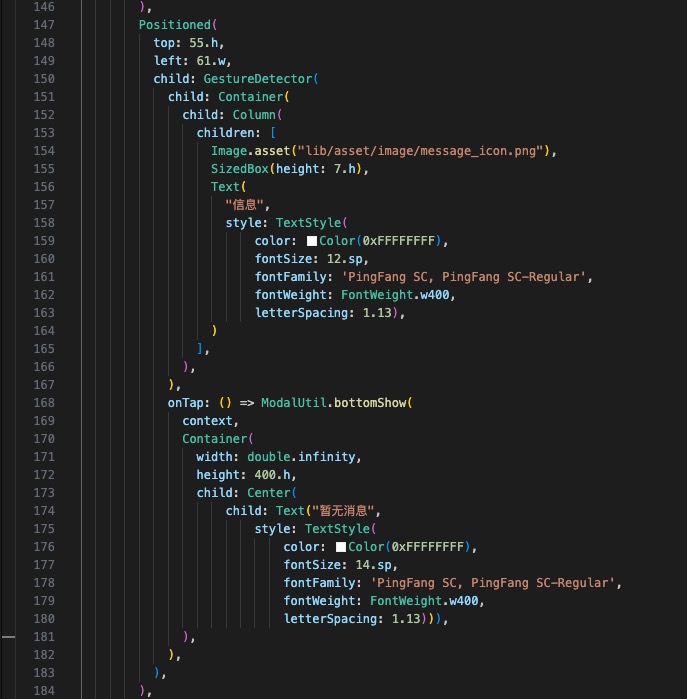
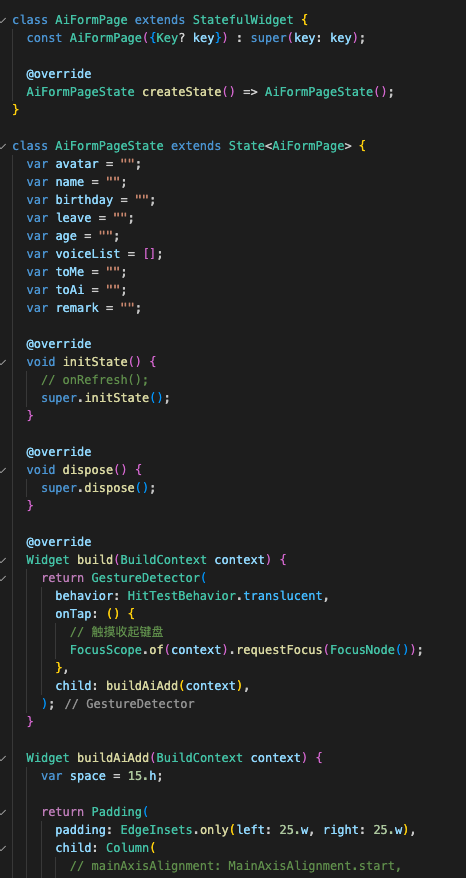
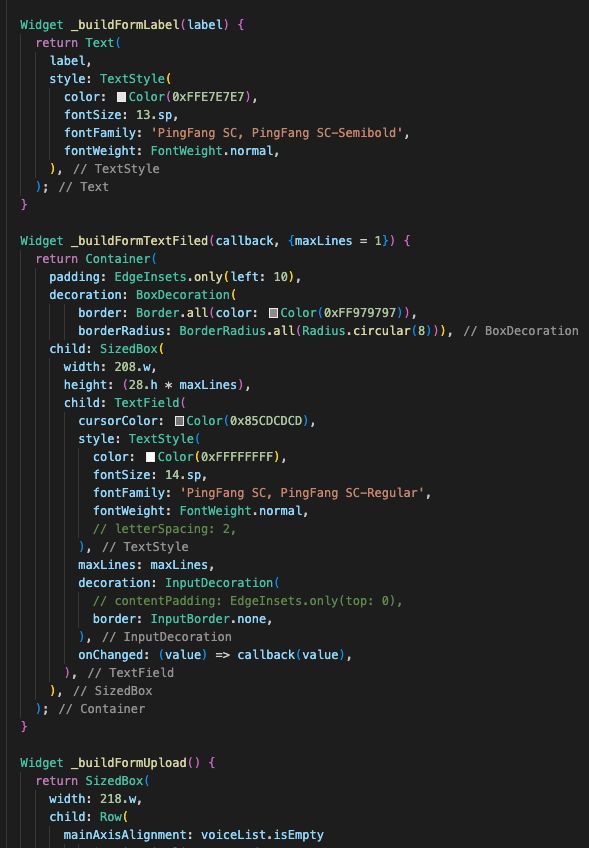
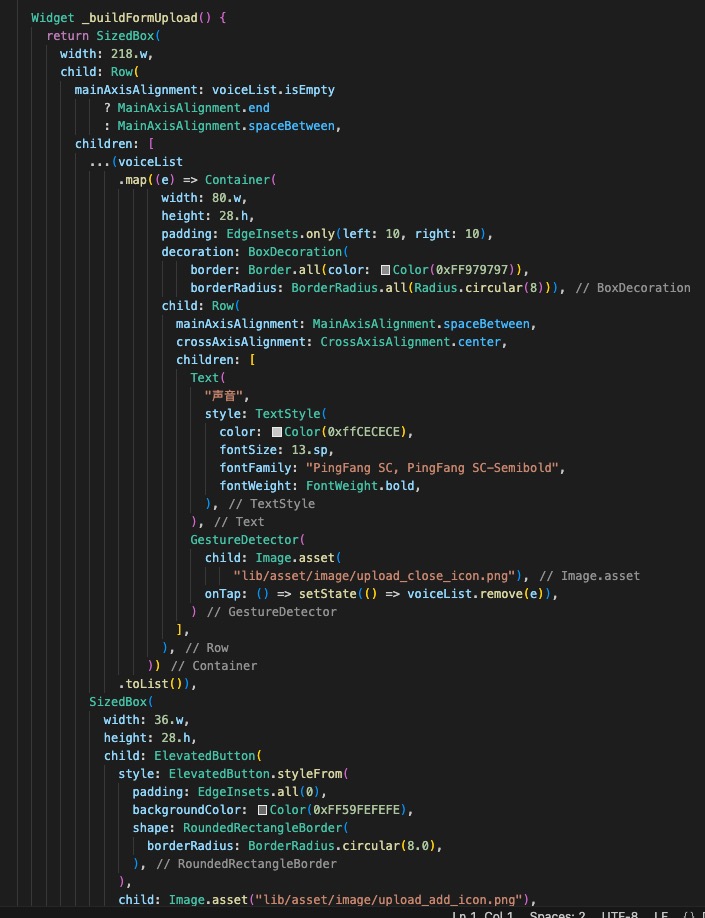
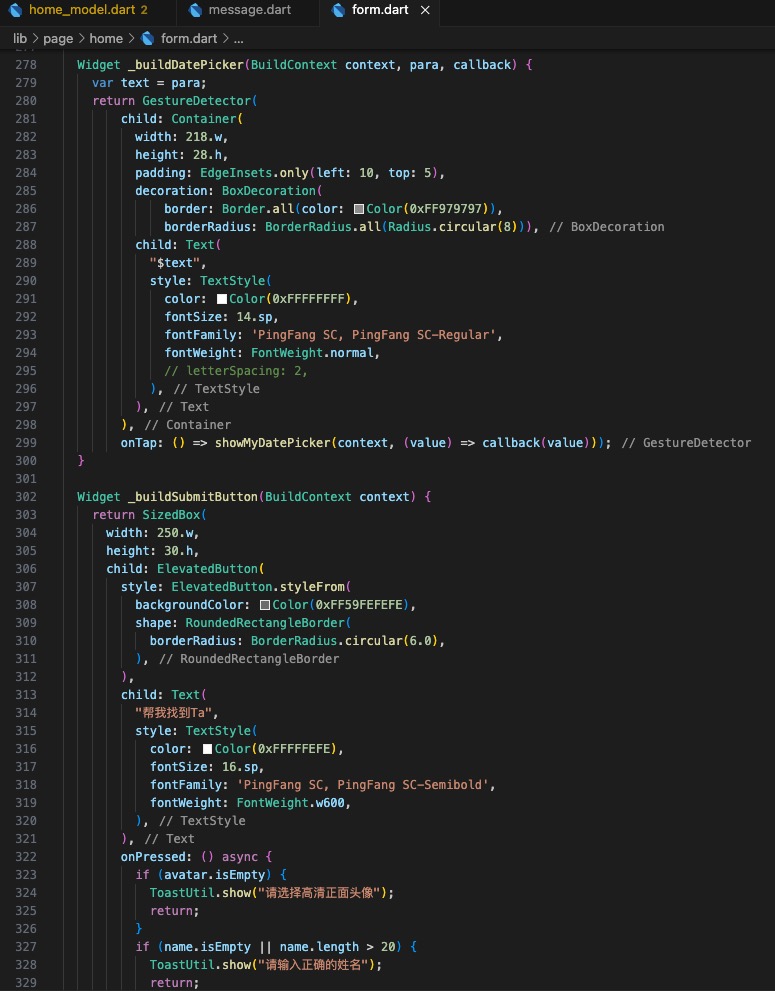
2)收集智能体页面
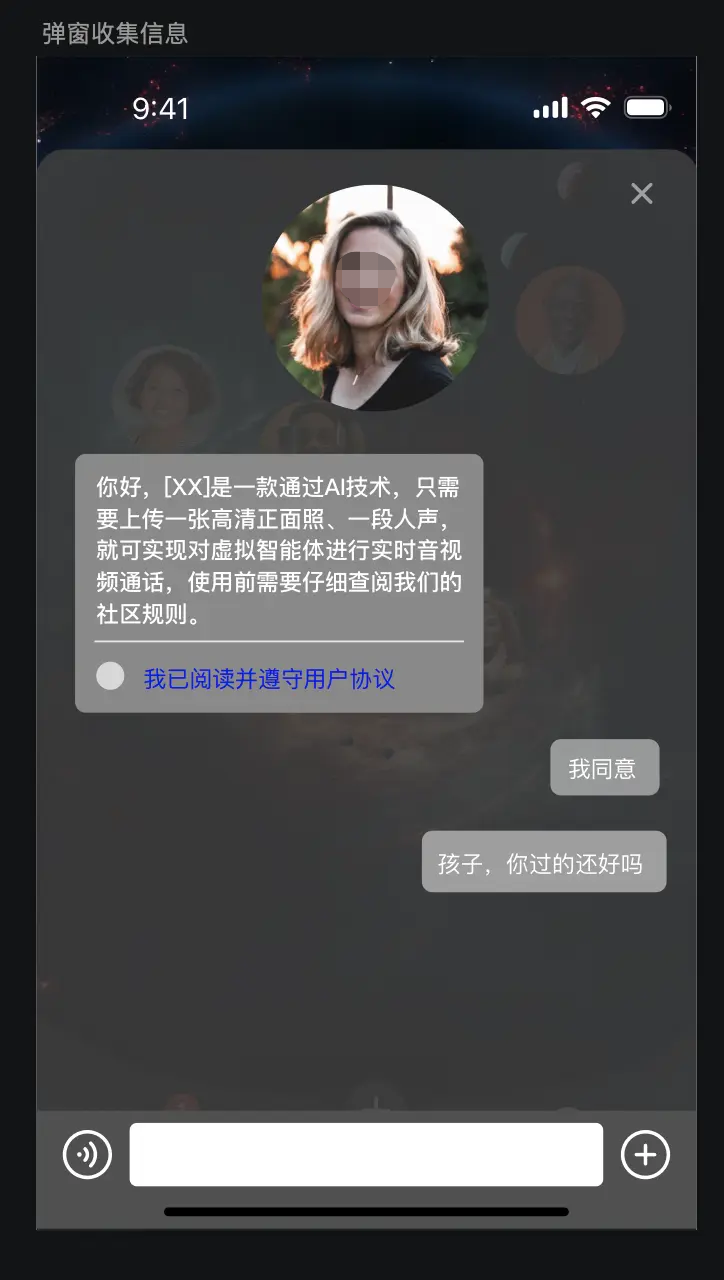
还是先分析布局,半弹窗页面,底部能发送文字,整体为对话信息页面。
- 半弹窗采用 showModalBottomSheet 底部弹出给一定的透明度
- 对话部分采用Column + 滚动容器实现
- 语音模块采用端本身的原生TTS组件
关键代码细节如下:

3)实时交流页面
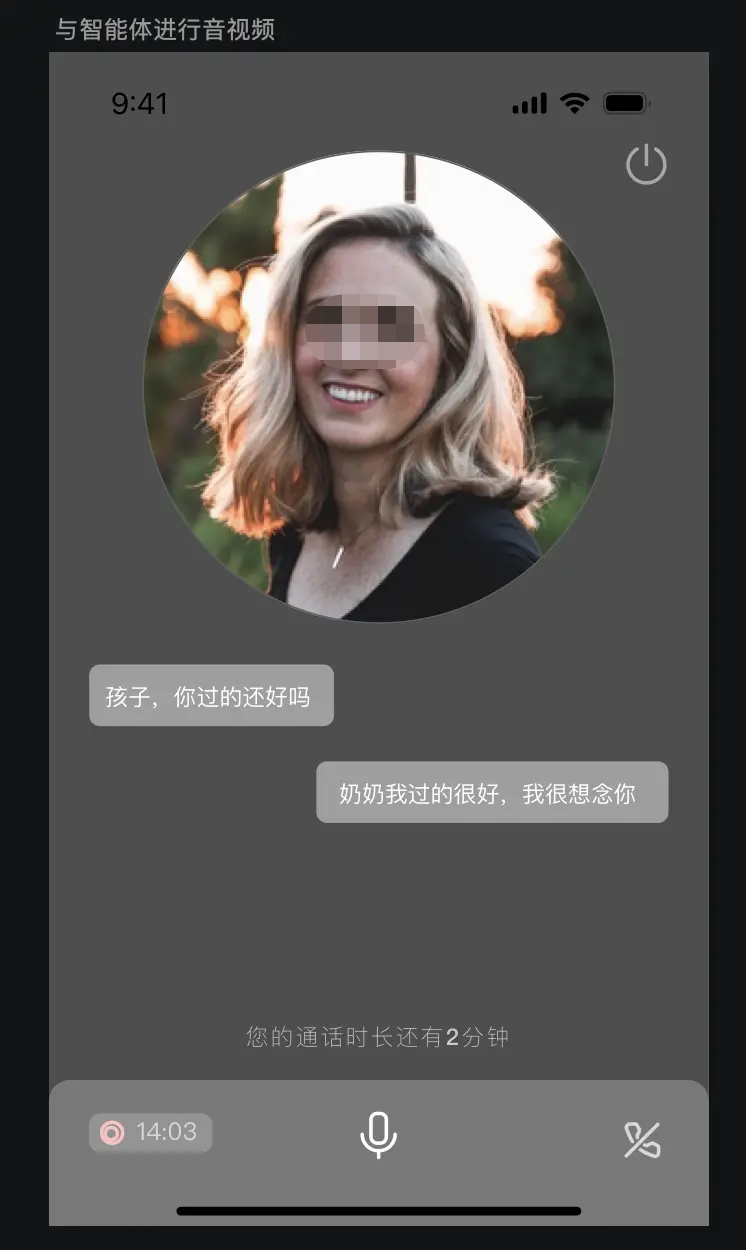
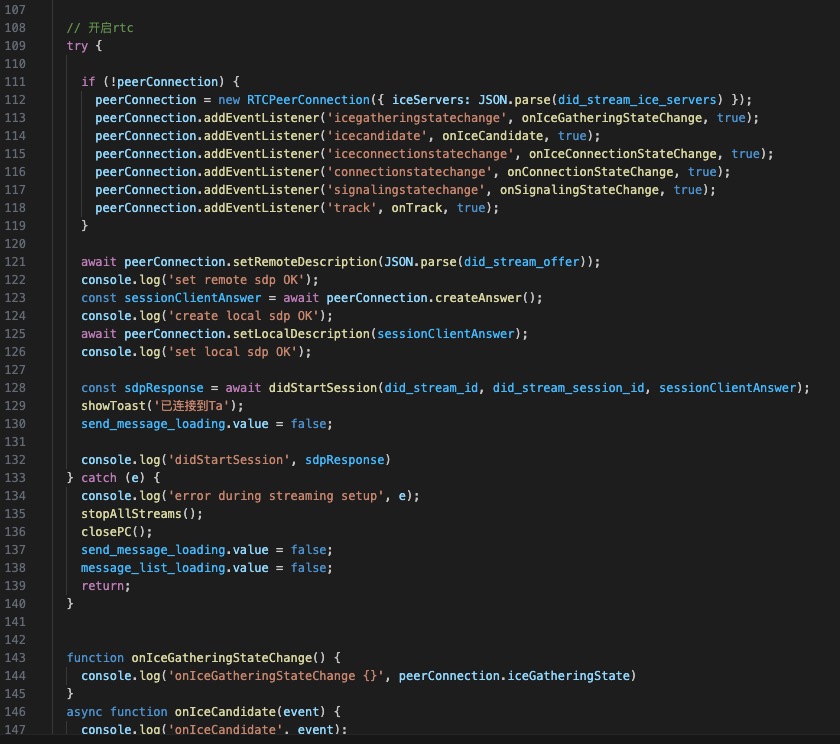
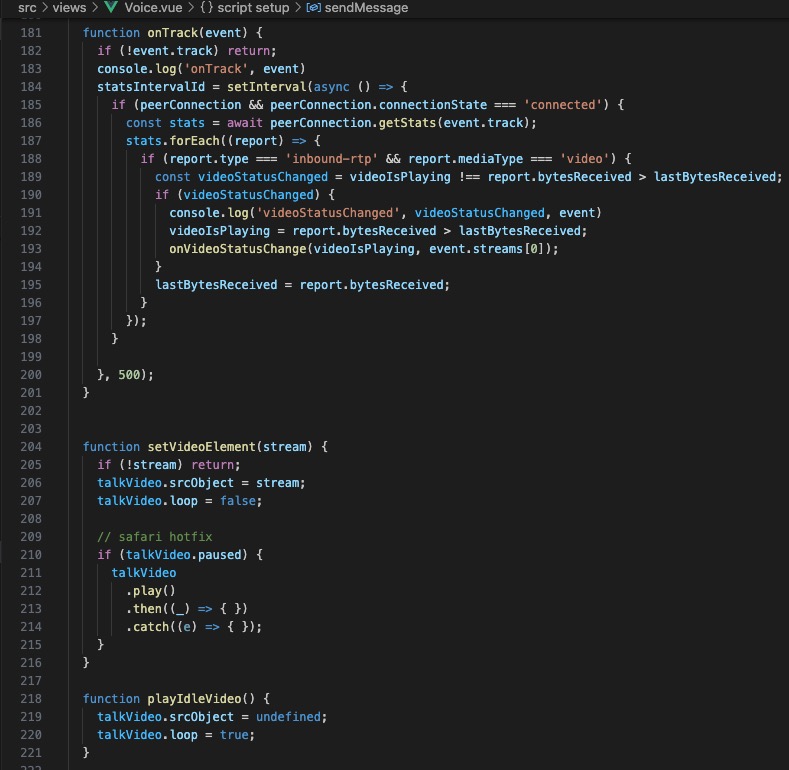
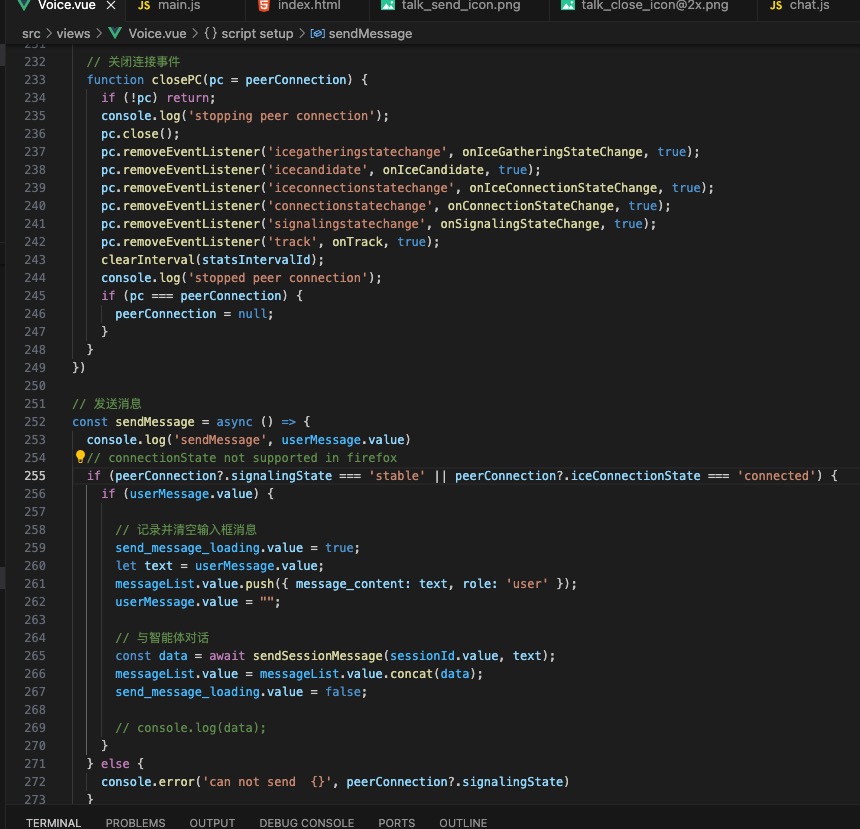
这块才是踩坑的开始,原来使用D-ID的时候,Demo是纯前端的方案,当时以为都是标准WebRTC,而且Flutter本身也有支持WebRTC的标准组件,就没太考虑端的兼容性问题。
实现后发现,不同的Android版本及IOS版本对原生WebRTC的支持都存在或多或少的兼容问题,最后决定更换对话为H5页面,采用端+H5方式解决兼容问题,关键代码如下:
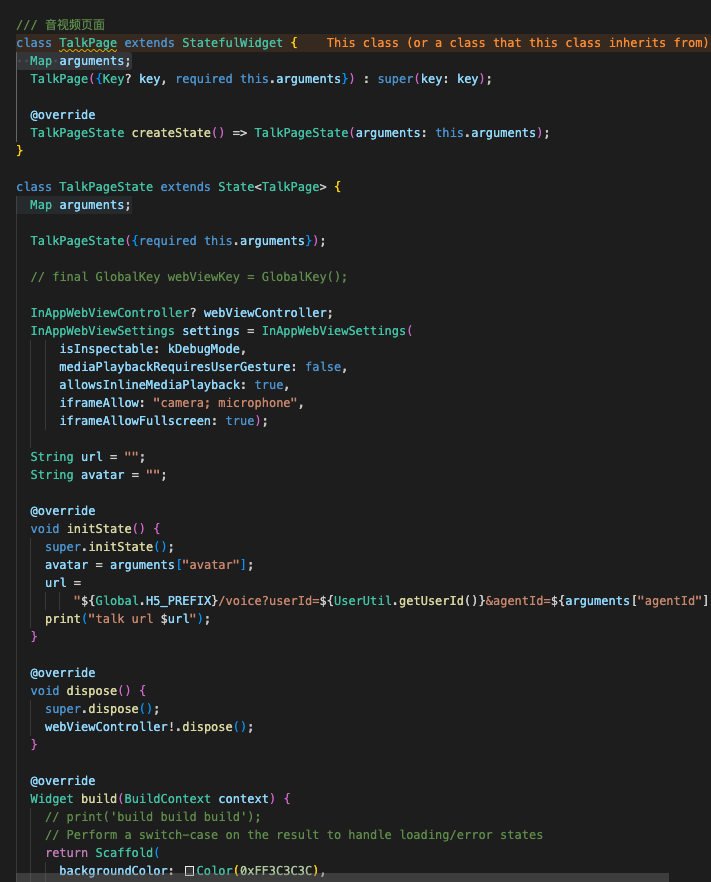
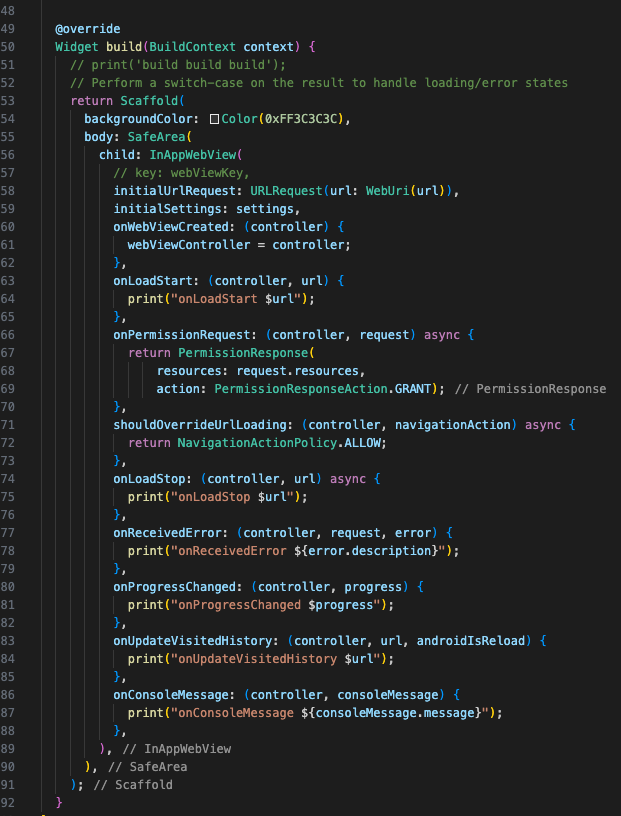
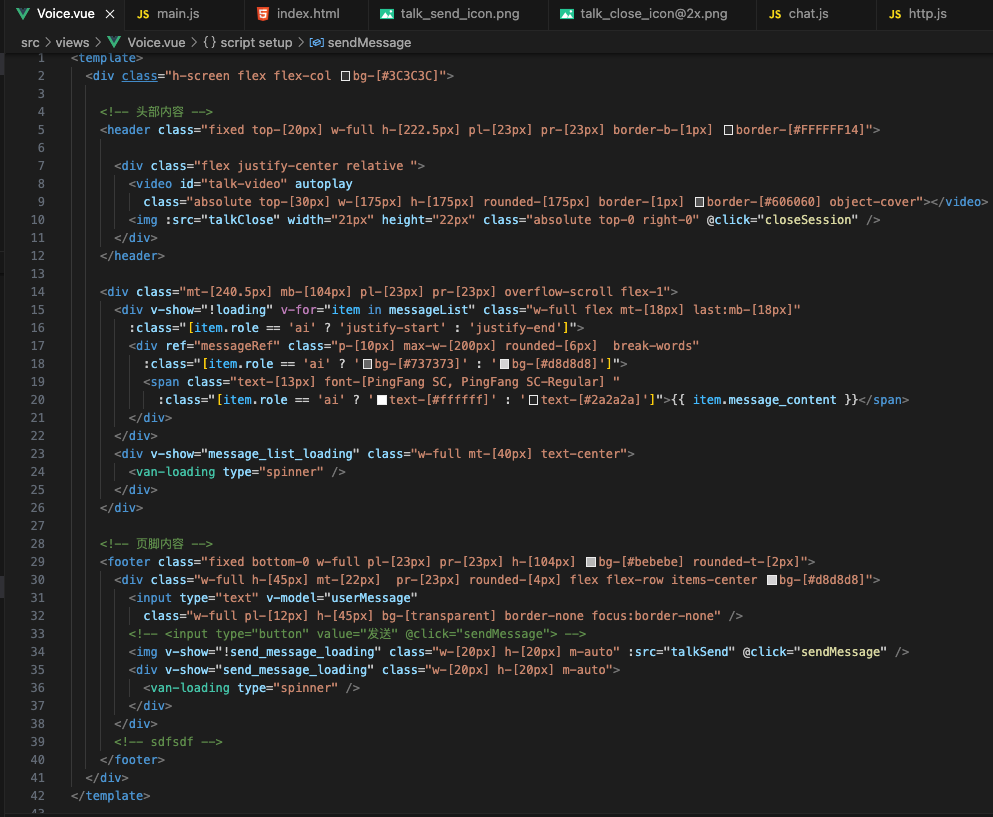

其他零散页面,难度不大,就不着重说明了,下面是服务端的实现细节。
2. 服务端实现
笔者对JAVA,Go,Rust相对熟悉,但由于需要对接不同的模型及第三方sdk都是python的,Python服务端语言成本较低,小规模下优点更多。
- 语音TTS模块,采用了ElevenLab,声音克隆能力对比讯飞、微软TTS、火山引擎语音包后,效果较佳
- 对话交流模块,采用了GPT4,多轮对话及角色扮演对比,GLM3/文心一言/通义千问,效果较佳
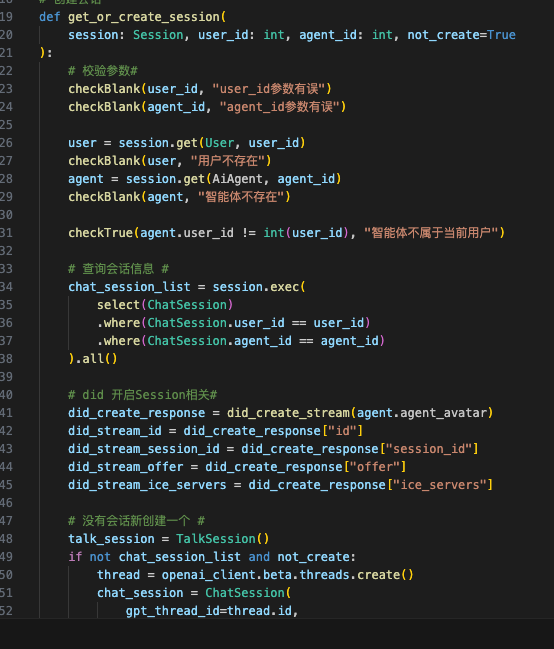
- 整体流程,首先APP端语音转文字,通过Websocket传到后台,用GPT4 Assistant回复,得到的文字,在通过ElevenLab 转为语音,最后调用D-ID用声音驱动图片的口型(已经预感到整理流程会很冗长)
关键代码逻辑如下(关注下,后续开源出来):
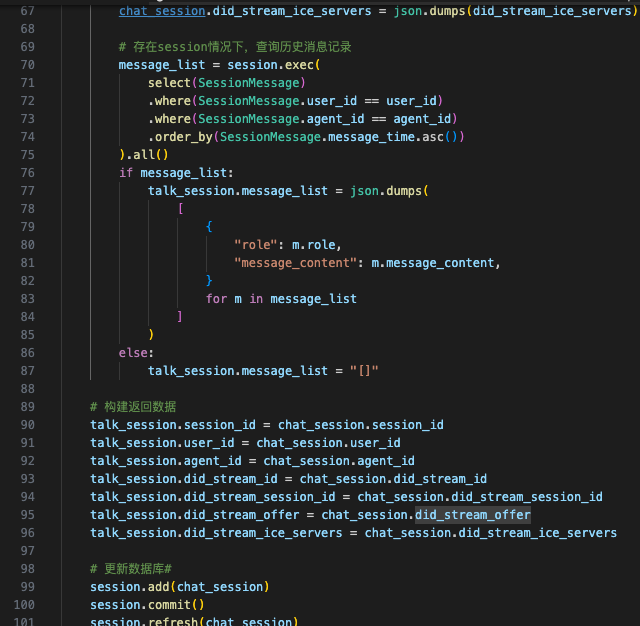
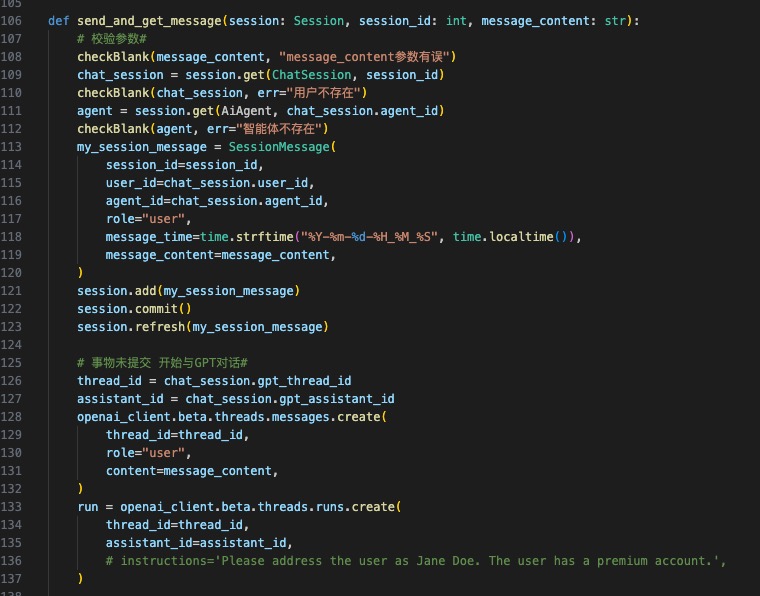
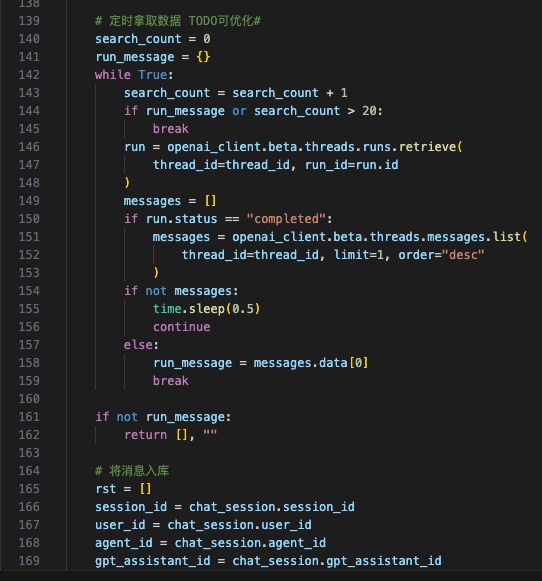
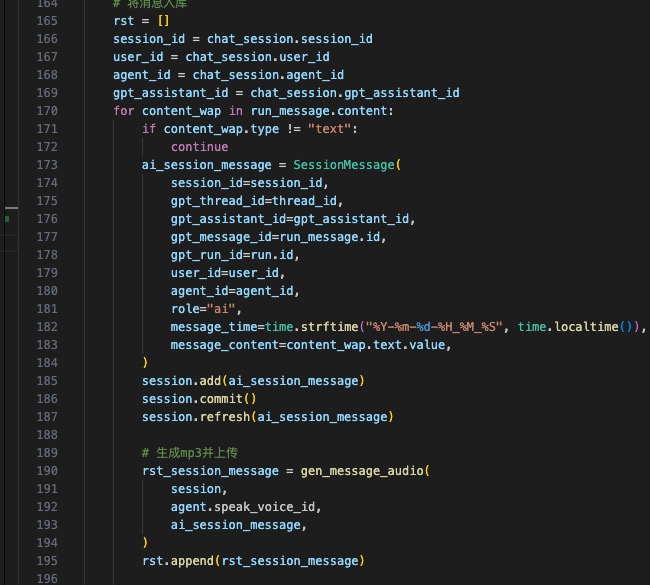



至此,Demo版的开发完成了,下一步开始我们的内部吐槽环节。
五、Demo版内测
无比成就感的开发完APP端,H5端,服务端,开始和身边朋友进行内测:
假朋友A:男哥,说完话,咋1分钟才能响应
假朋友B:+1
假朋友C:+1
….
我:哎呀,我要先把语音转文字,文字给到GPT,GPT给我回复,我还要调接口生成语音,在通过语音驱动图片说话
假朋友D:啊,然后那,为什么这么慢呀
假朋友E:+1
假朋友F:+1
假朋友N:哎呦,辣鸡呀,这BUG太多了,男哥你不行呀,果然产品是不能参与研发的
我:。。。
于是开始了各种bug的修复,各种优化。

最后将每次的沟通响应缩短到30秒,汗!也是很慢,所以现在有俩条路,一是继续优化,或是自己训练模型,或是使用metahuman超写实模型,二是从产品角度改变思路。
六、产品改进调研
通过声音驱动口型的不同技术调研:
SadTalker:https://github.com/OpenTalker/SadTalker
西安交通大学、腾讯人工智能实验室、蚂蚁集团共同发布的一个模型,让头像能够说话,使用WebUI Colab白嫖后,发现还是比较慢的,如果图片质量不高,效果也会更差。
Wav2Lip:https://github.com/ajay-sainy/Wav2Lip-GFPGAN
Colab部署后,对视频文件支持较好,同时GFPGAN还可以修复不协调的口型,但是图片支持一般,需要自己改造,同时项目比较老实,也3080,4080需要自己升级改造,并行逻辑也需要增强(在B站看到有人改造后效果还可以,但是也不能完全达到实时,一个500*500,1分钟左右的视频,大概在20-30秒的延迟)。
VideoReTalking:https://github.com/OpenTalker/video-retalking
个人感觉,更像是SadTalker的升级版,对固定身位的图像视频支持比较好,但是图片说话,需要改造,同时对分辨率要求较高,最后还是延迟的问题,1分钟视频,4080最好成绩13秒。
最后,发现只要是和真人相关的图像效果都不是很好,因此改变了下调研思路,从有戏建模的角度来衡量是否能够完成我要求。
MetaHuman:是虚幻引擎发布的超写实的数字人类,整个身体和空间都可以进行驱动,咋一看找到了福音,不能重蹈D-ID的覆辙,一部iPhone 12(或更新型号)以及一台台式电脑就能化身为完整的面部捕捉和动画解决方案,我父亲去世的时候,也没留下太多的视频和声音,把面部的表情和身体特征从视频和声音中提取出来,还是比较麻烦的一件事,其他人要得重新来一遍,对于还在世的人比较友好,可以作为一个备选方案,如:将一个人的照片,3D补齐后,优化细节,导入MetaHuman的模型中。
NVIDIA Omniverse Audio2Face:https://www.nvidia.cn/omniverse/apps/audio2face/
官网很牛的介绍:使用生成式 AI 可以即时从一个音频来源创建面部表情动画。这不就是我心心念念的吗,看了看上手难度,有点打鼓呀,又联系了下企业本地版的价格,好的,我错了。
服务端的主流方案能够搜索的,还有国内外论坛求助的,主流大概这些,大概花了1周的时间,是时候改变下思路了。
文章系列完成后,会把相关的原先,设计,源码,数据库等一同开源出来。
未完待续。
本文由 @AI产品李伯男 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









仔细看完了第一篇和第二篇,很高兴国内也有精英在跟我一样关注这个方面的应用并尝试动手制作!有时间可以加个V好友。主要架构上,基本还是去年11月之前主流的一些方案和思路,没有从技术角度去研究诸如GTPs商店里有没有现成的同类模型,或是github里参考一些应用,不过作者毕竟是产品经理,已经是非常难得了(默默嫌弃了一下我这边的产品小伙……)
可以交流下,v: libonan_com