
 起点课堂会员权益
起点课堂会员权益人工智能的人工部分—数据标注(下)
大模型背后,大多需要数据标注甚至人工标注的支持,那么,怎么理解数据标注呢?这篇文章里,作者主要从业务角度出发,介绍标注规则的细则构建、标注团队培养与管理的具体方法,一起来看。

如今的人工智能已是大模型的天下,但再强的智能,再大的模型,也需要人工标注的支持。上篇文章主要介绍了数据标注的分类、标注规则制定的原则,本篇文章主要从业务角度出发,介绍标注规则的细则构建、标注团队培养与管理的具体方法。
一、标注规则构建
为了便于大家理解,本模块主要参考王阳明先生“格物致知”的逻辑去展开,说明标注体系的搭建过程,就是一个“悟道”的过程,当然自己才疏学浅,如有运用不当的地方,希望大家多多包涵!
1. 单因子拆解标注——析物
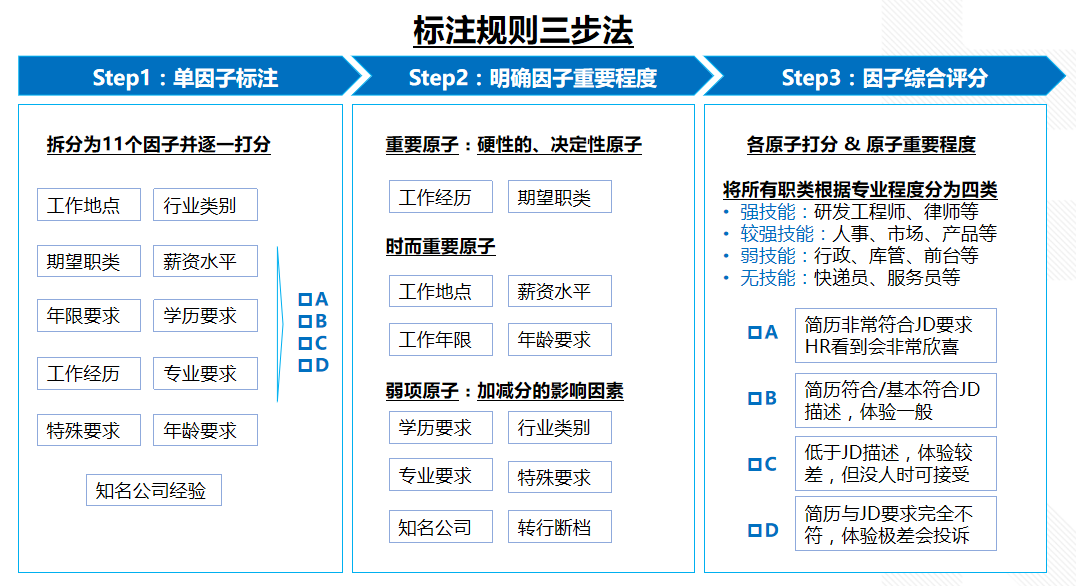
上篇文章讲了标注规则的三步法:单因子标注、多维因子排列组合、综合策略评分,其中最基础也是最重要的一环就是第一步:单因子标注,就是将所有影响标注结果的因素依次列举,对每个影响因素单独标注。
例如,标注简历与职位的匹配度,即模拟HR招人的思路给推荐的简历打分,首先要将影响HR招人的因素全部列出来,例如工作地点、行业类别、薪资水平、学历要求、专业要求等。
然后分别对每个因素进行标注打分,打分时要将行业的一些通用规则考虑进去,例如,某职位要求学历是本科,这里的本科大概率是指全日制统招本科,而不是花点钱就能上,或者根本不需要学习就能获得证书的成考或自考本科。
那么问题来了,如何识别统招学历呢?什么样的学历属于全日制的呢?哪些院校是统招的呢?野鸡大学算不算统招的呢?有没有识别野鸡大学的方法?
仅学历一个因素标注细则就很多,识别逻辑也很复杂,我们要将十几项因子里的每一项,都进行多维度深度思考与分析,并给出可衡量的标注规则与指标。这一层的核心是“析物”,即深入剖析每一个因子,直到剖到每个因子的根部,程颐认为,凡一物上有一理,须穷致其理。
2. 多因子排列组合——量物
在上篇文章就讲到,多因子排列组合不是单纯的给每个因子赋予固定的权重,而是将每个因子结合具体场景,分析各因子在具体场景中的的重要程度,因为场景不同,标注细则就不同。
那么有哪些具体场景呢?
第一,标注对象不同,标注细则就不同,在招聘业务中,标注对象是职位,职位类型不同标注的关注点就不同,比如,招聘销售类岗位关注行业经验、业绩能力、客户群体等,招聘蓝领岗位只要候选人愿意做、身体健康即可,招聘财务类岗位则会要求资格证书。
第二,各影响因子的程度不同,标注细则也不同,比如要招聘一位初级文员,但是候选人年龄超过了50岁,再比如要招聘一名销售员,但是候选人五年前做过销售,现在早就不做销售了,而且也不想再做销售了,类似这种情况可能因为这一个因子,总分就可能给到0分。
所以标注细则的场景数量,是标注对象类型与影响因子的乘积,但在招聘业务场景中,标注对象类型有1000多种,影响因子有十多种,所以标注细则是一万多条吗?在实际操作中不可能列出所有场景,并给出所有的标注细则,这些场景需要标注员基于实际业务灵活运用规则。这一层的核心是“量物”,即衡量所有标注对象,并将其与影响因子融会贯通,活学活用,找到那个平衡的度。
3. 各因子融会贯通——悟物
在第二步中讲到标注细则的场景数量,是标注对象类型与影响因子的乘积,这个数量级太大了,在实际业务中需要融会贯通,但是怎么能做到融会贯通呢?有没有一些归类方法,或针对不同场景的指导思想呢?
答案是肯定的,首先,影响因子可以按照对最终结果的重要程度分为三类:重要因子,时而重要因子,弱项影响加减分的因子,其次,职位类别可以按照对专业技能的强弱分为四类:强技能类职位,较强技能职位,弱技能职位,无技能职位,最后,根据此等分类,我们得到了12种场景,此时我们可以针对这12种场景做细节的标注规则了。
分类之后是汇总,就是所谓的融会贯通,不管是规则制定者还是标注员,到这一阶段都要到达一种境界,就是忘掉之前的细节规则,从良知出发评估简历与职位的匹配度,是非常匹配,还是比较匹配,还是不太匹配,还是非常不匹配,也就是王阳明先生所谓的“致良知”。
完成最终评分后,不要忘记将不匹配的原因以标签的形式固定下来,这样便于后面的问题分析与策略优化。
二、标注团队管理
1. 新人培训与管理
无规矩不成方圆,可见规矩是形成方圆的关键,但是方圆之内要有田地苗木,才是一块好的方圆之地,标注规则就是这规矩,而标注所依赖的领域知识就是其中的田地苗木,所以新人入职首先要学习标注规则,但同时也要学习领域知识,尤其是专业性比较强的领域,如此两条腿走路,才能学好整个标注体系。
在学习的前提下,标注练习是必不可少的,首先可以做单因子标注的练习,合格之后再进行综合评分的练习,此时的练习,最好是有正确答案的,这样可以随时监督新人练习的进度和质量,也可以制定一套新人培训学习体系,里面不仅要包括要学的内容,还要列清楚练习期间的任务数量,以及每个阶段所要达成的质量指标,以此来评判新人培训期间的成绩。
2. 质量把控与管理
相信做过标注工作的同学都明白,低质量的标注数据会直接影响模型的训练效果,所以数据质量是标注工作的重中之重。保证标注质量的前提是做好任务的培训,明确标注需求、标注方法和验收标准。数据验收环节一般会采用自检、交叉检验,或者按任务进行分类检验的方式进行检验,甚至大一些的标注团队会设置专门的质检小组,对标注员的标注结果进行抽检或全检。
本文重点介绍另外一种质检方式,即提前插入正确样本,以检验标注质量的方式,此种方式可以节约一定的成本,因为不用进行双验或多验了,还能时刻检验标注员的工作态度,以及对任务是否真的理解,能否达到要求的质量标准,如果发现质量不合格,则可以立刻更换标注员或进行再次培训。
此种方式主要适用于结构化且需要长期标注的项目,要提前设置好正确样本,建任务时插入样本,至于插入的比例,可以根据具体任务需求,或不同标注人群进行设置。
需要注意的是,一组正确样本如果长期使用,可能标注员都记住哪些是样本了,所以一定要经常更换正确样本,以达到“混淆视听”的效果,此外还需要保证正确样本的质量,不能出现正确样本不正确的情况。标注质量把控是一项非常重要,也非常有难度的事情,后续可能会单独写一篇质量把控相关的文章,请大家多多关注。
至此,整个标注体系的重点工作或原则都讲完了,如有不足或错误的地方,还希望大家能不吝赐教,指正出来。开篇就说到,如今的人工智能已是大模型的天下了,那么下篇文章会重点讲讲大模型标注那些事,请大家多多关注。
本文由 @艳杰 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


