起点课堂会员权益
起点课堂会员权益
深入解析:如何高效评估RAG系统(一)
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等本文深入探讨了RAG系统的优势、挑战以及如何通过RAGAS框架对其进行有效评估,旨在为读者提供一套系统的理解和应用RAG技术的指南。

一、为什么要选择RAG
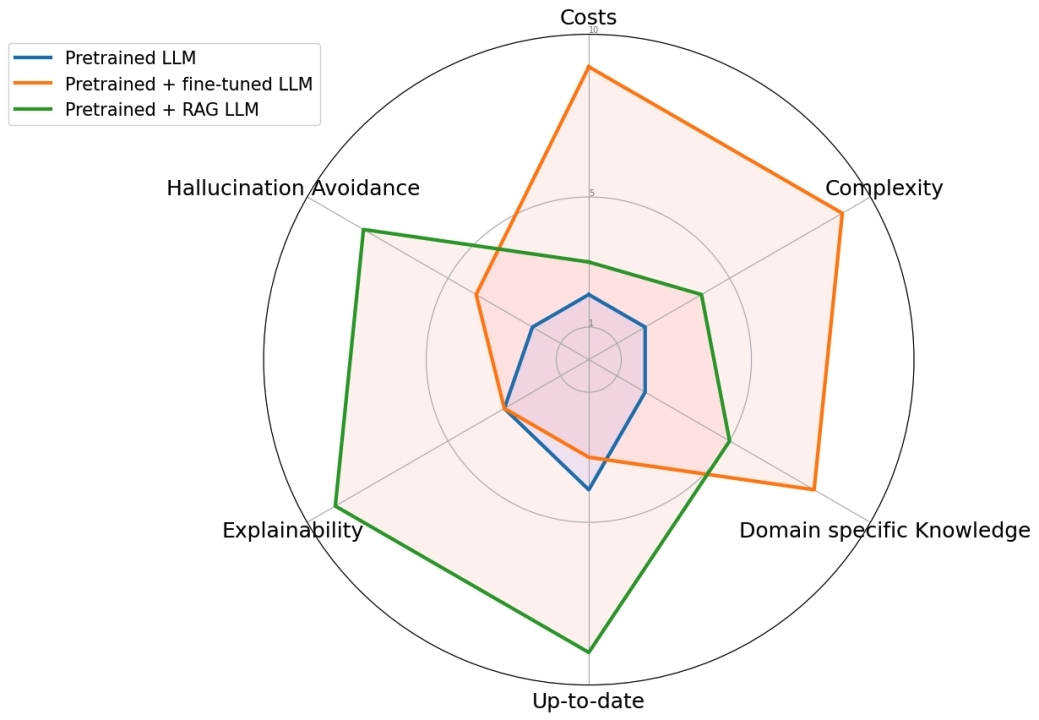
众所周知,大语言模型(LLM)存在”幻觉”问题,经常一本正经的胡说八道,除此之外还有在知识无法及时更新、可解释性差等问题;RAG(检索增强生成)和Fine-Tune(微调)是目前主流的两种解决方法,他们之间的对比如下:
在实际应用中,判断是采取RAG还是Fine-Tune方案可以通过以下几个维度判断:
笔者所处的行业是医疗疗行业,是典型的”严肃”应用场景,要尽量避免”幻觉”问题,又因为属于偏垂直的应用,可用于微调的数据有限,所以RAG就成为了首选的方式。

RAG的介绍和快速搭建可以参考之前的文章基于开源框架快速搭建基于RAG架构的医疗AI问答系统,可选框架有很多,如果完全是无编程经验的建立用coze.cn(具备科学上网条件的用.com)更容易上手一些,基本搭建流程都差不多。
二、如何评估RAG系统
“Demo只需一天,好用至少半年”,RAG是典型的入手简单做好难。自从跟随大模型爆火之后,各种RAG框架层出不穷,他们内置的大模型底座、检索策略等各不相同,我们无论是选择自己手动搭建还是采用第三方RAG框架,都需要了解如何去评价它。
首先我们再回顾一下RAG的基本工作流程和关键节点:
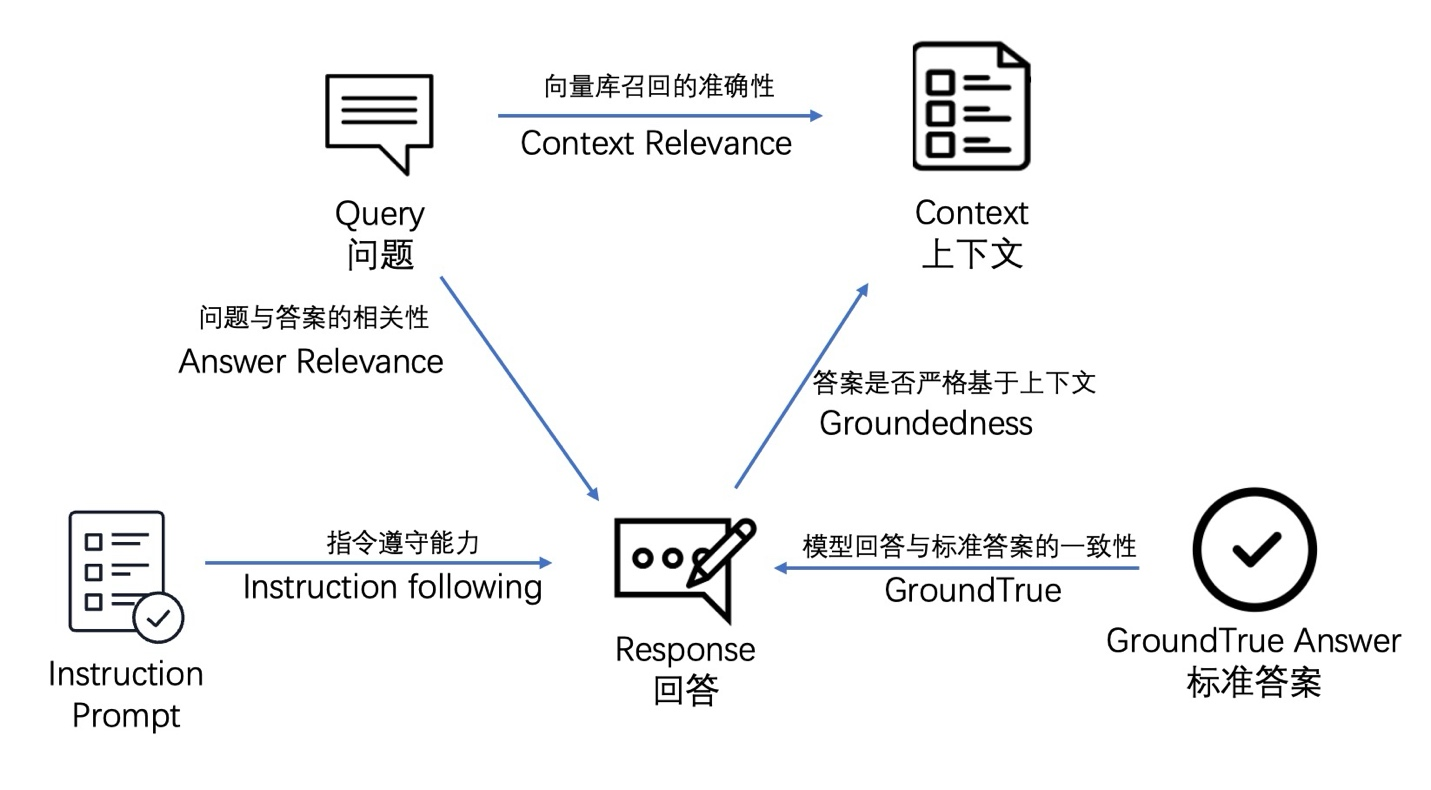
RAG包括三个核心内容,用户的输入(Query)、检索到的知识(Context)和模型最终给出的回答(Answer),他们之间两两对比可以得到三个基础指标,分别是:
- Context Relevance衡量召回的内容和问题之间相关程度。如果相关度很低甚至召回了毫不相关的内容会给LLM提供错误的Pormpt,这个也是目前RAG系统最大的挑战之一。
- Groundedness(Faithfulness) 该指标衡量了生成的答案在给定的上下文中的事实一致性。它是根据答案和检索到的上下文计算出来的,如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。
- Answer Relevance 该指标衡量回答内容和提问内容之间的相关性,如果出现”答非所问”或者回答内容不完整,该指标会给出一个比较低的分数。
- Answer Correctness对于一些有标准答案(Ground Truth)的场景,还可以评估回答的内容和标准答案的一致性
- Instruction Follwing另外在挑选底座大模型的时候还可以评估不同底座模型的指令跟随能力(尤其是针对小参数模型),简单来讲就是”听话”的能力
跟所有基于AI的应用一样,RAG应用可以通过人工端到端的评估方式进行评估,比如对于医疗问答系统,可以让专业的医生直接给输出的内容打分,这种方式是最可靠的的但是很难覆盖所有场景且费时费力;除此之外就是通过自动化量化评估的方式给出评估结果,接下来将着重介绍几种自动化评估的框架。
三、开源RAG评估框架RAGAS
项目地址:https://github.com/explodinggradients/ragas
论文:https://arxiv.org/abs/2309.15217
RAGAS应该目前评估比较全面,而且各种文档也比较齐全的评估框架了,而且跟Langchain等框架做了集成,可以直接调用。RAGAS论文中提到三个指标,现在已经扩展到九个了:
Faithfulness(忠诚度) RAGAS的计算原理是通过大语言模型(LLM)从生成的答案中拆分成一组描述,然后让大模型去判断是否是否可以从上下文中推断出来,主要是通过提示词工程实现,Prompt如下:(注意:RAGAS内置都是英文的提示词,我们需要转换成中文)
考虑给定的上下文和以下陈述,然后判断这些陈述是否得到上下文信息的支持。 在得出结论(是/否)之前,对每个陈述进行简要解释。 最后按指定格式依次给出对每项陈述的最终裁定。 不要偏离指定格式:
[语句 1]
…
[语句 n]
例如某个问题被拆成5组描述,大模型判断3组可以从上下文推断出来,得分就是3/5=0.6
Answer Relevance (回答相关性)RAGAS采用的是经典的余弦相似度来进行判断,首先使用大语言模型 (LLM) 从生成的答案中逆向设计问题的“n”个变体,然后计算生成的问题与实际问题之间的平均余弦相似度。引用官网给的例子:
Answer:France is in western Europe.
Question 1:“In which part of Europe is France located?”
Question 2:“What is the geographical location of France within Europe?”
Question 3:“Can you identify the region of Europe where France is situated?”
因为这个指标跟Context无关,所以也可以用来测试不是基于RAG的问答系统。
Context Precision(上下文召回精度) 是一个评估召回的指标,核心思路给定一个问题,然后判断基于这个问题召回的内容跟金标准是否相关,计算步骤拆解如下:
第一步:判断每个chunk是否跟ground truth相关,假如一个问题和召回了top5的chunks,其中不同chunk分别用LLM进行判断相关性:
- chunk1 : 相关
- chunk2: 不相关
- chunk 3: 相关
- chunk 4:不相关
- chunk5:相关
第二步:计算每个chunk的 Precision@k值,在位置k之前的相关chunk数量除以 k,分别计算结果如下:
- Precision@1 = 1/1 = 1.0
- Precision@2 = 1/2 = 0.5
- Precision@3 = 2/3 ≈ 0.67
- Precision@4 = 2/4 = 0.5
- Precision@5 = 3/5 = 0.6
第三步:计算 Precision@k 的平均值
平均Precision@k=1.0+0.5+0.67+0.5+0.6=53.27=0.654
这里计算均值前引入了位置的信息判断,跟答案相关的越靠前,得分就会越高,Context Precision 指标可以看做是Faithfulness 指标的的一种延伸,二者都是用来评价召回内容跟金标准的一致性。
Context Recall (上下文召回率)也是一个评估召回的指标,它的思路跟Answer Relevance有点接近,只不过他是把ground truth拆分了几份,每一份再去判断跟context的相关性,最终计算一个比例出来。
Context entities recall (上下文实体召回率) 这个是最近刚推出的指标,引入了实体的概念,通过计算context和ground truth中同时存在的实体数据在ground truth 实体中的比例来衡量召回的内容是否接近ground truth,举个例子:
假设ground truth中抽取的实体如下:[‘长城’, ‘北京’, ‘秦始皇’, ‘公元前221年’, ‘世界遗产’]
context1中抽取的实体 [‘长城’, ‘北京’, ‘秦始皇’, ‘中国’]
context2中抽取的实体 [‘长城’, ‘世界遗产’, ‘中国’]
计算相似度:
context1中的相关实体:[‘长城’, ‘北京’, ‘秦始皇’]
context2中的相关实体 : [‘长城’, ‘世界遗产’]
context1的召回准确率0.6>context2的召回准确率0.4,我们应该选用context1的召回策略。
Answer semantic similarity (回答语义相关度)也是一个评估回答结果跟金标准一致性的指标,在RAGAS中,Answer Relevance指标通过逆向生成问题对比得出分数,这个就比较简单了,直接把answer和ground truth 分别做一个向量化,然后直接通过语义相似度判断一致性。语义相似度的判断是通过余弦相似度来实现的。
Answer Correctness (回答准确性)RAGAS提供的另外一个评估系统answer和ground truth 一致性的指标,只不过他是上一个指标Context entities recall 在结合factual correctness(事实一致性),两边分给一个权重然后计算最终得分,但是官网并没有提到事实一致性是如何计算的,那只能是人工评价后计算一个调和平均数,我们可以简单理解为这个指标是把人工评价和语义评价做了一个综合。
Aspect Critique(特定方向评估)RAGAS提供一个可扩展的评估方向,其中内置的了,
无害性(Harmlessness)、恶意性(Maliciousness)、连贯性(Coherence)、正确性(Correctness)和 简洁性(Conciseness)5个评估方向,评估方法是通过写一个提示词然后让大模型来进行判断是否存在上述问题,我们也可以自定义要评估指标,通过 SUPPORTED_ASPECTS 这个字段进行维护,每个指标都可以单独调用。
假设我们有一篇文章需要评估其质量,你可以使用这些方面来进行评估:
- 无害性检查:判断文章内容是否会对读者造成心理或情感上的伤害。
- 恶意性检查:判断文章内容是否包含欺骗、操纵或伤害他人的意图。
- 连贯性检查:判断文章内容是否逻辑连贯,信息传达清晰
- 正确性检查:判断文章中的信息是否准确无误
- 简洁性检查:判断文章内容是否简洁明了,没有冗长和不必要的信息
Summarization Score (总结能力评分) 在RAG系统中,假如我们将 top k 设置为 5,那么通常会召回 5 个相关的知识片段。这些召回的知识片段会作为上下文的一部分全部传递给大语言模型。大语言模型会利用这些上下文信息来生成更准确和相关的回答。所以召回的内容进行总结的好坏也会影响最终输出的效果,好的总结应该包含原文中的所有重要信息,这个指标就是用来评估这个能力。实现思路如下:
- 首先从原文中提取出一组重要的关键词或关键短语。
- 然后基于这些关键词生成一组问题。
- 接着将这些问题应用到总结中,检查总结能否正确回答这些问题。
- 最后计算正确回答的问题数与总问题数的比值。
借用官网的例子:
摘要:摩根大通公司(JPMorgan Chase & Co.)是一家总部位于纽约市的美国跨国金融公司。截至2023年,它是美国最大的银行,也是全球市值最大的银行。公司成立于1799年,是主要的投资银行服务提供商,拥有3.9万亿美元的总资产,并在2023年《福布斯》全球2000强排名中位列第一。
关键词: [ “摩根大通公司(JPMorgan Chase & Co.)”,
“美国跨国金融公司”,
“总部位于纽约市”,
“美国最大的银行”,
“全球市值最大的银行”,
“成立于1799年”,
“主要的投资银行服务提供商”,
“3.9万亿美元的总资产”,
“《福布斯》全球2000强排名第一”,
]问题: [ “摩根大通公司是一家美国跨国金融公司吗?”,
“摩根大通公司总部位于纽约市吗?”,
“摩根大通公司是美国最大的银行吗?”,
“截至2023年,摩根大通公司是全球市值最大的银行吗?”,
“摩根大通公司被金融稳定委员会认为具有系统重要性吗?”,
“摩根大通公司于1799年作为大通曼哈顿公司成立吗?”,
“摩根大通公司是主要的投资银行服务提供商吗?”,
“摩根大通公司是全球资产排名第五的银行吗?”,
“摩根大通公司运营着收入最大的投资银行吗?”,
“摩根大通公司在《福布斯》全球2000强排名中位列第一吗?”,
“摩根大通公司提供投资银行服务吗?”,
]答案: [“0”, “1”, “1”, “1”, “0”, “0”, “1”, “1”, “1”, “1”, “1”]
最后我们把RAGAS体系的指标做一个总结:
评估召回能力,关系到检索策略、chunk策略:
- Context Precision
- Context Recall
- Context entities recall
基于上下文的回答回答准确率,关系到大模型的指令跟随能力:
- Faithfulness
- Answer Relevancy
- Answer Semantic Similarity
- context-answer
- Answer Correctness
- Aspect Critique
- Summarization Score
不依赖上下文也可以评估的指标:
- Answer semantic similarity
- Answer Correctness
- Aspect Critique
- Answer Relevance
上述内容结合了项目官网和个人的理解,如果理解错误的地方欢迎指正交流,后续文章后会接着介绍其他的RAG评估框架,敬请关注。
本文由 @Leo 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!