
 起点课堂会员权益
起点课堂会员权益详解用户体系/ID-Mapping
在实际生活场景中,我们可能会遇到很多无法获取用户设备号/手机号的场景或者更复杂的情况,基于这类情况,作者做出一个设想,并对相关方案和ID-Mapping做了详细阐述,一起来看。

一、大背景
中小企业的user_center_id(全域唯一id)是基于设备号/手机号生成,即需要获取用户的设备号/手机号才能生成用户在全域的唯一id,并且打通的是带有全域唯一id的数据,那么无法打通那些无法获取用户设备号/手机号的场景下产生数据。
罗列一下无法获取用户设备号/手机号的场景或者更复杂的情况:
- 用户作为游客打开H5页面但是还没购买就走了,没获取到用户设备号/手机号,流失一个销售机会但不知道原因也无法进行下一步动作。如果能够关联到已有的用户,那么我们可能可以再次对这个销售机会有所动作——可能是通过手机号/邮箱/私域/app,看关联到什么。
- 用户有多个设备,第一天在电脑上看了企业的某个网站上的摄影内容,第二天又关注了企业了微信号继续看摄影内容,第三天在手机上下载了app看了一会摄影相关内容(可能因为app的引导),在app内销售对其发起了会话开始聊关于摄影的内容,但没有意识到这是一个对摄影兴趣浓厚的用户,因为数据没有打通,可能错失一个及时销售的机会。
- 当客户进入私域时,只有微信号,关联不到全域内其他的数据,因而销售只能基于陌生的一次会话去挖掘销售机会,缺少深度的个性化的服务,没有懂用户的感觉。
- ……
基于此业务背景,我们做出一个设想:我们将若干个实体归拢到一起并将之命名为OneEntity。归拢虽然有据可依,但终究是基于大数据算法进行的设想,不可能与现实世界一模-样,因此,其只可能是“无限逼近”。在“无限逼近”的过程中,根据实体归拢的效果及能否贴上“特定标签”,OneEntity在理论上可以分为一般质量OneEntity、高质量OneEntity和高价值OneEntity。
其中,高质量OneEntity是指能够贴上“特定标签”的OneEntity,这里的“特定标签’会因业务和场景而异。不能够贴上“特定标签”的OneEntity,我们称之为一般质量OneEntity。而高价值OneEntity则是在高质量OneEntity的基础上提出进一步要求,不仅要能用标签等来精准刻画,还要达到实际意义上的可精准触达。
假设现在有上千亿条大数据世界里的实体数据,归拢得到的6亿个OneEntity。其中一般质量OneEntity 有4亿,高质量OneEntity有1.5亿,高价值OneEntity有0.5亿。
以触达营销场景为例,假设高价值触达UV的平均收入为0.2,则对0.5亿个高价值OneEntity来说,能够实现营收1000万;假设高质量触达UV的平均收入为0.05,能够实现营收750万;假设一般质量触达UV的平均收入为0.025,能够实现营收1000万。那么,对业务人员而言,高价值OneEntity就是其最想要的,高质量OneEntity也是不错的,一般质量OneEntity是退而求其次的选择,但没有经过任何归拢的实体数据则是技术人员不追求、业务人员不欣赏的。看似如果能把握好一般质量和高质量用户也能产生不错的效益。
二、业务流程
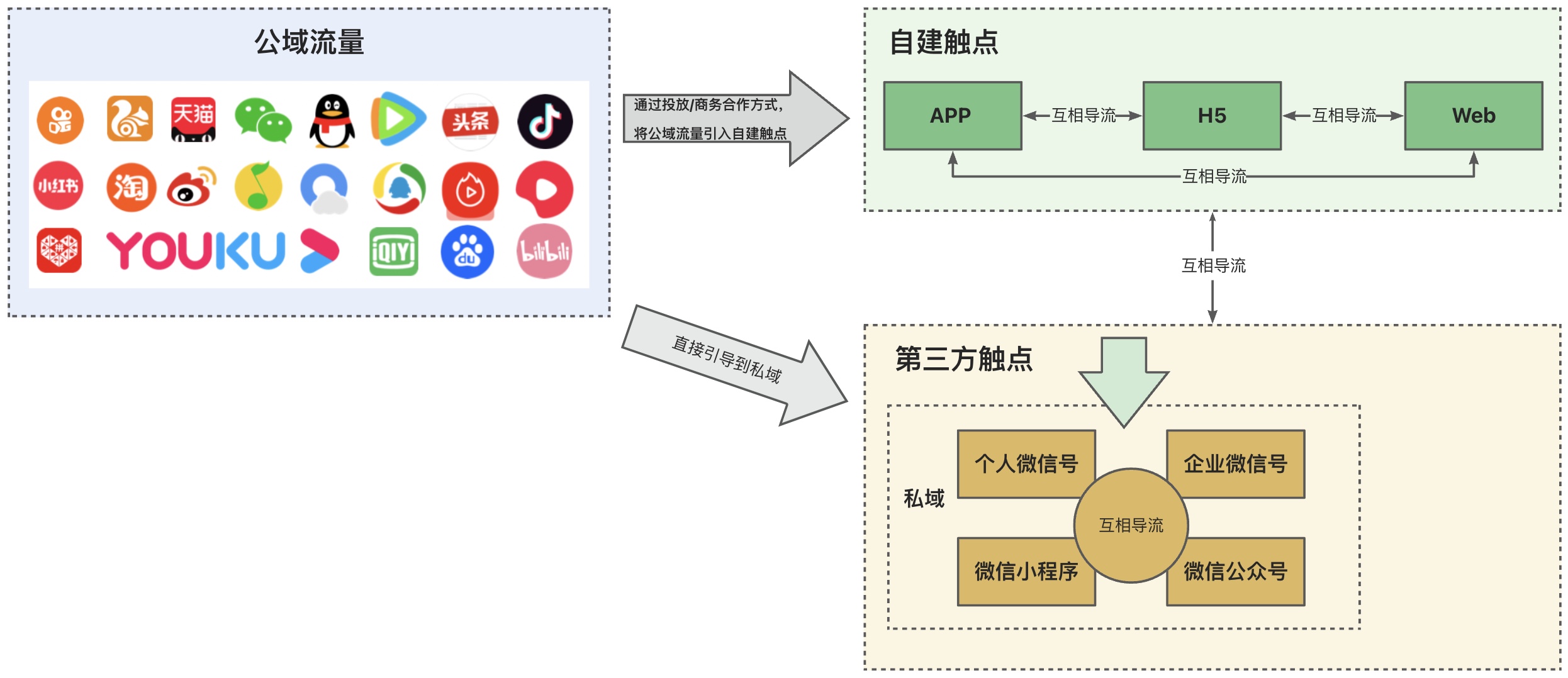
该业务流程基于用户旅程角度进行描述。
大多数的公司的业务流程如下:
- 通过投放或者商务合作的方式将公域流量导到自建触点上——App、H5、Web或者直接导流到私域。
- 自建触点之间会互相进行导流。
- 自建触点会将流量导到私域。
- 第三方触点之间会互相进行导流。
- 最后自建触点和第三方触点开始无序地导流,形成一张无中心的导流网络。
总的来说:
- 用户的旅程触及的点可能会比较多,因为集团内部的导流关系比较复杂。
- 在另一方面如果能将用户在各个触点的信息串联起来,将很大程度上能够全面描述客户的情况,形成客户档案,能够为各种营销动作提供价值,例如:销售针对客户个性化服务,根据客户旅程信息智能推荐,定时个性化发送触达任务等等。
三、方案
1. 概述
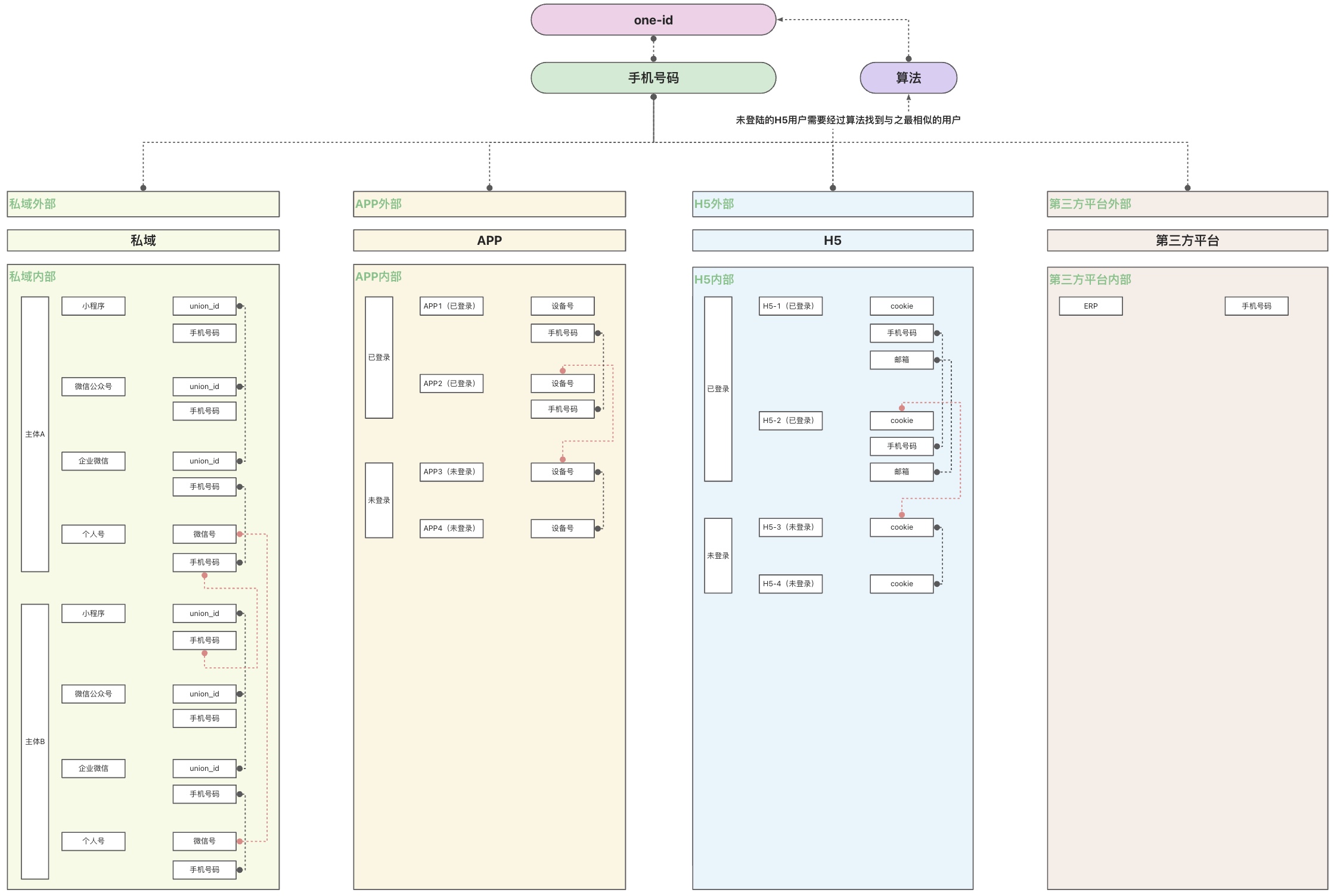
对于私域而言;
在私域内部,单个主体内,以union_id作为打通的第一优先级id,第二优先级id为手机号码,因为对于个人号而言没有union_id(不在主体下,在这里为了更全面地描述私域,将个人号也放在了主体下)。不同的主体之间打通的第一优先级id为手机号码,第二优先级id是微信号。
在私域外部,私域生态以手机号码为打通的id与外部的数据进行打通。
对于APP而言;
在APP内部,对于已登录的用户,使用手机号码进行打通。对于未登录的用户,使用设备号打通。对于已登录的用户和未登录用户之间的打通,使用设备号。
在APP外部,APP生态以手机号码与外部数据进行打通。
对于H5而言;
在H5内部,对于已登录的用户,使用手机号码进行打通。对于未登录的用户,使用cookie打通。已登录的用户和未登录的用户之间使用cookie打通。
在H5外部,对于已登录用户使用手机号码进行打通,对于完全未登录过的用户使用算法与one-id进行关联,可以使用相似度原理与one-id进行关联。
对于第三方平台而言;
第三方平台很多,例如:淘宝、小红书、抖音、天猫等等,但是订单一般都是进入ERP,因此仅写了ERP。使用ERP订单中的用户手机号码与外部数据进行打通。
最终以one-id作为全域的唯一id,关联全域数据。
四、框架
1. ID架构
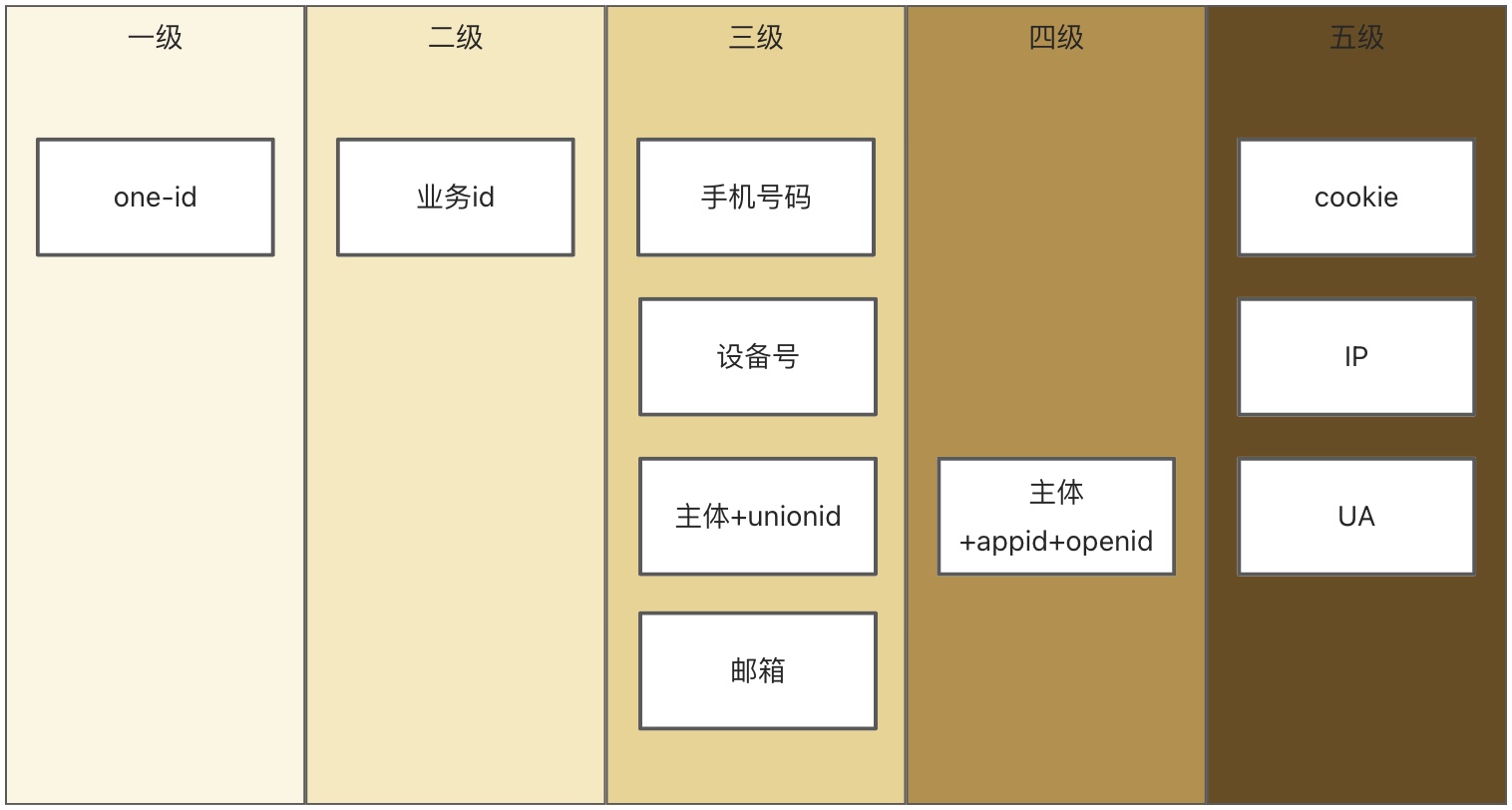
5级结构。
- 第一级:one-id。在逻辑上,该ID是直接标识用户。作为全域唯一标识一个用户的的ID。
- 第二级:业务id。在逻辑上,该ID是业务线对于用户的标识。
- 第三级:三级id。在逻辑上,该ID是标识用户的什么,强关联关系的ID,例如手机号码、设备号、[主体+unionid]、邮箱等等。
- 第四级:四级id。在逻辑上,该ID是三级id的子id。
- 第五级:五级id。在逻辑上,该ID是标识匿名用户的什么,弱关联关系的ID,例如cookie、IP、UA等等。
2. 关联整体架构
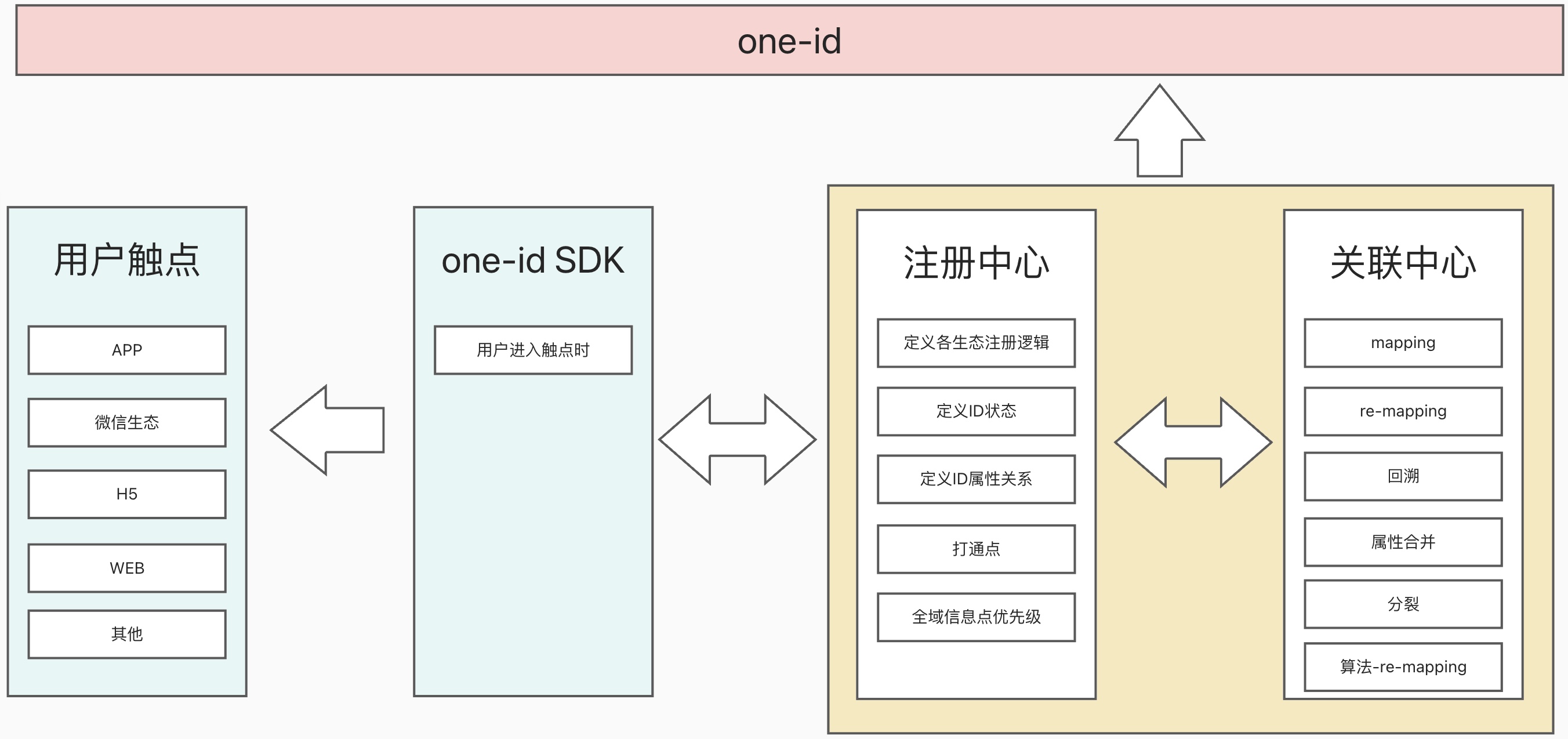
1.制定one-id SDK,各个生态的采集规则,以便之后有丰富的数据可以关联。
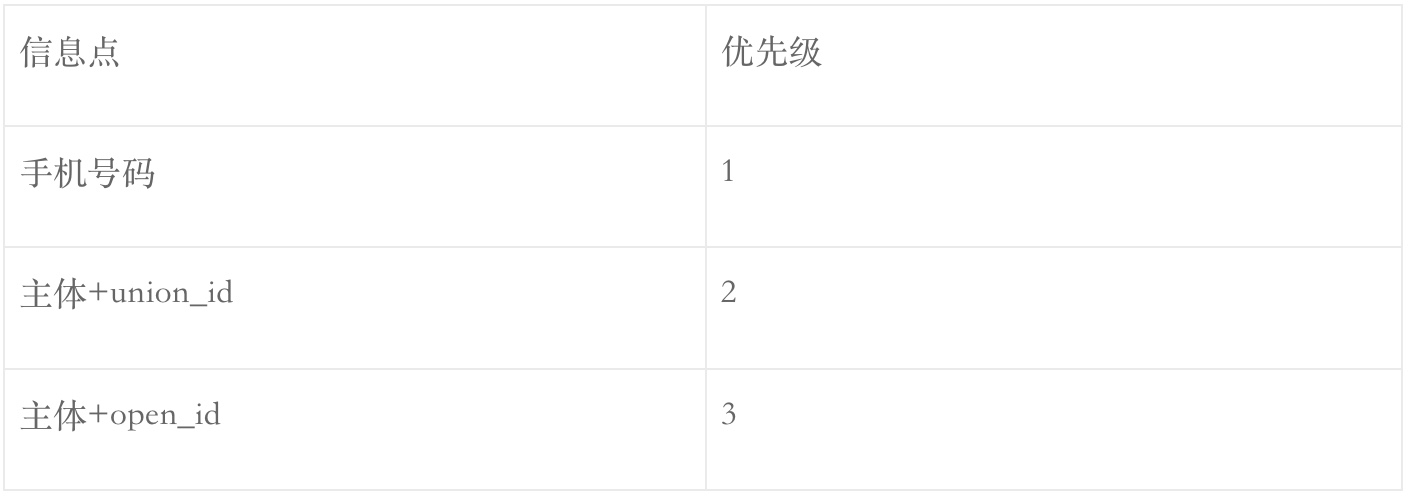
2.注册:通过one-id SDK集成到各个触点中,当用户进入触点时,触发SDK,SDK与注册中心(注册中心背后的核心引擎是关联中心)进行交互,产生2种one-id,一是游离态one-id,二是稳定态one-id。稳定态one-id将不再变化(其实还是会变的,不是实际意义上的绝对稳定,像身份证ID)。游离态是由于各种无法打通全域的id生成,而稳定态则是由手机号码生成。完成注册时,用户的所有id和属性将同步给大数据,大数据再后续的关联中心中会做进一步的处理。注意:对于游离态id需要记录其回溯时间,即生成该id的时间,以便之后在关联的过程中,若游离态的id变更了one-id,可以对应地去修改已存储的数据。
3.再关联:各个游离态one-id将进入关联中心试图与稳定态进行关联或者与其他的id进行关联。没有关联上的将继续保留原状,已关联上的将可能变更其one-id以及修改对应的数据的one-id,例如订单数据、日志数据等等。
4.若用户的信息变更可能触发id的信息分裂。
5.定期验证mapping的准确性。
五、细节步骤
1. 采集
关于各个生态SDK采集的数据:
将SDK集成到各个触点中,当用户进入触点时即触发用户信息的采集,采集之后将用于下一步的注册。
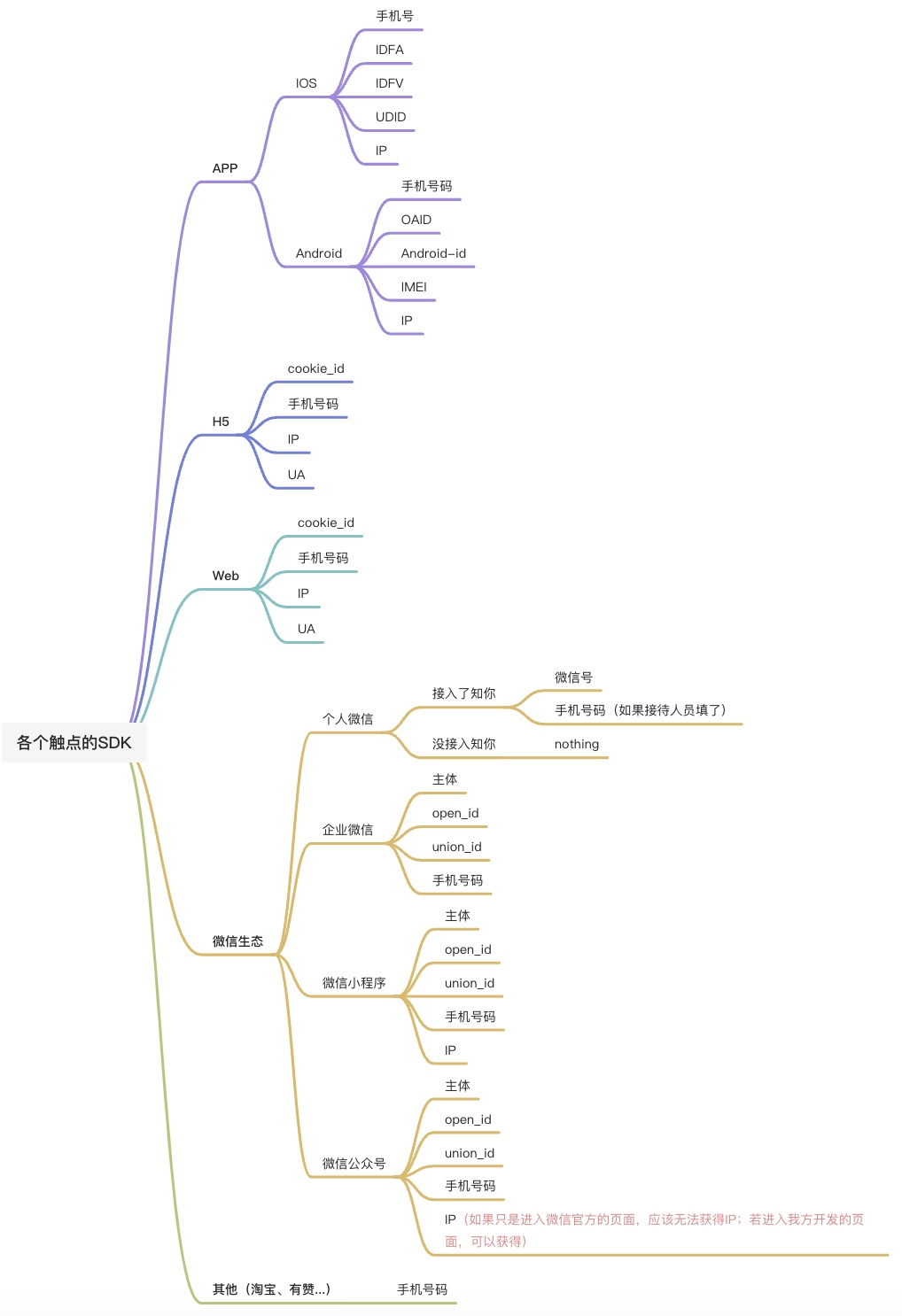
网上查找到的一些资料:
Android-App:
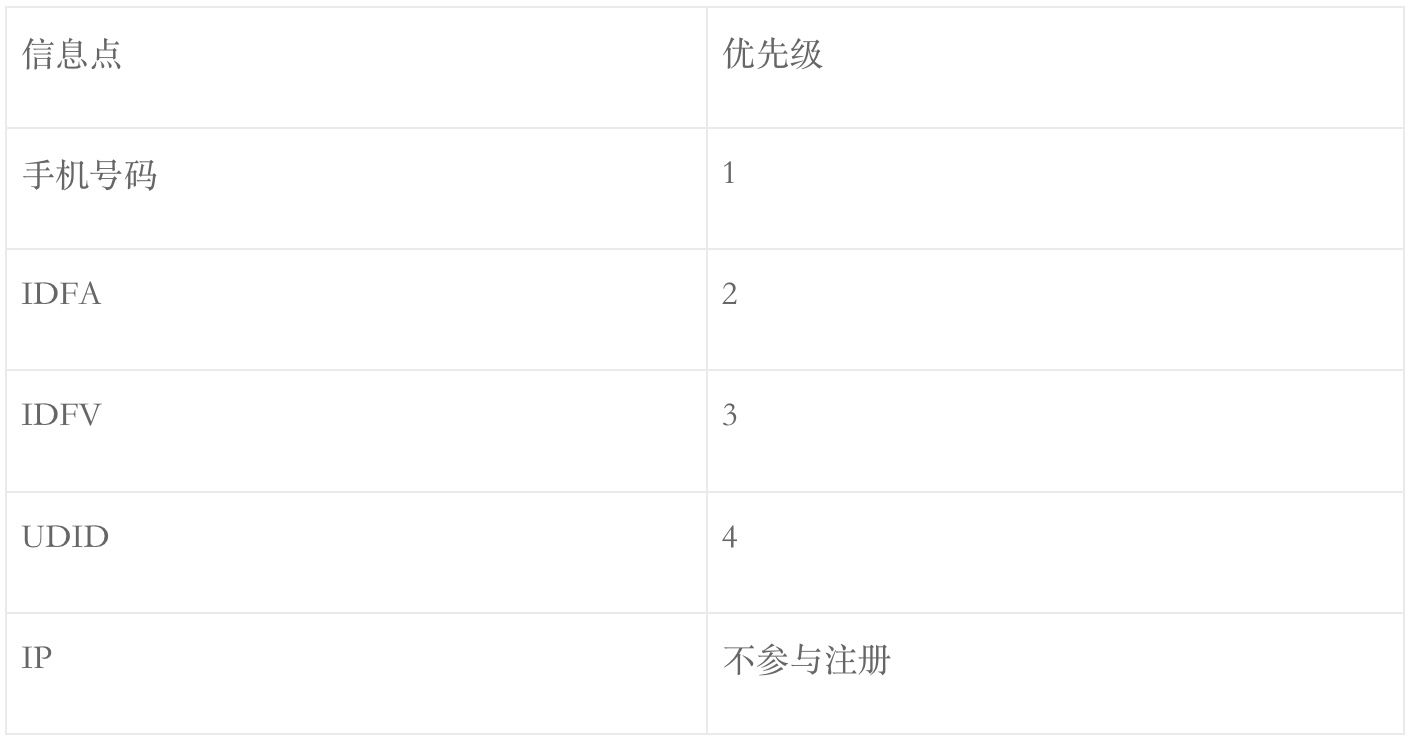
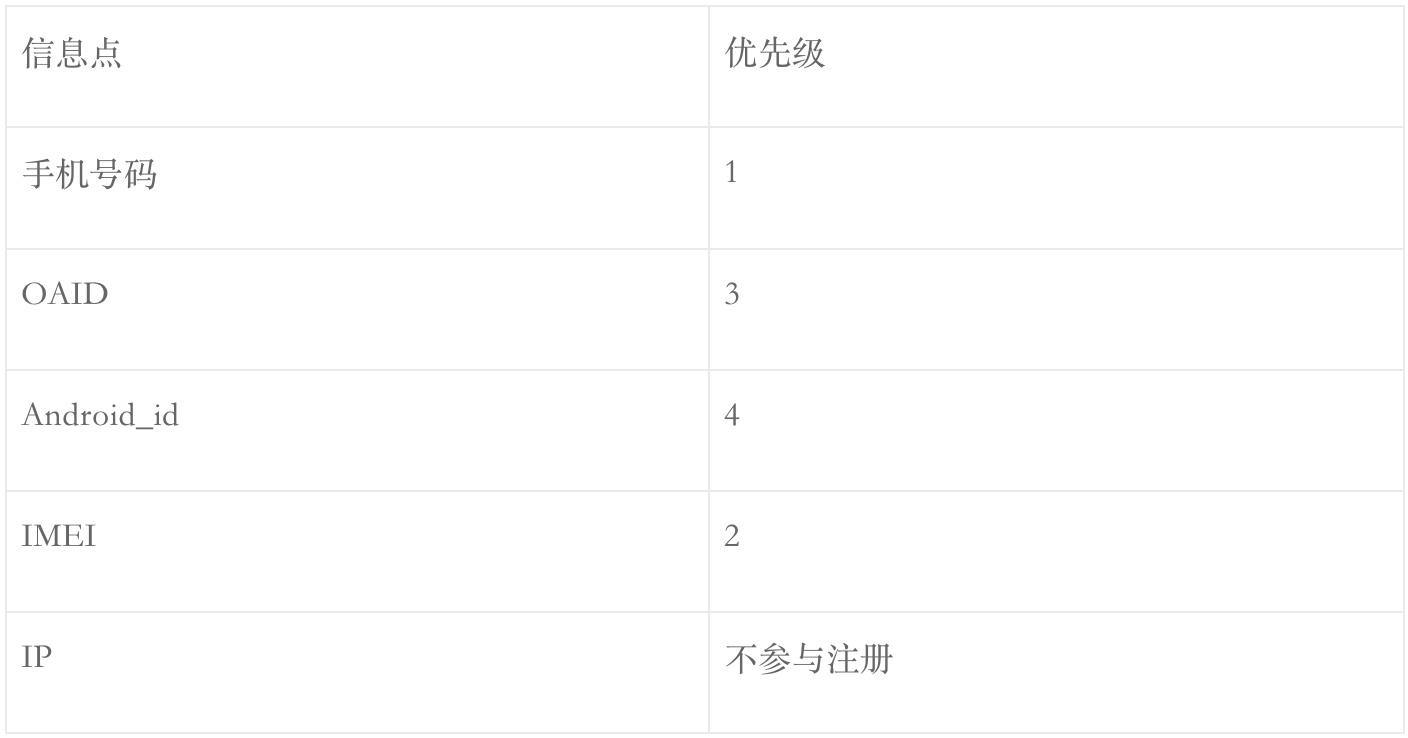
安卓系统历经多次升级,对权限控制越来越严格,唯一识别手机的方法也在发生变化。下面整理一下安卓系统适合做设备唯一标识符的几个标识符,以及其特性:

从表格中看出,IMEI是最适合做设备唯一标识的,奈何获取IMEI需要授予权限且Android 10以后不再开放IMEI的权限。综合起来,安卓系统中,应该按照IMEI ->OAID -> ANDROID_ID的顺序生成设备ID。即先获取IMEI号,获取不到IMEI时获取OAID,获取不到OAID时,再获取ANDROID_ID。
IOS-App:
苹果系统,可用于识别唯一设备的标识不多,如下图。综合起来,苹果系统生成设备ID的标识符顺序应该是IDFA -> IDFV ->UDID,即先获取IDFA,获取不到在获取IDFV,获取不到IDFV时,再获取UDID。

微信小程序获取用户IP:https://www.csdn.net/tags/MtjacgzsNjgwMzMtYmxvZwO0O0OO0O0O.html
微信公众号获取用户IP:暂时没有发现方法。
2. 注册
根据用户信息的优先级进行注册。
1)各个生态注册id优先级
① APP生态
IOS:
Android:
② H5生态/WEB生态
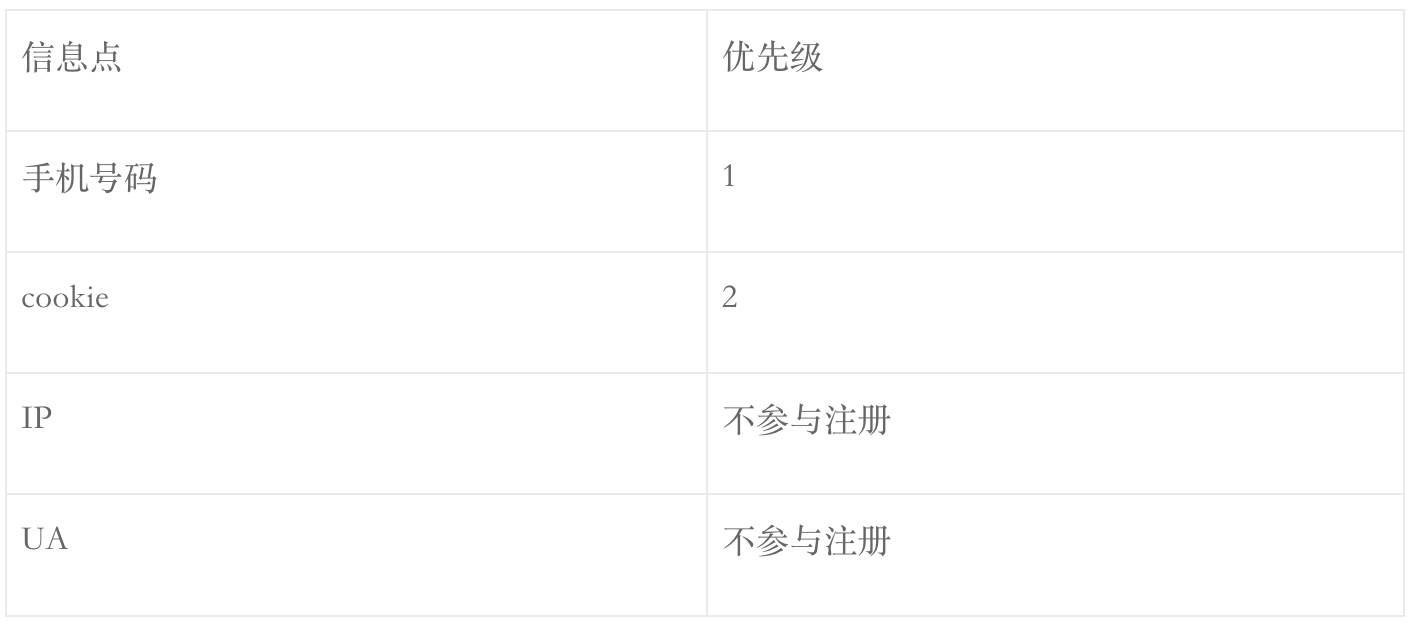
③ 微信生态
个人微信号:
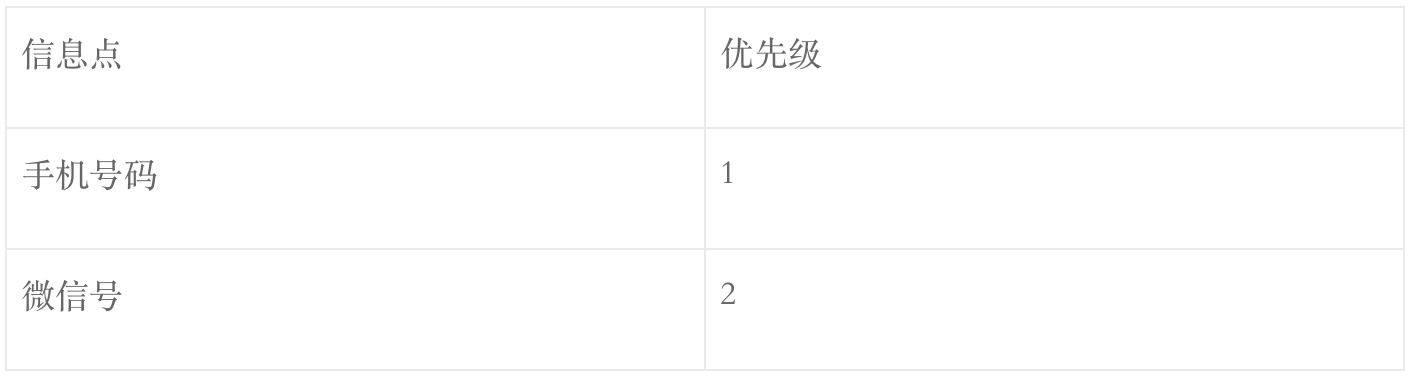
企业微信:
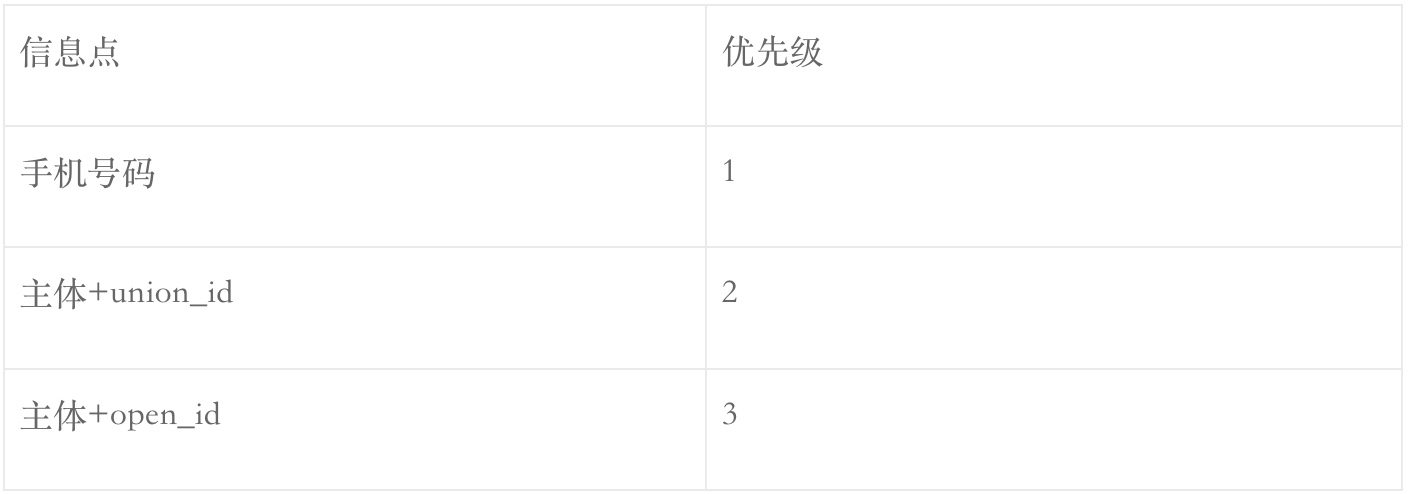
微信小程序:
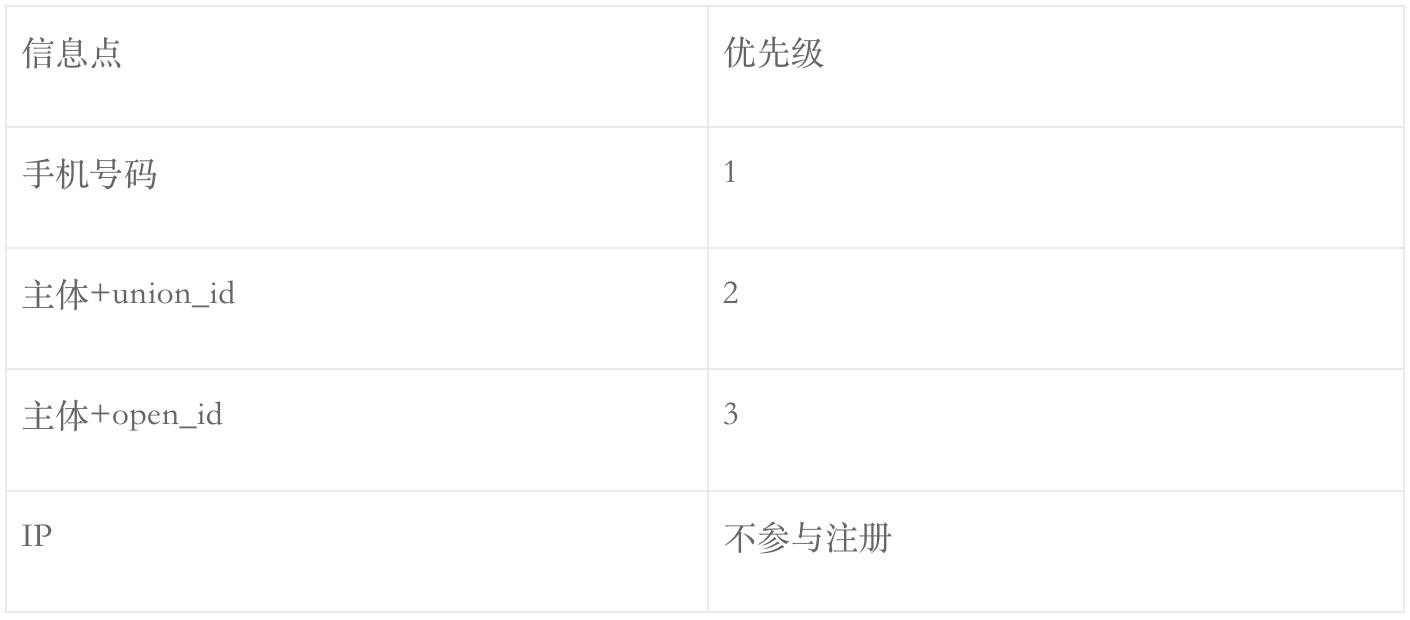
微信公众号:
④ 其他生态
通过订单中的手机号码进行注册。
2)注册逻辑
① 初步mapping
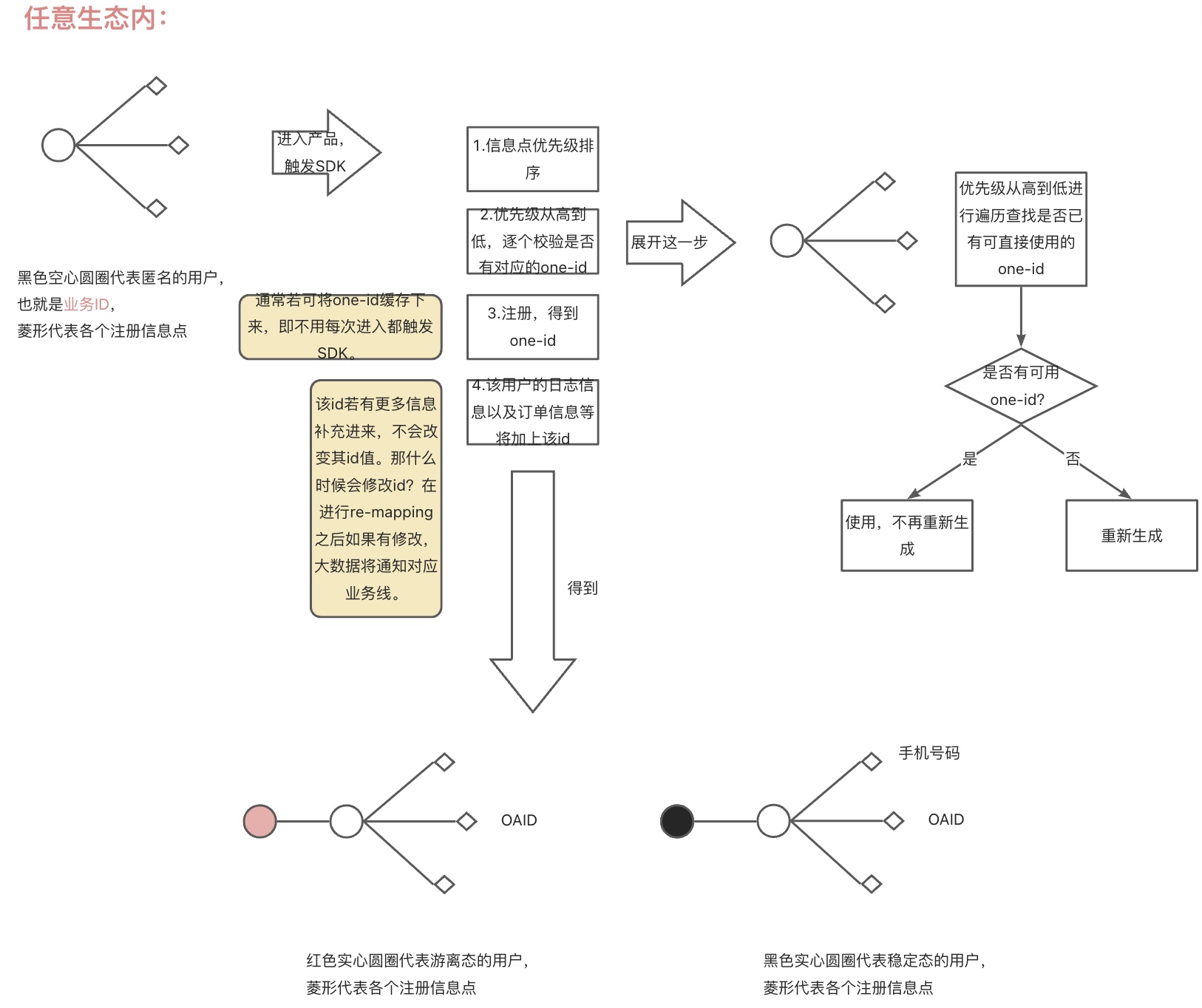
初步mapping在一定程度上进行了数据的打通,关键点在于在生成id时会去查询是否已有相关的信息点生成的id。但是它还没有解决全域打通的问题,例如一个用户使用苹果手机在APP1上通过IDFA生成了一个id1,后来又使用安卓手机在APP2上OAID生成一个id,后来2个账号都输入了手机号码,如果没有打通这一步的话,那么2部分信息依然是割裂的,因此需要再mapping。
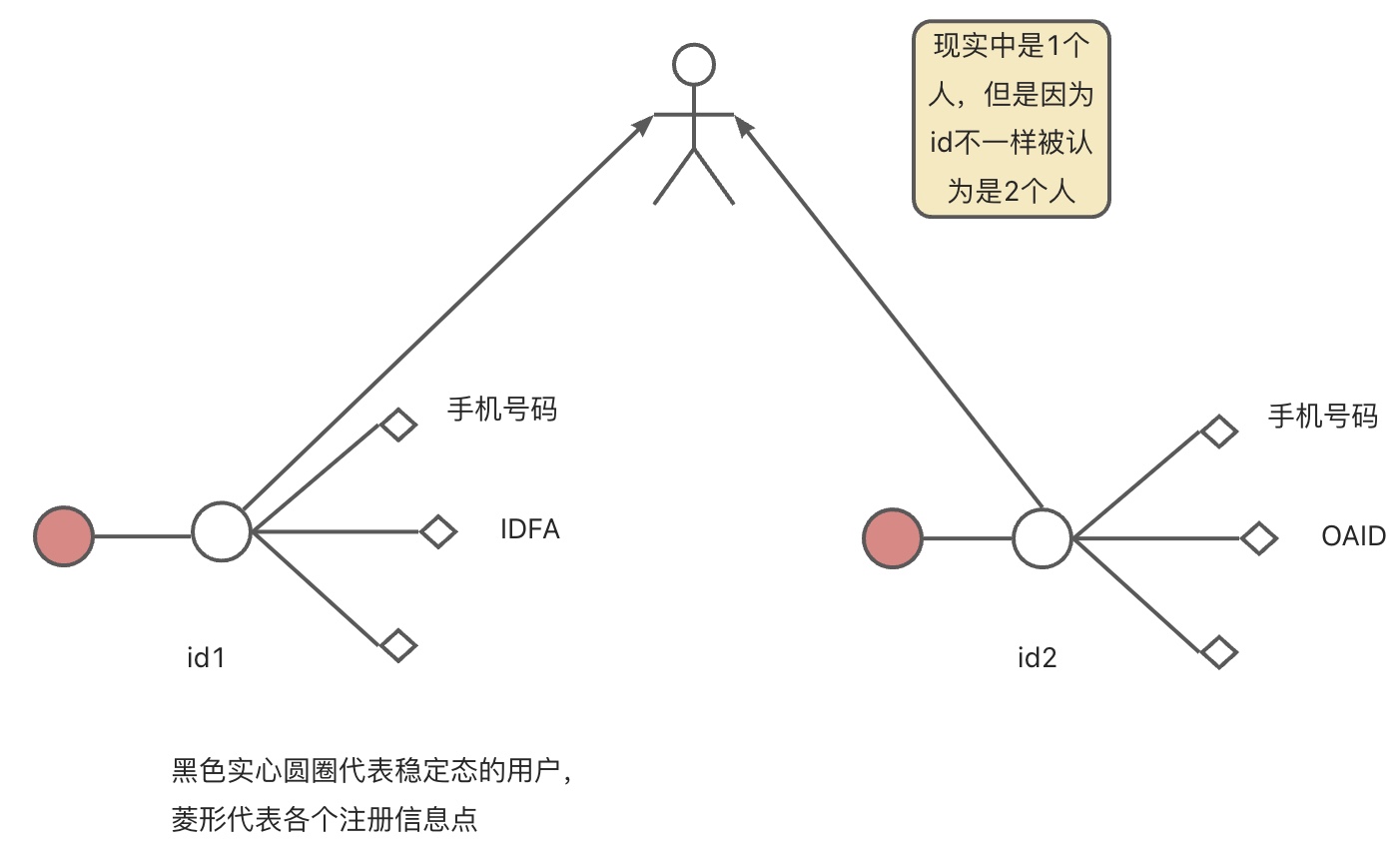
② re-mapping
案例:
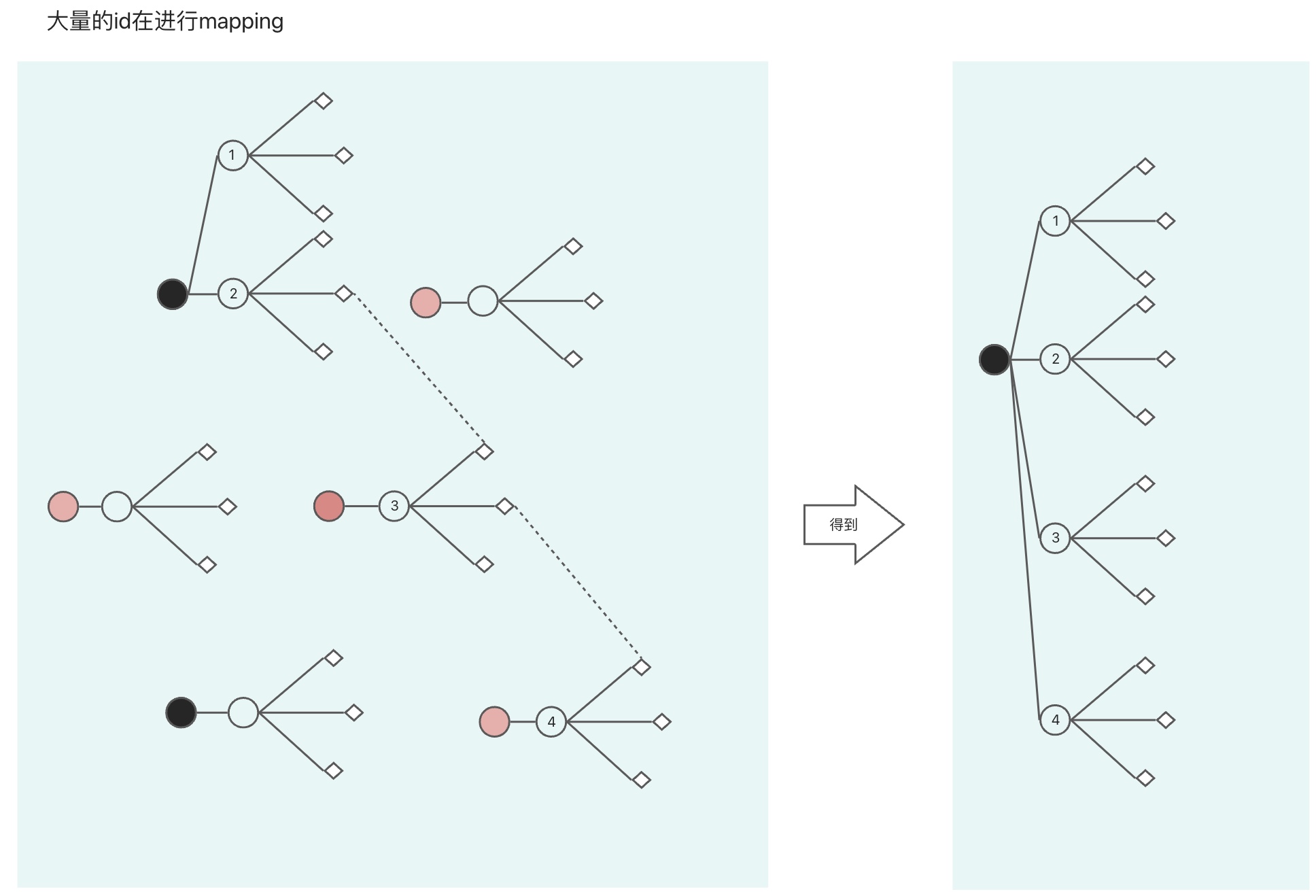
逻辑:
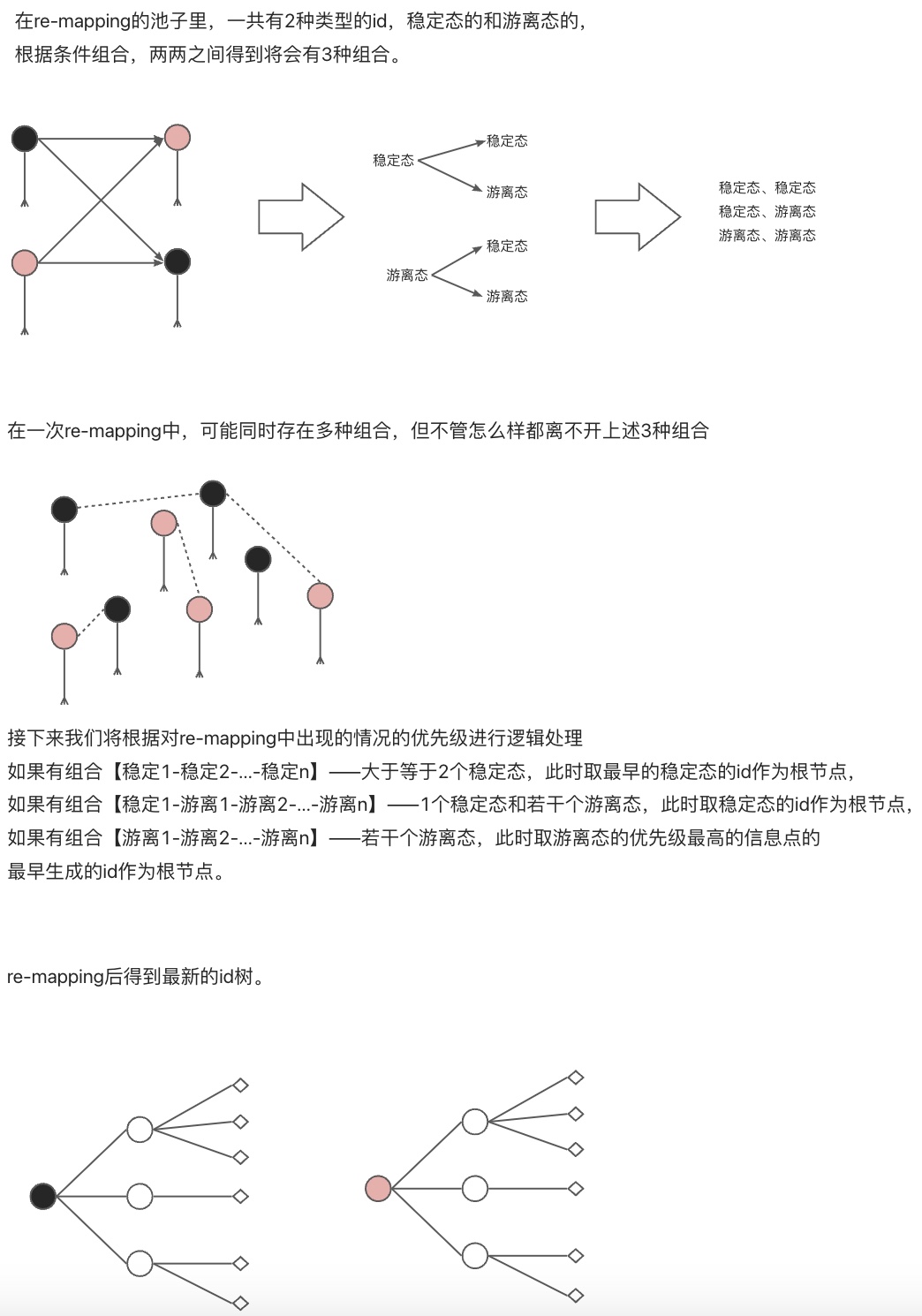
回溯历史数据:
进行再re-mapping时,会产生新的one-id取代旧的,此时将修改历史数据中的one-id。那么我们需要一个回溯的时间点,修改什么时间段内的数据,暂且称之为回溯时间点。这个时间点与我们初次生成one-id的时间点是一致的,因此可以根据这个时间点对数据进行修改。并且我们将新id告知各业务系统,各业务系统也做出对应的修改。
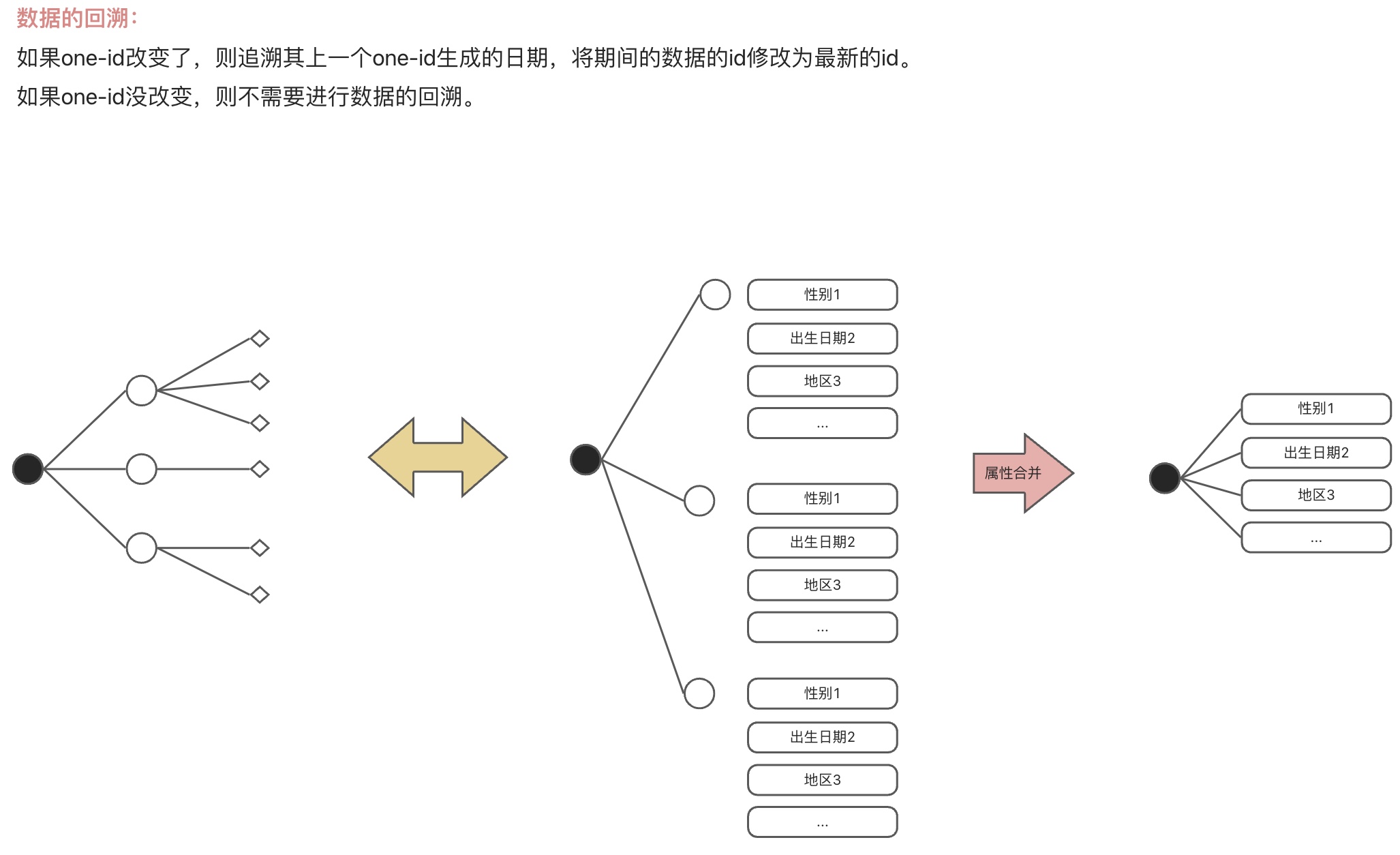
属性合并:
每个业务系统都需要在更新用户信息时将之上报。每个系统需要有一个id,每个数据上报上来都带有系统id,上报上来的数据将经过评审确定其准确性与优先级。上报上来后将根据优先级决定是否替换历史数据,若无历史数据则默认填充。最后达到的效果是每个属性字段都力求最真实,来源于最可靠的数据来源。
涉及到属性合并的有2个场景:初步mapping和再次mapping,原则都是根据数据来源的优先级决定是否替换历史数据。

用户信息的修改:
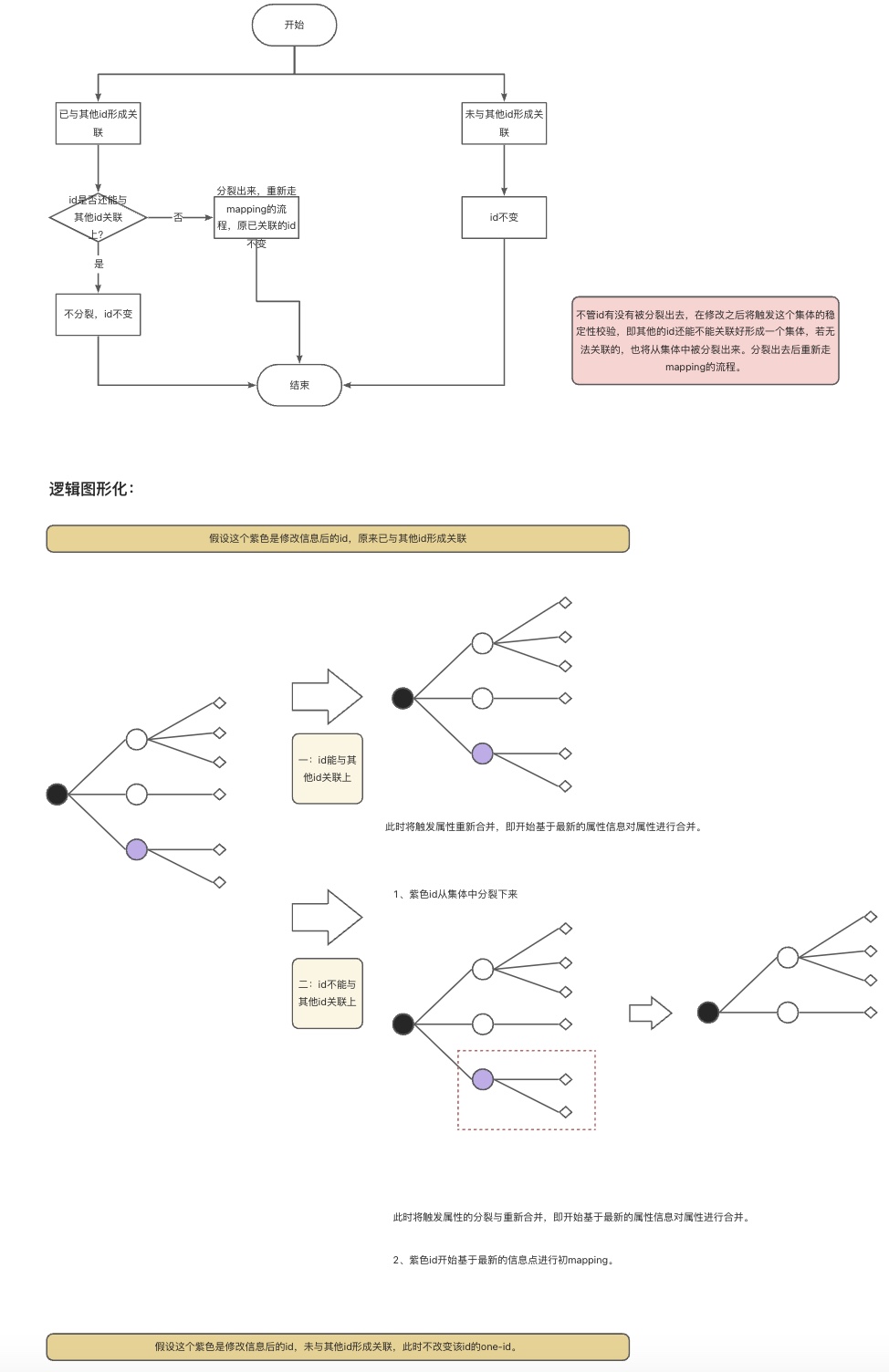
当用户的信息修改后,有两种大的情况。
1.id已经与其他id形成关联,在修改后将判断是否还能与其他id形成关联。
- 能形成关联:依然与其他的id,one-id不变,将触发属性的重新合并过程——基于最新的属性情况。
- 不能形成关联:与其他的id脱离,从集体中分裂出来,将重新走初步mapping流程得到one-id。将触将发属性的重新合并过程——基于最新的属性情况。
2.id与其未他id形成关联,其one-id不会改变。
在整个mapping中有一个原则就是尽量少地使用现在已有的one-id,以及尽量减少one-id的更改。
无法获取手机号码和设备号等明确信息的用户的关联算法预测:
关联的核心是时空条件序列(也就是多个时空信息)的重合度计算,也就是时间和位置的重合度。为了增强辨识的准确性,增加了重合度计算因子:手机品牌和型号。最终重合度计算因子是时间、位置、手机品牌-型号、产品属性、网络,将采用Jaccard Coefficient算法。
概述方法:使用H5中的IP+UA解析出位置和手机品牌-型号,与app生态、微信生态进行比较。在与app生态进行比较时,使用位置、手机品牌-型号(位置由IP解析出,手机品牌和型号app中可获得);与微信生态进行比较时,使用位置(位置由IP解析出)。
在用户经过初步mapping流程之后得到one-id,之后我们将进行算法re-mapping流程,这个流程是要是经过算法去预测用户与游离态/稳定态ID的关联度,通过关联度与游离态/稳定态ID关联起来,最后达到辨识匿名客户的目的。
在进行算法re-mapping流程之前或者之后,用户可能更改了自己的信息或者我们通过某些手段能够获得用户的更多信息等等,总而言之就是客户的信息改变了,此时我们要尝试去re-mapping,看看最新的信息点能不能与与游离态/稳定态ID直接关联,而不是通过算法猜测。
那么关键的步骤是:
- 根据匿名的信息先经过初步mapping给一个one-id。
- 定期进行算法re-mapping,但是在此之前先进行一步re-mapping。注意:re-mapping是上文中提到的,而算法re-mapping在这里刚提出的,用于猜测用户与其他ID的关联度,如果关联度合适,将需关联的ID进行关联。re-mapping流程是我们之前已经讲了很多的,这里我重点讲讲算法re-mapping。
③ 算法re-mapping
流程概述:
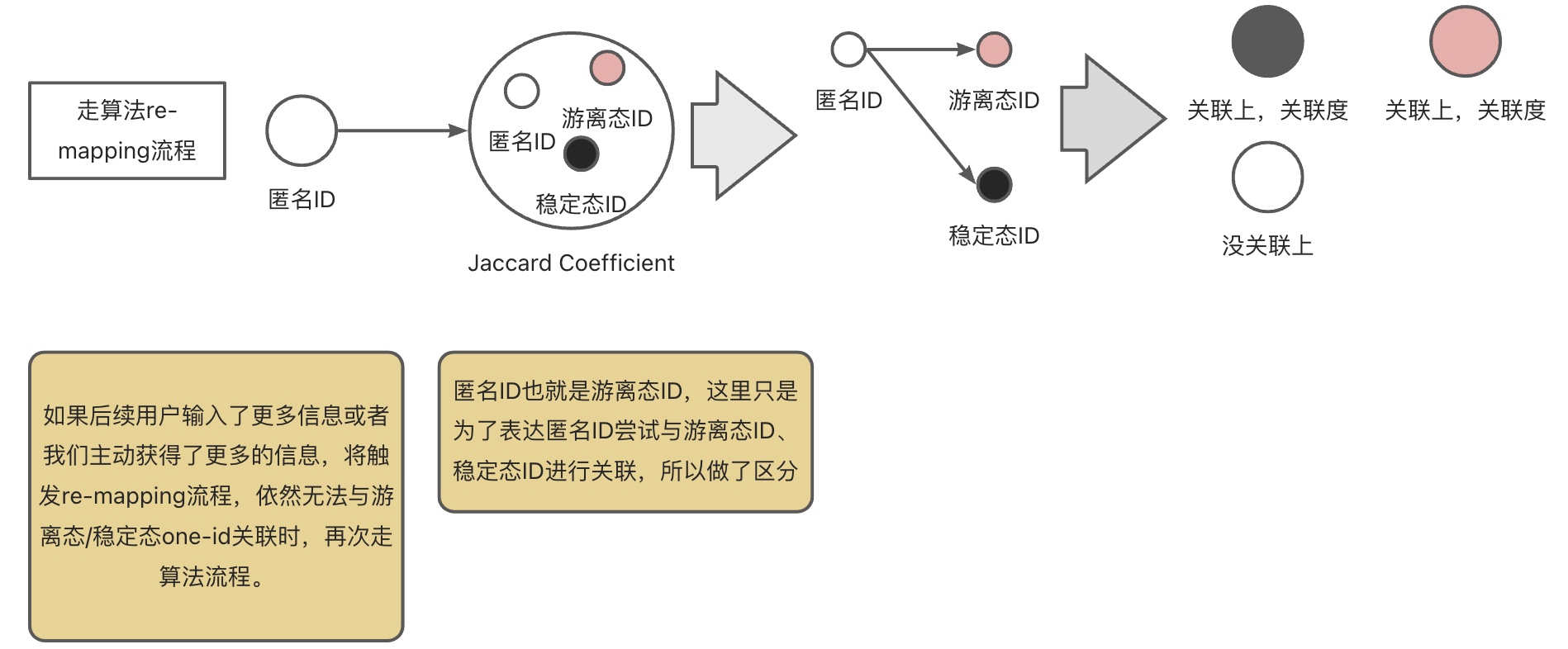
详细方案:
数据来源是解析用户进入网站时的日志以及相关属性。需要增量记录用户的所有的位置(时间)、网络、手机品牌、型号、相关属性。
重合度计算因子是位置、网络、手机品牌-型号、相关属性。
算法:Jaccard Coefficient算法。
具体的计算方法:将因子去重后得到分母,而分子部分由2个ID的因子的交集获得,得到重合度。
例如:用户A是匿名用户,因子去重后得到:【位置:广东省广州,网络:移动,手机品牌-型号:苹果-12,相关属性:摄影、二次元、漫展】,
而某个游离态one-idB的因子去重后得到:【位置:广东省广州、云南省昆明,网络:移动,手机品牌-型号:苹果-12,相关属性:摄影、二次元、漫展、古风、日系】,
而某个稳定态one-idC的因子去重后得到:【位置:广东省广州、云南省昆明、陕西省西安,网络:移动,手机品牌-型号:苹果-11,相关属性:摄影、二次元、漫展、古风、日系】,
那么计算得到A与B的重合度是6/15,约为40.00%概率是同一个人,而A与C的重合度是5/11,约为45.45%概率是同一个人。
至少概率要达到50%及以上才将之关联。另外,针对手机品牌-型号可增加权重,若该点没有重合的,可直接不关联。
六、方案的可拓展性
面对外界的改变,主要是能够获取的用户的信息点的改变,我们主要去调整注册中心的各个生态注册id,包括:新增注册信息点、减少注册信息点、调整注册信息点的优先级。那么后面的流程将按照最新的注册中心的信息点设置跑。同时,我们还有一个是全域的注册信息点优先级表,这个也是需要维护的,包括:新增注册信息点、减少注册信息点、调整注册信息点的优先级。另外,还需要维护:可用于打通的信息点。
例如:Android的OAID已经完全无法获得,那么我们将减少这个注册信息点。
Android(删除之前):
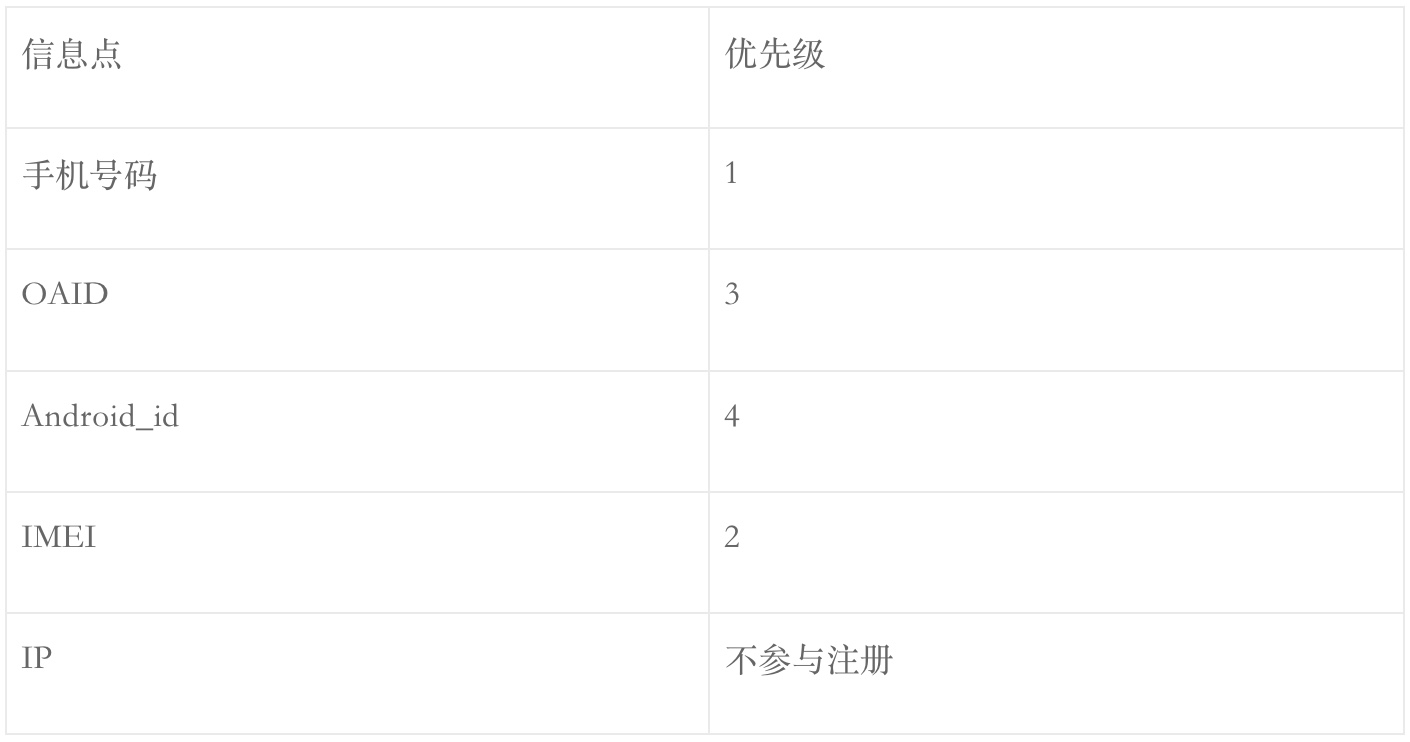
Android(删除之后):
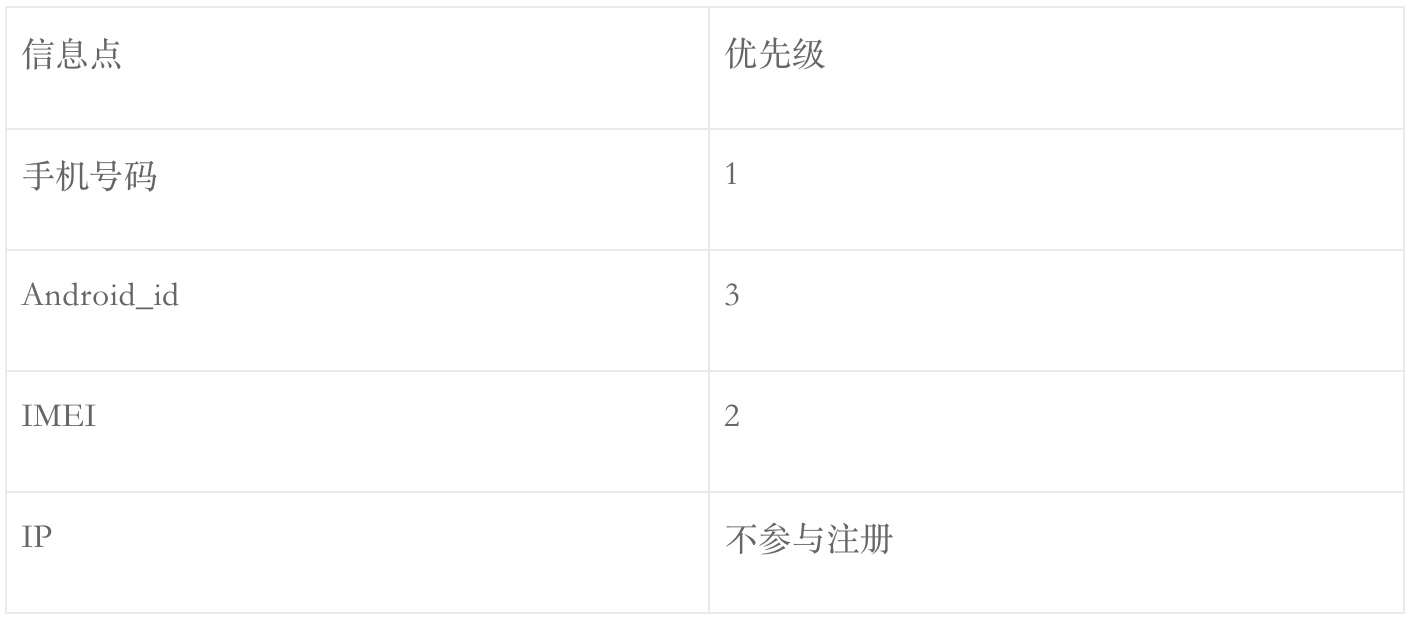
之后,SDK不再采集这个信息点,在初步mapping时都不会再使用这个信息点,但是注意之前已有这个信息点的不会删除,re-mapping时会使用这个信息点,因为之前数据是有这个信息点的,有可能正是使用这个信息与其他one-id进行关联。
如果是新增了信息点,那么这个信息点将可能参与初步mapping、re-mapping。
如果是调整了信息点的优先级,那么不影响这个信息点参与初步mapping、re-mapping,只是改变了这个信息点在参与时的优先级。
在修改了信息点后,还需要修改全域的信息点优先级,以及维护可打通的信息点。
七、方案优劣势
1. 优势
- 从数据的角度,打通数据的点变多了,能被打通的数据变多了,这将有助于全面描述一个用户,形成比较稳固的严谨的数据根基,以支撑上层对于数据的使用。
- 从业务的角度,用户因为打通之后会更加的归拢,这将缓解没有打通而统计出来的庞大的虚假的用户数,给业务以更真实的数据。另外,因为打通我们能够知道用户在整个公司产品领域内的先后触点情况,即在整个用户生命周期内是如何经过一个个的公司产品触点。
- 从使用的角度,数据进一步打通之后,数据根基更稳固了,在使用的时候我们可以更加信赖底层的数据。对于单个用户,因为数据更加地归拢,在统计与打标签等工作上,将更准确,特别是对于全域产品范围的统计。
2. 劣势
逻辑比较复杂,计算量比较大,特别是算法re-mapping的计算量。
参考资料
- 神策的id-mapping方案,视频:https://school.sensorsdata.cn/liveVideo?liveId=3841
- 数澜科技算法专家在B站关于id-mapping的视频,全系列有4个视频:https://www.bilibili.com/video/BV1Ei4y177cX?spm_id_from=333.999.0.0
- 《阿里巴巴云上数据中台之道》中的id-mapping部分(one-id)
- 《华为数据之道》中的id-mapping部分
- 《标签类目体系 面向业务的数据资产设计方法论》中的id-mapping部分
- https://jishuin.proginn.com/p/763bfbd75525

本文由@Bruce 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









mapping 和remapping算法有更详细资料不
木有了喔,你找到的话也可以分享一下
👍
多交流才有进步!