
 起点课堂会员权益
起点课堂会员权益浅析过考模型实现思路
在线下教学中,分析学员能力往往需要依赖教师的主观判断,而在线教育可以通过过考模型来进行数据分析,分析学员当前的情况。本文浅析过考模型实现思路,希望对你有所启发。

考试类学科的目标是让学员通过考试,教培机构主要通过教、学、练、测四个环节来提高学员的能力。教育发展的最终阶段往往是个性化教学,而想要向个性化教学发展,最重要的是分析学员的能力,这样才能让学员查漏补缺,针对性提高能力。
传统的线下教育中,分析学员的能力依赖于教师的主观判断。在线教育中更希望通过学员的学习行为和学习数据来分析学员当前的能力情况,并给出针对性的建议。
也因此,产生了过考模型。
一、什么是过考模型
过考模型是基于大数据分析的学习规划工具,旨在通过精确的数据分析,制定个性化的学习计划,帮助学员通过考试。这里面包含三部分内容:量化学员能力、给出学习建议、提升学习效率。
量化学员能力是根据考生的在线行为数据(如听课时间、做题数量、正确率等)来评估学员对知识点的掌握程度,通过学员的考试预估分来外化呈现,因为学员最容易感知的地方就是自己在考试中可以考多少分。
分析出学员当前的能力水平之后,就可以针对学员薄弱的知识点给出学习建议,比如给学员推荐重点要听的课程和智能组卷刷题,让学员可以针对性学习。
提高学习效率主要体现在教师专家制定的高效学习路线。可以根据不同学习阶段的需求来制定学习路线,比如在备考初期可能更注重理解知识点,在复习阶段更注重刷题和记忆。
因为成人教育中的考生好多是在职考生,只能在工作之外的时间学习,自身基础差、时间紧,建立过考模型可以让考生更有效地利用他们的时间,取得更好的成绩。
二、过考模型实现思路
在线教育的过考模型中,主要难点在于分析学员能力和建立高效学习路线。前者主要靠产品经理来实现,后者则更依赖于教研对教学的思考,因此本部分只介绍前者。
要想分析学员能力,需要建立统一的知识结构,然后拆细教学内容(包括题、课程、学习资料等)的粒度,并在最细的粒度上关联知识点,形成统一的体系。
基础工作完成之后,就可以搜集学员的学习数据,并进行分析,主要有两个实现思路,一个正向思路,一个反向思路。
2.1 正向思路

正向思路是根据每个用户自身的学习数据来分析其对每个知识点的掌握程度,建立学员的能力模型。然后根据考纲和历年出题情况,分析每个知识点对应题目的考试概率和分数。二者相乘后的加和即为考试的预估分。
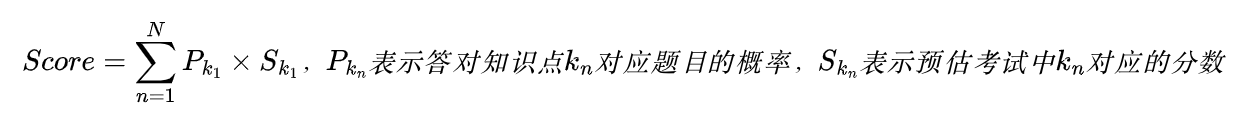
这种分析思路就是认知诊断,通过学生的学习记录来对学生的状态进行分析。之前写过一篇文章(从推荐算法出发,浅谈题库个性化推题思路),其中能力模型部分就介绍了通过项目反应理论IRT模型来分析用户对某个知识点的掌握情况的方法。
在认知诊断/知识追踪领域常用的模型还有DINA模型、NIDA模型、贝叶斯知识追踪(BKT)模型、学习因子分析(LFA)模型等等,感兴趣的读者可以找一下相关资料。
这个思路需要准确评估学员对知识点的掌握水平,涉及到很多机器学习算法,从0开始搭建的投入成本很高。在实际中更可行的可能是下面这种思路。
2.2 反向思路
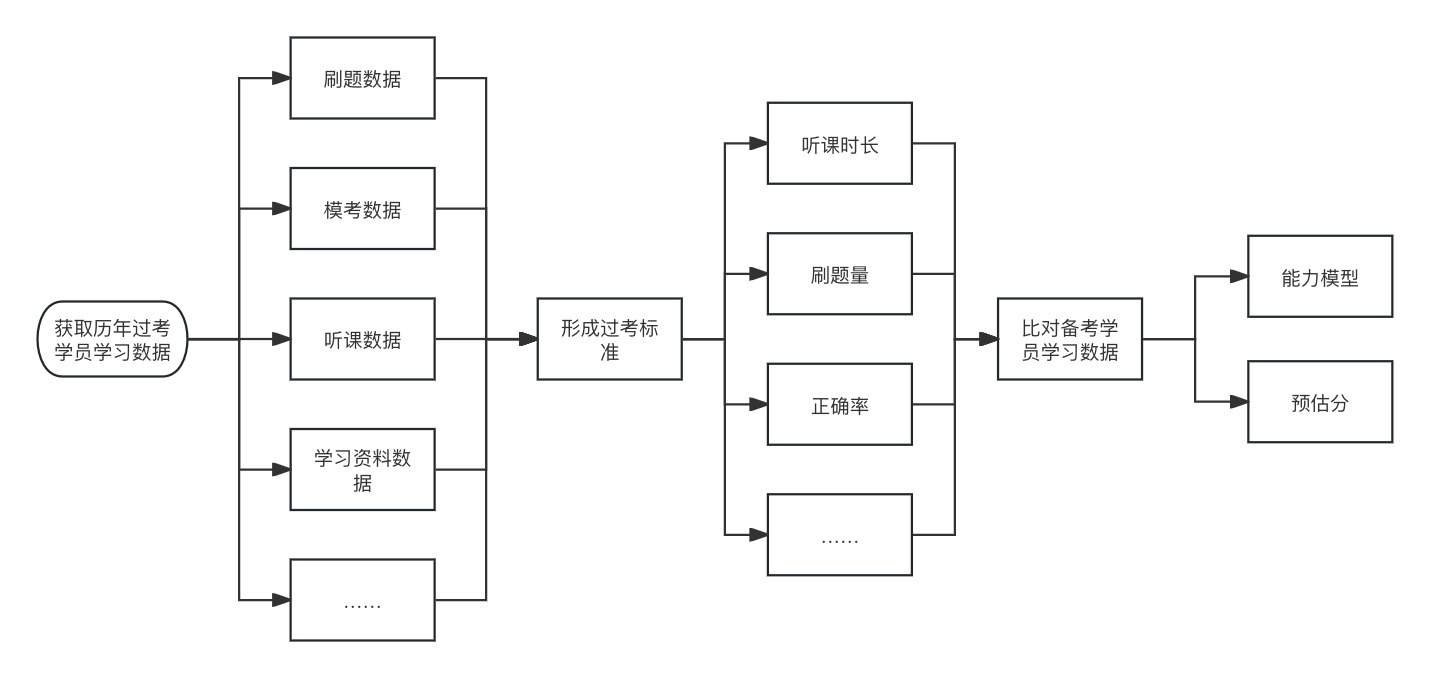
反向思路落到考过学生的学习数据上,通过备考学员数据与之前过考学员数据比对来反推备考学员欠缺的能力。主要方法是从历年通过考试的用户的学习数据中找到规律,以此作为对新的备考学员的要求标准,达到标准后通过考试的概率会很高。
采用这种思路需要数据足够细化,不然仅从大面上比对听课时长、刷题量准确定不高。以觉晓法考为例,他们按照考频和难度将知识点分为五类,将数据细化到了每个科目(法考分为18个科目)每个学习阶段需要听多长时间的课、刷多少题,每类知识点对应的题目需要达到多少刷题量和正确率,以及每周甚至每天需要完成的任务量,全部达标之后通过考试的概率可以达到90%以上。
但是这个思路需要长期的过考数据积累,才能建立过考模型的标准。而且建立的标准跟机构内的课程设置、题目数量、难度分布等高度相关,即使公开思路和标准数据后,其他机构也很难抄走,这也是一种壁垒。
总之,两种思路虽然方法不同,但殊途同归,都有实现的可能性,可以根据当前的情况选择合适的成本更低的思路去实现。
以上就是关于过考模型的介绍,希望可以给大家带来一些思考和启发。
本文由 @YTY 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。





- 目前还没评论,等你发挥!


