
 起点课堂会员权益
起点课堂会员权益大数据取数工具演进之路
在降本增效的大环境下,人力资源和服务器资源都愈发的紧张,但人们对于数据获取的需求却在不断的提高。大家期望可以查询的速度更快,查询的数据量更大,查询的交互更友好,查询工具的使用门槛更低......本文从大数据的起源讲起,逐步讲解到现在的大数据取数产品。

一、大数据起源
1.1、google论文发布
如果问存储数据量最大的互联网公司是哪家?那做搜索的Google应该是一个有力的竞争者。
作为一家搜索引擎公司,Google需要保存大量网页数据,还要对海量的数据进行快速的搜索、计算、排名等处理。而在这个过程中,有大量的数据需要存储和计算,所以Google内部研发出了对应的解决方案,并在2003年开始相继公布了对应的技术解决方案,也就是开启大数据工业时代的三驾马车。
其中两篇论文是:
- 于2003年发布《The Google File System》,用于处理海量网页的存储
- 于2004年 发布《MapReduce: Simplified Data Processing on Large Clusters》,可用于处理海量网页的索引计算问题
这两篇论文让业界为之一振,这时突然大家恍然大悟,原来还可以这么玩。Google的思路是部署一个大规模的服务器集群,通过分布式的方式将海量数据分散的存储在这个集群的不同节点上,然后再利用集群上的所有机器进行数据计算。 通过这种方式,Google其实不需要买很多很贵的服务器,而是把很多普通的服务器组织到一起,实现了更加强大的功能。
1.2、Hadoop诞生
Lucene(ES)创始人Doug Cutting阅读了Google的论文后,他非常兴奋,紧接着就根据论文原理初步实现了类似GFS和MapReduce的功能。这也就是后来的Hadoop,主要包括Hadoop分布式文件系统HDFS(Hadoop Distributed File System)和大数据计算引擎MapReduce。
1.2.1、HDFS
HDFS是一种分布式文件系统,用于存储和管理大规模数据集的分布式存储解决方案,通过目录树来定位文件。
HDFS的思想:
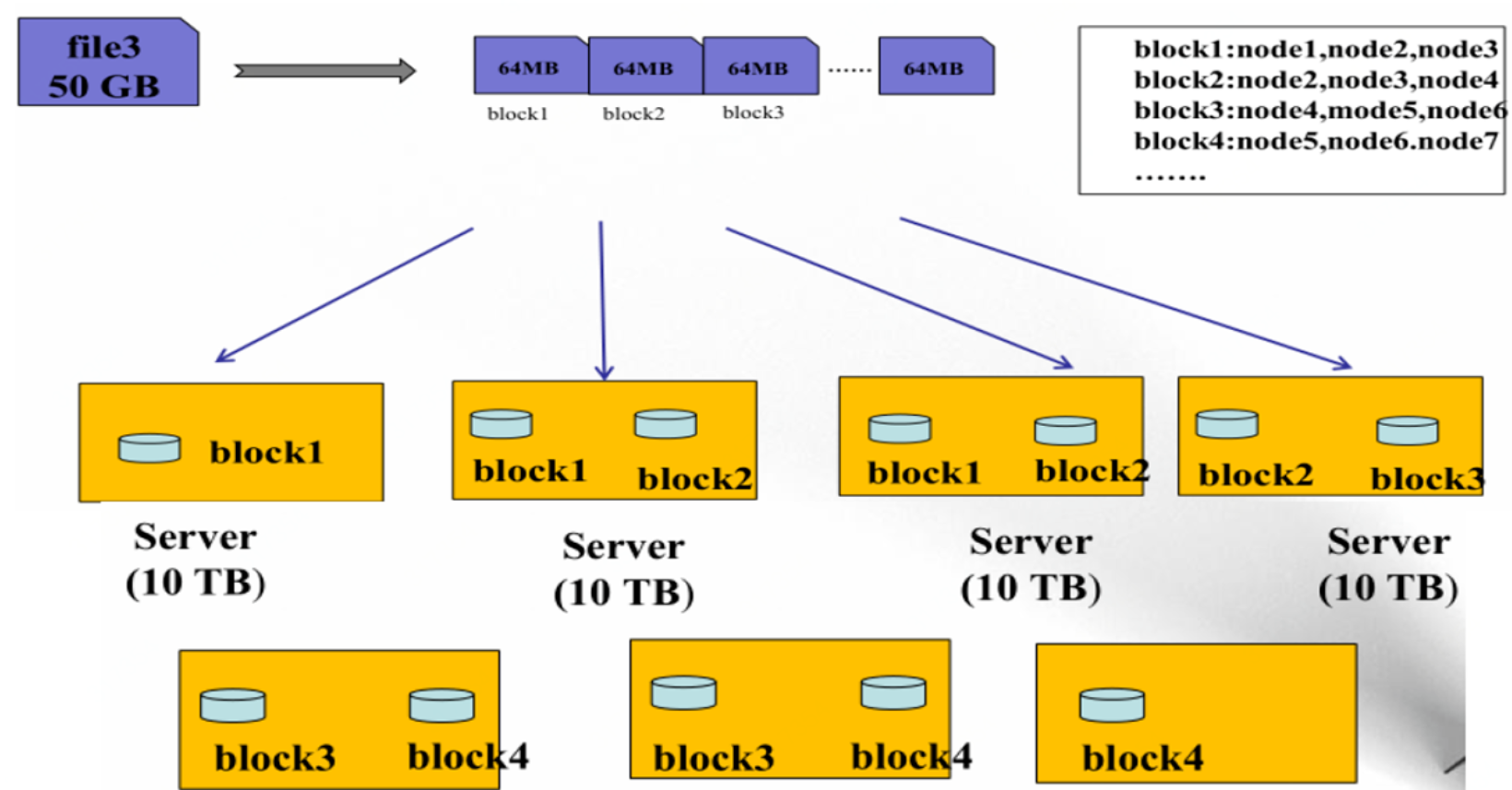
1、文件数据以数据块的方式进行切分,数据块可以存储在集群任意服务器上,所以HDFS存储的文件可以非常大。
2、DataNode存储的数据块会进行复制,使每个数据块在集群里有多个备份,保证了数据的可靠性。
HDFS的目录:
你看到的是一个文件系统而不是很多文件系统。比如你说我要获取/hdfs/tmp/file1的数据,你引用的是一个文件路径,但是实际的数据存放在很多不同的机器上。
1.2.2、MapReduce
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce的思想:
这个模型既简单又强大,简单是因为它只包含Map和Reduce两个过程,强大之处又在于它可以实现大数据领域几乎所有的计算需求。我们用大数据里面的HolleWorld,也就是wordcount为例说明
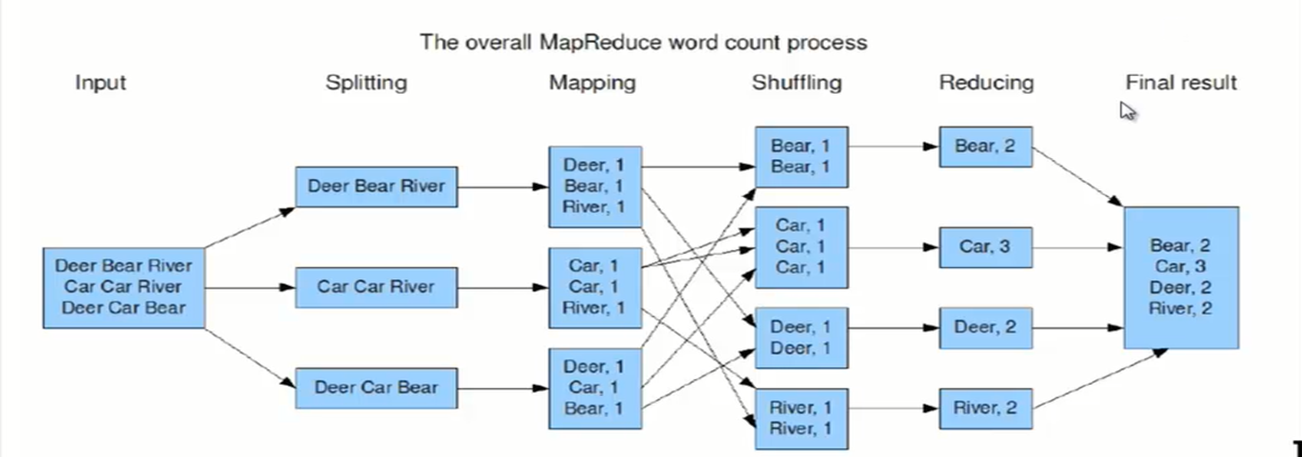
代码实现:
Map

Redece

1.3、一点思考
现在大家听到分布式、大数据之类的词,肯定一点儿也不陌生。
但如果我们回到03、04年,那时鹅厂刚才在香港上市,Facebook和支付宝都是刚刚创立,整个互联网还处于懵懂时代。
大多数公司对数据处理的关注点其实还是聚焦在单机上,在思考如何提升单机的性能,寻找更贵更好的服务器,大家觉得一切都是那么顺理成章。
如果回到那个时候,我们能不能跳出思维限制,给出其它方向的解决方案。
二、Hive
2.1、Hive的出现
MapReduce降低了大数据编程的难度,很多工程师都可以通过MapReduce开发大数据程序来进行数据获取。
但是对于其他有大数据分析需求的人,比如数据分析师,他们对SQL更加熟悉,但是去编写MapReduce程序还是有一定的学习成本。而且如果每次统计和分析都开发相应的MapReduce程序,人力成本也比较高。那么有没有办法进行优化,让SQL直接运行在大数据平台上呢?

这样的产品一出现,瞬间把大数据取数的门槛大幅度降低,研发的效率提高的同时,用户范围也进一步扩大。
更进一步的,把这些SQL沉淀成模板后,一些愿意动手的业务人员也可以初步进行大数据分析。
2.2、一点思考
思路打开之后,各种类似的SQL引擎产品被设计了出来,例如执行在HBase上的SQL引擎。
有时两个已经存在的东西做结合可以产生非常好的效果,例如人脸识别、掌纹和支付结合,功能机上叠加拍照,大模型和各种数据产品的结合等等。
三、指标库表取数
虽然Hive降低了大数据分析的难度,让更多的人可以参与的大数据的使用上,但很多业务人员有没有数据相关基础。那能不能有一种不需要有代码基础,明白业务逻辑就能使用的数据工具。这类分析工具很多公司都会做,大家的思路也基本类似。
3.1、交互逻辑
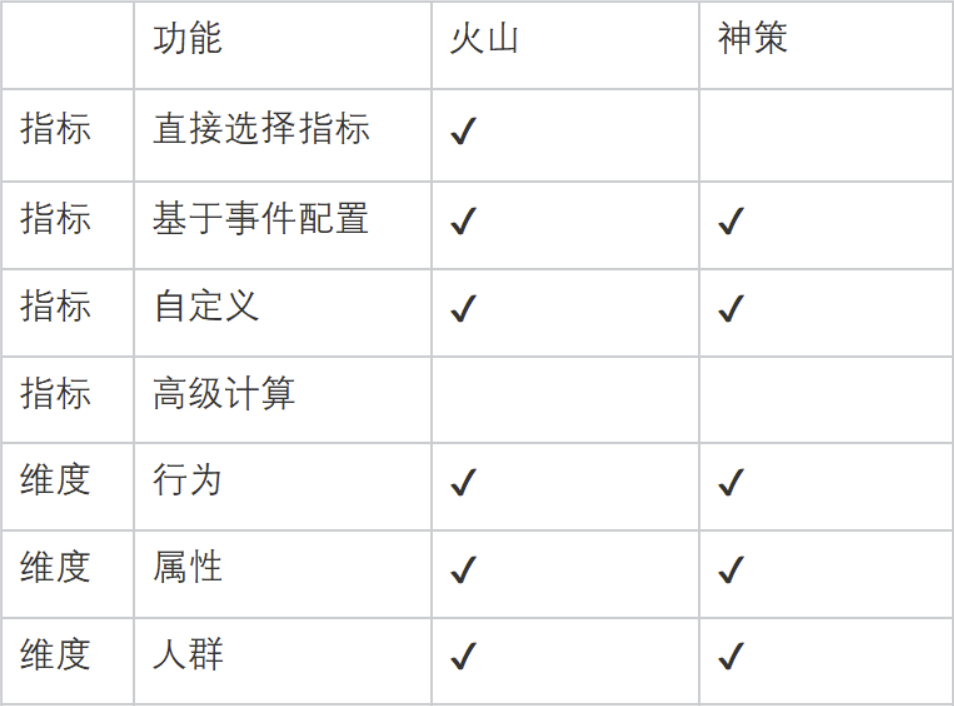
主要的产品交互模式就是基于拖拽或筛选的方式,对需要的指标和维度进行选择后进行分析。本质其实就是引导用户写一条SQL,而用户并不需要关注SQL的语法,进一步降低用户使用的门槛。
火山:
指标支持自己配置和直接选择已有指标,维度支持功能比较丰富
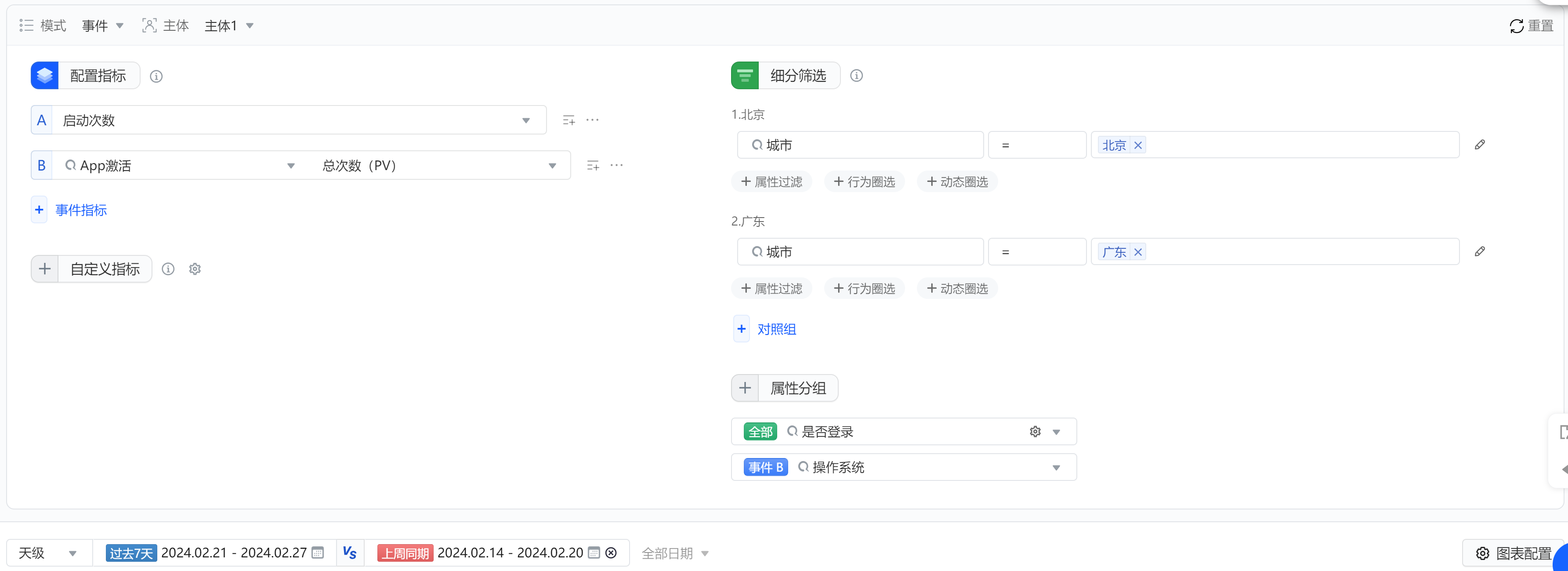
神策:
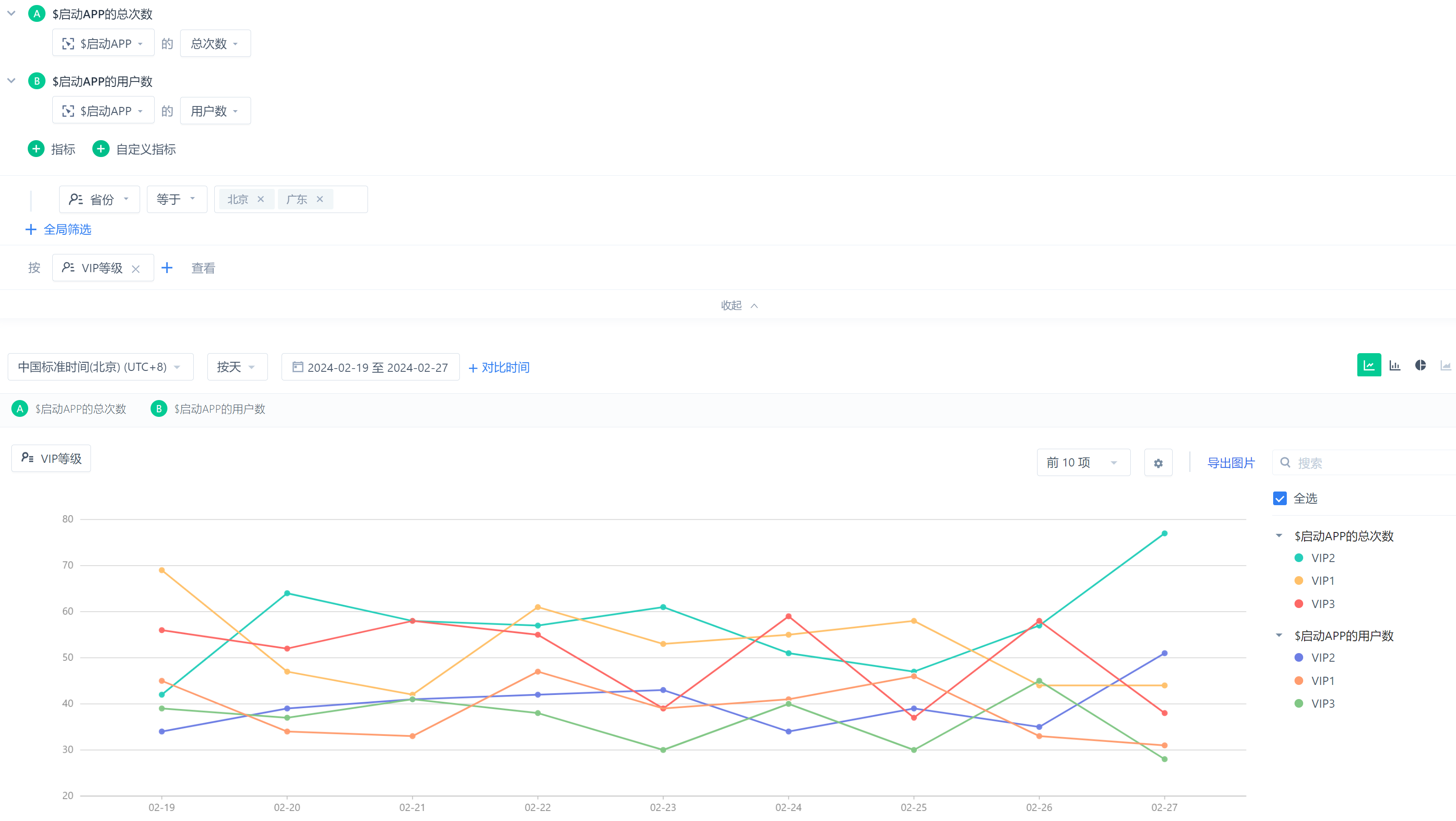
3.2、一点思考
1、对于一个工具类的产品,经常会面临着易用性和灵活性的矛盾。如果设计的足够灵活,这样可以支持更多更复杂的情况,但往往也意味着使用门槛的提高,目标用户的减少。
相反如果设计的足够易用,虽然门槛低了,目标用户多了,但很多情况支持不到,或者支持的不完整。在做产品设计的时候经常需要基于业务需求、实现成本、项目发展阶段来进行设计。

2、如果我们进一步对指标和库表取数在易用性上提升,那会是什么产品形态
本文由 @暮雪云然 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


