
 起点课堂会员权益
起点课堂会员权益终局之战!OpenAI Sora大佬专访:AI视频模型仍处在GPT-1时代
Sora一出,谁与争锋!近日,Sora团队的三位负责人Aditya Ramesh、Tim Brooks和Bill Peebles接受了采访,解读了Sora在模拟现实、预测结果和丰富人类体验等方面带来的变革。

对于视频生成领域,大家一致的看法就是:Sora一出,谁与争锋!
然而,身处于风口浪尖的Sora团队成员怎么看?
近日,Sora的三位领导者,Aditya 、Tim和Bill接受了专访。
结果就是——相当稳健!
看过整个采访视频你会发现,除了年轻有为,整个团队的思考和规划都非常稳。
稳到实际上没有什么规划。
稳到就像是知道自己稳赢,或者并不在乎能不能赢,只管踏踏实实改进模型。
也许是OpenAI的企业文化?诸位随意碰瓷,如果有人在排行榜上超过了我,我就会拉个分支出来,release一版重归王座。
ps:对这三位大佬以及团队其他成员还不太了解的观众老爷们,可以参见这一期。
对于整个采访视频,小编帮大家总结成四点:
模拟现实通往AGI:
AGI是充满希望的未来,但有了Sora,这一切就不会止步于想象。
Sora通过在神经网络中模拟复杂环境,弥合了当前AI能力与高级通用智能(AGI)之间的差距。
随着Sora的发展,它将能够全面理解我们的三维世界,实现向更复杂人工智能系统的飞跃。
丰富人类体验:
Sora成为了创造力的媒介,用户利用它来创作新颖的艺术和叙事。
同时,Sora的探索增强了传统形式的内容创作,为故事的讲述和经验的分享提供一个新的维度。
未来,从娱乐到教育的各个领域,提供的内容将更具沉浸感和互动性。
技术基础、质量成本和受众:
三位大佬还现场讲述了Sora的技术基础,包括数字建模、物理引擎和视频生成等方面。
另外在实际部署和优化方面,需要考虑可访问性和可负担性,确保Sora的能力能够覆盖广泛的受众,同时又不影响质量和效益。
价值观:
安全问题是旅途中永远不可忽视的。
特别是关于错误信息和滥用AI生成内容的问题,需要技术的努力,也需要相关的准则和法规。
三人表示:不急,我们的Sora正在接受艺术家和伦理学家的反馈,确保对齐社会价值观和安全标准。
一、模拟一切,直到AGI
团队相信,Sora真的处于通往AGI的关键路径上。
比如我们可以重温一下Sora曾带给我们的惊艳场景:

冬日,东京,人群。人们交谈、牵手,有人在附近的摊位卖东西。
这个场景有如此多的复杂性,很好地说明了如何在神经网络的权重范围内,模拟极其复杂的环境和世界,并预测未来的行为。
为了生成真正逼真的视频,模型必须学习人们如何工作、如何与他人互动,如何思考。
——不仅仅是人,还有动物,以及任何你想建模的物体。
而随着Sora的规模不断扩大,她将有可能变成另一个概念股——世界模型。
任何人都可以和这个「世界模拟器」互动,每个人都可以拥有自己的模拟器,在任何时候去体验模拟事件、模拟人生(或者模拟爱情?)
通过这种方式,人类将帮助模型一步步走向那个华丽的终点。
「这将会发生」。
二、Sora 如何影响世界
1. 探索创造潜力,丰富人类体验
世界模型在不远的未来,而另一些体验就在此刻,发生在我们身边。
当Sora推出时,很多人会被美丽的画面所吸引,被水中小熊猫的倒影所震惊。

但是现在,越来越多的人开始使用它,职业创作者可以尽情发挥自己的创造力,普通人也可以展示自己的想法。
Sora团队举了两个例子,首先是一个短篇故事airhead:

区别于传统形式的内容创作(特效、剪辑等),Sora帮助创作者解锁了一种很酷的方式,为故事的讲述和经验的分享提供一个新的维度。
另一个例子是Bill本人使用Sora制作的,纽约动物园的多镜头场景:

作为一个喜欢生成创意内容,但没有足够技能去实现的人,使用Sora这样的模型可以很容易做出引人注目的作品。
Bill通过提示和迭代得到了自己喜欢的东西,整个过程只花了不到一个小时。
「我玩得很开心」。
2. 从短片到世界模型
技术积累、由短变长,是电影工业的历程,也是Sora的未来。
看看皮克斯30年来的演变,以后也会有越来越多的人,使用视频生成模型,制作越来越多的电影。

同时Tim认为,人们会找到全新的方式来使用模型,这将与我们习惯的当前媒体完全不同。
比如上面谈到的世界模型,创作者以一个非常不同的范式,模拟想让用户看到的东西,人们能够与内容互动,带来意想不到的结果。
另外一个急需世界模型的领域,就是机器人。

Bill表示,机器人可以从模型构建的虚拟世界中学到很多东西,这是其他形式所无法比拟的。
再一次回到东京那个场景,腿是如何运动的,以及如何以物理上精确的方式与地面接触。
——模型从原始视频的训练中学到的关于物理世界的知识,将能够低成本传递给机器人,或者其他领域。
三、时空补丁和新架构
1. 更多算力,更强性能
Sora在OpenAI的DALL·E模型(Diffusion model)和GPT模型(Transformer)的研究基础上进行构建,
扩散模型(Diffusion model)是一个创建数据的过程,从噪声文件开始,反复删除噪声,形成最终结果。

而Transformer则提供了强大的学习能力和可扩展性,在更多计算和更多训练数据的加持下,Sora的能力将会越来越强。

团队的实验结果证明了模型表现和算力的这种正相关,他们也坚信这种趋势将会持续下去。
使用Transformer的好处之一是可以继承领域中的所有伟大属性,比如语言。
类比到视频数据,也要构建相应的损失函数,还要想办法在不增加所需计算量的情况下,获得更好的损失。——这也是团队正在努力的方向。
2. 长视频生成的秘密
大语言模型范式能够成功的关键因素之一,就是token的概念。
互联网上充斥着各种各样的文本数据,有书籍,有代码,有数学。而LLM将他们统一转化为token,于是能够在如此广泛多样的数据上进行训练。
而以前的视觉生成模型没有搞明白这件事情。
在Sora之前,大家一般使用256 × 256分辨率的图像或256 × 256的视频进行训练,这限制了视频生成的长度,更限制了模型能够获取的信息。
在Sora中,团队引入了时空块的概念,无论是图像还是视频,也无论是什么尺寸,只需要把它们看成是一个个的小块。
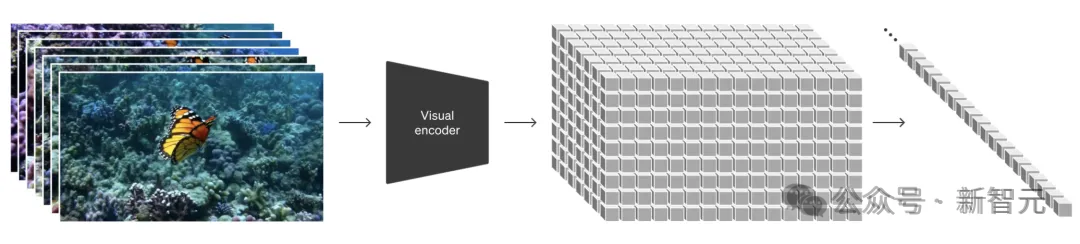
——这就是相对于视觉模型的token。
这样做的结果是,Sora拥有了通用的能力,不仅仅是生成固定时间的720p视频,你可以生成垂直视频,宽屏视频,还可以生成图像。
从零开始:
在Sora之前,许多人一直在做的是对图像生成模型进行扩展,最终可以生成几秒钟的视频。
而我们得先定一个小目标:如果需要制作一分钟的高清视频应该怎么办?
以这个目标为导向,就需要抛弃传统的方法,从零开始,数据需要分解成非常简单的方式,模型需要可扩展,——于是Sora架构诞生了。
「这是第一个视觉内容生成模型,同时具有语言模型的广度」。
四、创造人人都能用的Sora
1. 价值观
安全绝对是一个相当复杂的话题。
比如模型处理有害内容图像的方式,比如虚假信息,是否应该允许用户生成带有攻击性词语的图像?
部署这项技术的公司应该承担多少责任?社交媒体公司应该花多大力气来向用户表明内容的可信度?用户对于自己创作的东西应该怎样负责?
我们需要认真思考这些问题,在保证对齐人类价值观的基础上,不扼杀未来的创造力。
2. 民主化
目前,生成视频是非常消耗资源的,而且用户可能需要等待几分钟才能拿到自己的结果。
未来,这项技术应该惠及所有人,团队正在朝这个方向努力。
当然,在民主化的过程中,我们也要非常小心错误信息和任何周围风险。
3. 从近似世界模型到高保真预测
Sora没有进行过3D信息的训练,却从海量视频中学会了空间关系。
Sora正在学习我们人类的世界,却有可能比我们更接近真实。
人类思考事物的方式是有缺陷的,实际上我们无法做出非常准确的长期预测。
而作为世界模型,Sora将提供这种能力,有朝一日会比人类更聪明。
喂给它给多的算力和数据,它就能变得更好。
而随着规模的增加,学习可扩展智能的最佳方法就是预测数据,——就像LLM所做的那样。
Sora的scaling law还远远没有走完,或者说才刚刚开始。
「这是令人兴奋的时刻,我们期待未来模型的能力」。
参考资料:
https://twitter.com/saranormous/status/1783505771097112703
编辑:alan
来源公众号:新智元(ID:AI_era),“智能+”中国主平台,致力于推动中国从“互联网+”迈向“智能+”。
本文由人人都是产品经理合作媒体 @新智元 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


