起点课堂会员权益
起点课堂会员权益
国产多模态大模型开源!无条件免费商用,性能超Claude 3 Sonnet
 产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..
产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..现在国内的大模型发展日新月异,比如正文提到的元象发布的这款开源大模型,各个方面的表现都很不错。

又一个国产多模态大模型开源!
XVERSE-V,来自元象,还是同样的无条件免费商用。
此前元象曾率先发布国内规模最大的开源大模型,如今开源家族系列又多了一个。
最新的多模态大模型支持任意宽高比图像输入,在主流评测中保持着效果领先——
- 在多项权威多模态评测中,XVERSE-V超过零一万物Yi-VL-34B、面壁智能OmniLMM-12B及深度求索DeepSeek-VL-7B等开源模型。
- 在综合能力测评MMBench中超过了谷歌GeminiProVision、阿里Qwen-VL-Plus和Claude-3V Sonnet等知名闭源模型。

支持任意长宽比图像输入
传统的多模态模型的图像表示只有整体,XVERSE-V 采用了融合整体和局部的策略,支持输入任意宽高比的图像。

兼顾全局的概览信息和局部的细节信息,能够识别和分析图像中的细微特征,看的更清楚,理解的更准确
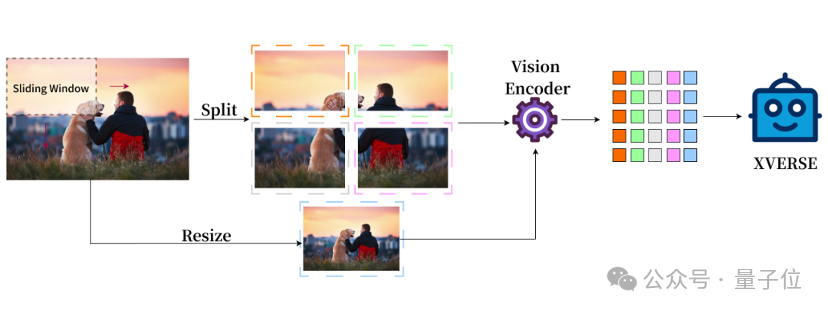

这样的处理方式使模型可以应用于广泛的领域,包括全景图识别、卫星图像、古文物扫描分析等。
 △示例- 高清全景图识别
△示例- 高清全景图识别
 △示例-图片细节文字识别
△示例-图片细节文字识别
除了基本能力表现不错,也能轻松应对各种不同的实际应用场景,比如图表、文献、代码转化、视障真实场景等。
图表理解
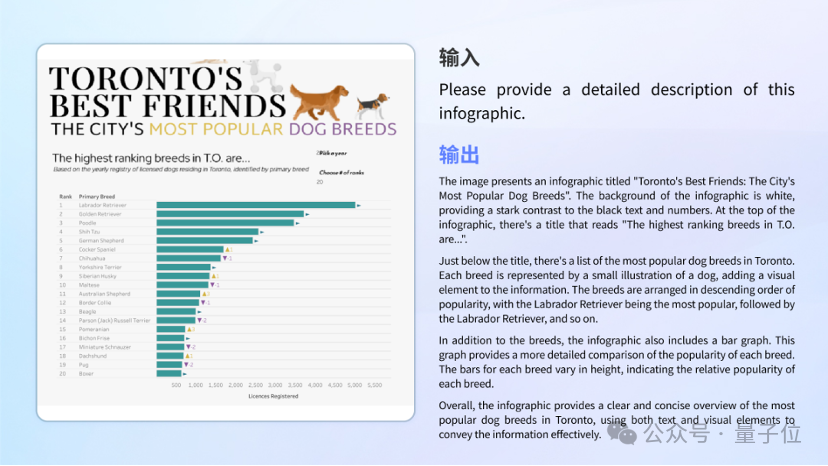
不论是复杂图文结合的信息图理解,还是单一图表的分析与计算,模型都能够自如应对。
自动驾驶

代码撰写
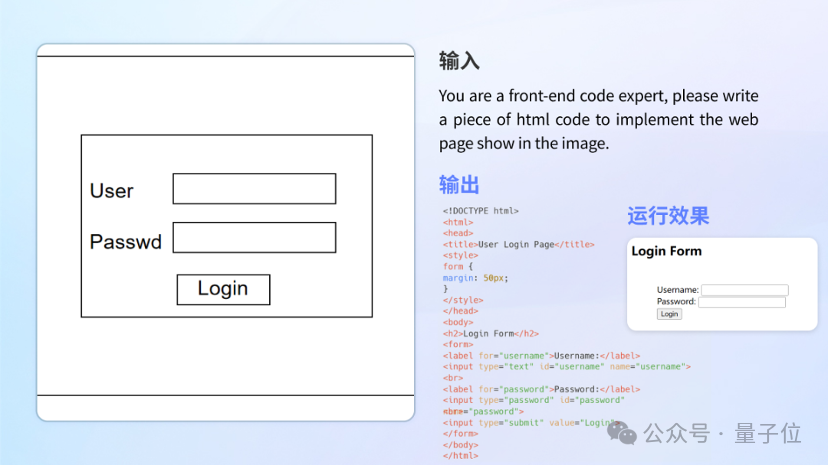
还有视障真实场景
在真实视障场景测试集VizWiz中,XVERSE-V的表现超过了InternVL-Chat-V1.5、DeepSeek-VL-7B等几乎所有主流的开源多模态大模型。该测试集包含了来自真实视障用户提出的超过31000个视觉问答,能准确反映用户的真实需求与琐碎细小的问题,帮助视障人群克服他们日常真实的视觉挑战。

本文由人人都是产品经理作者【量子位】,微信公众号:【量子位】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







评论
- 目前还没评论,等你发挥!