
 起点课堂会员权益
起点课堂会员权益LLM上下文窗口突破200万!无需架构变化+复杂微调,轻松扩展8倍
LongRoPE方法首次将LLM的窗口扩展到了2048k个token,只是简单微调的情况下,就能实现与短上下文窗口相近的性能!

大型语言模型(LLM)往往会追求更长的「上下文窗口」,但由于微调成本高、长文本稀缺以及新token位置引入的灾难值(catastrophic values)等问题,目前模型的上下文窗口大多不超过128k个token
最近,Microsoft Research的研究人员提出了一个新模型LongRoPE,首次将预训练 LLM 的上下文窗口扩展到了2048k个token,在256k的训练长度下只需要1000个微调步骤即可,同时还能保持原始短上下文窗口的性能。

论文链接:https://arxiv.org/abs/2402.13753
代码链接:https: //github.com/microsoft/LongRoPE
LongRoPE主要包含了三个关键创新点:
- 通过高效搜索识别并利用了位置插值中的两种非均匀性,为微调提供了更好的初始化,并在非微调情况下实现了 8 倍扩展;
- 引入了渐进扩展策略,首先微调 256k 长度的 LLM,然后在微调扩展的LLM上进行第二次位置插值,以实现 2048k 上下文窗口;
- 在8k长度上重新调整 LongRoPE以恢复短上下文窗口性能。
在 LLaMA2 和 Mistral 上对各种任务进行的大量实验证明了该方法的有效性。
通过 LongRoPE 扩展的模型保留了原始架构,只对位置嵌入稍作修改,并且可以重复使用大部分已有的优化。
一、位置插值的不均匀性
Transformer模型需要明确的位置信息,通常以位置嵌入(position embedding)的形式来表示输入token的顺序。
本文中的位置嵌入表示方法主要来自于RoPE, 对于位置索引为 n 的标记,其相应的 RoPE 编码可简化如下:

其中,d 是嵌入维度,nθi 是标记在位置 n 上的旋转角度,θi = θ -2i/d 表示旋转频率。在 RoPE 中,θ 的默认基准值为 10000。
受 NTK 和 YaRN 的启发,研究人员注意到这两个模型可以从非线性嵌入中获得性能提升,特别是在考虑 RoPE 各维度的不同频率以进行专门的内插法和外推法时。
然而,当前的非线性在很大程度上依赖于人为设计的规则。
这也自然引出了两个问题:
- 当前的位置插值是否是最佳的?
- 是否存在尚未探索的非线性?
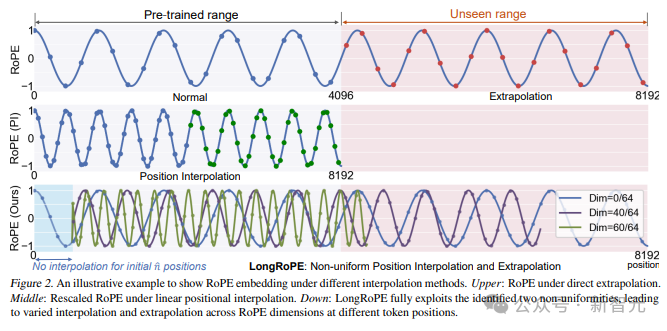
为了回答这些问题,研究人员使用进化搜索(evolution search)为LLaMA2-7B发现更好的非均匀位置插值。搜索以易错性为指导,使用来自PG19验证集的5个随机样本。
通过实证分析,研究人员总结了几个主要发现。
发现1:RoPE维度表现出很大的不均匀性,目前的位置插值方法无法有效处理这些不均匀性;
在公式 2 中为每个 RoPE 维度搜索最佳 λ。

研究人员对比了PG19和Proof-pile测试集上使用不同方法的 LLaMA2-7B 在不进行微调的情况下的复杂度。
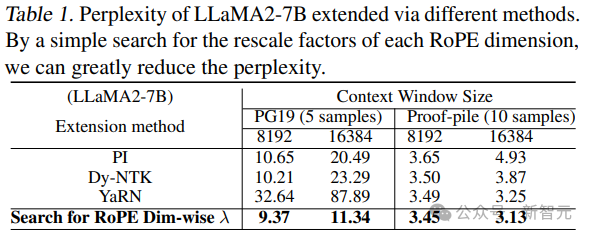
从结果来看,搜索到的解决方案有明显改善,表明当前的线性(PI,positional interpolation)和非均匀(Dynamic-NTK 和 YaRN)插值方法都不是最佳的。
值得注意的是,YaRN 在 PG19 上的表现不如 PI 和 NTK,因为其达不到非微调 LLM 的目标上下文窗口长度。
例如,在 8k 上下文大小的情况下,YaRN 的困惑度在 7k 后达到峰值。
通过搜索,公式 2 中的重标度(rescaled)因子λ变得不均匀,与PI、NTK的公式计算和YaRN的分组计算中的固定标度s有所不同。
在8k和16k上下文窗口中,这些非均匀因子大大提高了LLaMA2的语言建模性能(即复杂度),而无需进行微调,主要是因为由此产生的位置嵌入有效地保留了原始的RoPE,尤其是关键维度,从而降低了LLM区分近似token位置的难度。
发现2:输入序列中初始词块的RoPE推断应减少插值;
对于输入序列中的初始n个token,假设RoPE应该做较少的插值,这是因为会获得较大的注意力分数,从而对注意力层至关重要,正如在Streaming LLM和 LM-Infinite 中观察到的那样。
为了验证这一点,研究人员使用PI和NTK将上下文窗口扩展到 8k 和 16k,保留前 n(0,2, …, 256)个token,不进行插值。当n=0 时,则恢复到原来的 PI 和 NTK

上表中可以观察到两个结果:
- 保留起始token而不进行位置插值确实能提高性能。
- 最佳起始token数n取决于目标扩展长度。
发现3:在微调和非微调设置中,非均匀位置插值都能有效扩展 LLM 上下文窗口。
虽然已经证明,在不进行微调的情况下,搜索到的非均匀位置插值能显著提高8k和16k扩展性能,但更长的扩展需要微调。
因此使用搜索到的RoPE对LLaMA2-7B的64k上下文窗口大小进行了微调。

从结果中可以看到,在微调LLaMA2-7B之前和之后,该方法都明显优于PI和YaRN,主要原因是有效地使用了非均匀位置插值、最小化信息损失,以及为微调提供了更好的初始化。
受上述发现的启发,研究人员提出了LongRoPE,首先引入了一种高效的搜索算法,以充分利用这两种不均匀性,并将LLM上下文窗口扩展到 200 万个token

具体形式化算法参见原文。
二、实验结果
研究人员将LongRoPE应用于LLaMA2-7B和Mistral-7B模型上,并从三个方面对其性能进行了评估:
- 长文档中扩展上下文 LLM 的困惑度;
- 密钥(passkey)检索任务,该任务衡量模型从大量无关文本中检索简单密钥的能力;
- 4096上下文窗口的标准LLM基准;
1. 在256k范围内进行长序列语言建模
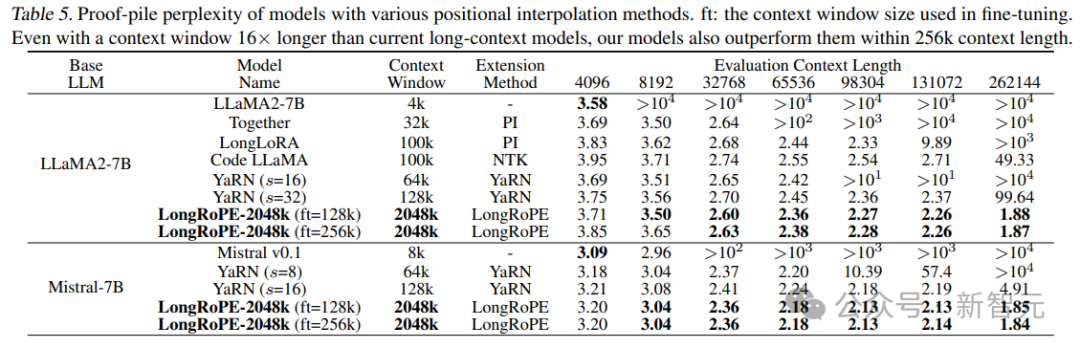
在Proof-pile和PG19上通过不同插值方法扩展的 LLaMA2 和 Mistral 的困惑度。
从实验结果中可以得出两个关键的结论:
- 从 4k 到 256k 的评估长度来看,扩展模型展现出整体困惑度下降的趋势,表明模型有能力利用更长的上下文;
- 即使在上下文窗口长度为 16 倍的情况下(这通常是在较短上下文长度下保持性能所面临的挑战),我们的 LongRoPE-2048k 模型在 256k 上下文长度内的性能仍优于最先进的基线模型。
2. 超过2000k的长序列语言建模
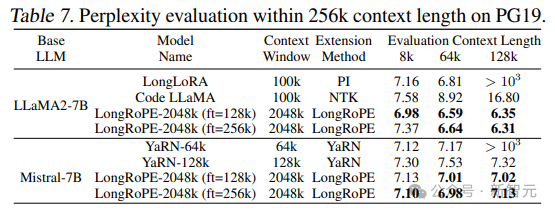
为了评估超长文档的有效性,研究人员使用了Books3数据集。
为了评估效率,随机选择20本书,每本长度超过2048k个token,并使用256k的滑动窗口。
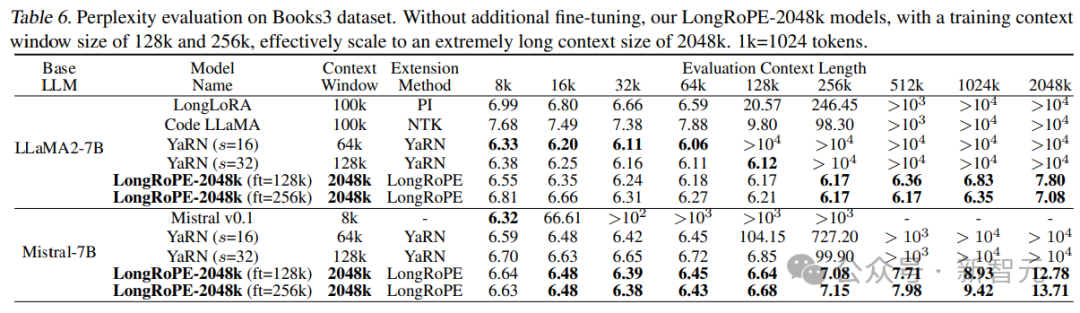
从结果中可以看出,LongRoPE成功地将LLaMA2-7B和Mistral-7B的上下文窗口扩展到2048k,同时还在8k-128k的较短长度内实现了与基线相当或更好的困惑度。
还可以观察到2048k LLaMA2和Mistral之间的显著性能差异:Mistral在较短的长度上优于基线,但困惑度在超过256k长度时达到7
LLaMA2的性能与预期一致:随着时间的延长,困惑感会有所减少,在1024k和2048k时略有增加。
此外,在LLaMA2上,LongRoPE-2048k在256k比128k的微调长度下表现更好,主要是由于次级延伸比(secondary extension ratio)更小(即8倍对16倍)。
相比之下,Mistral在微调128k的窗口大小方面表现更好,主要原因是对于Mistral的128k和256k微调,研究人员遵循YaRN的设置使用16k训练长度,影响了Mistral在微调后进一步扩展上下文窗口的能力。
参考资料:
https://arxiv.org/abs/2402.13753
编辑:LRS
来源公众号:新智元(ID:AI_era),“智能+”中国主平台,致力于推动中国从“互联网+”迈向“智能+”。
本文由人人都是产品经理合作媒体 @新智元 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


