
 起点课堂会员权益
起点课堂会员权益机器学习之朴素贝叶斯算法基本原理
什么是朴素贝叶斯算法?朴素贝叶斯算法可以如何被应用与实践?关于这些问题,作者做了较为详细的阐述,我们不妨一起来看一下。

一、什么叫朴素贝叶斯算法?
朴素贝叶斯是基于“特征之间是独立的”这一朴素假设,应用贝叶斯定理的监督学习算法。
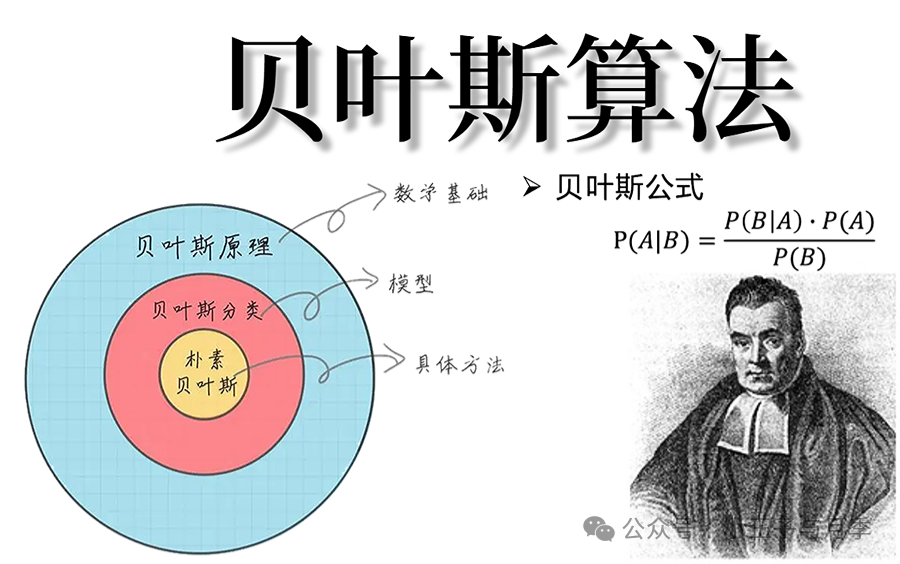
二、朴素贝叶斯算法的基本原理是什么?
贝叶斯公式又被称为贝叶斯规则,其原理大概是:当不能准确知道事物本质时,可以根据与事物特定本质相关的事件出现的多少去判断该事物的本质。
比如,我们虽然无法准确的知道某个西瓜是不是好西瓜,但是我们可以通过敲击声、色泽、根蒂形状等特征去判断是否是好西瓜,如果它的敲击声沉闷、色泽青绿、根蒂蜷缩,那我们根据经验可以判断它大概率是个好西瓜。
需掌握的基本概念:
- 先验概率:事件A根据经验来判断发生的概率,记作P(A)。比如从历史数据中统计出西瓜“色泽青绿”事件的概率为60%,那么P(色泽青绿)=60%
- 条件概率:事件B在事件A已发生条件下的概率,记作P(B|A)。比如从历史数据中统计出西瓜为“好瓜”时,“色泽青绿”的概率为80%,那么P(色泽青绿|好瓜)=80%
- 后验概率:基于先验概率求得的反向条件概率。P(B|A)是A发生后B的条件概率,也可以称作B的后验概率,所以后延概率的公式和条件概率一样,但区别在于条件概率是从历史数据中统计得来,而后验概率是基于先验概率和条件概率计算得来。
- 联合概率:表示两个事件共同发生的概率。A与B的联合概率一般表示为P(AB)或P(A,B)。比如“色泽青绿”(事件A)和“敲击声沉闷”(事件B)同时发生的概率为30%,则事件A和事件B同时发生的概率P(AB)=30%
朴素贝叶斯是在贝叶斯原理的基础上,假定特征与特征之间相互独立,从而得到了如下朴素贝叶斯的公式:
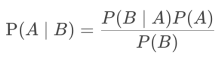
假设公式里的A代表“好瓜”,B代表“色泽青绿”,那么我们可以得到如下几个概率:
P(A):历史数据中,统计西瓜为“好瓜”的概率,比如70%
P(B):历史数据中,统计西瓜为“色泽青绿”的概率,比如60%
P(B|A):历史数据中,统计西瓜为“好瓜”时,“色泽青绿”的概率,比如75%
那么我们就可以根据这几个概率,代入公式,计算得到P(A|B),即西瓜“色泽青绿”时,为“好瓜”的概率:P(A|B) = P(B|A)*P(A)/P(B) = 0.75*0.7/0.6 = 87.5%
也就是说,当西瓜“色泽青绿”时,有87.5%的概率是“好瓜”。
当然,仅仅靠一个特征是无法判断西瓜好坏的,那么多个特征的时候要怎么计算呢?我们来扩展一下,再引入一“敲击声沉闷”特征。
也就是假设A1代表“好瓜”,A2代表“坏瓜”,B1代表“色泽青绿”,B2代表“敲击声沉闷”,计算当西瓜同时具备“色泽青绿”和“敲击声沉闷”特征时,为好瓜或坏瓜的概率。
P(A1):历史数据中,统计西瓜为“好瓜”的概率,比如70%
P(A2):历史数据中,统计西瓜为“坏瓜”的概率,比如30%
P(B1B2):历史数据中,统计西瓜同时具备“色泽青绿”和“敲击声沉闷”特征的概率,比如30%
P(B1B2|A1):历史数据中,统计西瓜为“好瓜”时,同时具备“色泽青绿”和“敲击声沉闷”特征的概率,比如40%
P(B1B2|A2):历史数据中,统计西瓜为“坏瓜”时,同时具备“色泽青绿”和“敲击声沉闷”特征的概率,比如15%
我们将以上概率代入公式,分别得到如下结果:
P(A1|B1B2) = P(B1B2|A1)*P(A1)/P(B1B2) = 0.4*0.7/0.3= 93.33%
P(A2|B1B2) = P(B1B2|A2)*P(A2)/P(B1B2) = 0.15*0.3/0.3 = 15%
也就是说,当西瓜同时具备“色泽青绿”和“敲击声沉闷”特征时,有93.33%的概率是“好瓜”,15%的概率是“坏瓜”。
三、朴素贝叶斯算法的变种及其特性
1. 多项式朴素贝叶斯
多项式朴素贝叶斯指当特征属性服从多项分布(特征是离散的形式的时候)。
多项式朴素贝叶斯适用于处理离散型和计数型特征,常用于文本分类任务。它的核心思想是对每个类别计算文档中所有单词的条件概率,并假设各单词的出现与否独立于其他单词。
2. 高斯朴素贝叶斯
高斯朴素贝叶斯指当特征属性为连续值时,而且分布服从高斯分布,那么在计算P(x|y)的时候可以直接使用高斯分布的概率公式。
高斯朴素贝叶斯适用于数值型连续特征,假设每个特征在给定类别下独立且服从高斯分布(正态分布)。在构建模型时,分别估计每个类别下每个特征的均值和方差,然后基于这些参数计算新的数据点属于各类别的概率。
3. 伯努利朴素贝叶斯
伯努利朴素贝叶斯指当特征属性为连续值时,而且分布服从伯努利分布, 那么在计算P(x|y)的时候可以直接使用伯努利分布的概率公式
对于二元特征,如文本中的词频是否大于零,伯努利朴素贝叶斯使用二项式分布进行建模。它关注的是特征在文档中出现的次数,而非具体的频率值,因此特别适合处理文本分类中的“词是否出现”的场景。
四、朴素贝叶斯算法的优势与局限性
1. 朴素贝叶斯算法的优势
计算效率高:由于朴素贝叶斯算法在训练阶段仅需要计算先验概率和条件概率,无需进行复杂的迭代优化过程,因此其训练速度快,尤其对于大数据集具有很好的可扩展性。同时,在预测阶段,只需对新样本的特征进行简单的概率乘积或密度函数计算,时间复杂度较低。
处理高维数据能力强:对于包含大量特征的数据集,即使数据维度极高,朴素贝叶斯算法仍能保持较快的学习速度和预测速度,这是许多其他复杂模型难以比拟的。
小样本学习效果好:相较于依赖大量数据拟合复杂模型的方法,朴素贝叶斯算法在小样本情况下表现较为出色,因为它并不试图从数据中学习复杂的非线性关系,而是基于统计学原理对类别概率进行估计。
易于理解和实现:朴素贝叶斯算法原理相对简单,易于理解,代码实现也较为直观,这为实际应用中的调试和优化提供了便利。
可以处理不相关的特征:朴素贝叶斯可以处理数据集中不相关的特征,并且仍然表现良好。
2. 朴素贝叶斯算法的局限性
特征独立性假设过于简化:算法的核心“朴素”假设——特征相互独立,这一假设在很多现实问题中往往不成立。特征间的相关性被忽略可能导致模型预测性能受到影响,特别是在高度相关的特征存在时,可能会低估某些类别的后验概率。
对输入数据分布敏感:如高斯朴素贝叶斯假设特征服从高斯分布,若实际数据不符合这种分布特性,则会导致预测结果产生偏差。例如,当特征值集中在某一区间而非正态分布时,高斯朴素贝叶斯可能无法准确捕捉数据的真实规律。
缺乏特征选择能力:朴素贝叶斯算法对待所有特征同等重要,无法自动识别并剔除无关或者噪声特征,这在一定程度上降低了模型的泛化能力和解释性。
无法处理连续变量:朴素贝叶斯假设特征是离散的,对于连续型数据需要进行离散化处理,可能会导致信息损失
需要足够的样本数据:朴素贝叶斯是基于统计学的算法,需要足够的样本数据来估计概率分布参数,否则会导致概率估计不准确,影响效果
五、朴素贝叶斯算法的应用与实践
1. 垃圾邮件过滤
朴素贝叶斯算法在垃圾邮件过滤领域应用广泛。通过分析邮件中的关键词、短语出现频率等特征,算法能够准确识别并分类垃圾邮件和正常邮件。即使存在新类型的垃圾邮件攻击,由于其基于统计学习的方法,也能够快速适应并更新模型。
2. 文本分类
在新闻分类、情感分析等领域,朴素贝叶斯算法同样表现出色。它能有效地对文档进行主题分类或情感倾向判断,通过计算词语在各类别下的概率分布来进行决策,尤其对于大规模文本数据集,具有高效处理的优势。
3. 医学诊断
在医疗领域,朴素贝叶斯算法可用于疾病预测和诊断。例如,在根据患者的症状、检查结果等特征信息预测患者是否患有某种疾病时,算法能够快速计算出各种可能疾病的后验概率,并选择最有可能的那个作为预测结果。
4. 推荐系统
尽管朴素贝叶斯在推荐系统中不如协同过滤等方法常见,但在某些场景下,如用户历史行为数据稀疏时,可以通过朴素贝叶斯算法来预测用户对未尝试过的商品或服务的兴趣度。
5. 自然语言处理
在词性标注、命名实体识别等自然语言处理任务中,朴素贝叶斯亦有应用。通过对上下文单词序列进行建模,它可以实现对未知词汇的标记预测。
参考文档:
朴素贝叶斯算法:如何用AI买到好瓜?-人人都是产品经理-AI小当家
机器学习 | 贝叶斯算法及应用-人人都是产品经理-SincerityY
七大机器学习常用算法精讲:朴素贝叶斯算法(二)-人人都是产品经理-火粒产品
本文由@厚谦 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


