
 起点课堂会员权益
起点课堂会员权益58行代码把Llama 3扩展到100万上下文,任何微调版都适用
开源之王Llama 3原本只有8k的上下文窗口,在开源社区技术大佬的努力下,仅需58行代码,自动扩展到1048k(一百万)上下文。怎么实现的?请看作者的分享。

堂堂开源之王Llama 3,原版上下文窗口居然只有……8k,让到嘴边的一句“真香”又咽回去了。
在32k起步,100k寻常的今天,这是故意要给开源社区留做贡献的空间吗?
开源社区当然不会放过这个机会:
现在只需58行代码,任何Llama 3 70b的微调版本都能自动扩展到1048k(一百万)上下文。
背后是一个LoRA,从扩展好上下文的Llama 3 70B Instruct微调版本中提取出来,文件只有800mb。
接下来使用Mergekit,就可以与其他同架构模型一起运行或直接合并到模型中。

所使用的1048k上下文微调版本,刚刚在流行的大海捞针测试中达到全绿(100%准确率)的成绩。
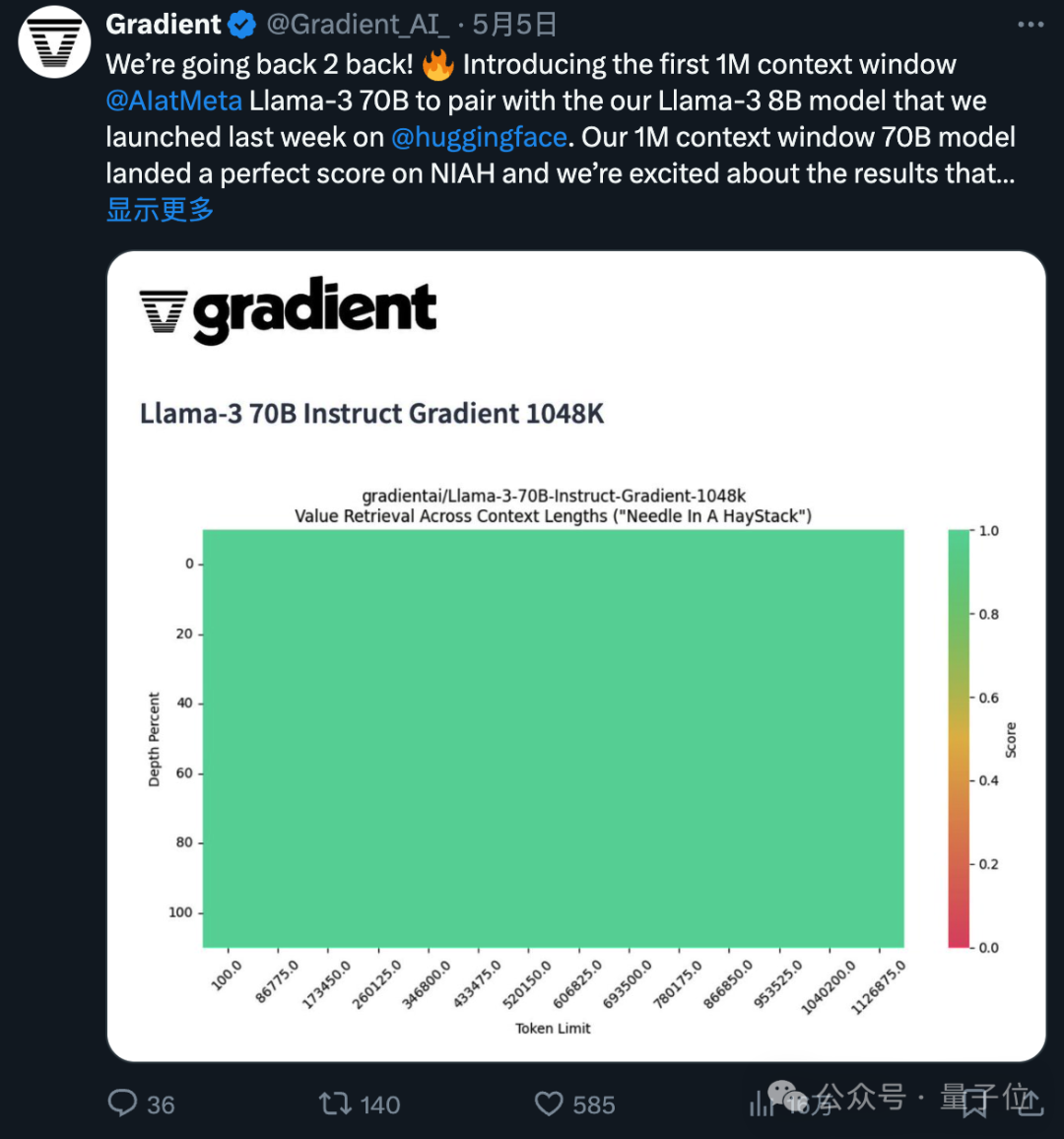
不得不说,开源的进步速度是指数级的。
1048k上下文LoRA怎么炼成的
首先1048k上下文版Llama 3微调模型来自Gradient AI,一个企业AI解决方案初创公司。

而对应的LoRA来自开发者Eric Hartford,通过比较微调模型与原版的差异,提取出参数的变化。
他先制作了524k上下文版,随后又更新了1048k版本。
首先,Gradient团队先在原版Llama 3 70B Instruct的基础上继续训练,得到Llama-3-70B-Instruct-Gradient-1048k。
具体方法如下:
- 调整位置编码:用NTK-aware插值初始化RoPE theta的最佳调度,进行优化,防止扩展长度后丢失高频信息
- 渐进式训练:使用UC伯克利Pieter Abbeel团队提出的Blockwise RingAttention方法扩展模型的上下文长度
值得注意的是,团队通过自定义网络拓扑在Ring Attention之上分层并行化,更好地利用大型GPU集群来应对设备之间传递许多KV blocks带来的网络瓶颈。
最终使模型的训练速度提高了33倍。
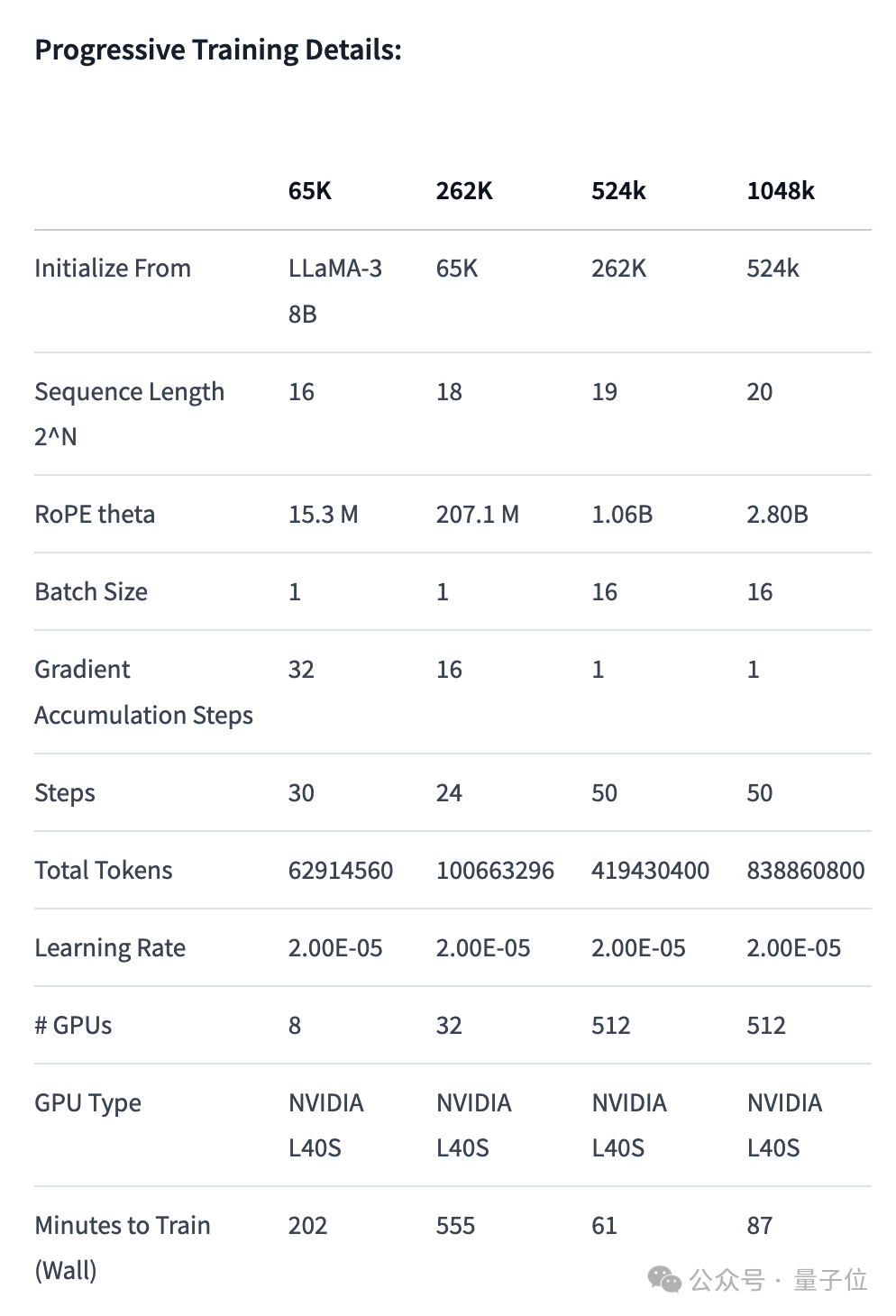
长文本检索性能评估中,只在最难的版本中,当“针”藏在文本中间部分时容易出错。

有了扩展好上下文的微调模型之后,使用开源工具Mergekit比较微调模型和基础模型,提取参数的差异成为LoRA。
同样使用Mergekit,就可以把提取好的LoRA合并到其他同架构模型中了。
合并代码也由Eric Hartford开源在GitHub上,只有58行。

目前尚不清楚这种LoRA合并是否适用于在中文上微调的Llama 3。
不过可以看到,中文开发者社区已经关注到了这一进展。

524k版本LoRA:
https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
1048k版本LoRA:
https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
合并代码:
https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
参考链接:
[1]https://twitter.com/erhartford/status/1786887884211138784
本文由人人都是产品经理作者【量子位】,微信公众号:【量子位】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


