
 起点课堂会员权益
起点课堂会员权益客户体验:问卷调研的样本量大小怎么确定?
在问卷调研工作中,不少小伙伴可能会不太清楚如何确定样本量。本文就对这一问题做了阐述,一起来看看。

在体验管理日常的问卷调研工作中,样本量大小的确定一直是很多小伙伴搞不清楚的地方。
现在网上也有一些免费的工具可以帮助进行计算,不过如果你缺少对其中变量的理解,就是拿到一个样本量的大小,也不知道怎么去解释,这很容易被其他人质疑。
理解这个事情一点都不难,你花几分钟时间,我来给你讲讲~
以下,enjoy~
一、什么是调研样本量?
🤔 想象一下,你很好奇早餐吃 Weetabix(一种早餐麦片)的长跑运动员和不吃的运动员在比赛中的表现是否有差异???
要弄清楚这个问题,理论上我们需要调查全世界的长跑运动员,但这显然不现实。
这时候,样本大小就变得重要了。
样本大小是指你在调查、研究或实验中包括的受试对象数量。
在对大量人群进行调查时,选择正确的样本大小至关重要,因为你不可能向每个人收集数据。相反,你可以从整个群体中随机抽取一些人,让他们代表整个群体。
假设你是一家咖啡店☕️的老板,你想知道顾客对新推出的「榛果拿铁☕️」的喜好程度。你的咖啡店在全国有 500 多家分店,服务超过百万的的顾客。
显然,你无法询问每一位顾客他们对「榛果拿铁☕️」的看法,因此你需要进行抽样调查。
在这个例子中,样本大小就是你选择调查的顾客数量。假设你决定调查 1,000 名顾客。
这 1,000 名顾客需要随机选择,以确保他们能够代表你所有的顾客。这样,无论是常来的老顾客还是偶尔光顾的新顾客,都有机会被包括在你的调查中。
通过这 1,000 名顾客的反馈,你可以得到一个关于顾客对「榛果拿铁☕️」喜好度的大致了解。
比如,如果 750 名顾客表示喜欢这款新饮品,你可以说,在一定的置信水平和置信区间下,大部分顾客对「榛果拿铁☕️」持积极态度。
这样的调查结果可以帮助你做出是否继续推广「榛果拿铁☕️」或调整食谱的决策。
通过这个过程,我们可以看到,合理的样本大小对于获取可靠信息,帮助我们做出更好的决策是非常关键的。
二、计算样本量需要了解什么?
当我们想了解一个大群体的某个特征时,通常不可能问遍每个人,这时候就需要抽样调查。
但怎么确保我们抽取的这一小撮人能代表整个群体呢?这就需要用到几个关键概念:置信区间、置信水平、人口规模和标准差。
1)置信区间(Confidence interval)
置信区间就像是给我们的调查结果划定一个合理的误差范围(margin of error)。
比如,我们在母亲节调查了一群杭州的朋友,发现 65% 的人计划给母亲买礼物,置信区间是 ±2.75%。
这就像是说,我们非常有信心(但不是 100% 确定)真实的比例会落在 63.25% 到 67.75% 之间。
想象一下,你用尺子量东西,但尺子上的刻度有点模糊,所以你会说这个长度大概在 9 到 11 厘米之间,这个“大概”就类似置信区间。
2)置信水平(Confidence level)
置信水平告诉我们这个“大概”有多靠谱。
如果置信水平是 95%,那就像是说,如果我们进行 20 次独立的同样调查,有 19 次的结果都会落在那个置信区间内。
这就像是你重复 20 次测量,19 次的结果都在 9 到 11 厘米之间。
3)人口规模(Population size)
人口规模就是你研究对象的总数。
比如全杭州人就是你的研究对象,那人口规模就是杭州的总人口数。
4)标准差(Standard Deviation)
标准差是衡量数据变化的一种方式。
如果大家的回答的选项都差不多,那标准差就小;如果大家的回答参差不齐,标准差就大。标准差小,你需要的样本量就会少一些;标准差大,你需要更多样本来确保调查结果的准确性。
当我们把这些因素结合起来,就可以计算出需要多大的样本量才能让我们的调查结果既准确又有信心。
如果我们不希望误差太大,就需要更多的样本;如果能容忍较大的误差,样本量可以少一些。
当然,如果调查的问题非常关键,比如涉及到重大决策,我们就会希望误差尽可能小,这时就需要更多的样本来确保结果的可靠性。
三、如何计算样本量的大小?
要计算样本大小,了解如何使用 Z 分数和样本大小公式是关键。即使你不知道总体的确切规模,这些信息仍然可以帮助你确定需要多少样本来进行有效的调查或研究。
1. 什么是 Z 分数(Z-score)?
Z 分数是统计学中的一个概念,它表示你的分数距离平均值有多少个标准差。在计算样本大小时,Z 分数代表了你想要的置信水平。
常见的置信水平有 90%,95%,和 99%,它们对应的 Z 分数分别大约是 1.645, 1.96, 和 2.576。
这里面我们需要使用到「正态分布Z值表」来帮助我们进行查找,下面是完整的表,可以存起来后面方便使用。
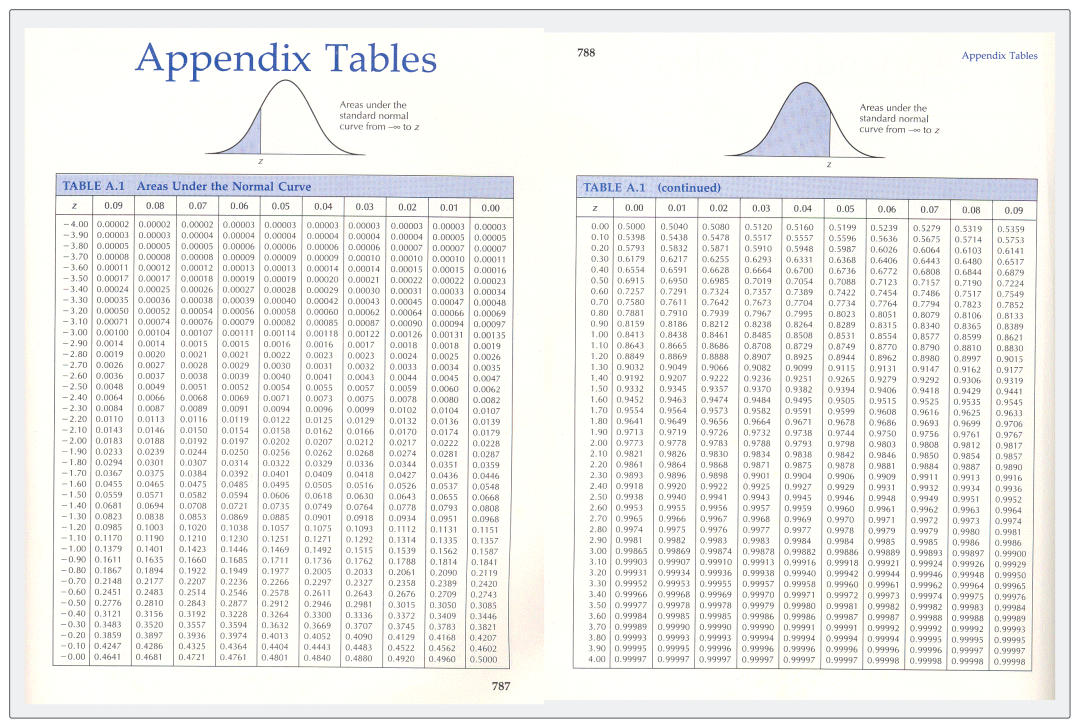
正态分布 Z 值表怎么看呢?
比如,我们想要找到置信水平为 90% 的时候,Z 分数是多少?(说明:你只知道置信水平是 90%,但不知道相应的 Z 分数是 1.645)
1)理解置信水平与 Z 分数的关系
90% 的置信水平意味着中间覆盖了总体的 90%,留下两端各占 5%(100% – 90% = 10%,两端各占一半,所以是 5%)。
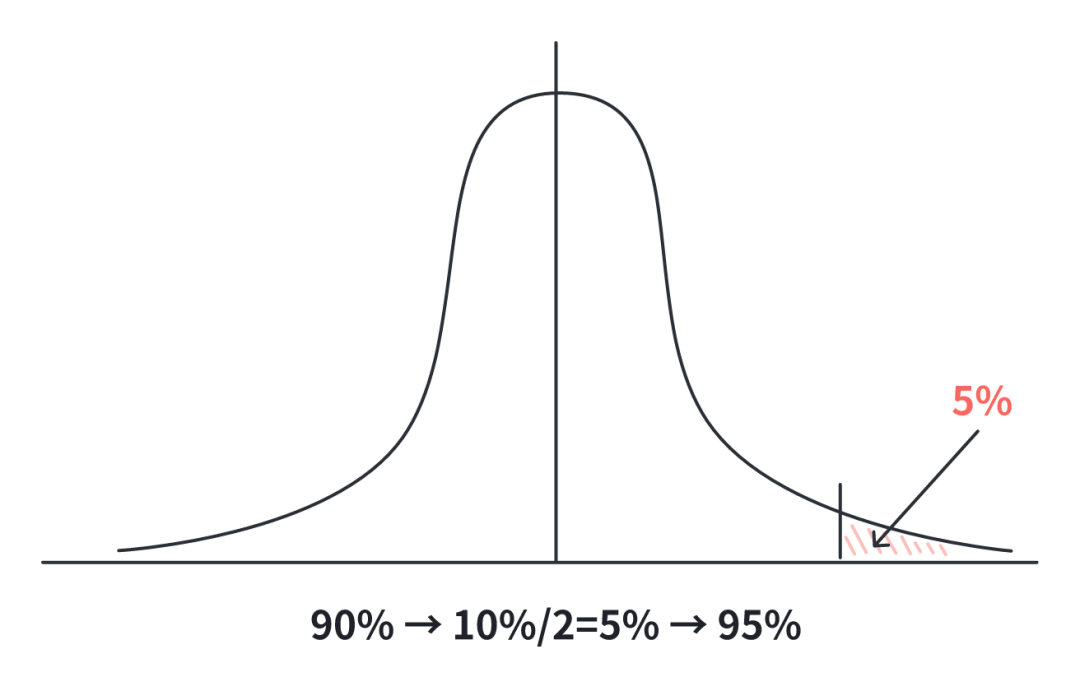
在标准正态分布中,这意味着你需要找到累积概率为 95%(50% + 45%)的 Z 分数。因为从最左端到中间覆盖了 50%,再加上从中间到你的 Z 点的 45%。
同样的,可以知道 95% 和 99% 应该通过以下数字查表:
- 95% → 5%/2 = 2.5% → 97.5%
- 99% → 1%/2 = 0.5% → 99.5%
2)使用Z分数表
在正态分布 Z 值表中,你通常会找到累积概率(从最左侧开始计算的面积),或者从平均值到 Z 点的累积概率。你需要找到累积概率接近 95% 的 Z 分数。
3)查找累积概率
在正态分布 Z 值表中,找到累积概率最接近 95% 的条目。通常的表类型会是从最左侧到 Z 值的累积概率,意味着是从标准正态分布的最左端(理论上是负无穷大)到特定 Z 值的累积概率。你需要在表中,找的是 0.9500 左右的值。
注意,还有另外一种表是显示从平均值到Z点的累积概率,即从标准正态分布的平均值(Z = 0)到特定Z值的累积概率。如果属于这种情况,你应该找接近 45%(或 0.4500)的值。
我所演示内容是前者,直接找接近 0.9500 左右的值就可以。
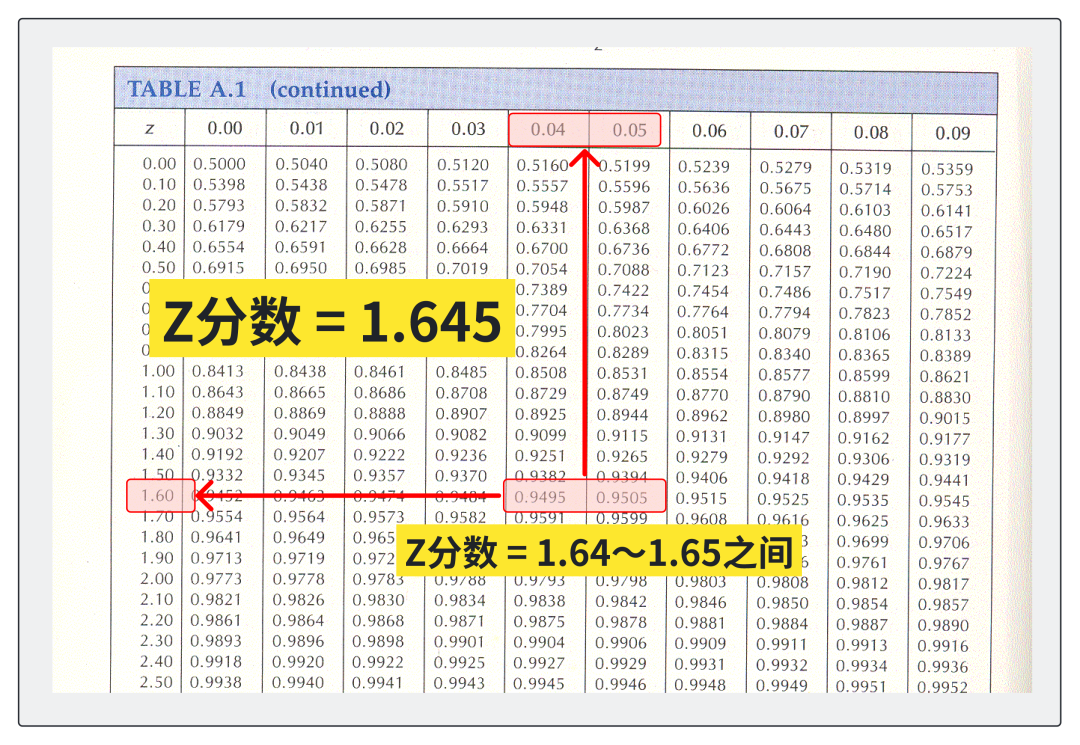
4)确定 Z 分数
找到对应的行和列,然后沿着这行和列确定交点,你就可以找到对应的 Z 分数。如果表是从最左侧到 Z 点的累积概率,你会找到累积概率为 0.9500 左右的 Z 分数。
从表中,我们可以看出 95% 存在于 1.64 到 1.65 之间,所以我们找到中间值,Z 分数就等于 1.645。
所以,置信区间为 90%,Z 分数为 1.645。
同样,置信水平 95% 和 99%,也可以通过对照表找到相应的 Z 分数。
2. 使用样本量公式计算
计算样本大小时,你需要知道以下几点信息:
1)置信水平(Z 分数):你需要多大的置信度?这决定了你的 Z 分数。
2)预期的效应大小(P):这通常是你希望能够检测到的最小变化或差异。假设我们没有先验知识,通常使用 P = 0.5 作为保守估计,因为这会给出最大的样本大小。
3)标准差(e):预期答案的变化范围。如果你不确定,可接受的误差范围 e 可以用 0.05(即 5%)作为一个保守估计。
一旦你有了这些信息,就可以使用样本大小公式来计算所需的样本量。样本大小公式可以帮助你根据上述因素确定需要调查多少人,以确保你的调查结果既有统计意义又具备代表性。
以一个简化的公式为例,样本大小可以用下面的公式估计:

如果你不知道总体规模,这个公式可以给出一个不考虑总体大小的样本估计。这个方法特别适用于大总体,因为当总体规模非常大时,样本大小不太受总体大小的影响。
假设我们要计算的情景如下:
- 置信水平是 95%,所以 Z = 1.96
- 预计效应大小(比例)P = 0.5
- 可接受的误差范围 e = 0.05(即 5%)
我们将这些值代入公式中:
N = (1.96² × 0.5 × (1 – 0.5)) / 0.05² = 384.16
根据计算,当置信水平为 95%,预期效应大小为 0.5,且可接受的误差范围为 5% 时,所需的样本大小大约为 384.16。
在实践中,我们通常会取整数,因此需要约 384 或 385 个样本来满足这些条件。这意味着如果你进行调查或实验,你需要至少 384 名参与者来确保你的结果具有统计意义。
以上。
专栏作家
龙国富,公众号:龙国富,人人都是产品经理专栏作家,CxHub主理人。致力于终身学习和自我提升,分享用户研究、客户体验、服务科学等领域资讯,观点和个人见解。
本文原创发布于人人都是产品经理,未经授权,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









不喜欢这篇文章 晦涩难懂 一摆出一堆数字来就知道肯定不是结果导向 而是过程导向做给老板看的