
 起点课堂会员权益
起点课堂会员权益
历时400多天,国产大模型全面赶超GPT-4?
 产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..
产品经理的职业发展路径主要有四个方向:专业线、管理线、项目线和自主创业。管理线是指转向管理岗位,带一个团队..赶超GPT-4的阶段性升级,可以看作是国产大模型有序迭代部署、不断拉近差距的标志,切莫像手机跑分那样,在过度营销的作用下,沦为被群嘲的对象。

稍微留意下近期的新闻,“赶超GPT-4”正在成为国产大模型的新热点。
百度文心一言、商汤日日新以及阿里云刚刚发布的通义千问2.5,均已迈入“全面赶超GPT-4”阵营。
把时间线稍微拉长一些的话,过去大半年时间里,“超越GPT-4”的消息可谓屡见不鲜,即使在报道中刻意加上了多项基准、部分指标等前缀,依然赚足了眼球,成为国产大模型佐证自身能力的有力指标。
简单做个复盘的话,国产大模型对GPT-4的追赶已经进行了400多天,其中“赶超进程”可以粗分为三个阶段。
第一阶段:部分性能超越GPT-4
2023年3月14日,OpenAI正式推出了GPT-4,彼时大多数国产大模型还未开放,少数内测大模型的比较对象还是GPT-3。作为业界标杆的GPT-4,就像是科幻照进了现实,被无数人捧上神坛。
但在短短半年后,GPT-4就出现在了国产大模型厂商的比较名单里。
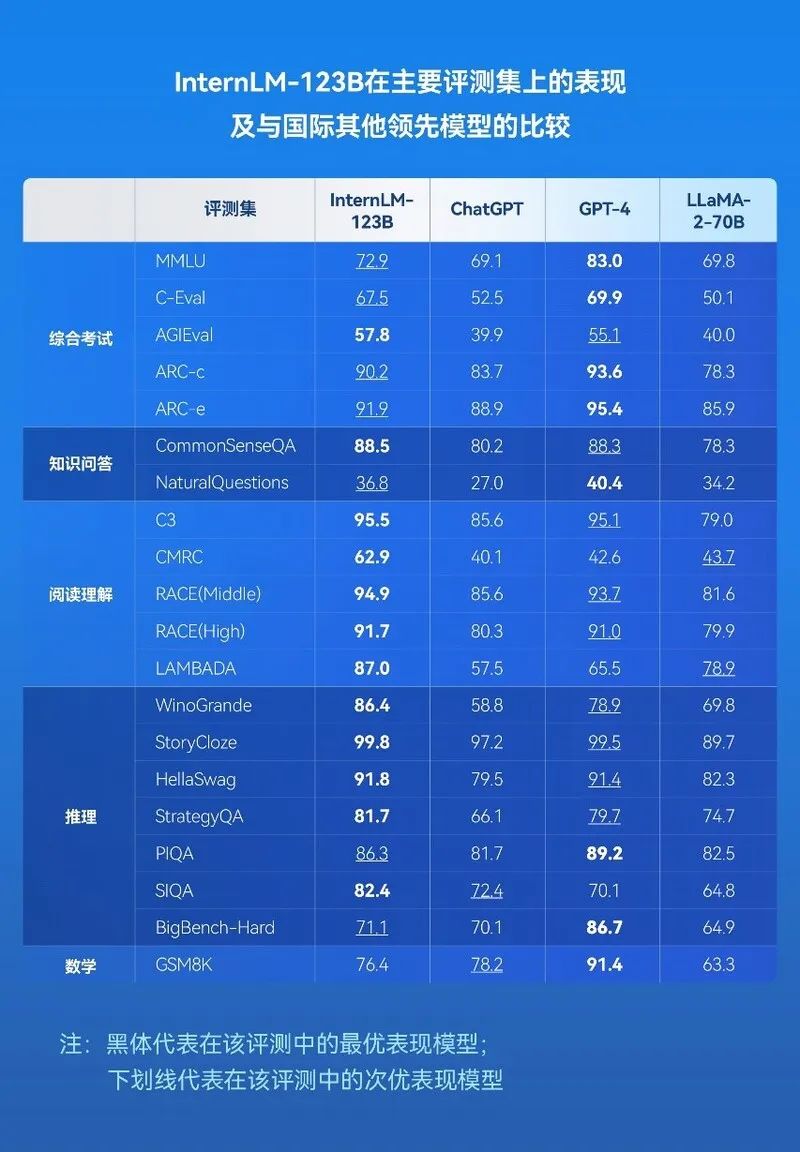
2023年8月底,商汤科技对外公布了一则新进展:拥有1230亿个参数的“书生·浦语”,在全球51个知名评测集共计30万道问题集合上,测试成绩排名全球第二,并在综合考试agieval、知识问答commonsenseqa、阅读理解和推理的十项评测中位列第一,分数超过风头正盛的GPT-4。

2023年10月17日的“生成未来”发布会上,百度正式发布了文心大模型4.0版本,李彦宏在现场依次演示了大模型的理解、生成、逻辑和记忆四大核心能力的特点与应用场景。
尽管没有给出评测数据,李彦宏却自信地表示:文心大模型4.0的综合水平,“与GPT-4相比毫不逊色”。

国产大模型赶超GPT-4的序幕正式拉开。
此后一两个月里,不少大模型给了这样的营销口径:整体能力已经不输于GPT-3.5,并且在部分性能指标上开始超越GPT-4。
第二阶段:整体性能逼近GPT-4
时间来到2024年初,国内的“百模大战”进入收敛期,一些不被资本市场认可的大模型,渐渐成了一个数字,只有几家科技大厂和独角兽仍活跃在大模型一线。
“活下来”的大模型,势必要在能力上证明自己。
综合性能逼近GPT-4,开始成为新的营销话术。
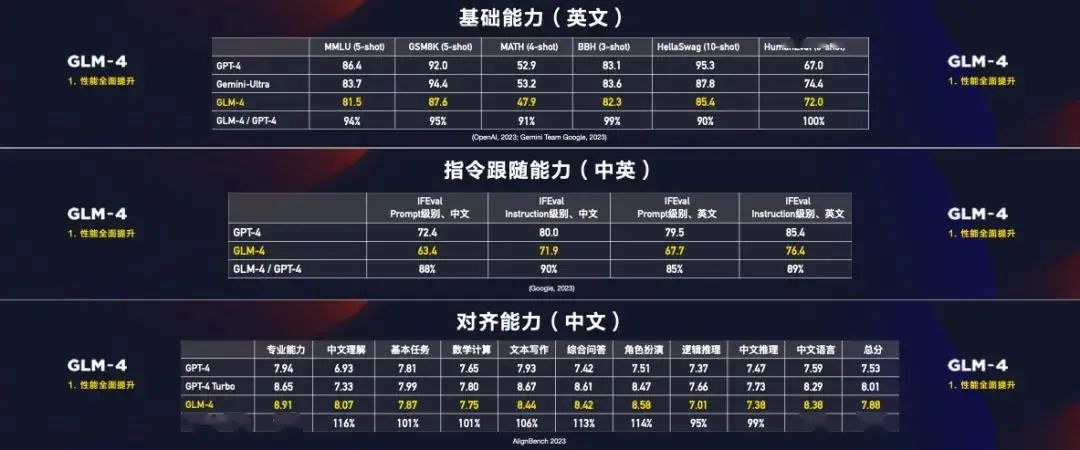
2024年1月中旬的智谱AI技术开放日上,正式发布了新一代基座大模型GLM-4。
按照智谱AI官方的说法:在权威的英文测试榜单中,GLM-4已经整体逼近GPT-4,平均能达到GPT-4 90%以上的水平,在个别项目上表现持平;而在国内企业更加看重的中文任务上,GLM-4的表现全面超过GPT-4。
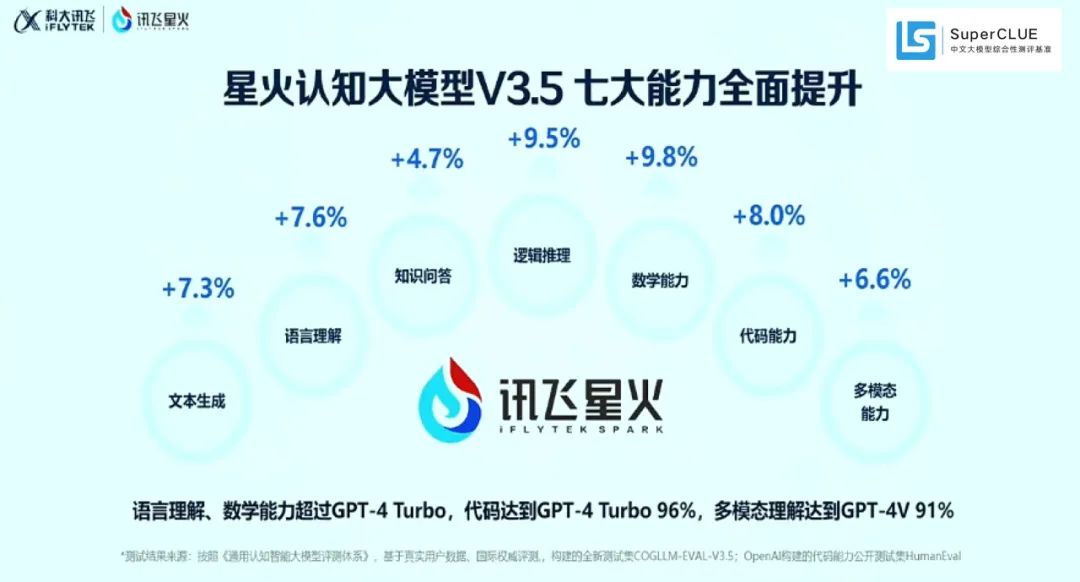
同样是在2024年1月,科大讯飞发布了星火认知大模型V3.5,在逻辑推理、语言理解、文本生成、数学答题、代码、多模态等核心能力均显著提升,其中语言理解、数学能力已经超过GPT-4 Turbo,代码能力达到GPT-4 Turbo 96%,多模态理解达到GPT-4V 91%。“在中文理解方面,甚至遥遥领先。”
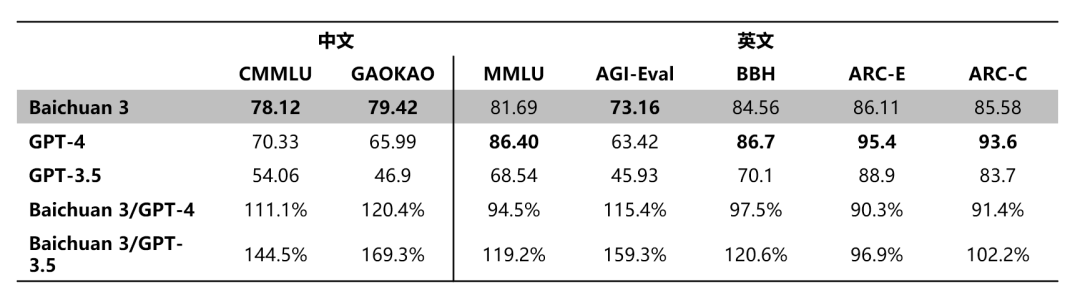
回头来看,智谱AI和科大讯飞的营销策略还是有些“保守”,百川智能在同一时间段发布的Baichuan 3,对外表示已经在CMMLU、GAOKAO等中文评测中超越GPT-4。
第三阶段:全面赶超GPT-4
Turbo2023年11月的OpenAI首届开发者大会,GPT-4 Turbo可以说整个活动的焦点,不仅比GPT-4更聪明,文本处理的上限更高,推理的速度更快,价格也更便宜,国产大模型随即迎来了新的比较对象。
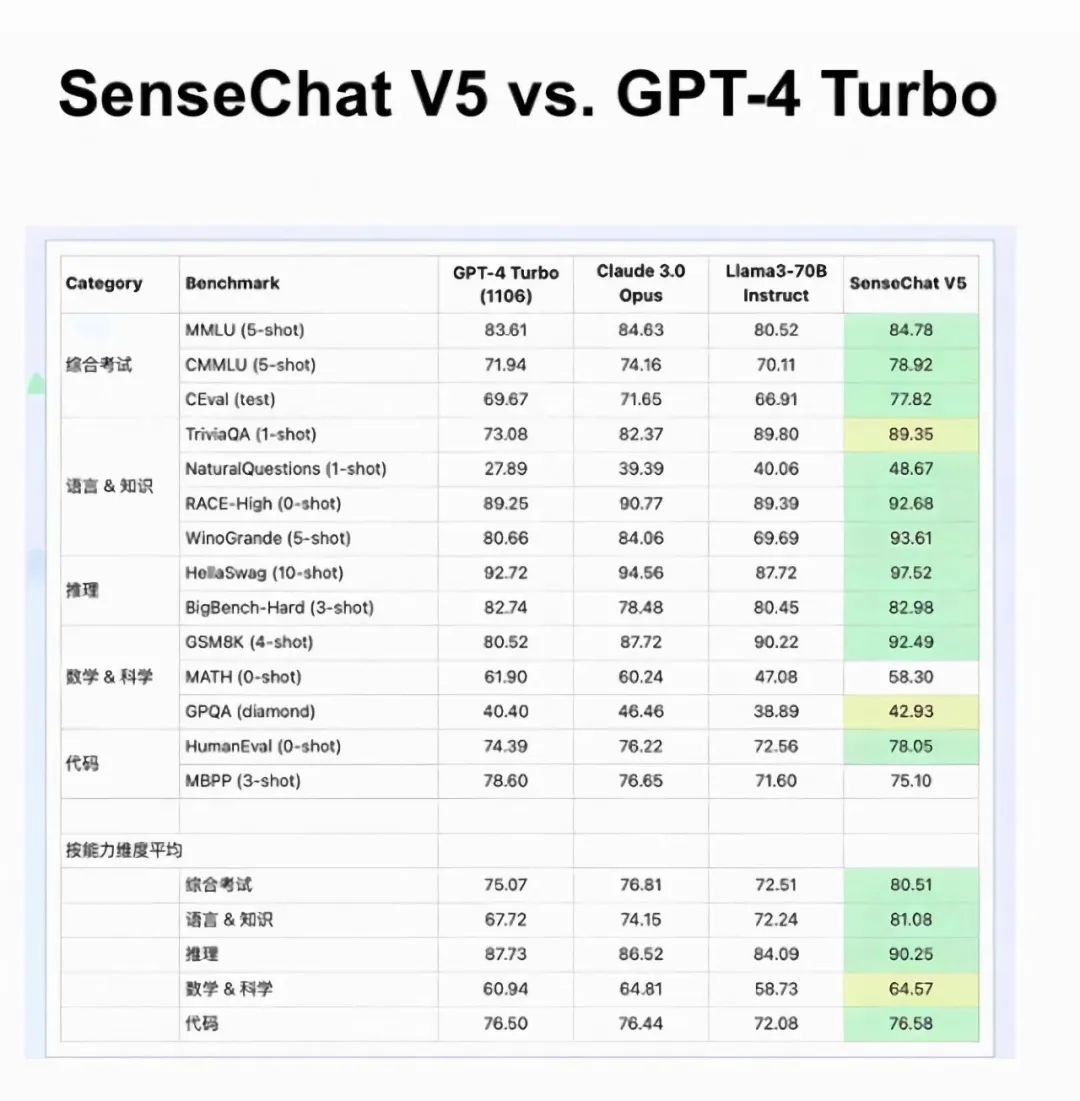
先是2024年4月份发布的日日新5.0,拥有6000亿参数,并在发布会上引用了OpenCompass的评测数据:日日新5.0达到或超越了GPT-4 Turbo版本,几乎全方位碾压了同期发布的 Llama 3-70B。
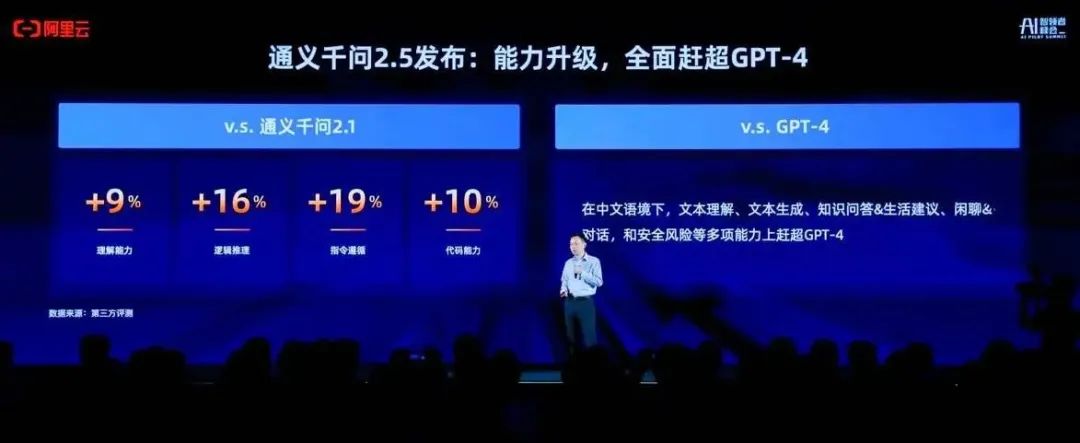
再然后就是阿里云刚刚发布的通义千问2.5,根据媒体报道中的说法:模型性能全面赶超GPT-4-Turbo,成为“地表最强”中文大模型;通义千问1100亿参数开源模型在多个基准测评收获最佳成绩,超越Meta的Llama-3-70B,成为开源领域最强大模型。
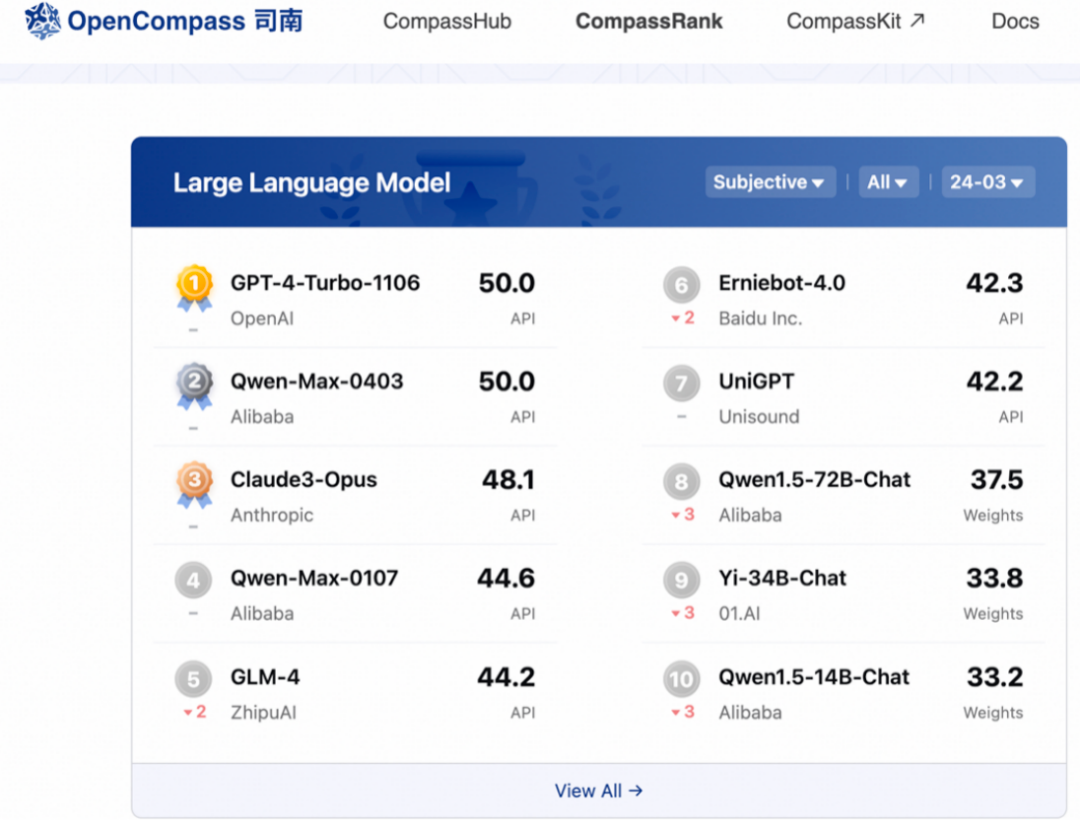
可以笃定的是,日日新5.0和通义千问2.5只是个开始,后续将有更多国产大模型在能力上超越GPT-4-Turbo。
毕竟科大讯飞早已预热了上半年发布星火认知大模型V4.0的消息,将全面对标GPT-4系列;文心一言4.0的发布已经超过半年,不排除新版本正在准备中,且大概率会在性能上再上一个台阶……
“跑分”的意义在哪里?
不管是一开始的“部分性能超越”,还是现在进行中的“全面赶超”,依据都是第三方评测结果,或者说大模型厂商的主观判断。比如商汤和阿里云争相引用的OpenCompass,就是上海人工智能实验室开源的大模型评测平台。
对于一些大模型沉迷于刷榜、跑分的现象,上海人工智能实验室领军科学家林达华教授曾在媒体采访中直言:通过题海战术提高大模型成绩,对于模型实际能力的反应是失真的,影响了模型研发团队的改进方向和模型的商业落地,“高分低能”伤害的是机构本身;榜单上任何具体的名字只是大模型成长过程中无数次测试中的一次,一时的排名高低并不真正反映模型的能力。
何况很多大模型测试集为了公开透明,测试题目或者提纲都是公开的,大模型厂商不难通过“针对性的训练”来提高分数。只要将足够的的测试题喂给大模型,在开卷考试的机制下,分数总不会太低。也就是说,分数高并不一定代表大模型的能力强。
“跑分”的意义仅仅是让客户或开发者对大模型能力有一个初步的认识,最终的评估因素永远是“能不能解决问题”,“能不能在场景中带来实实在在的生产力”。特别是在大模型走向落地应用的趋势下,一味炒作“超越GPT-4”、“跑分第一”,妄顾落地应用的实效,可能会适得其反。
以大模型应用中比较常见的财报分析为例,如果大模型连一家企业的财报都看不懂,再高的计算分数也不会让客户信服,反而会被排除在合作名单外。
而参考中信证券等机构的研究报告,目前OpenAI的GPT-5正处于红队测试阶段,有望在今年夏天正式发布,可能在多模态理解、长文本输入、zero-shot学习等方面实现重大突破,且性能将远超GPT-4。即使国产大模型花费400多天追平了GPT-4,在相当长一段时间里,仍将处于追赶的姿态。
大模型的价值是解决日常问题的生产力工具,赶超GPT-4的阶段性升级,可以看作是国产大模型有序迭代部署、不断拉近差距的标志,切莫像手机跑分那样,在过度营销的作用下,沦为被群嘲的对象。
撰文|顾青云编辑|沈菲菲
本文由人人都是产品经理作者【Alter】,微信公众号:【Alter聊科技】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。







- 目前还没评论,等你发挥!








