
 起点课堂会员权益
起点课堂会员权益策略产品 ①算法逻辑
机器学习是AI的关键技术之一,是指机器从历史数据中学习规律,从而提升系统某个性能度量的过程。这篇文章,我们在作者的带领下梳理下全流程。

机器学习,机器从历史数据中学习规律,从而提升系统某个性能度量的过程。在工业界中的应用主要为:研究如何让计算机从历史数据中更好地学习,从而产生一个优秀模型以提升系统某项性能的学科。
1952年,“Machine Learning”的概念被提出。
一、机器学习与AI的关系
AI是一个领域,1956年8月被正式提出,主要包括三大要素:算法、算力、算据。机器学习便是其中的算法,算力指的是计算资源,最主要的是芯片。故而AI包含机器学习,而机器学习这一实现AI的方法论包括传统机器学习、深度学习、强化学习、深度强化学习等子技术。
AI分为三个阶段:弱人工智能、强人工智能、超人工智能。
- 弱人工智能:专注某方面能力,智商高,情商为0
- 强人工智能:可以批评性思考,智商情商均高
- 超人工智能:智商与情商全面超越人类,思维多元化。

二、机器学习全流程

1. 问题定义
利用机器学习构建模型需要考虑以下问题定义,问题定义清楚后再考虑以下3个问题。
1)机器学习的任务类型是什么?
机器学习的任务类型可以分成两大类:一类是预测类任务,如销量预测、推荐系统、人脸识别等,一类为生成类任务,基于历史数据学习后,可以从零生成任务,具体细化分类如下
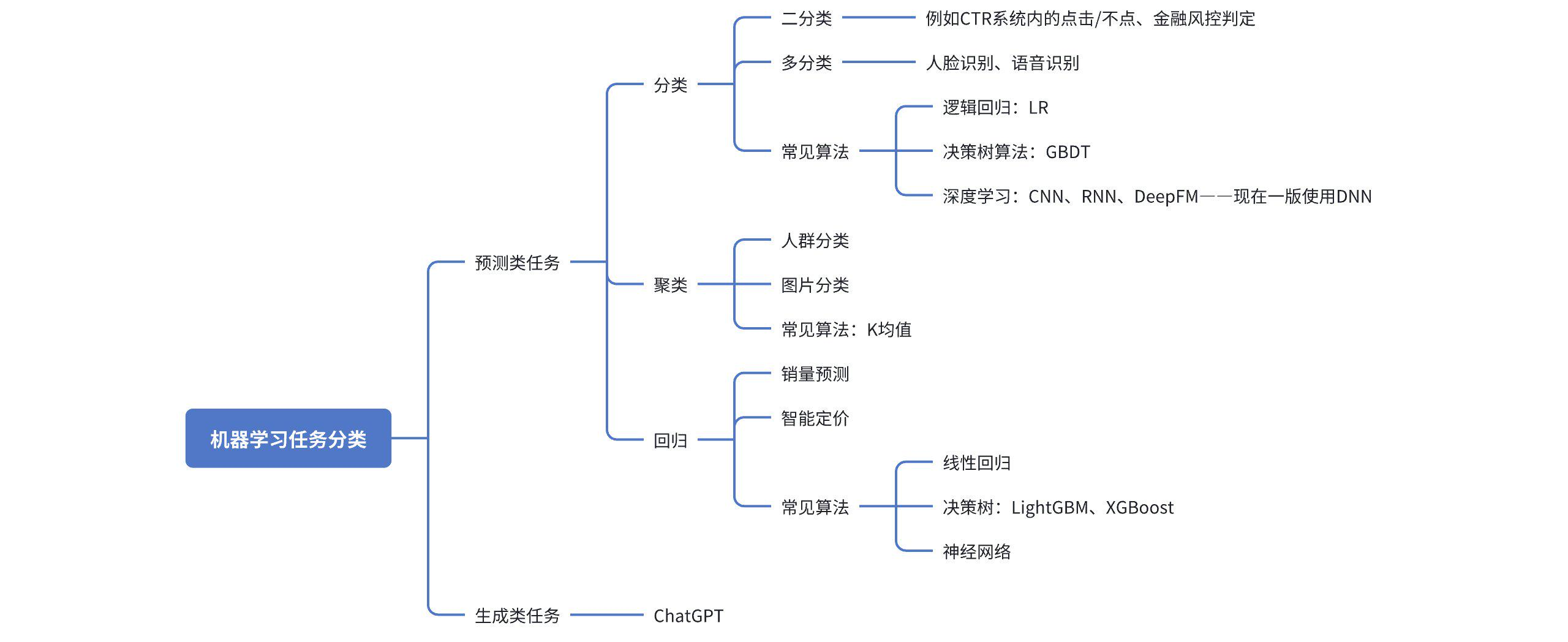
2)使用什么算法来构建模型
任务类型确定后,可以结合具体场景确定使用什么算法。
以CTR预估模型为例,工业界搞起普遍使用LR(logistics regression,逻辑回归)算法,现在多使用DNN(deep neutral network,深度神经网络)算法。
3)如何评估模型的好坏
不同任务类型需要使用不同指标来评估模型效果。对于CTR预估模型,离线训练时应该使用AUC(area under curve,曲线下面积)指标进行评估。。
2. 数据处理
数据处理分为4步:数据收集、数据清晰、数据标注、数据切分。
以用户CTR为例进行说明:
- 数据收集:确定需使用的数据,分为正样本(用户点击)和负样本(用户不点击)、基本信息特征(最好近期,样本量大时可以随机抽样)
- 数据清洗:剔除脏数据、测试数据、无效数据、统一字段含义。
- 数据标注:人工达标分类,明确样本标签
- 数据切分:训练集+测试集测试拟合效果,调试防过拟合/不拟合。(注:小心“数据穿越”问题的出现)
3. 特征工程
模型效果一部分由数据质量决定,一部分由特征工程决定。挑选使用场景下最适合、最有效的特征并加入模型,这就是特征工程的工作。此时业务专家的经验输入可以帮助锁定有效特征。
4. 模型训练
常见的模型训练方法有四种:监督学习、无监督学习、半监督学习、强化学习,主要区分点在于是否数据打标、算法模式。
- 监督学习:打好已知训练数据的标签,目的明确的学习特征。
- 无监督学习:直接训练数据模型,原因:数据杂乱、标注成本高、区分标准难确定,方式比如聚类
- 半监督学习:有的达标,有的不打
- 强化学习:不需要达标,与环境互动,奖励/惩罚+反馈调整。
经过数据+算法输入,构建完特征工程后即有初版模型,表现形式为函数,如y=ax+by+cz+d,模型训练结果可能出现欠拟合、过拟合、正常三种情况。
5. 模型评估
模型评估主要指离线效果评估,不是在线上做小流量的ABTest试验,需要在测试集上进行验证,对于不同任务有不同的关注点。
- 分类任务:召回率、精准率、AUC指标
- 聚类任务:聚类纯度、兰德系数
- 回归任务:MSE、RMSE、R-Squared。
6. 模型应用
在线上真实环境进行效果测试。用户行为变化、数据迭代速度是影响因素,所以需要线上不断调优。
本文由 @产品研习中 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


